Озеро данных, каким мы его видим
Наша основная задача, как команды центров обработки данных iQiyi, — управлять и обслуживать большое количество активов данных внутри компании. В процессе внедрения управления данными мы продолжаем осваивать новые концепции и внедрять передовые инструменты для совершенствования управления нашими системами данных.
«Озеро данных» — это концепция, которая широко обсуждалась в области данных в последние годы, а ее технические аспекты также привлекли широкое внимание в отрасли. Наша команда провела углубленное исследование теории и практики озер данных. Мы считаем, что озера данных — это не только новый взгляд на управление данными, но и многообещающая технология интеграции и обработки данных.
Озеро данных — это идея управления данными
Целью внедрения озера данных является предоставление эффективного решения для хранения и управления, позволяющего вывести простоту использования и доступность данных на новый уровень.
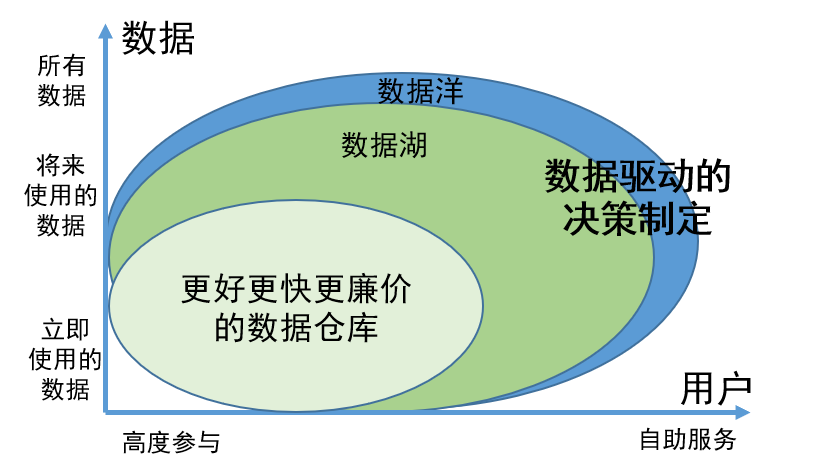
Ценность озера данных как инновационной концепции управления данными в основном отражается в следующих двух аспектах:
1. Возможность комплексного хранения всех данных, независимо от того, используются ли данные или временно недоступны, обеспечивает возможность легкого поиска необходимой информации в случае необходимости и повышает эффективность работы;
2. Данные в озере данных управляются и систематизируются с научной точки зрения, что упрощает пользователям поиск и использование данных самостоятельно. Эта модель управления значительно снижает участие инженеров по данным. Пользователи могут самостоятельно выполнять задачи по поиску и использованию данных, тем самым экономя много человеческих ресурсов.
Чтобы более эффективно управлять всеми типами данных, озеро данных делит данные на четыре основные области в зависимости от различных характеристик и потребностей, а именно исходную область, область продукта, рабочую область и конфиденциальную область:
Область необработанных данных
: эта область ориентирована на удовлетворение потребностей инженеров по данным и профессиональных ученых, занимающихся данными, и ее основная цель — хранить необработанные, необработанные данные. При необходимости его также можно частично открыть для удовлетворения особых требований к доступу.
Область продукта
: Большая часть данных в области продукта обрабатывается и обрабатывается инженерами данных, учеными-исследователями данных и бизнес-аналитиками, чтобы обеспечить стандартизацию и высокую степень управления данными. Этот тип данных обычно широко используется в бизнес-отчетности, анализе данных, машинном обучении и других областях.
Рабочая область
: Рабочая область в основном используется для хранения промежуточных данных, созданных различными обработчиками данных. Здесь пользователи несут ответственность за управление своими данными для поддержки гибкого исследования данных и экспериментирования для удовлетворения потребностей различных групп пользователей.
Конфиденциальная область
: Конфиденциальная область ориентирована на безопасность и в основном используется для хранения конфиденциальных данных, таких как личная информация, финансовые данные и данные о соответствии законодательству. Эта территория защищена высочайшим уровнем контроля доступа и безопасности.
Благодаря такому разделению озеро данных может лучше управлять различными типами данных, обеспечивая при этом удобный доступ к данным и их использование для удовлетворения различных потребностей.
