фонпредставлять
Графические процессоры в настоящее время широко используются в платформе глубокого обучения iQiyi. Графический процессор имеет сотни или тысячи вычислительных ядер и может выполнять большое количество инструкций параллельно, что делает его очень подходящим для вычислений, связанных с глубоким обучением. Графические процессоры широко используются в моделях CV (компьютерное зрение) и NLP (обработка естественного языка). По сравнению с процессорами они обычно могут выполнять обучение модели и делать выводы быстрее и экономичнее.
Модель CTR (Click Trough Rate) широко используется в рекомендациях, рекламе, поиске и других сценариях для оценки вероятности того, что пользователь нажмет на рекламу или видео. Графические процессоры широко использовались в сценарии обучения модели CTR, что повышает скорость обучения и снижает необходимые затраты на сервер.
Но в сценарии вывода, когда мы напрямую развертываем обученную модель на графическом процессоре с помощью сервиса Tensorflow, мы обнаруживаем, что эффект вывода не идеален. появляется в:
-
Задержка вывода высока. Модели типа CTR обычно ориентированы на конечного пользователя и очень чувствительны к задержке вывода.
-
Загрузка графического процессора низкая, а вычислительная мощность не используется полностью.
Анализ причин
инструмент анализа
-
Tensorflow Board, инструмент, официально предоставляемый tensorflow, может визуально просматривать затраты времени на каждом этапе графика потока вычислений и суммировать общие затраты времени операторов.
-
Nsight — это набор инструментов разработки, предоставляемый NVIDIA для разработчиков CUDA. Он может выполнять относительно низкоуровневое отслеживание, отладку и анализ производительности программ CUDA.
Заключение анализа
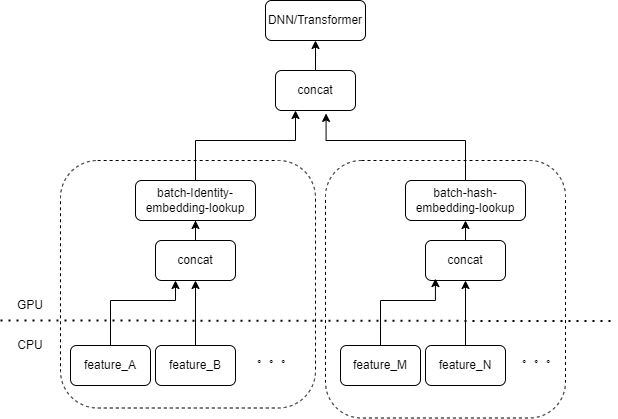
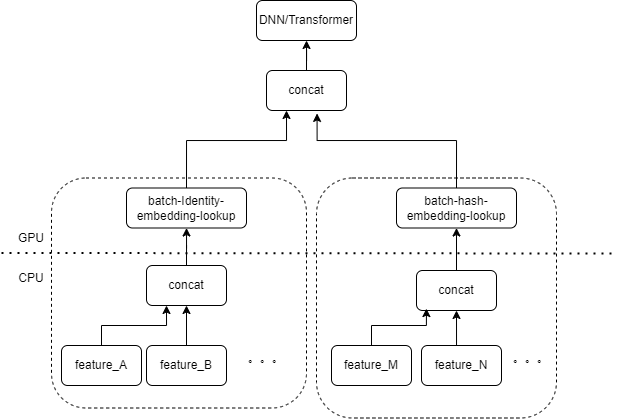
Типичные входные данные модели CTR содержат большое количество разрозненных функций (таких как идентификатор устройства, идентификатор недавно просмотренного видео и т. д.). FeatureColumn Tensorflow будет обрабатывать эти функции. Сначала выполняются операции идентификации/хеширования для получения индекса таблицы внедрения. После внедрения операций поиска и усреднения получается соответствующий тензор внедрения. После объединения тензоров внедрения, соответствующих нескольким признакам, получается новый тензор, который затем входит в последующие DNN/Transformer и другие структуры.
Таким образом, каждый разреженный объект активирует несколько операторов на входном слое модели. Каждому оператору будет соответствовать один или несколько вычислений GPU, то есть ядра cuda. Каждое ядро cuda включает в себя два этапа: запуск ядра cuda (накладные расходы, необходимые для запуска ядра) и выполнение ядра (фактически выполнение матричных вычислений на ядре cuda). Оператор, соответствующий поиску идентификатора/хеша/встраивания разреженного объекта, требует небольшого объема вычислений, а запуск ядра часто занимает больше времени, чем время выполнения ядра. Вообще говоря, модель CTR содержит от десятков до сотен редких функций, и теоретически будут сотни ядер запуска, что в настоящее время является основным узким местом производительности.
