Как решение для улучшения использования ресурсов и снижения затрат совместное размещение общепризнано в отрасли. В процессе облачной адаптации, снижения затрат и повышения эффективности iQiyi успешно объединила офлайн-вычисления больших данных, обработку аудио- и видеоконтента и другие рабочие нагрузки с онлайн-бизнесом и добилась поэтапного роста. В этой статье основное внимание уделяется большим данным в качестве примера, позволяющего представить практический процесс реализации системы смешанного развертывания от 0 до 1.
фон
Большие данные iQIYI поддерживают такие важные сценарии, как принятие операционных решений, рост числа пользователей, распространение рекламы, видеорекомендации, поиск и членство в компании, обеспечивая управляемый данными механизм для бизнеса. По мере роста потребностей бизнеса объем требуемых вычислительных ресурсов увеличивается с каждым днем, а контроль затрат и обеспечение ресурсами сталкиваются с все большим давлением.
Вычисления больших данных iQIYI разделены на два канала обработки данных: автономные вычисления и вычисления в реальном времени, среди которых:
-
Автономные вычисления включают обработку данных на основе Spark, построение хранилища данных на уровне часа или даже дня на основе Hive, а также соответствующий запрос и анализ отчетов. Этот тип вычислений обычно начинается рано утром каждого дня для расчета данных предыдущего дня и заканчивается. утро. . 0–8 часов каждый день — пиковый период потребности в вычислительных ресурсах. Общие ресурсы кластера часто недостаточны, а задачи часто ставятся в очередь и задерживаются. В течение дня наблюдается большое количество простоев, что приводит к большим простоям. пустая трата ресурсов.
-
Вычисления в реальном времени включают обработку потока данных в реальном времени, представленную Kafka + Flink, которая имеет относительно стабильные требования к ресурсам.
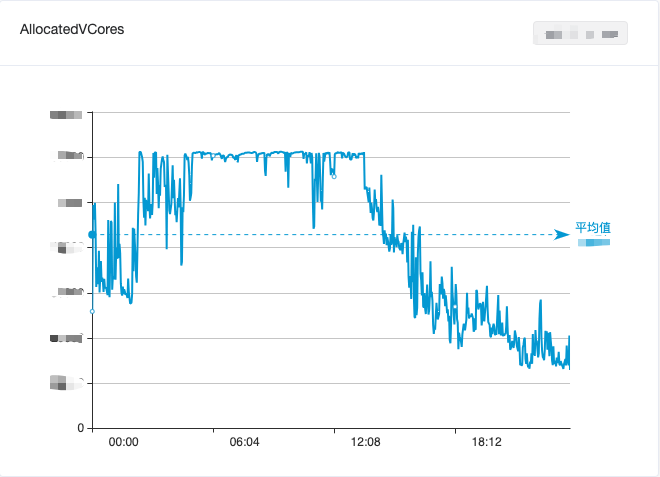
Чтобы сбалансировать использование ресурсов больших данных, мы объединили офлайн-вычисления и вычисления в реальном времени, что в определенной степени уменьшило неактивную трату ресурсов в течение дня. Однако по-прежнему не удавалось эффективно сокращать пики и заполнять провалы. и общее использование вычислительных ресурсов больших данных по-прежнему показало: «Приливное явление «дневного минимума и раннего утреннего пика» показано на рисунке 1.