Применение идей управления данными Data Lake в центрах обработки данных
Целью центра обработки данных является решение таких проблем, как непостоянство статистических калибров, повторяющаяся разработка, медленная реакция на потребности в разработке показателей, низкое качество данных и высокая стоимость данных, вызванная резким увеличением объема данных и расширением бизнеса.
Цели центра обработки данных и озера данных совпадают. Благодаря объединению концепции озера данных система данных и общая архитектура центра обработки данных были оптимизированы и обновлены.
На начальном этапе строительства дата-центра мы интегрировали систему хранилища данных компании, провели углубленное исследование бизнеса, разобрали существующую информацию по полям и измерениям, обобщили измерения согласованности, создали единую систему показателей и сформулировали конструкцию хранилища данных. Характеристики. В соответствии с этой спецификацией мы создали исходный уровень данных (ODS), уровень подробных данных (DWD) и уровень агрегированных данных (MID) единого хранилища данных, а также создали библиотеку устройств, включая накопленную библиотеку устройств и новое устройство. библиотека. На основе единого хранилища данных команда данных построила тематическое хранилище данных и бизнес-рынок на основе различных аналитических и статистических направлений и потребностей бизнеса. Хранилище данных субъекта и бизнес-рынок включают дополнительно обработанные подробные данные, агрегированные данные и таблицы данных прикладного уровня. Прикладной уровень данных использует эти данные для предоставления пользователям различных услуг.
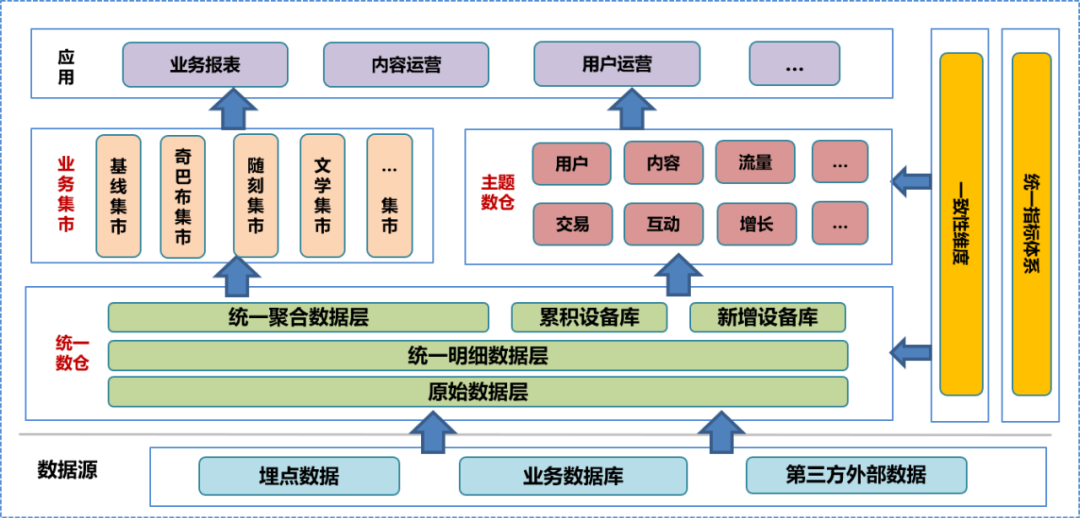
В единой системе хранилища данных исходный уровень данных и
ниже
недоступны для общественности. Пользователи могут использовать инженеров данных только для обработки обработанных данных, поэтому неизбежна потеря некоторых деталей данных.
В повседневной работе пользователи, обладающие возможностями анализа данных, часто хотят получить доступ к исходным необработанным данным для проведения персонализированного анализа или устранения неполадок.
Концепция управления данными озера данных может эффективно решить эту проблему. После внедрения идеи управления данными озера данных мы разобрались и интегрировали существующие ресурсы данных, обогатили и расширили метаданные данных и построили центр метаданных специально для управления центром метаданных.
