Текущий статус Apache Spark в iQiyi
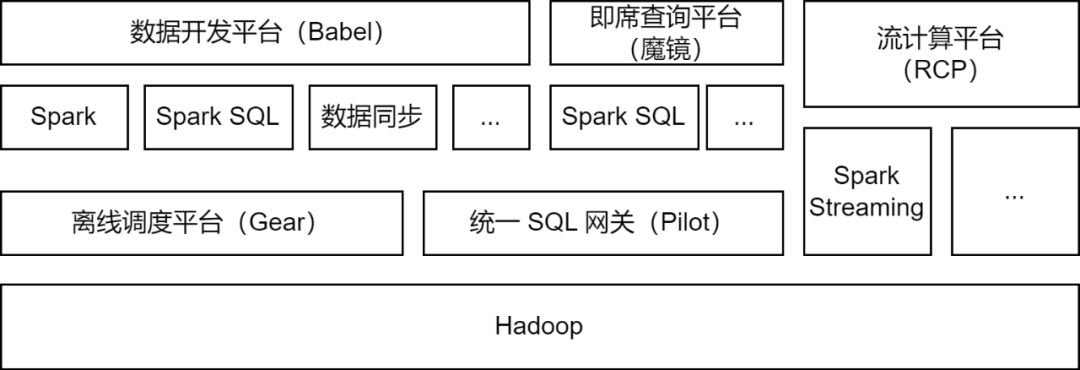
Apache Spark — это платформа автономных вычислений, которая в основном используется платформой больших данных iQiyi и поддерживает некоторые задачи потоковых вычислений для обработки данных, синхронизации данных, анализа запросов к данным и других сценариев:
-
Обработка данных . Платформа разработки данных позволяет разработчикам отправлять задачи пакета Spark Jar или задачи Spark SQL для обработки данных ETL.
-
Синхронизация данных
: инструмент синхронизации данных BabelX, разработанный iQIYI, разработан на основе вычислительной среды Spark. Он поддерживает обмен данными между 15 источниками данных, такими как Hive, MySQL и MongoDB, а также поддерживает синхронизацию данных между несколькими кластерами и несколькими облаками. настроены Полностью управляемые задачи синхронизации данных.
-
Анализ данных . Аналитики данных и студенты, изучающие операции, отправляют SQL или настраивают запросы индикаторов данных на платформе специальных запросов Magic Mirror и вызывают службу Spark SQL через унифицированный шлюз SQL Pilot для анализа запросов.
В настоящее время сервис iQiyi Spark ежедневно выполняет более 200 000 задач Spark, занимая более половины общих вычислительных ресурсов больших данных.
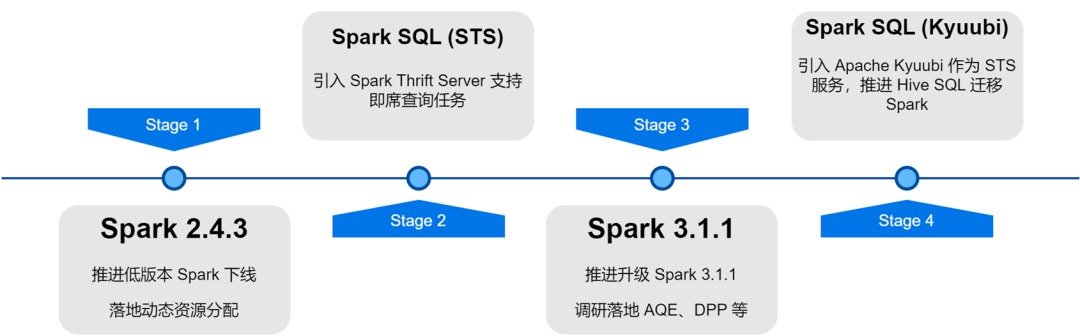
В процессе обновления и оптимизации архитектуры платформы больших данных iQiyi сервис Spark подвергся итерации версий, оптимизации сервиса, SQLизации задач, управлению стоимостью ресурсов и т. д., что значительно повысило эффективность вычислений и экономию ресурсов при выполнении автономных задач.
Оптимизация приложений платформы вычислений Spark
При итеративном обновлении внутренней версии Spark мы исследовали и реализовали несколько замечательных функций новой версии Spark: динамическое распределение ресурсов, адаптивную оптимизацию запросов, динамическое сокращение разделов и т. д.
-
Динамическое распределение ресурсов (DRA)
: пользовательское приложение не учитывает ресурсы, а требования к ресурсам на каждом этапе задач Spark также различны. Необоснованное распределение ресурсов приводит к пустой трате ресурсов задачи или медленному выполнению. Мы запустили службу внешнего перемешивания в Spark 2.4.3 и включили динамическое распределение ресурсов (DRA). После включения Spark будет динамически запускать или освобождать Executor в зависимости от требований к ресурсам текущего этапа работы. После того как DRA вышел в онлайн, потребление ресурсов задачами Spark сократилось на 20%.
