
01
назадсценаи статус-кво
1. Характеристики данных в рекламной сфере
Данные в сфере рекламы можно разделить на признаки непрерывной В отличие от изображений AI, видео, голоса и других полей , исходные данные в рекламном поле в основном представлены в виде идентификатора, такого как идентификатор пользователя, рекламный идентификатор, последовательность рекламных идентификаторов, взаимодействующих с пользователем и т. д., а также идентификатор. Масштаб велик, образуя рекламное поле. Отличительные характеристики многомерных разреженных данных.
-
Существуют как статические (например, возраст пользователя), так и динамические характеристики, основанные на поведении пользователя (например, количество раз, когда пользователь нажимает на рекламу в определенной отрасли). -
Преимущество в том, что он имеет хорошую способность к обобщению. Предпочтения пользователя в отношении отрасли можно распространить на других пользователей, имеющих такие же статистические характеристики отрасли. -
Недостатком является то, что отсутствие памяти приводит к низкой дискриминации. Например, два пользователя с одинаковыми статистическими характеристиками могут иметь существенные различия в поведении. Кроме того, функции с непрерывным значением также требуют большого количества ручного проектирования функций.
-
Дискретнозначные функции являются мелкозернистыми функциями. Есть перечислимые (например, пол пользователя, идентификатор отрасли), а есть и многомерные (например, идентификатор пользователя, рекламный идентификатор). -
Преимущество в том, что у него сильная память и высокая различимость. Функции дискретных значений также можно комбинировать для изучения перекрестной и совместной информации. -
Недостатком является то, что способность к обобщению относительно слаба.
-
Горячее кодирование -
Встраивание функций (Внедрение)
-
Конфликт функций: если словарь_size установлен слишком большим, эффективность обучения резко упадет, и обучение завершится неудачно из-за нехватки памяти. Таким образом, даже для функций дискретного значения идентификатора пользователя на уровне миллиарда мы настроим пространство хэша идентификатора только в 100 000 уровней. Частота конфликтов хэша высока, информация о функциях повреждена, и нет никакой положительной выгоды от автономной оценки. -
Неэффективный ввод-вывод: поскольку такие функции, как идентификатор пользователя и рекламный идентификатор, являются многомерными и разреженными, то есть параметры, обновляемые во время обучения, составляют лишь небольшую часть от общего числа. В соответствии с исходным статическим механизмом внедрения TensorFlow необходимо обрабатывать доступ к модели. Весь плотный тензор потребует огромных затрат на ввод-вывод и не сможет поддерживать обучение разреженных больших моделей.
02
Редкая реклама, крупная модельная практика
-
API TFRA совместим с экосистемой Tensorflow (повторное использование исходного оптимизатора и инициализатора, API имеет то же имя и единообразное поведение), что позволяет TensorFlow поддерживать обучение и вывод разреженных больших моделей ID-типа более естественным способом; Стоимость обучения и использования невелика и не меняет привычек моделирования инженеров-алгоритмов. -
Динамическое расширение и сжатие памяти экономит ресурсы во время обучения, что эффективно позволяет избежать конфликтов хеш-функций и гарантирует сохранение информации о функциях без потерь.
-
Статическое внедрение обновляется до динамического внедрения: для искусственной хеш-логики функций дискретных значений динамическое внедрение TFRA используется для хранения, доступа и обновления параметров, тем самым гарантируя, что внедрение всех функций дискретных значений является бесконфликтным в структуре алгоритма и обеспечение того, чтобы все дискретные значения изучались без потерь. -
Использование функций многомерного разреженного идентификатора. Как упоминалось выше, при использовании статической функции внедрения TensorFlow функции идентификатора пользователя и рекламного идентификатора не приносят никакой пользы при автономной оценке из-за конфликтов хэша. После обновления структуры алгоритма вновь вводятся функции идентификатора пользователя и рекламного идентификатора, что дает положительные преимущества как в автономном режиме, так и в Интернете. -
Использование многомерных разреженных комбинированных функций идентификатора: введение комбинированных функций дискретного значения идентификатора пользователя и рекламного общего идентификатора, таких как комбинация идентификатора пользователя с отраслевым идентификатором и именем пакета приложения соответственно. В то же время в сочетании с функцией доступа к функциям вводятся отдельные функции, использующие комбинацию более редких идентификаторов пользователей и рекламных идентификаторов.

2. Обновление модели
-
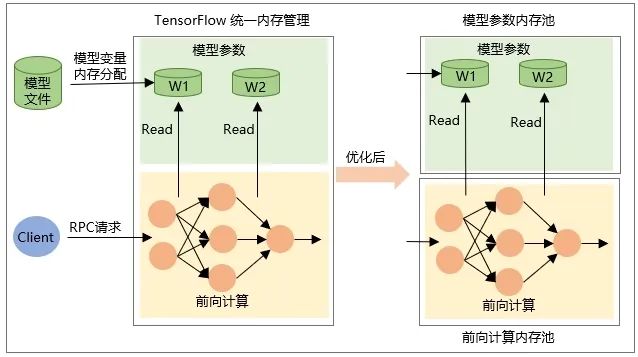
Выделение самой переменной Tensor при восстановлении модели, то есть память выделяется при загрузке модели, а память освобождается при выгрузке модели. -
Память промежуточного выходного тензора выделяется во время прямого расчета сети во время запроса RPC и освобождается после завершения обработки запроса.
03
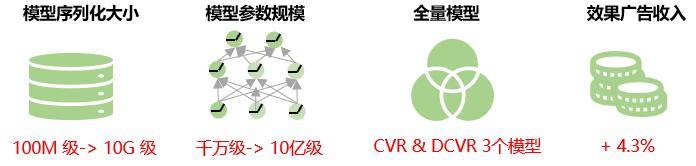
общая выгода
04
прогноз на будущее
В настоящее время всем значениям одной и той же функции в большой рекламной разреженной модели присваивается одно и то же измерение внедрения. В реальном бизнесе распределение данных многомерных функций крайне неравномерно, на очень небольшое количество высокочастотных функций приходится очень высокая доля, а явление «длинного хвоста» является серьезным; использование фиксированных размеров внедрения для всех значений функций; уменьшит возможность обучения внедрению представлений. То есть для низкочастотных функций размерность внедрения слишком велика, и существует риск переобучения модели для высокочастотных функций, поскольку существует огромное количество информации, которую необходимо представить и изучить, встраивание; Размер слишком мал, и модель может оказаться неподходящей. Поэтому в будущем мы будем изучать способы адаптивного изучения измерения функции внедрения, чтобы еще больше повысить точность прогнозирования модели.
В то же время мы рассмотрим решение инкрементального экспорта модели, то есть загружать в TensorFlow Serving только те параметры, которые изменяются во время инкрементального обучения, тем самым сокращая время сетевой передачи и загрузки во время обновления модели, достигая обновлений на минутном уровне. разреженных больших моделей и улучшение характера модели в реальном времени.

Раскрытие секрета взрыва памяти: решение ООМ-проблемы распределенного обучения больших моделей
Процесс оптимизации двойного назначения ставок iQIYI Performance Advertising
Эта статья опубликована в общедоступной учетной записи WeChat — iQIYI Technology Product Team (iQIYI-TP).
Если есть какие-либо нарушения, свяжитесь с нами по адресу [email protected] для удаления.
Эта статья участвует в « Плане создания исходного кода OSC ». Вы, кто читаете, можете присоединиться и поделиться ею.
{{o.name}}
{{m.name}}