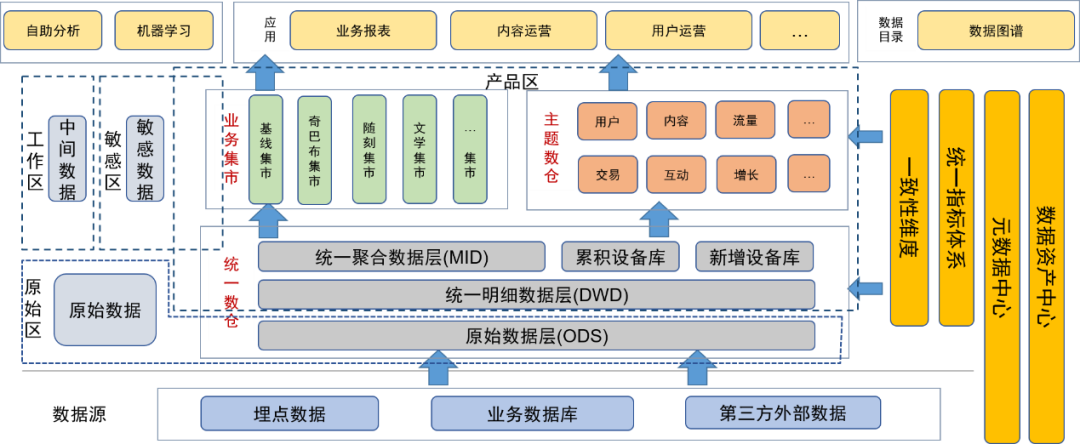
После внедрения концепции озера данных для управления данными мы поместили исходный уровень данных и другие исходные данные (например, исходные файлы журналов) в исходную область данных. Пользователи с возможностями обработки данных могут подать заявку на разрешение на использование данных в этой области.
Подробный уровень, уровень агрегации, хранилище данных темы и бизнес-витрина единого хранилища данных размещаются в области продукта. Эти данные обрабатываются инженерами по обработке данных группы данных и предоставляются пользователям в качестве конечных продуктов данных. в этой области были обработаны управлением данными, поэтому качество данных гарантировано.
Мы также определили конфиденциальные области для конфиденциальных данных и сосредоточились на контроле прав доступа.
Временные таблицы или персональные таблицы, создаваемые ежедневно пользователями и разработчиками данных, размещаются во временной области. Эти таблицы данных являются ответственностью самих пользователей и могут быть открыты для других пользователей при определенных условиях.
Метаданные каждых данных хранятся в центре метаданных, включая информацию о таблицах, информацию о полях, а также измерения и индикаторы, соответствующие полям. В то же время мы также поддерживаем происхождение данных, включая отношения происхождения на уровне таблицы и поля.
Поддерживайте характеристики активов данных через центр обработки данных, включая управление уровнем данных, конфиденциальностью и разрешениями.
Чтобы помочь пользователям лучше использовать данные самостоятельно, мы предоставляем карту данных в качестве каталога данных на уровне приложения, чтобы пользователи могли запрашивать данные, включая метаданные, такие как использование данных, измерения, индикаторы и происхождение. В то же время платформу также можно использовать в качестве портала для подачи заявок на получение разрешений.
Кроме того, мы также предоставляем платформу самообслуживания для анализа, предоставляющую пользователям данных возможности самообслуживания.
Оптимизируя систему данных, мы также обновили архитектуру промежуточной платформы данных на основе концепции озера данных.
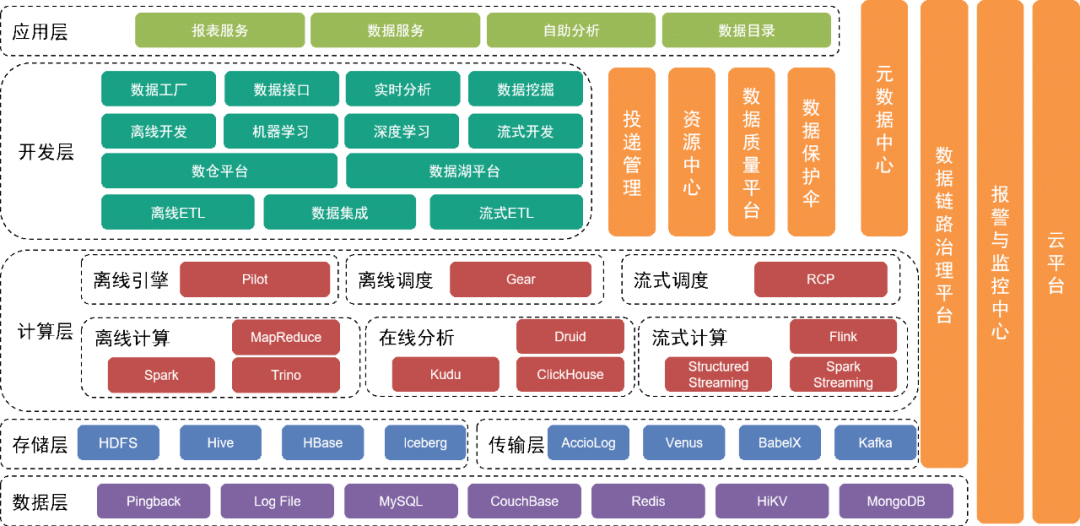
Нижний уровень — это уровень данных , который включает в себя различные источники данных, такие как данные Pingback, которые в основном используются для сбора данных о поведении пользователей. Бизнес-данные хранятся в различных реляционных базах данных и базах данных NoSQL.