-
Адаптивная оптимизация запросов (AQE)
. Адаптивная оптимизация запросов (AQE) — отличная функция, представленная в Spark 3.0. На основе статистических показателей во время выполнения предварительного этапа она динамически оптимизирует план выполнения последующих этапов и автоматически выбирает наиболее подходящий. Оптимизируйте искаженное объединение, объединяйте небольшие разделы, разделяйте большие разделы и т. д. После обновления Spark 3.1.1 AQE был включен по умолчанию, что эффективно решило такие проблемы, как небольшие файлы и искажение данных, а также значительно улучшило вычислительную производительность Spark. Общая производительность увеличилась примерно на 10%.
-
Динамическое сокращение разделов (DPP)
. В вычислительных механизмах SQL обычно используется перенос предикатов для уменьшения объема данных, считываемых из источника данных, тем самым повышая эффективность вычислений. В Spark3 представлен новый метод pushdown: динамическое сокращение разделов и фильтр времени выполнения. При первом расчете маленькой таблицы соединения большая таблица соединения фильтруется на основе результатов вычислений, тем самым уменьшая объем данных, считываемых большой таблицей. стол. Мы провели исследование и тестирование этих двух функций и включили DPP по умолчанию. В некоторых бизнес-сценариях производительность выросла в 33 раза. Однако мы обнаружили, что в Spark 3.1.1 включение DPP приведет к тому, что синтаксический анализ SQL со многими подзапросами будет особенно медленным. Поэтому мы реализовали правило оптимизации: подсчитываем количество подзапросов, и когда оно превышает 5
, отключаем
оптимизацию DPP.
В процессе использования Spark мы также столкнулись с некоторыми проблемами. Следя за последними достижениями сообщества, мы обнаружили и установили некоторые исправления для их решения. Кроме того, мы также внесли некоторые улучшения в Spark, чтобы сделать его пригодным для различных сценариев применения и повысить стабильность вычислительной среды.
-
Поддержка одновременной записи
Поскольку Spark 3.1.1 по умолчанию преобразует таблицы формата Hive Parquet во встроенный в Spark Parquet Writer, для записи данных используйте оператор InsertIntoHadoopFsRelationCommand (spark.sql.hive.convertMetastoreParquet=true). При записи статического раздела временный каталог будет создан непосредственно под путем к таблице. Когда несколько задач записи статических разделов одновременно записывают данные в разные разделы одной и той же таблицы, существует риск сбоя записи задачи или потери данных (при фиксации задачи весь временный каталог будет очищен, что приведет к потере данных). для других задач).
Мы добавляем параметр ForceUseStagingDir к оператору InsertIntoHadoopFsRelationCommand и используем промежуточный каталог для конкретной задачи в качестве временного каталога. Таким образом, разные задачи используют разные временные каталоги, что решает проблему одновременной записи. Мы представили сообществу соответствующую проблему [SPARK-37210].
-
Поддержка запросов к подкаталогам
После обновления Hive до версии 3.x механизм Tez используется по умолчанию. При выполнении оператора Union будет создан подкаталог HIVE_UNION_SUBDIR. Поскольку Spark игнорирует данные в подкаталогах, никакие данные не могут быть прочитаны.
Эту проблему можно решить, вернув Parquet/Orc Reader к Hive Reader, добавив следующие параметры:

Однако использование встроенного в Spark Parquet Reader обеспечит более высокую производительность, поэтому мы отказались от плана вернуться к Hive Reader и вместо этого преобразовали Spark. Поскольку Spark уже поддерживает чтение подкаталогов несекционированных таблиц с помощью параметра recursiveFileLookup, мы расширили его, чтобы поддерживать чтение подкаталогов секционированных таблиц. Подробности см. в [SPARK-40600].
-
Улучшения источника данных JDBC
В приложениях синхронизации данных существует большое количество задач источников данных JDBC. Чтобы повысить эффективность работы и адаптироваться к различным сценариям приложений, мы внесли следующие изменения во встроенный источник данных JDBC Spark:
Смещение условий сегментирования
:
после того, как Spark фрагментирует источник данных JDBC, он вставляет условия сегментирования через подзапросы. Мы обнаружили, что в MySQL 5.x условия подзапроса не могут быть переданы вниз, поэтому мы добавили Заполнитель представляет положение условия. , а при вставке условия сегментирования в Spark оно перемещается внутрь подзапроса, тем самым реализуя возможность выполнения условия сегментирования.
Несколько режимов записи
.
Мы реализовали несколько режимов записи для источников данных JDBC в Spark.
-
Обычный: обычный режим, для записи используйте INSERT INTO по умолчанию.
-
Upsert: обновление при наличии первичного ключа, записанного в режиме INSERT INTO...ON DUPLICATE KEY UPDATE.
-
Игнорировать: игнорировать наличие первичного ключа, писать в режиме INSERT IGNORE INTO.
Тихий режим:
если во время записи JDBC возникает исключение, печатается только журнал исключений, а задача не завершается.
Поддержка типа карты
: мы используем источник данных JDBC для чтения и записи данных ClickHouse. Тип карты в ClickHouse не поддерживается в источнике данных JDBC, поэтому мы добавили поддержку типа карты.
-
Ограничение размера записи на локальный диск
Такие операции, как «Перемешать», «Кэш» и «Разлив» в Spark, будут создавать некоторые локальные файлы. Когда записывается слишком много локальных файлов, диск вычислительного узла может быть заполнен, что влияет на стабильность кластера.
