【题目】
原题地址
题目大意:字符集大小为小写字母,给定一个字符串
,你可以在
中的任意位置添加一共
个字符。问最后得到的字符串是回文串的方案数(方案不同当且仅当最终得到的回文串不同)。
【题目分析】
这题
很大,我们可以显然发现这是一个矩阵快速幂,但是这样做的复杂度爆炸,需要用一些巧妙的方法来优化。
【题目分析】
以下设
,图片均来自官方题解。
题意其实要求的就是一个回文串中有s这个子序列的方案数。
因为回文串左边确定了,右边也一定确定了,那么当只确定一部分字符时,匹配的
串一定是一段前缀加一段后缀。
我们设
表示已经确定了前
个字符,左边和
前缀匹配到l,右边和
的后缀匹配到
的方案数。
那么
可能可以转移到:
,
,
这些边权值都为1,代表字符唯一确定,即分别表示新字符匹配左边/右边/两边都匹配。
还可能存在自环,即转移到
,此时可能存在边权为24或25的自环(前者是两端字符不同,后者是相同)。
最后还有终点的自环,边权为26(因为可以随意匹配)
答案就是在这个图上走
步能到终点的方案数。图长得和下面差不多。
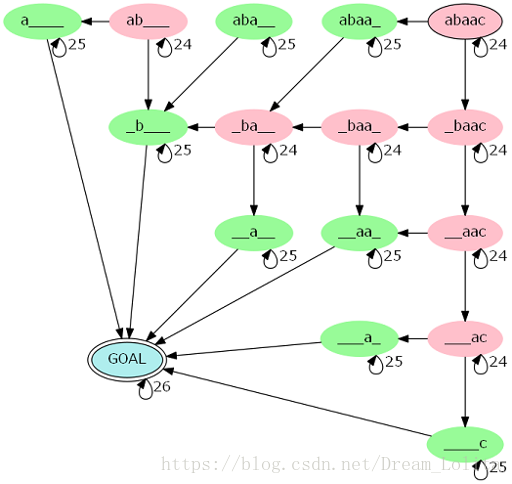
但直接做矩阵快速幂,状态数是 的,显然过不了。
发现这个图是一个DAG,每一条从起点到终点的路径都可以抽出来,当作一个单独的自动机做快速幂,对其他路径没有影响。这样状态数是
,但还要乘上链数,复杂度是
,仍然过不了。

接下来想优化这个做法需要发现一些性质。
我们记一条链有24自环的节点有 个,有25自环的节点有 个,可以发现 或 (因为可能字符串长度为奇数),也就是说对于一个确定的 ,一定有一个确定的
现在考虑这每一条链,实际上自环顺序对答案没有影响,那么现在实际上我们要求的就是将除了链长外的步数分给24/25/26,的所有方案,看起来可以用数学方法来做,然而很不可做。
每一条链看起来十分相似,那么我们有没有什么办法能将他们通过特殊的方法合并起来呢?
这里要用一个技巧来合并这
条链的状态。
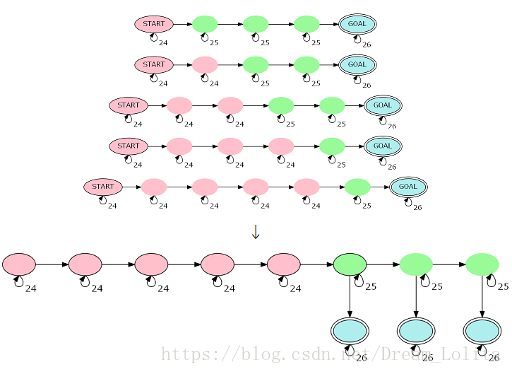
我们构建一个自动机
,然后每个25后面再接上一个
,每个
有一个26的自环。
我们发现,这样每一条链都可以由这个自动机上的某一段表示出来。这个自动机只有
个节点,且转移矩阵是唯一确定的。
那么我们可以计算出这个矩阵的
次幂,并构造一个矩阵使得可以表示出从每个24出发的方案(实际上就是某些格子为1),算出从这里所有
的答案。
这样子的复杂度仍然有
,超了一点。但是我们发现,最后构造出的自动机相当于一颗树,因此转移矩阵的左下角一定都是0,因此for (i=1 to n) (j=i to n) (k=i to j) 就行了。
当然还有一些细节比如说字符串长度是奇数偶数这种。
需要去除一些算重的情况,这里不多说了,有点复杂233(主要是懒)。
据说还有 的做法,但是CF官方题解也没说,只是将代码贴了出来,于是我也不打算去看qwq。
【参考代码】
#include<bits/stdc++.h>
using namespace std;
const int N=405,mod=1e4+7;
int n,m,len,ans,sum;
char s[N];
int f[N>>1][N>>1][N>>1];
struct Matrix
{
int a[N][N];
Matrix(){memset(a,0,sizeof(a));}
void init(){for(int i=1;i<=len;++i) a[i][i]=1;}
}mat,tmp;
Matrix mult(Matrix A,Matrix B)
{
Matrix ret;
for(int i=1;i<=len;++i)
for(int j=i;j<=len;++j)
{
ret.a[i][j]=0;
for(int k=i;k<=j;++k) (ret.a[i][j]+=A.a[i][k]*B.a[k][j])%=mod;
}
return ret;
}
Matrix qpow(Matrix A,int y)
{
Matrix ret;ret.init();
for(;y;y>>=1,A=mult(A,A)) if(y&1) ret=mult(ret,A);
return ret;
}
int calc(int x,int l,int r)
{
if(~f[x][l][r]) return f[x][l][r];
f[x][l][r]=0;
if(l==r) return f[x][l][r]=(x==0);
if(s[l]==s[r]) return (l+1==r?(f[x][l][r]=(x==0)):(f[x][l][r]=calc(x,l+1,r-1)));
if(x>0) return f[x][l][r]=(calc(x-1,l+1,r)+calc(x-1,l,r-1))%mod;
return f[x][l][r];
}
int main()
{
#ifndef ONLINE_JUDGE
freopen("CF506E.in","r",stdin);
freopen("CF506E.out","w",stdout);
#endif
scanf("%s%d",s+1,&m);n=strlen(s+1);m+=n;memset(f,-1,sizeof(f));
int pw=(m+1)>>1,n24=n-1,n25=(n+1)>>1,n26=n25;
len=n24+n25+n26;
for(int i=1;i<=n24;++i) mat.a[i][i]=24,mat.a[i][i+1]=1;
for(int i=n24+1;i<=n24+n25;++i) mat.a[i][i]=25,mat.a[i][i+n25]=mat.a[i-1][i]=1;
for(int i=n24+n25+1;i<=n24+n25+n26;++i) mat.a[i][i]=26;
tmp=qpow(mat,pw-1);mat=mult(tmp,mat);
for(int i=0;i<=n24;++i)
{
int j=(n-i+1)>>1,k=pw-i-j;
if(k<0) continue;
sum=calc(i,1,n)%mod;
(ans+=sum*mat.a[n24-i+1][n24+n25+j])%=mod;
if((m&1) && (n-i&1^1)) ((ans-=sum*tmp.a[n24-i+1][n24+j]%mod)+=mod)%=mod;
}
printf("%d\n",ans);
return 0;
}【总结】
十分可怕的一题,这题dp优化的意义很大,自动机合并的新套路get。