Рисунок 1. Изменение использования ЦП кластера вычислений больших данных за один день
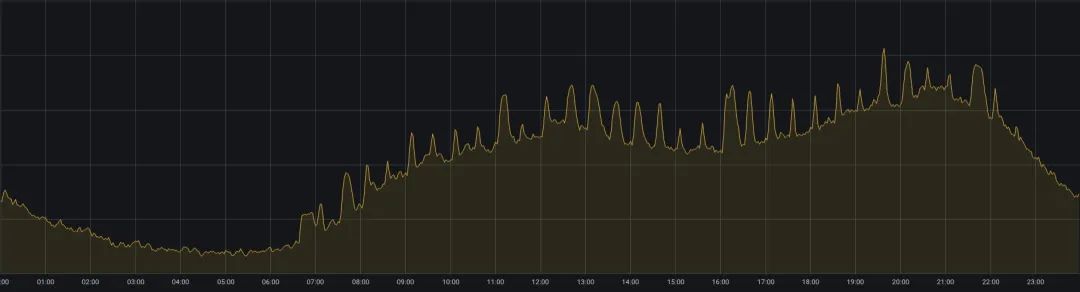
Онлайн-бизнес iQiyi сталкивается с еще одной проблемой: балансом между качеством обслуживания и использованием ресурсов. Интернет-бизнес в основном обслуживает такие сценарии, как воспроизведение видео iQiyi. Больше пользователей смотрят видео в полдень и вечером, а использование ресурсов имеет приливный характер: «пики в течение дня и спады ранним утром» (как показано на рисунке 2). . Чтобы обеспечить качество обслуживания в периоды пиковой нагрузки, онлайн-бизнес обычно резервирует больше ресурсов, что делает их использование очень неудовлетворительным.
Рисунок 2. Изменение использования ЦП онлайн-бизнес-кластера за один день
Чтобы улучшить использование, контейнерная платформа предыдущего поколения, разработанная iQiyi, приняла стратегию статического резервирования ЦП. Хотя этот метод оказывает значительное влияние на улучшение использования, он ограничен такими факторами, как возможности ядра, и не может избежать перебоев между службами на одном компьютере. Периодические проблемы с конкуренцией ресурсов также приводили к нестабильному качеству онлайн-бизнес-услуг, и эта проблема так и не была решена должным образом.
С развитием облачной нативизации контейнерная платформа iQiyi постепенно трансформировалась в технологический стек Kubernetes (далее «K8s»). В последние годы в сообществе K8s появилось множество проектов с открытым исходным кодом, связанных с совместным развертыванием, а также в отрасли существуют некоторые практики совместного развертывания [1] . На этом фоне команда вычислительной платформы скорректировала направление работы со «статического овербукинга» на «динамическое овербукинг + смешанное развертывание».
Как наиболее типичный оффлайн-бизнес, большие данные являются пионером в попытках реализовать совместное размещение. С одной стороны, большие данные имеют большой объем и относительно стабильные требования к вычислительным ресурсам; с другой стороны, бизнес с большими данными и онлайн-бизнес могут достичь взаимодополняющих эффектов во многих измерениях, а использование ресурсов может быть полностью улучшено за счет совместного размещения.
На основании приведенного выше анализа команда вычислительной платформы iQiyi и команда больших данных начали изучать возможность совместного размещения.
Смешанный дизайн плана расположения
Система больших данных iQiyi построена на базе экосистемы Apache Hadoop с открытым исходным кодом и использует YARN в качестве системы планирования вычислительных ресурсов. Интернет-бизнес построен на K8s. Как соединить две разные системы планирования ресурсов — это первое, что необходимо решить. решение совместного размещения.
В отрасли обычно существуют два совмещенных решения:
-
Вариант 1. Запускайте задания больших данных напрямую (Spark, Flink и т. д., MapReduce не поддерживается) на K8s и используйте собственный планировщик.
-
Вариант 2. Запустите NodeManager YARN (далее «NM») на K8, и задания больших данных по-прежнему планируются через YARN.
После тщательного рассмотрения мы выбрали второй вариант по двум основным причинам:
-
В настоящее время подавляющее большинство задач по обработке больших данных в компании планируются на основе YARN. YARN имеет мощные функции планирования (мультитенантная многоочередность, осведомленность о стойках), отличную производительность планирования (более 5 тыс. контейнеров в секунду) и полноценные механизмы безопасности. (Kerberos, токены делегирования) и поддерживает практически все платформы обработки больших данных, такие как MapReduce, Spark и Flink. С момента внедрения YARN в 2014 году команда iQiyi по работе с большими данными создала вокруг нее ряд платформ для разработки, эксплуатации и обслуживания, управления вычислениями и т. д., предоставляя внутренним пользователям удобный процесс разработки больших данных. Поэтому совместимость с YARN API является одним из важных факторов при выборе гибридного решения.