В связи с этим мы добавили индикатор объема записи на диск в Spark, выдаем исключение, когда объем записи на диск достигает порогового значения, оцениваем исключение сбоя задачи в TaskScheduler и вызываем DagScheduler при обнаружении исключения ограничения записи на диск. метод останавливает задачи с чрезмерным использованием диска.
В то же время мы также добавили индикатор использования диска Executor в ExecutorMetric, чтобы отображать текущее использование диска Spark Executor, что упрощает наблюдение за тенденциями и анализ данных.
Сервис Spark отнимает много вычислительных ресурсов. Мы разработали платформу управления исключениями для аудита и управления вычислительными ресурсами для задач пакетной обработки Spark и задач потоковых вычислений соответственно.
В ходе повседневной эксплуатации и обслуживания мы обнаружили, что у большого количества задач Spark возникают такие проблемы, как непроизводительная трата памяти и низкая загрузка ЦП. Чтобы найти задачи с этими проблемами, мы доставляем индикаторы ресурсов, когда задачи Spark выполняются, в Prometheus для анализа использования ресурсов задач, а также получаем информацию о конфигурации ресурсов и расчетах путем анализа Spark EventLog.
За счет оптимизации параметров ресурсов задач и включения динамического распределения ресурсов эффективно улучшается использование вычислительных ресурсов задачами Spark. Обновление версии Spark также обеспечивает значительную экономию ресурсов.
Оптимизация параметров ресурсов разделена на оптимизацию памяти и ЦП. Платформа управления исключениями рекомендует разумные настройки параметров ресурсов на основе пикового использования ресурсов задачей за последние семь дней, тем самым улучшая использование ресурсов задачами Spark.
На примере оптимизации памяти пользователи часто решают проблему переполнения памяти (OOM) за счет увеличения памяти, но игнорируют углубленное исследование причин OOM. Это приводит к тому, что параметры памяти для большого количества задач Spark устанавливаются слишком высоко, а соотношение памяти ресурсов очереди к ЦП оказывается несбалансированным. Мы получаем индикаторы памяти Spark Executor и отправляем рабочие задания по исключениям, чтобы уведомить пользователей и помочь им правильно настроить параметры памяти и количество разделов.
После почти года управления аудитом ресурсов платформа управления исключениями выдала более 1600 рабочих заданий, сэкономив в общей сложности около 27% вычислительных ресурсов.
Внедрение и оптимизация сервиса Spark SQL.
Служба iQiyi Spark SQL прошла несколько этапов: от собственной службы Thrift Server Spark до версии Kyuubi 0.7 и версии Apache Kyuubi 1.4, что привело к значительным улучшениям в архитектуре службы и ее стабильности.
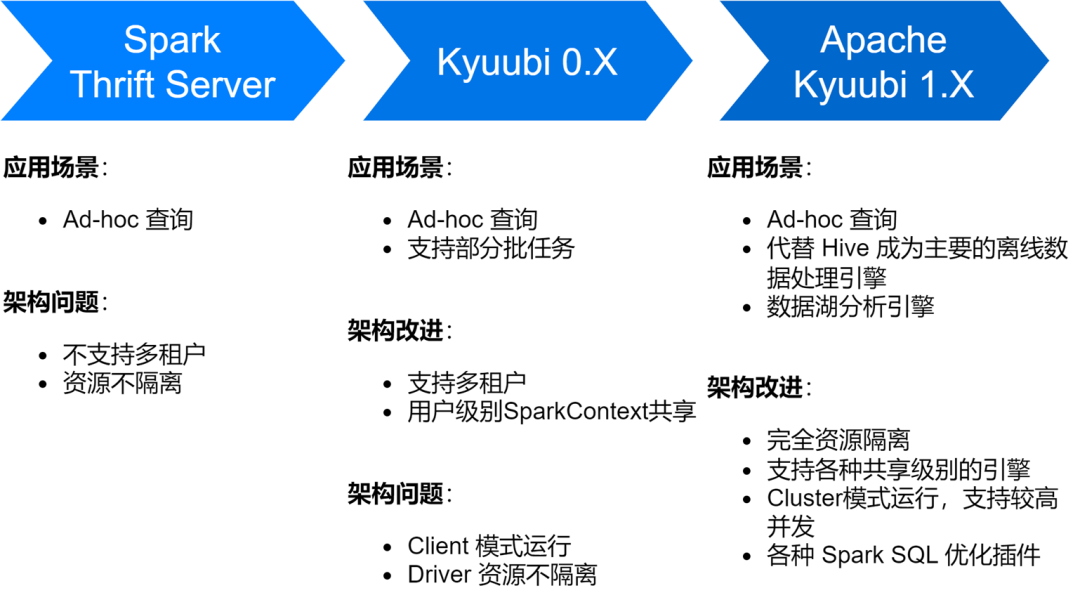
В настоящее время сервис Spark SQL заменил Hive в качестве основного механизма автономной обработки данных iQiyi, выполняя в среднем около 150 000 задач SQL каждый день.
-
Оптимизация хранения и эффективности вычислений
Во время исследования службы Spark SQL мы также столкнулись с некоторыми проблемами, в основном включая создание большого количества небольших файлов, увеличение объема хранилища и более медленные вычисления. По этой причине мы также провели ряд оптимизаций эффективности хранения и вычислений.
Включите сжатие ZStandard, чтобы улучшить степень сжатия.