Эта проблема не возникала при использовании графического процессора для обучения модели CTR. Поскольку обучение само по себе является автономной задачей и не учитывает задержки, размер пакета во время обучения может быть очень большим. Хотя запуск ядра по-прежнему будет выполняться несколько раз, пока количество выборок, рассчитанных при выполнении ядра, достаточно велико, среднее время, затрачиваемое на каждый образец запуска ядра, будет очень небольшим. Для сценариев онлайн-вывода, если Tensorflow Serving требуется для получения достаточного количества запросов на вывод и объединения пакетов перед выполнением вычислений, задержка вывода будет очень высокой.
Оптимизация
Наша цель — оптимизировать производительность без существенного изменения кода обучения или инфраструктуры сервиса. Мы, естественно, думаем о двух методах: уменьшении количества запускаемых ядер и повышении скорости запуска ядра.
Объединение операторов
Основная операция — объединение нескольких последовательных операций или операторов в один оператор. С одной стороны, это может уменьшить количество запусков ядра cuda, с другой стороны, некоторые промежуточные результаты в процессе вычислений могут храниться в регистрах или совместно использоваться. памяти, и только в расчете. В конце подраздела результаты расчета записываются в глобальную память cuda.
-
Автоматическое объединение на основе компилятора глубокого обучения
-
Ручное объединение операторов для бизнеса
автоматическая сварка
Мы опробовали различные компиляторы глубокого обучения, такие как TVM/TensorRT/XLA, и в реальных тестах можно добиться объединения небольшого количества операторов в DNN, таких как непрерывный MatrixMat/ADD/Relu. Поскольку TVM/TensorRT необходимо экспортировать промежуточные форматы, такие как onnx, необходимо изменить онлайн-процесс исходной модели. Поэтому мы используем tf.ConfigProto(), чтобы включить встроенный XLA тензорного потока для слияния.
Однако автоматическое слияние не оказывает хорошего эффекта на операторов, связанных с редкими объектами.
Ручное объединение операторов
Мы, естественно, думаем, что если на входном слое есть несколько функций, обрабатываемых одной и той же комбинацией FeatureColumn, то мы можем реализовать оператор для объединения входных данных нескольких функций в массив в качестве входных данных оператора. Выходные данные оператора представляют собой тензор, и форма этого тензора соответствует форме тензора, полученного путем отдельного вычисления исходных признаков и их последующего объединения.
Взяв в качестве примера исходную комбинацию IdentityCategoricalColumn + EmbeddingColumn, мы реализовали оператор BatchIdentiyEmbeddingLookup для достижения той же логики вычислений.
Чтобы облегчить использование изучающих алгоритмы, мы инкапсулировали новый FusedFeatureLayer для замены собственного FeatureLayer. Помимо включения оператора слияния также реализована следующая логика:
-
Объединенная логика действует во время вывода, а исходная логика используется во время обучения.
-
Объекты необходимо сортировать, чтобы гарантировать, что объекты одного типа можно расположить вместе.
-
Поскольку входные данные каждого объекта имеют переменную длину, здесь мы генерируем дополнительный индексный массив, чтобы отметить, какому признаку принадлежит каждый элемент входного массива.
В бизнесе для достижения эффекта интеграции необходимо заменить только исходный FeatureLayer.
Запусковое ядро, которое изначально тестировалось сотни раз, после ручного слияния сократилось до менее чем 10 раз. Затраты на запуск ядра значительно сокращаются.
MultiStream повышает эффективность запуска
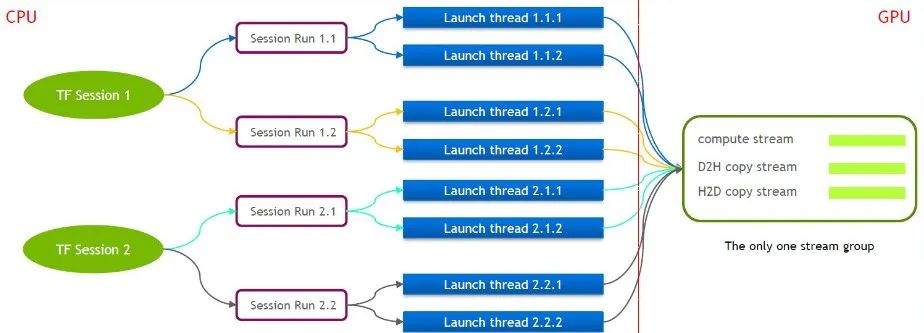
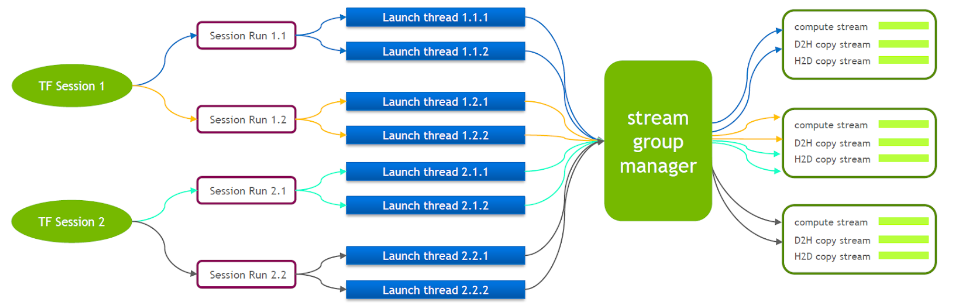
Сам TensorFlow представляет собой однопоточную модель, содержащую только одну группу потоков Cuda (состоящую из вычислительного потока, потока H2D, потока D2H и потока D2D). Несколько ядер могут выполняться только последовательно в одном и том же вычислительном потоке, что неэффективно. Даже если ядро cuda запускается через несколько сеансов тензорного потока, на стороне графического процессора все равно требуется организация очереди.