-
Хотя в K8s есть пакетный планировщик, он недостаточно развит, и существует узкое место в производительности планирования (<1 тыс. контейнеров/с), чего недостаточно для поддержки потребностей сценариев с большими данными.
На уровне K8s обеим сторонам необходим набор стандартных интерфейсов для управления и использования ресурсов совместного размещения. В сообществе есть много отличных проектов, таких как Koordinator с открытым исходным кодом от Alibaba [2], FinOps-проект Tencent с открытым исходным кодом Crane [3], проект с открытым исходным кодом ByteDance Katalyst [4] и т. д. Среди них Koordinator обладает «естественной» адаптируемостью к операционной системе Dragon Lizard (одна из альтернатив CentOS, которую пробует iQiyi) и может сотрудничать для обеспечения онлайн-мониторинга бизнес-нагрузки, чрезмерного использования ресурсов в режиме ожидания, иерархического планирования задач и гарантии качества обслуживания автономной рабочей нагрузки. и т. д., удовлетворяющие потребности iQiyi.
Основываясь на вышеупомянутом выборе технологии, посредством глубокой трансформации мы поместили YARN NM в контейнер и запустили его в модуле K8s и можем воспринимать динамически изменяющиеся вычислительные ресурсы Координатора с высоким разрешением в режиме реального времени, тем самым достигая автоматического горизонтального и вертикального расширения и сжатия, а также максимальное использование смешанных ресурсов.
Эволюция стратегии совместного планирования
Совместное размещение больших данных и онлайн-бизнеса прошло несколько этапов технологической эволюции, о которых мы подробно расскажем ниже.
Этап 1. Мультиплексирование с разделением времени в ночное время.
Чтобы быстро проверить решение, мы сначала завершили преобразование контейнеризации NM на K8s Pod (Kordinator на этом этапе не использовался) и расширили его на существующий кластер Hadoop в качестве эластичного узла. На уровне больших данных эти NM K8s равномерно планируются YARN вместе с NM на других физических машинах. Эти эластичные узлы регулярно запускаются и останавливаются каждый день и работают только с 0 до 9 часов.
На данном этапе мы выполнили более 20 ремонтов. Вот 5 основных пунктов ремонта:
Пункт улучшения 1: фиксированный пул IP-адресов.
Традиционный NM развертывается на физической машине, а IP-адрес и доменное имя машины фиксированы. Белый список узлов (файл подчиненных устройств) настраивается в YARN ResourceManager (далее именуемый «RM»), чтобы позволить узлу присоединиться к сети. кластер. В то же время кластер YARN использует Kerberos для реализации аутентификации безопасности. Перед развертыванием файл keytab необходимо создать в Kerberos KDC и распространить на узел NM.
Чтобы адаптироваться к белому списку и механизму аутентификации безопасности YARN, мы используем самостоятельно разработанную функцию статического IP-адреса для самостоятельно созданных кластеров. Каждый статический IP-адрес будет иметь соответствующий ресурс K8s StaticIP для одновременной записи соответствующих отношений между Pod и IP. В настоящее время он основан на общедоступном облаке. Мы также развернем в кластере самостоятельно разработанный StaticIP CRD и создадим ресурсы StaticIP для каждого статического IP-адреса, тем самым предоставив YARN фиксированный пул IP-адресов, который будет использоваться так же, как и самостоятельно созданный кластер. . Заранее создайте записи DNS и файлы таблиц ключей на основе IP-адресов в пуле фиксированных IP-адресов, чтобы можно было быстро получить необходимую конфигурацию при запуске NM.