Zstd — это алгоритм сжатия с открытым исходным кодом Meta. По сравнению с другими форматами сжатия он имеет более высокую скорость сжатия и эффективность распаковки. Наши фактические результаты измерений показывают, что степень сжатия Zstd эквивалентна Gzip, а скорость распаковки лучше, чем у Snappy. Поэтому мы использовали формат сжатия данных Zstd в качестве формата сжатия данных по умолчанию в процессе обновления Spark, а также установили для данных в случайном порядке сжатие Zstd, что привело к значительной экономии ресурсов кластерного хранилища. При применении в сценариях с рекламными данными степень сжатия улучшилась в 3,3 раза. , что позволяет сэкономить 76 % затрат на хранение.
Добавьте этап ребалансировки, чтобы избежать создания маленьких файлов.
Проблема небольших файлов — важная проблема в Spark SQL: слишком много маленьких файлов окажут большую нагрузку на Hadoop NameNode и повлияют на стабильность кластера. Собственная вычислительная среда Spark не имеет хорошего автоматизированного решения для решения проблемы небольших файлов. В связи с этим мы также исследовали некоторые отраслевые решения и, наконец, использовали решение для оптимизации небольших файлов, которое поставляется с сервисом Kyuubi.
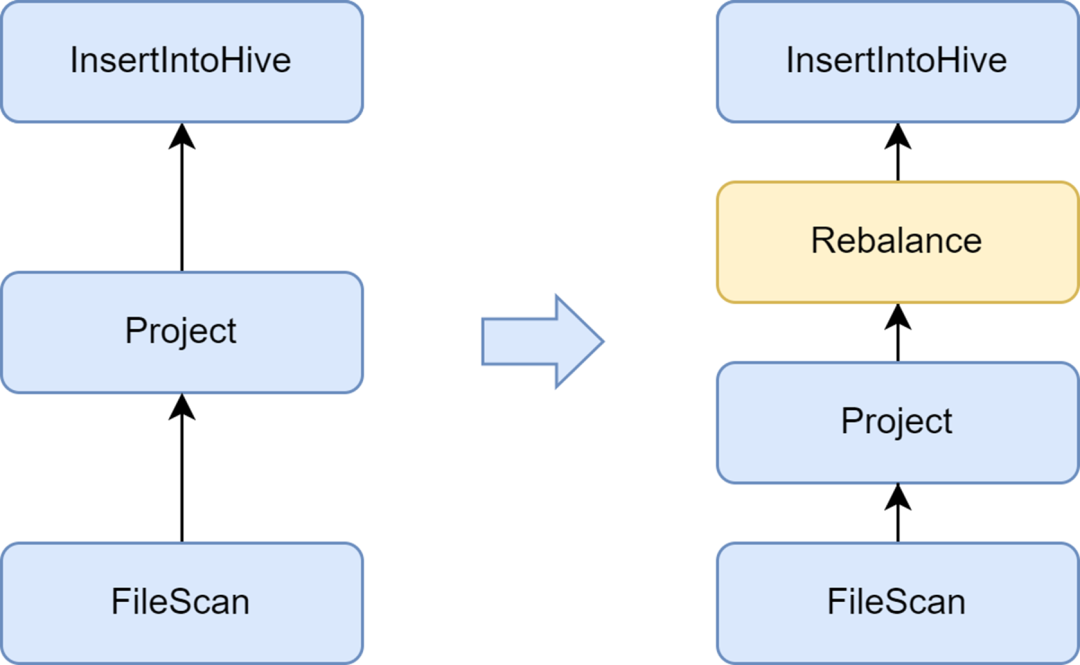
Оптимизатор InsertRepartitionBeforeWrite, предоставляемый Kyuubi, может вставлять оператор Rebalance перед оператором Insert. В сочетании с логикой AQE для автоматического объединения небольших разделов и разделения больших разделов он реализует контроль размера выходного файла и эффективно решает проблему небольших файлов.
После его включения средний размер выходного файла Spark SQL оптимизируется с 10 МБ до 262 МБ, что позволяет избежать создания большого количества маленьких файлов.
Включите вывод сортировки перераспределения для дальнейшего улучшения степени сжатия.
Включив оптимизацию мелких файлов, мы обнаружили, что хранилище данных некоторых задач стало намного больше. Это связано с тем, что операция Rebalance, вставленная в оптимизацию небольших файлов, использует для разбиения поля разделов или случайные разделы, а данные разбрасываются случайным образом, что приводит к снижению эффективности кодирования файла в формате Parquet, что, в свою очередь, приводит к снижению в степени сжатия файлов.