Эти данные хранятся на уровне хранения с помощью различных инструментов сбора на транспортном уровне.
Над уровнем данных находится уровень хранения
, который в основном основан на HDFS, распределенной файловой системе, для хранения исходных файлов. Другие структурированные или неструктурированные данные хранятся в Hive, Iceberg или HBase.
Далее находится вычислительный уровень
, который в основном использует автономный механизм Pilot для управления Spark или Trino для автономных вычислений, а также использует механизм планирования Gear offline Workflow Engine для запланированного планирования рабочих процессов. Платформа вычислений реального времени RCP отвечает за планирование потоковых вычислений. После нескольких раундов итераций потоковые вычисления в настоящее время в основном используют Flink в качестве вычислительного механизма.
Уровень разработки над вычислительным уровнем
дополнительно инкапсулирует каждый сервисный модуль вычислительного уровня и уровня передачи, чтобы обеспечить функции для разработки рабочих процессов автономной обработки данных, интеграции данных, разработки рабочих процессов обработки в реальном времени и разработки инженерных реализаций машинного обучения и промежуточных средств. услуги по завершению опытно-конструкторских работ. Платформа озера данных управляет информацией каждого файла данных и таблицы данных в озере данных, а платформа хранилища данных управляет моделью данных хранилища данных, физической моделью, измерениями, индикаторами и другой информацией.
В то же время мы предоставляем различные инструменты и услуги управления по вертикали. Например, инструмент управления доставкой управляет метаинформацией, такой как скрытые спецификации Pingback, поля, словари и сроки доставки, центр метаданных, центр ресурсов и другие модули; используются для ведения таблиц данных или файлов метаинформации и обеспечения безопасности данных. Центр качества данных и платформа управления ссылками контролируют качество данных и состояние создания каналов передачи данных, оперативно уведомляют соответствующие группы о мерах безопасности и быстро реагируют на онлайн-проблемы и сбои. на основе существующих планов.
Базовые услуги предоставляются командой облачных сервисов для обеспечения поддержки частного и публичного облака.
Верхний уровень архитектуры предоставляет карту данных в качестве каталога данных, позволяющую пользователям находить нужные им данные. Кроме того, мы предоставляем приложения самообслуживания, такие как Magic Mirror и Beidou, для удовлетворения потребностей пользователей на разных уровнях в работе с данными самообслуживания.
После преобразования всей архитектурной системы интеграция и управление данными стали более гибкими и комплексными. Мы снижаем порог пользователя за счет оптимизации инструментов самообслуживания, удовлетворения потребностей пользователей на разных уровнях, повышения эффективности использования данных и повышения ценности данных.
Применение технологии озера данных в дата-центре
В широком смысле озеро данных — это концепция управления данными. В узком смысле озеро данных также относится к технологии обработки данных.
Технология озера данных охватывает формат хранения таблиц данных и технологию обработки данных после попадания в озеро.