Точка преобразования 2: Оператор Elastic YARN
Чтобы пользователи не знали о введении эластичных узлов, мы добавили эластичный NM в существующий кластер Hadoop YARN. Принимая во внимание сложность динамически осведомленных ресурсов в более поздних смешанных развертываниях, мы выбрали самостоятельно разработанный оператор Elastic YARN, чтобы лучше управлять жизненным циклом эластичного NM.
На этом этапе оператор Elastic YARN поддерживает следующие стратегии:
-
按需启动:应对离线任务的突发流量,包括寒暑假、节假日、重要活动等场景
-
周期性上下线:利用在线服务每天凌晨的资源利用率低谷期,运行大数据任务
改造点 3:Node Label - 弹性与固定资源隔离
由于 Flink 等大数据实时流计算任务是 7x24 小时不间断常驻运行的,对 NM 的稳定性的要求比批处理更高,弹性 NM 节点的缩容或资源量调整会使得流计算任务重启,导致实时数据波动。为此,我们引入了 YARN Node Label 特性 [5],将集群分为固定节点(物理机 NM)和弹性节点(K8s NM)。批处理任务可以使用任意节点,流任务则只能使用固定节点运行。
此外,批处理任务容错的基础在于 YARN Application Master 的稳定性。我们的解决方案是,给 YARN 新增了一个配置,用于设置 Application Master 默认使用的 label,确保 Application Master 不被分配到弹性 NM 节点上。这一功能已经合并到社区:
YARN-11084
、
YARN-11088
。
改造点 4:NM Graceful Decommission
我们采用了弹性节点固定时间上下线,来对在离线资源进行削峰填谷。弹性 NM 的上线由 YARN Operator 来启动,一旦启动完成,任务就可被调度上。弹性 NM 的下线则略微复杂些,因为任务仍然运行在上面,我们需要尽可能保证任务在下线的时间区间内已经结束。
例如我们周期性部署策略为:0 - 8 点弹性 NM 上线,8 - 9 点为下线时间区间,9 - 24 点为节点离线状态。通过使用 YARN graceful decommission [6] 的机制,将增量 container 请求避免分配到 decommissioning 的节点上,在下线时间区间内等待任务缓慢结束即可。
但是在我们集群中,批处理任务大部分是 Spark 3.1.1 版本,因为 Spark 申请的 YARN container 是作为 task 的 executor 来使用,在大部分情况下,1 个小时的下线区间往往是不够的。因此我们引入了 SPARK-20624 的一系列优化 [7],通过 executor 响应 YARN decommission 事件来将 executor 尽可能快速退出。