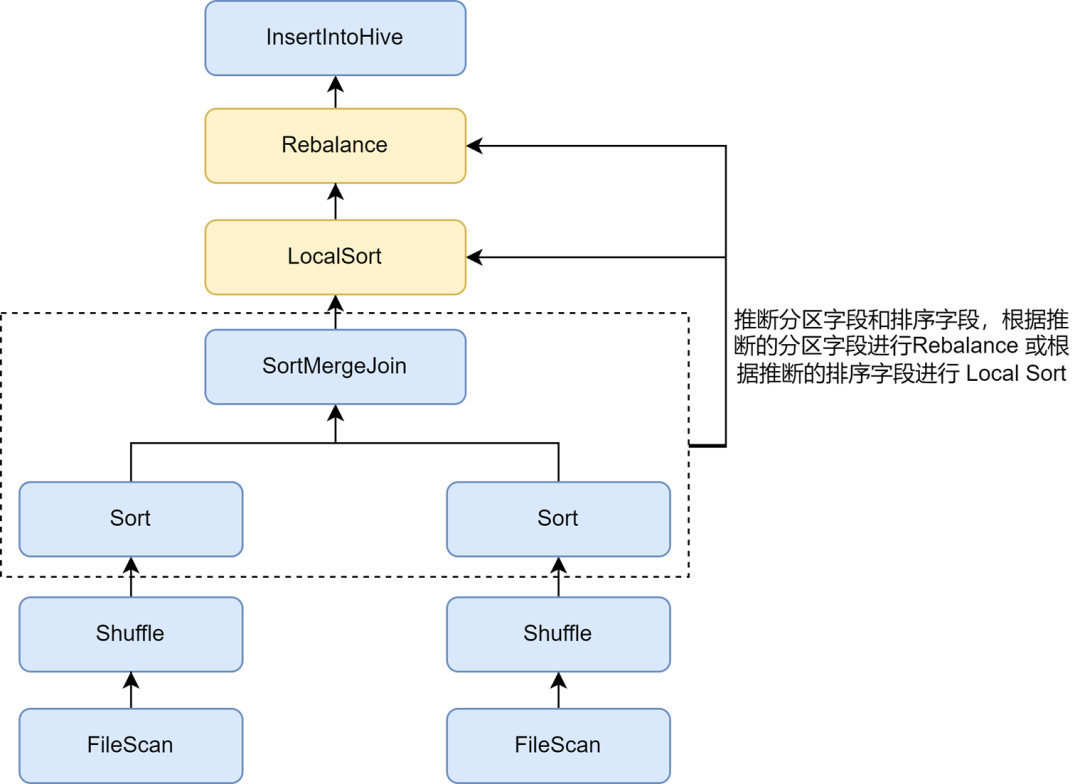
В правилах оптимизации небольших файлов Kyuubi автоматический вывод разделов и полей сортировки можно включить с помощью параметра spark.sql.optimizer.inferRebalanceAndSortOrders.enabled. Для нединамической записи разделов в файле используются такие операторы, как Join, Aggregate и Sort. используются план предварительного выполнения. Поля секционирования и сортировки выводятся из ключей, а выведенные поля секционирования используются для перебалансировки, или выведенные поля сортировки используются для локальной сортировки перед перебалансировкой, так что распределение данных окончательно вставленных данных. Оператор ребалансировки максимально соответствует предварительному плану и позволяет избежать записи. Входящие данные разбросаны случайным образом, тем самым эффективно улучшая степень сжатия.
Включите оптимизацию Zorder, чтобы повысить степень сжатия и эффективность запросов.
Сортировка Zorder — это алгоритм многомерной сортировки. Для столбчатых форматов хранения, таких как Parquet, эффективные алгоритмы сортировки могут сделать данные более компактными, тем самым улучшая степень сжатия данных. Кроме того, поскольку аналогичные данные собираются в одном и том же блоке хранения, например, статистический диапазон мин/макс меньше, объем пропуска данных во время процесса запроса может быть увеличен, что эффективно повышает эффективность запроса.
Оптимизация сортировки по кластеризации Zorder реализована в Kyuubi. Поля Zorder можно настроить для таблиц, а сортировка Zorder будет автоматически добавляться при записи. Для существующих задач также поддерживается команда «Оптимизировать» для оптимизации Zorder существующих данных. Мы внедрили внутреннюю оптимизацию Zorder для некоторых ключевых предприятий, сократив пространство для хранения данных на 13 % и повысив производительность запросов к данным на 15 %.
На заключительном этапе внедрите независимую конфигурацию AQE для повышения параллелизма вычислений.
В процессе миграции некоторых задач Hive в Spark мы обнаружили, что скорость выполнения некоторых задач фактически замедлилась. Анализ обнаружил, что, поскольку оператор Rebalance был вставлен перед записью и объединен с Spark AQE для управления небольшими файлами, мы изменили Spark AQE. sql Для конфигурации Adaptive.advisoryPartitionSizeInBytes установлено значение 1024M, что приводит к уменьшению параллелизма промежуточной фазы перемешивания, что, в свою очередь, замедляет выполнение задачи.