В отрасли существует три основных решения для хранения данных в озерах: Delta Lake, Hudi и Iceberg. Сравнение этих трех выглядит следующим образом:
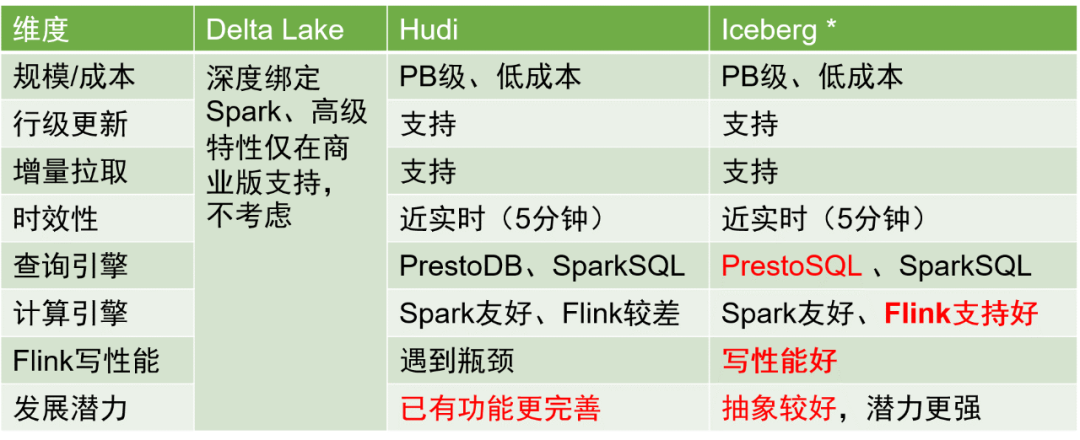
После всестороннего рассмотрения в качестве формата хранения таблицы данных мы выбрали Iceberg.
Iceberg — это формат хранения таблиц, который организует файлы данных в базовой файловой системе или хранилище объектов.
Вот основные сравнения Iceberg и Hive:
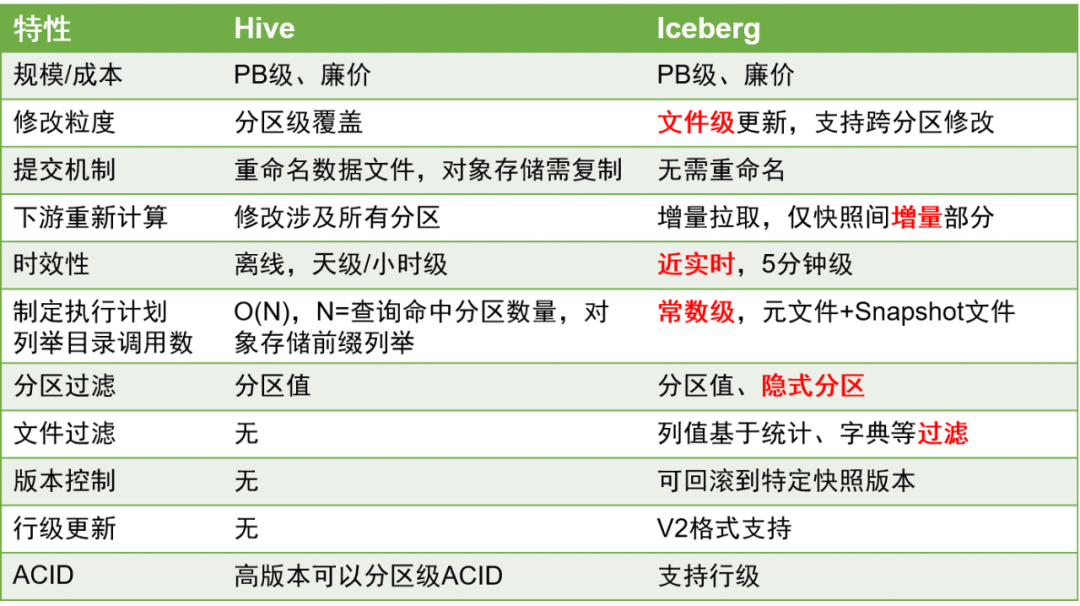
По сравнению с таблицами Hive таблицы Iceberg имеют значительные преимущества, поскольку они лучше поддерживают обновления на уровне строк, а своевременность данных может быть улучшена до минутного уровня.
Это имеет большое значение при обработке данных, поскольку улучшение своевременности данных может значительно повысить эффективность обработки данных ETL.