改造点 5:引入 Remote Shuffle Service - Uniffle
Shuffle 作为离线任务中的重要一环,我们采用 Spark ESS on NodeManager 的部署模式。但在引入弹性节点后,因为弹性 NM 生命周期短,无法保证在 YARN graceful decommmission 的时间区间内,任务所在节点的 shuffle 数据被消费完,导致作业整体失败。
基于这一点,我们引入了 Apache Uniffle (incubating) [8] 实现 remote shuffle service 来解耦 Spark shuffle 数据与 NM 的生命周期,NM 被转变为单纯的计算,不存储中间 shuffle 数据,从而实现 NM 快速平滑下线。
另外一方面,弹性 NM 挂载的云盘性能一般,无法承载高 IO 和高并发的随机读写,同时也会对在线服务产生影响。通过独立构建高性能 IO 的 Uniffle 集群,提供更快速的 shuffle 服务。
爱奇艺作为 Uniffle 的深度参与者,贡献了 100+ 改进和 30+ 特性,包括 Spark AQE 优化 [9] 、Kerberos 的支持 [10] 和超大分区优化 [11] 等。
阶段二:资源超分
在阶段一,我们仅使用 K8s 资源池剩余未分配资源实现了初步的混部。为了最大限度地利用空闲资源,我们引入 Koordinator 进行资源的超分配。
我们对弹性 NM 的资源容量采用了固定规格限制:10 核 batch-cpu、30 GB batch-memory(batch-cpu 和 batch-memory 是 Koordinator 超分出来的扩展资源),NM 保证离线任务使用的资源总量不会超过这些限制。
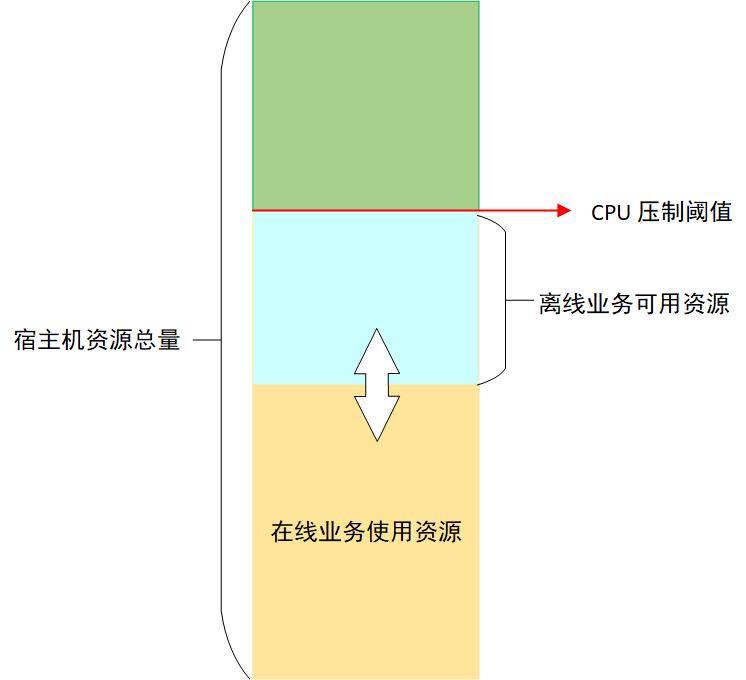
为了保证在线业务的稳定性,Koordinator 会对节点上离线任务能够使用的 CPU 进行压制 [12],压制结果由压制阈值和在线业务 CPU 实际用量(不是 request 请求)的差值决定,这个差值就是离线业务能够使用的最大 CPU 资源,由于在线业务 CPU 实际使用量不断变化,所以离线业务能够使用的 CPU 也在不断变化,如图 3 所示:
对离线任务的 CPU 压制保证了在线业务的稳定性,但是离线任务执行时间就会被拉长。如果某个节点上离线任务被压制程度比较严重,就可能会导致等待的发生,从而拖慢整体任务的运行速度。为了避免这种情况,Koordinator 提供了基于 CPU 满足度的驱逐功能 [13],当离线任务使用的 CPU 被压制到用户指定的满足度以下时,就会触发离线任务的驱逐。离线任务被驱逐后,可以调度到其他资源充足的机器上运行,避免等待。
在经过一段时间的测试验证后,我们发现在线业务运行稳定,集群 CPU 7 天平均利用率提升了 5%。但是节点上的 NM Pod 被驱逐的情况时有发生。NM 被驱逐之后,RM 不能及时感知到驱逐情况的发生,会导致失败的任务延迟重新调度。为了解决这个问题,我们开发了 NM 动态感知节点离线 CPU 资源的功能。
阶段三:从夜间分时复用到全天候实时弹性