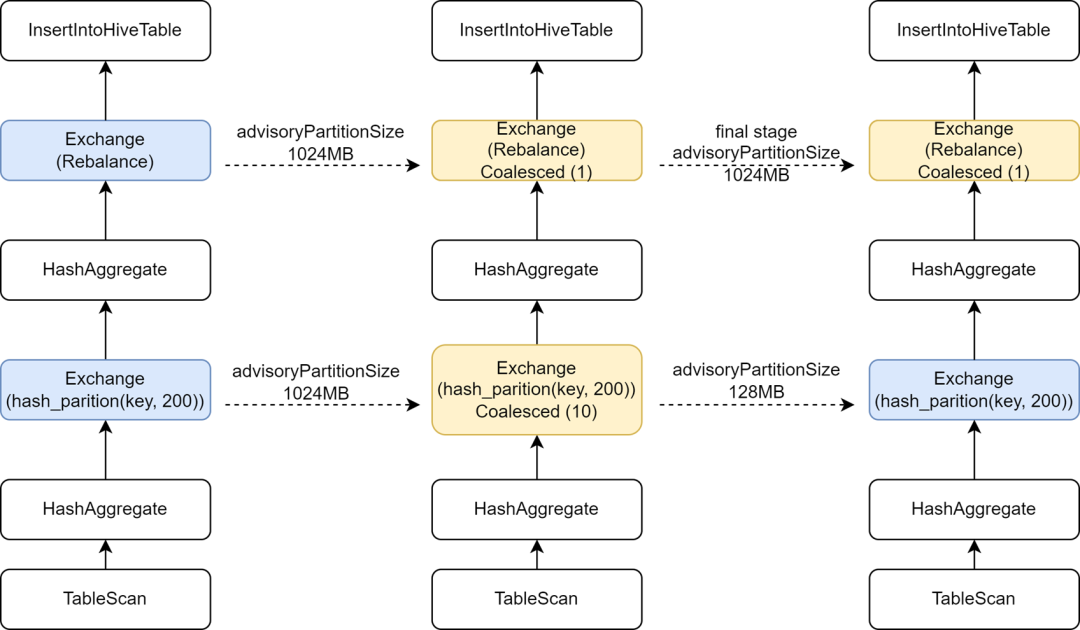
Kyuubi обеспечивает оптимизацию конфигурации финального этапа, позволяя добавлять некоторые конфигурации отдельно для финального этапа, чтобы мы могли добавить больший AdvisoryPartitionSizeInBytes для финального этапа управления небольшими файлами и использовать меньший AdvisoryPartitionSizeInBytes для предыдущих этапов для увеличения параллелизма. степени вычислений и уменьшает переполнение диска на этапе перемешивания, эффективно повышая эффективность вычислений. После добавления этой конфигурации общее время выполнения задач Spark SQL сокращается на 25 %, а ресурсы экономятся примерно на 9 %.
Сделайте вывод о динамической записи однораздельных задач, чтобы избежать чрезмерно больших разделов Shuffle.
При динамической записи разделов оптимизация небольших файлов Kyuubi будет использовать поле динамического раздела для перебалансировки. В задачах, использующих динамическое секционирование для записи в один раздел, все данные в случайном порядке будут записываться в один и тот же раздел в случайном порядке. iQIYI внутренне использует Apache Uniffle в качестве службы удаленного перемешивания. Большие разделы вызывают единую точку давления на сервере перемешивания и даже вызывают ограничение тока и снижение скорости записи. С этой целью мы разработали правило оптимизации, позволяющее фиксировать условия фильтра записанных разделов и делать вывод о том, записываются ли данные одного раздела в режиме динамического разделения. Для таких задач мы больше не используем динамические поля разделов для перебалансировки, а используем случайные значения; Перебалансируйте, чтобы избежать создания большего раздела Shuffle. Подробности см.: [KYUUBI-5079].
-
Обнаружение и перехват аномального SQL
Когда возникают проблемы с качеством данных или пользователи не знакомы с распределением данных, легко отправить ненормальный SQL-запрос, что может привести к серьезной трате ресурсов и низкой эффективности вычислений. Мы добавили некоторые индикаторы мониторинга в службу Spark SQL, а также обнаружили и перехватили некоторые аномальные вычислительные сценарии.
Ограничьте большие запросы
В iQiyi аналитики данных отправляют SQL для анализа специальных запросов через платформу специальных запросов Magic Mirror, которая предоставляет пользователям возможности запросов второго уровня. Мы используем общий механизм Kyuubi в качестве механизма внутренней обработки, чтобы избежать запуска нового механизма для каждого запроса, что приводит к потере времени запуска и вычислительных ресурсов. Постоянное присутствие общего механизма в фоновом режиме может обеспечить пользователям более быстрый интерактивный опыт.
Для общего механизма несколько запросов будут захватывать ресурсы друг у друга. Даже если мы включим динамическое распределение ресурсов, все равно возникают ситуации, когда ресурсы заняты некоторыми большими запросами, что приводит к блокировке других запросов. В связи с этим мы реализовали функцию перехвата больших запросов в плагине Kyuubi Spark. Анализируя такие операции, как сканирование таблицы, в плане выполнения SQL, мы можем подсчитать количество запрошенных разделов и объем сканируемых данных. превышает указанный порог, он будет определен для больших запросов и выполнения перехвата.
По результатам определения платформа Magic Mirror переключает большие запросы на выполнение в независимый механизм. Кроме того, Magic Mirror определяет тайм-аут на уровне минут. Задачи, использующие общий механизм для сверхурочного выполнения, будут отменены и автоматически преобразованы в независимый механизм. Весь процесс нечувствителен к пользователям, эффективно предотвращая блокировку обычных запросов и позволяя продолжать выполнение больших запросов с использованием независимых ресурсов.
Мониторинг раздутия данных
Некоторые операции, такие как разнесение, объединение и подсчет различий в Spark SQL, приведут к расширению данных. Если расширение данных очень велико, это может вызвать переполнение диска, полный сбор мусора или даже OOM, а также ухудшить эффективность вычислений. Мы можем легко увидеть, произошло ли расширение данных, основываясь на количестве индикаторов выходных строк предыдущего и последующего узлов на диаграмме плана выполнения SQL на вкладке SQL пользовательского интерфейса Spark.