Таким образом, мы можем легко преобразовать существующую архитектуру Lambda для создания интегрированной архитектуры потоковой и пакетной обработки:
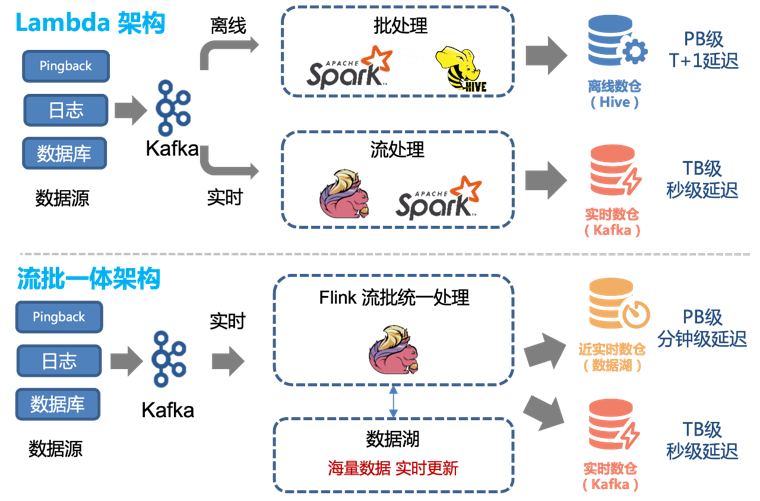
До внедрения технологии озера данных мы использовали комбинацию автономной обработки и обработки в реальном времени, чтобы обеспечить автономное хранилище данных и хранилище данных в реальном времени.
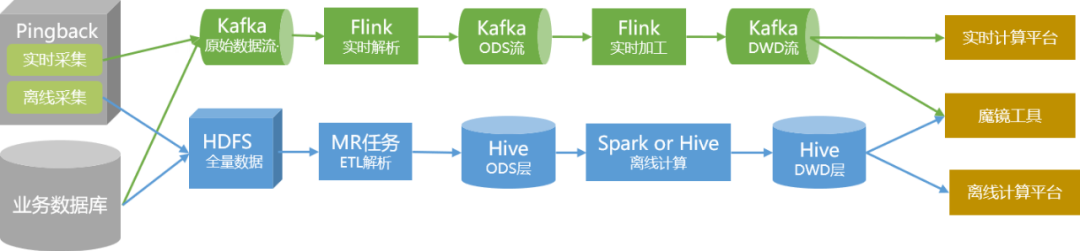
Полный объем данных преобразуется в данные хранилища данных с помощью традиционных методов автономного анализа и обработки
и сохраняется в кластере в виде таблиц Hive.
Для данных с высокими требованиями к работе в реальном времени мы создаем их отдельно через ссылки в реальном времени и предоставляем пользователям в виде тем в Kafka.
Однако эта архитектура имеет следующие проблемы:
-
Два канала, в режиме реального времени и оффлайн, должны поддерживать два разных набора логики кода. Когда логика обработки изменяется, каналы реального времени и автономные каналы необходимо обновлять одновременно, в противном случае произойдет несогласованность данных.
-
Ежечасное обновление оффлайн-ссылок и задержка около 1 часа означают, что данные в 00:01 могут быть запрошены не раньше 02:00. Для некоторых нисходящих сервисов с высокими требованиями к работе в реальном времени это неприемлемо, поэтому необходимо поддерживать каналы связи в реальном времени.
-
Хотя производительность линии реального времени может достигать второго уровня, ее стоимость высока. Большинству пользователей достаточно пятиминутного обновления. В то же время использовать потоки Kafka не так удобно, как напрямую работать с таблицами данных.
Эти проблемы можно лучше решить, используя интегрированный метод обработки данных таблиц Iceberg и потоковых пакетов.

В процессе оптимизации мы в основном выполняли трансформацию Iceberg на таблицах слоя ODS и DWD, а также реконструировали парсинг и обработку данных в задачи Flink.
Чтобы гарантировать, что стабильность и точность создания данных не пострадают в процессе преобразования, мы приняли следующие меры:
1. Начать переключение с непрофильных данных. В зависимости от реальных условий бизнеса мы используем доставку QOS и индивидуальную доставку в качестве пилотных проектов.