与其触发 Koordinator 的驱逐操作,不如让 NM 主动感知节点上离线资源的变化,在离线资源充足时,调度较多任务,离线资源不足时,停止调度任务,甚至主动杀死一些离线 container 任务,避免 NM 被 Koordinator 驱逐。
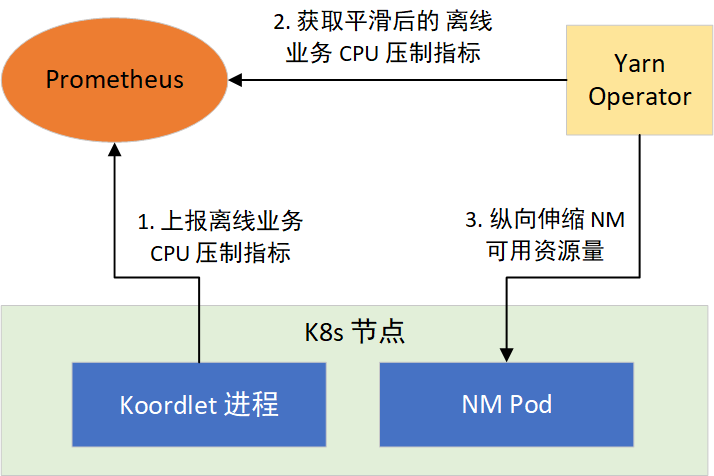
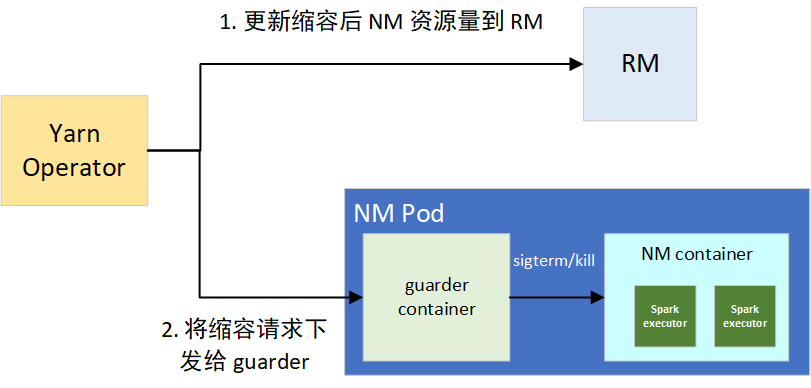
根据这个思路,我们通过 YARN Operator 动态感知节点所能利用的资源,来纵向伸缩 NM 可用资源量。分两步实现:1)提供离线任务 CPU 压制指标;2)让 NM 感知 CPU 压制指标,采取措施。如图 4 所示:
CPU 压制指标
Koordinator 的 Koordlet 组件,运行于 K8s 的节点上,负责执行离线任务 CPU 压制、Pod 驱逐等操作,它以 Prometheus 格式提供了 CPU 压制指标,经过采集后就可以通过 Prometheus 对外提供。CPU 压制指标默认每隔 1 秒更新 1 次,会随着在线业务负载的变化而变化,波动较大。而 Prometheus 的指标抓取周期一般都大于 1 秒,这会造成部分数据的丢失,为了平滑波动,我们对 Koordlet 进行了修改,提供了 1 min、5 min、10 min CPU 压制指标的均值、方差、最大值和最小值等指标供 NM 选择使用。
YARN Operator 动态感知和纵向伸缩
在 NM 常驻的部署模式下,YARN Operator 提供了新的策略。通过在 YARN Operator 接收到当前部署的节点 10 min 内可利用的资源指标,用来决策是否对所在宿主机上的 NM 进行纵向伸缩。
对于扩容,一旦超过 3 核,则向 RM 进行节点的资源更新。扩容过程如图 5 所示:
缩容的话,如果抑制率控制在 10% 以内的波动,我们默认忽略。一旦超过阈值,则会触发缩容操作,分为两个步骤:1)更新节点在 RM 上的可用资源,用来堵住增量的 container 分配需求;2)将缩容请求下发给 NM 的 guarder sidecar 容器,来对部分资源超用的 container 的平滑和强制下线,避免因占用过多 CPU 资源导致整个 NM 被驱逐。
guarder 在拿到目标可用资源后,会对当前所有的 YARN container 进程进行排序,包括框架类型、运行时长、资源使用量三者,决策拿到要 kill 的进程。在 kill 前,会进行 SIGPWR 信号的发送,用来平滑下线任务,Spark Executor 接收到此信号,会尽可能平滑退出。缩容过程如图 6 所示:
通常节点的资源量变动幅度不是很大,且 NM 可使用的资源量维持在较高的水平(平均有 20 core),部分 container 的存活周期为 10 秒级,因此很快就能降至目标可用资源量值。涉及到变动幅度频繁的节点,通过 guarder 的平滑下线和 kill 决策,container 失败数非常低,从线上来看,按天统计平均 force kill container 数目为 5 左右,guarder 发送的平滑下线信号有 500+,可以看到效果比较好。
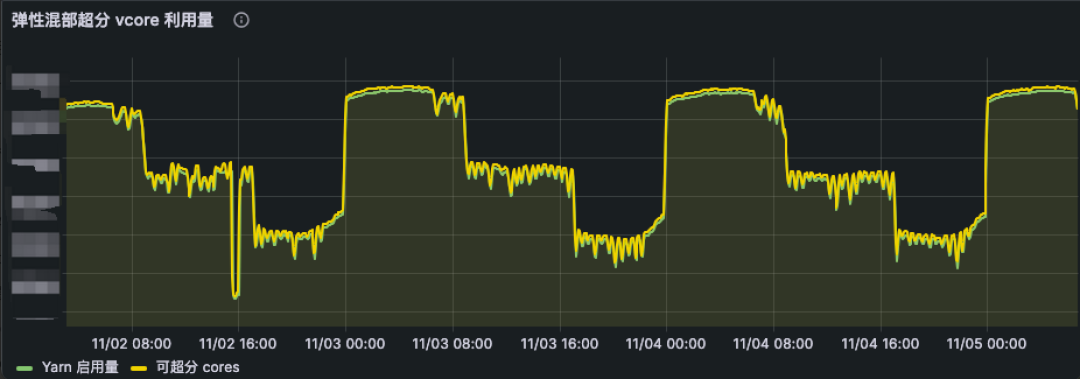