Индикаторы в графике плана выполнения Spark SQL передаются драйверу через события выполнения задачи и события тактового сигнала исполнителя и агрегируются в драйвере.
Чтобы более своевременно собирать показатели времени выполнения, мы расширили SQLOperationListener в Kyuubi, прослушивали событие SparkListenerSQLExecutionStart для поддержания sparkPlanInfo и в то же время слушали событие SparkListenerExecutorMetricsUpdate, фиксировали изменения статистических показателей SQL работающего узла. и сравнивал количество индикаторов выходных строк текущего работающего узла и индикатор количества выходных строк предыдущих дочерних узлов, вычислял скорость расширения данных, чтобы определить, происходит ли серьезное расширение данных, и собирал аномальные события или перехватывал аномальные задачи при их возникновении. происходит расширение данных.
Клавиша наклона соединения позиции
Проблема неравномерности данных является распространенной проблемой в Spark SQL и влияет на производительность. Хотя существуют некоторые правила автоматической оптимизации неравномерности данных в Spark AQE, они не всегда эффективны. Кроме того, проблема неравномерности данных может быть вызвана действиями пользователя. неправильное понимание данных. Написана неправильная логика анализа, потому что понимание недостаточно глубокое или сами данные имеют проблемы с качеством данных, поэтому нам необходимо проанализировать задачу перекоса данных и найти искаженное значение ключа.

Мы можем легко определить, произошла ли асимметрия данных в задаче, с помощью статистики задач этапа в пользовательском интерфейсе Spark. Как показано на рисунке выше, максимальное значение длительности и произвольного чтения задачи превышает значение 75-го процентиля, поэтому очевидно, что данные. произошел перекос.
Однако для расчета значений ключей, вызывающих перекос в задаче перекоса, обычно необходимо вручную разделить SQL, а затем вычислить распределение ключей на каждом этапе, используя функцию подсчета групп по ключам, чтобы определить искаженное значение ключа. обычно это относительно трудоемкий процесс.
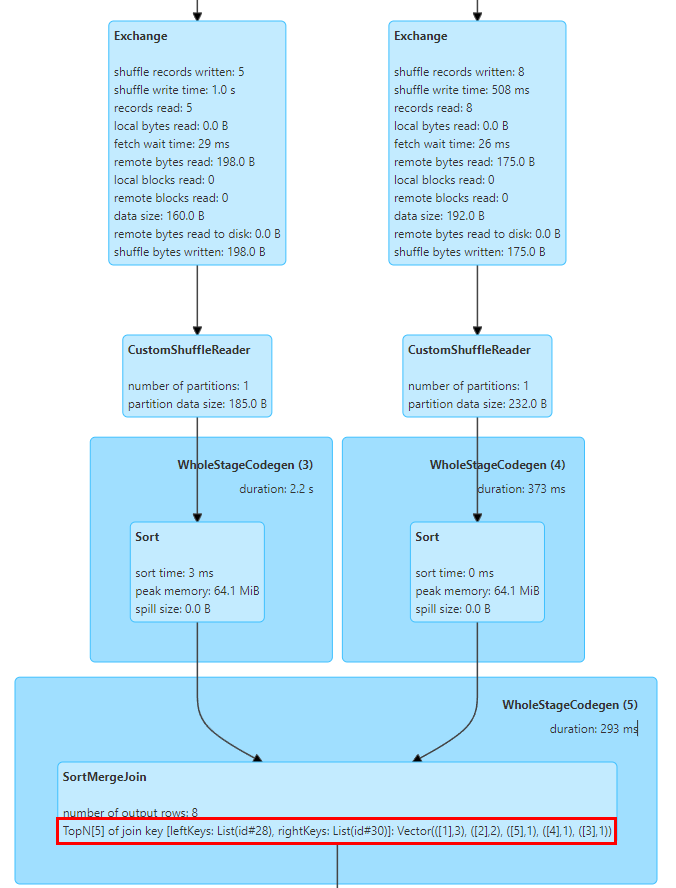
В связи с этим мы реализовали статистику TopN Keys в SortMergeJoinExec.
Реализация SortMergeJoin заключается в том, чтобы сначала отсортировать Ключ, а затем выполнить операцию Объединения, чтобы мы могли легко подсчитать значения TopN Ключа путем накопления.
Мы реализовали аккумулятор TopNAccumulator, который внутренне поддерживает объект типа Map[String, Long]. Он использует значение ключа соединения в качестве ключа карты и сохраняет значение счетчика ключа в значении карты в SortMergeJoinExec для каждой строки данных. Для накопительного расчета, поскольку данные в порядке, нам нужно только накопить вставленные Ключи, а при вставке новых Ключей определить, достигнуто ли значение N, и исключить наименьший Ключ.
Кроме того, Spark поддерживает отображение только статистических индикаторов длинного типа. Мы также изменили логику отображения статистических индикаторов SQL для адаптации к значениям типа Map.
На рисунке выше показаны 5 основных значений ключа соединения двух таблиц для соединения, где ключом является поле id, и есть 3 строки с id=1.