По этой причине техническая команда NVIDIA поддерживает собственную ветку Tensorflow для поддержки одновременного выполнения нескольких групп потоков. Это используется для повышения эффективности запуска ядра cuda. Мы портировали эту функцию в наш сервис Tensorflow.
Когда запущен Tensorflow Serving, необходимо включить Nvidia MPS, чтобы уменьшить взаимное влияние между несколькими контекстами CUDA.
Оптимизация небольшого копирования данных
На основе предыдущей оптимизации мы дополнительно оптимизировали небольшую копию данных. После того как Tensorflow Serving десериализует значения каждой функции из запроса, он несколько раз вызывает cudamemcpy для копирования данных с хоста на устройство. Количество вызовов зависит от количества функций.
Для большинства CTR-сервисов фактически установлено, что при небольшом размере пакета будет более эффективно сначала объединить данные на стороне хоста, а затем сразу вызвать cudamemcpy.
Объединить пакеты
В сценарии с графическим процессором необходимо включить пакетное слияние. По умолчанию Tensorflow Serving не объединяет запросы. Чтобы лучше использовать возможности параллельных вычислений графического процессора, в одно прямое вычисление можно включить больше выборок. Мы включили опцию Enable_batching в Tensorflow Serving во время выполнения для пакетного объединения нескольких запросов. В то же время вам необходимо предоставить пакетный файл конфигурации, сосредоточив внимание на настройке следующих параметров. Ниже приведены некоторые из наших опытов.
-
max_batch_size: максимальное количество запросов, разрешенное в пакете, которое может быть немного больше.
-
atch_timeout_micros: максимальное время ожидания объединения пакета. Даже если номер пакета не достигает max_batch_size, он будет рассчитан немедленно (теоретически, чем выше требование к задержке, тем меньше значение здесь). Лучше всего установить значение Менее 5 миллисекунд.
-
num_batch_threads: Максимальное количество одновременных потоков вывода. После включения MPS его можно установить от 1 до 4. Увеличение количества вызовов увеличит задержку.
Здесь следует отметить, что большинство разреженных функций, входных в модель класса CTR, являются функциями переменной длины. Если клиент не заключает специального соглашения, длина определенной функции может быть несовместимой в нескольких запросах. Tensorflow Serving имеет логику заполнения по умолчанию, которая дополняет соответствующие функции нулями для более коротких запросов. Для функций переменной длины -1 используется для обозначения нуля. Заполнение по умолчанию, равное 0, фактически изменит смысл исходного запроса.
Например, идентификатор последнего просмотренного видео пользователем A — [3,5], а идентификатор последнего просмотренного видео пользователем B — [7,9,10]. Если выполнение по умолчанию выполнено, запрос принимает вид [[3,5,0], [7,9,10]]. При последующей обработке модель будет думать, что А недавно просмотрел 3 видео с идентификаторами 3, 5, 0. .
Поэтому мы изменили логику завершения ответа Tensorflow Serving. В этом случае логика завершения будет [[3,5,-1], [7,9,10]]. Смысл первой строчки всё равно в том, что были просмотрены 3 и 5 видео.
конечный эффект
После различных вышеупомянутых оптимизаций задержка и пропускная способность удовлетворили наши потребности, и это было реализовано в рекомендуемых персонализированных службах потоковой передачи push и водопада. Результаты бизнеса следующие:
-
Пропускная способность увеличена более чем в 6 раз по сравнению с нативным графическим контейнером Tensorflow.
-
Задержка в основном такая же, как у процессора, что соответствует потребностям бизнеса.
-
При поддержке того же QPS стоимость снижается более чем на 40%
Может быть, вы тоже хотите увидеть
Эта статья опубликована из общедоступной учетной записи WeChat — группы продуктов iQIYI Technology (iQIYI-TP).
Если есть какие-либо нарушения, свяжитесь с нами по адресу [email protected] для удаления.
Эта статья участвует в « Плане создания исходного кода OSC ». Вы, кто читаете, можете присоединиться и поделиться ею.