在离线 CPU 资源感知功能全面上线后,NM Pod 被驱逐的情况基本消失。因此,我们逐步将混部时间由凌晨的 0 点至 8 点,扩展到全天 24h 运行,并根据在线业务负载分布情况,在一天的不同时段采用不同的 CPU 资源超分比,从而实现全天候实时弹性调度策略。伴随着全天 24h 的稳定运行,集群 CPU 利用率再度提升了 10%。从线上混部 K8s 集群来看(如图 7 所示),弹性 NM 的 vcore 使用资源量(绿线)也是动态贴合可超分的资源(黄线)。
阶段四:提升资源超分率
为了提供更多的离线资源,我们开始逐步调高 CPU 资源的超分比,而 NM Pod 被驱逐的情况再次发生了,这一次的原因是内存驱逐。我们将物理机器的内存超分比设置为 90%,从集群总体情况看,物理机器上的内存资源比较充足,刚开始我们只关注了 CPU 资源,没有关注内存资源。而 NM 的 CPU 和内存按照 1:4 的比例来使用,随着 CPU 超分比的提高,YARN 任务需要的内存也在提升,最终当 K8s 节点内存使用量超过设定的阈值时,就会触发 Koordinator 的驱逐操作。
经过观察,我们发现内存驱逐在某些节点上发生的概率特别高,这些节点的内存比其他节点内存小,而 CPU 数量是相同的,因此这些节点在 CPU 超分比相同的情况下,更容易因为内存原因被驱逐,它们能提供的离线内存更少。因此,guarder 容器也需要感知节点的离线内存资源用量,并根据资源用量采取相应的措施,这个过程与 CPU 离线资源的感知一样的,不再赘述。
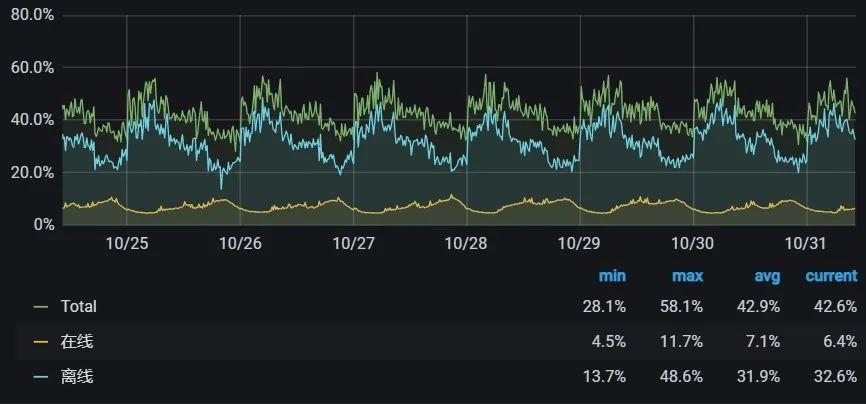
内存感知功能上线后,我们又逐步提升了 CPU 的超分比,当前在线业务集群的 CPU 利用率已经提升到全天平均 40%+、夜间 58% 左右。
效果
通过大数据离线计算与在线业务的混部,我们将在线业务集群 CPU 平均利用率从 9% 提升到 40%+,在不增加机器采购的同时满足了部分大数据弹性计算的资源需求,每年节省数千万元成本。
同时,我们也将这套框架应用到大数据 OLAP 分析场景,实现了 Impala/Trino on K8s 弹性架构,满足数据分析师日常动态查询需求,支持了寒暑假、春晚直播、广告 618 与双 11 等重要活动期间临时大批量资源扩容需求,保障了广告、BI、会员等数据分析场景的稳定、高效。
未来计划
当前,大数据离在线混部已稳定运行一年多,并取得阶段性成果,未来我们将基于这套框架进一步推进大数据云原生化:
-
完善离在线混部可观测性:建立精细化的 QoS 监控,保障在线服务、大数据弹性计算任务的稳定性。
-
加大离在线混部力度:K8s 层面,继续提高宿主机资源利用率,提供更多的弹性计算资源供大数据使用。大数据层面,进一步提升通过离在线混部框架调度的弹性计算资源占比,节省更多成本。
-
大数据混合云计算:目前我们主要使用爱奇艺内部的 K8s 进行混部,随着公司混合云战略的推进,我们计划将混部推广到公有云 K8s 集群中,实现大数据计算的多云调度。
-
探索云原生的混部模式:尽管复用 YARN 的调度器能让我们快速利用混部资源,但它也带来了额外的资源管理和调度开销。后续我们也将探索云原生的混部模式,尝试将大数据的计算任务直接使用 K8s 的离线调度器进行调度,进一步优化调度速度和资源利用率。
参考资料
[1] 一文看懂业界在离线混部技术. https://www.infoq.cn/article/knqswz6qrggwmv6axwqu