После серии исследований и тестов мы обнаружили, что Spark SQL значительно улучшил производительность и использование ресурсов по сравнению с Hive. Однако мы также столкнулись со многими проблемами во время миграции Hive SQL на Spark. Внеся некоторые изменения совместимости и адаптацию службы Spark SQL, мы успешно перенесли большинство задач Hive SQL в Spark.
Поддержка Spark SQL для Hive UDF имеет некоторые проблемы при фактическом использовании. Например, компании часто используют функцию отражения для вызова статических методов Java для обработки данных. Когда в вызове отражения возникает исключение, Hive вернет значение NULL, а Spark SQL выдаст исключение и приведет к сбою задачи. С этой целью мы изменили функцию отражения Spark, чтобы она фиксировала исключения вызовов отражения и возвращала значения NULL, что соответствует Hive.
Другая проблема заключается в том, что Spark SQL не поддерживает частный конструктор Hive UDAF, что приводит к невозможности инициализации UDAF некоторых предприятий. Мы преобразовали логику регистрации функций Spark для поддержки частных конструкторов Hive UDAF.
-
Совместимость встроенных функций
Существуют различия в логике вычислений встроенной функции GROUPING_ID между Spark SQL и Hive версии 1.2, что приводит к несогласованности данных на этапе двойного выполнения. В версии Hive 3.1 логика вычислений этой функции была изменена, чтобы соответствовать логике Spark, поэтому мы рекомендуем пользователям обновить логику SQL и адаптировать логику этой функции в Spark, чтобы обеспечить правильность логики вычислений.
Кроме того, хеш-функция Spark SQL использует хеш-алгоритм Murmur3, который отличается от логики реализации Hive. Мы рекомендуем пользователям вручную зарегистрировать встроенную хеш-функцию Hive, чтобы обеспечить согласованность данных до и после миграции.
-
Совместимость преобразования типов
В Spark SQL введена спецификация ANSI SQL, начиная с версии 3.0. По сравнению с Hive SQL, он предъявляет более строгие требования к согласованности типов. Например, автоматическое преобразование между строковыми и числовыми типами запрещено. Чтобы избежать аномалий автоматического преобразования, вызванных нестандартными определениями типов данных в бизнесе, мы рекомендуем пользователям добавлять CAST в SQL для явного преобразования. Для крупномасштабных преобразований можно временно добавить конфигурацию spark.sql.storeAssignmentPolicy=LEGACY. чтобы уменьшить проверку типов уровня Spark SQL, чтобы избежать исключений при миграции.
Функция str_to_map в Hive автоматически сохранит последнее значение для повторяющихся ключей, тогда как в Spark будет выдано исключение и задача завершится неудачей. В связи с этим мы рекомендуем пользователям проверять качество исходящих данных или добавить конфигурацию spark.sql.mapKeyDedupPolicy=LAST_WIN, чтобы сохранить последнее повторяющееся значение в соответствии с Hive.
-
Другая совместимость синтаксиса
Синтаксис подсказок Spark SQL и Hive SQL несовместим, и пользователям необходимо вручную удалять соответствующие конфигурации во время миграции. Общие подсказки Hive включают трансляцию небольших таблиц. Поскольку функция Spark AQE более интеллектуальна для трансляции небольших таблиц и оптимизации наклона задач, пользователю обычно не требуется дополнительная настройка.
Также существуют некоторые проблемы совместимости между Spark SQL и операторами DDL Hive. Обычно мы рекомендуем пользователям использовать платформу для выполнения операций DDL с таблицами Hive. Для некоторых команд работы с разделами, таких как удаление несуществующих разделов [KYUUBI-1583], неравные операторы Alter Partition и другие проблемы совместимости, мы также расширили подключаемый модуль Spark для обеспечения совместимости.
Резюме и перспективы
В настоящее время мы перенесли большинство задач Hive в компании в Spark, поэтому Spark стал основным механизмом автономной обработки iQiyi. Мы завершили предварительный аудит ресурсов и работу по оптимизации производительности движка Spark, что принесло компании значительную экономию. В будущем мы продолжим оптимизировать производительность и стабильность сервисов Spark и вычислительных инфраструктур. Мы также будем и дальше продвигать миграцию очень немногих оставшихся задач Hive.
С внедрением озера данных компании все больше и больше предприятий переходят на озеро данных Iceberg. Поскольку Iceberg продолжает совершенствовать функции Spark DataSourceV2, Spark 3.1 больше не может удовлетворить некоторые новые потребности в анализе озера данных, поэтому мы собираемся перейти на Spark 3.4. В то же время мы также провели исследование некоторых новых функций, таких как фильтр времени выполнения, объединение с разделами хранилища и т. д., надеясь еще больше повысить производительность вычислительной среды Spark в соответствии с потребностями бизнеса.
Кроме того, чтобы продвигать процесс облачных вычислений больших данных, мы представили Apache Uniffle, службу удаленного перемешивания (RSS). В ходе использования мы обнаружили проблемы с производительностью при сочетании со Spark AQE, такие как оптимизация перекоса BroadcastHashJoin [SPARK-44065], проблема с большими разделами, упомянутая ранее, и способы более эффективного планирования разделов AQE. Мы продолжим над этим работать. в будущем это приведет к более глубоким исследованиям и оптимизации.
Может быть, вы тоже хотите увидеть