2. Путем абстрагирования логики автономного синтаксического анализа формируется единый SDK хранилища синтаксического анализа Pingback, который реализует унифицированное развертывание в режиме реального времени и в автономном режиме и делает код более стандартизированным.
3. После внедрения таблицы Iceberg и нового производственного процесса мы в течение двух месяцев запускали двухканальные параллельные операции и проводили регулярный сравнительный мониторинг данных.
4. Убедившись в отсутствии проблем с данными и продакшеном, выполняем незаметное переключение на верхний уровень.
5. Для данных запуска и воспроизведения, связанных с основными данными, мы проведем интегрированную потоковую передачу и пакетное преобразование после того, как общая проверка станет стабильной.
После трансформации преимущества заключаются в следующем:
1. Качество обслуживания и каналы передачи данных по индивидуальному заказу были реализованы практически в режиме реального времени. Данные с часовой задержкой могут обновляться на пятиминутном уровне.
2. За исключением особых обстоятельств, интегрированная линия потоковой и пакетной передачи может удовлетворить потребности в режиме реального времени. Таким образом, мы можем отключить существующие ссылки в режиме реального времени и ссылки на автономный анализ, связанные с качеством обслуживания и настройкой, тем самым экономя ресурсы.
Благодаря трансформации обработки данных наша ссылка на данные в будущем будет такой, как показано на рисунке ниже:
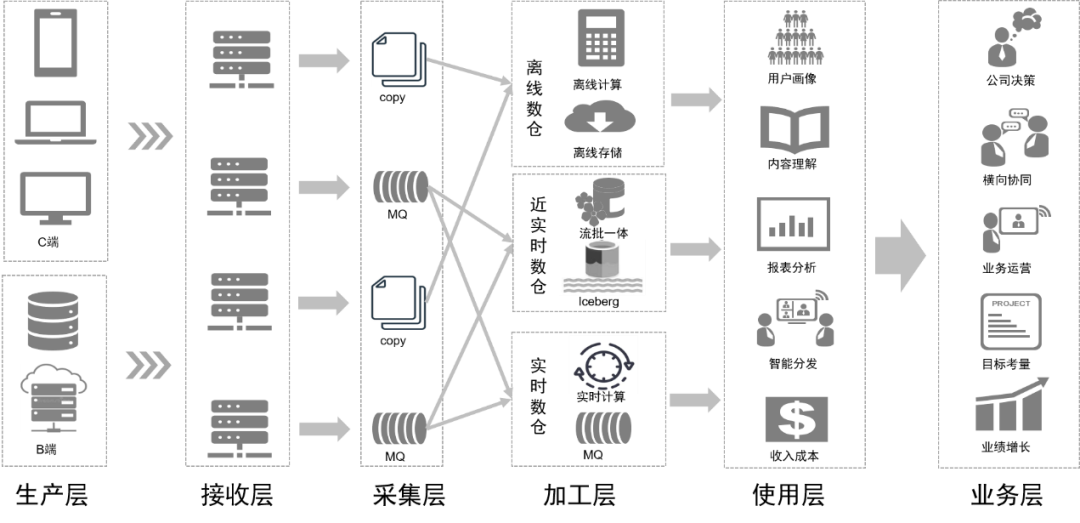
Последующее планирование
Для последующего планирования применения озера данных в дата-центре необходимо учитывать два основных аспекта:
На архитектурном уровне мы продолжим дорабатывать разработку каждого модуля, чтобы сделать данные и услуги, предоставляемые дата-центром, более полными и простыми в использовании, чтобы разные пользователи могли удобно ими пользоваться;
На техническом уровне мы продолжим трансформировать канал передачи данных в потоковую-пакетную интеграцию и в то же время продолжим активно внедрять соответствующие технологии обработки данных для повышения эффективности производства и использования данных и снижения производственных затрат.
6. Алексей Горелик. Корпоративное озеро больших данных.
Может быть, вы тоже хотите увидеть
Эта статья опубликована в общедоступной учетной записи WeChat — iQIYI Technology Product Team (iQIYI-TP).
Если есть какие-либо нарушения, свяжитесь с нами по адресу [email protected] для удаления.
Эта статья участвует в « Плане создания исходного кода OSC ». Вы, кто читаете, можете присоединиться и поделиться ею.