[2] Koordinator: QoS-based Scheduling for Colocating on Kubernetes. https://koordinator.sh/
[3] Crane: Cloud Resource Analytics and Economics in Kubernetes clusters. https://gocrane.io/
[4] Katalyst: a universal solution to help improve resource utilization and optimize the overall costs in the cloud. https://github.com/kubewharf/katalyst-core
[5] Apache Hadoop YARN - Node Labels. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeLabel.html
[6] Apache Hadoop YARN - Graceful Decommission of YARN Nodes. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/GracefulDecommission.html
[7] Apache Spark - Add better handling for node shutdown. https://issues.apache.org/jira/browse/SPARK-20624
[8] Apache Uniffle: Remote Shuffle Service. https://uniffle.apache.org/
[9] Apache Uniffle - Support getting memory data skip by upstream task ids. https://github.com/apache/incubator-uniffle/pull/358
[10] Apache Uniffle - Support storing shuffle data to secured dfs cluster. https://github.com/apache/incubator-uniffle/pull/53
[11] Apache Uniffle - Huge partition optimization. https://github.com/apache/incubator-uniffle/issues/378
[12] Koordinator - CPU Suppress. https://koordinator.sh/docs/user-manuals/cpu-suppress/
[13] Koordinator - Eviction Strategy based on CPU Satisfaction. https://koordinator.sh/docs/user-manuals/cpu-evict/

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。