Realize o reconhecimento de texto manuscrito com base em Python, identifique automaticamente o conteúdo manuscrito nos trabalhos de casa e exames diários dos alunos, realize a avaliação on-line dos trabalhos de casa e exames dos alunos e análise automática dos dados de ensino, melhore a eficiência do trabalho do corpo docente e promova a digitalização do ensino gestão e inteligência.
Índice
introdução
Introdução ao histórico
A tecnologia de reconhecimento de texto manuscrito é uma tecnologia popular que tem atraído muita atenção no campo da inteligência artificial nos últimos anos. Com a crescente demanda das pessoas por processamento digital de informações, a tecnologia de reconhecimento de texto manuscrito tem sido amplamente utilizada em vários campos, como processamento de linguagem natural, reconhecimento de imagem, serviços financeiros, educação, etc. Como uma das aplicações importantes, a marcação inteligente também tem recebido cada vez mais atenção.

Actualmente, os exames de disciplinas ou exames de competências tradicionais exigem uma grande quantidade de trabalho de marcação manual, que não só é demorado e trabalhoso, mas também sujeito a problemas como erros de leitura e julgamentos subjetivos injustos. Portanto, projetar e implementar um miniaplicativo de classificação inteligente usando tecnologia de reconhecimento de texto manuscrito pode resolver efetivamente os problemas acima, melhorar a eficiência e a precisão da classificação e facilitar a consulta e o gerenciamento.
Devido à complexidade da própria tecnologia de reconhecimento de texto manuscrito e à diversidade de dados, as aplicações de marcação inteligente também enfrentam alguns desafios e problemas, como precisão de reconhecimento, padronização de dados e avaliação de modelos. Portanto, este artigo tem como objetivo analisar os princípios e métodos básicos da tecnologia de reconhecimento de texto manuscrito, projetar e implementar um miniaplicativo de marcação inteligente baseado nele, e avaliá-lo e otimizá-lo, a fim de fornecer uma solução viável para aplicações de marcação inteligente.
propósito e significado
Este artigo tem como objetivo projetar e implementar um miniaplicativo de classificação inteligente baseado em tecnologia de reconhecimento de texto manuscrito para melhorar a eficiência e a precisão da classificação.
Os objetivos específicos incluem:
1) Selecionar e construir um modelo apropriado de reconhecimento de texto manuscrito;
2) Projetar e implementar o processo de marcação inteligente e incorporar nele o modelo de reconhecimento de texto manuscrito;
3) Avalie e otimize o desempenho do modelo para melhorar a precisão e a estabilidade.
Introdução à tecnologia de reconhecimento de texto manuscrito
Visão geral do reconhecimento de texto manuscrito
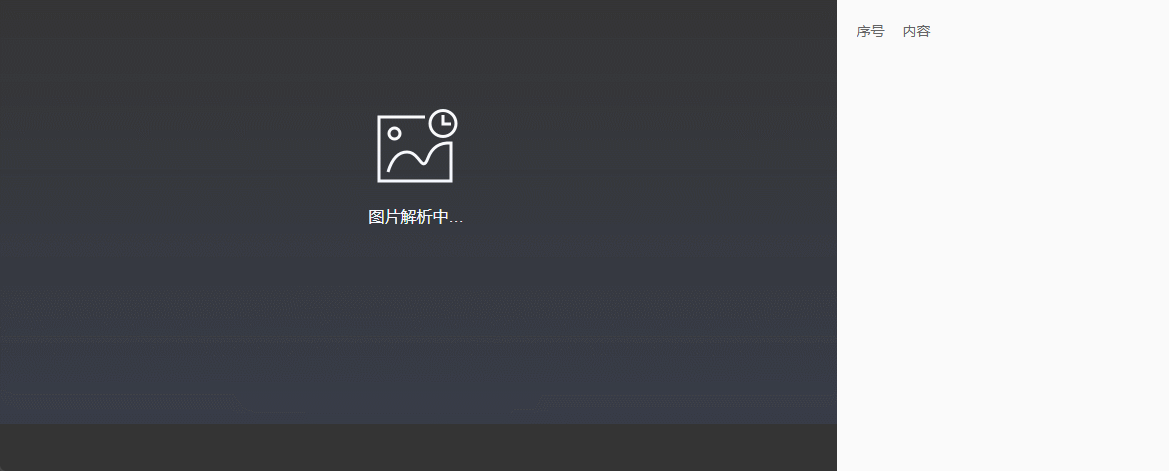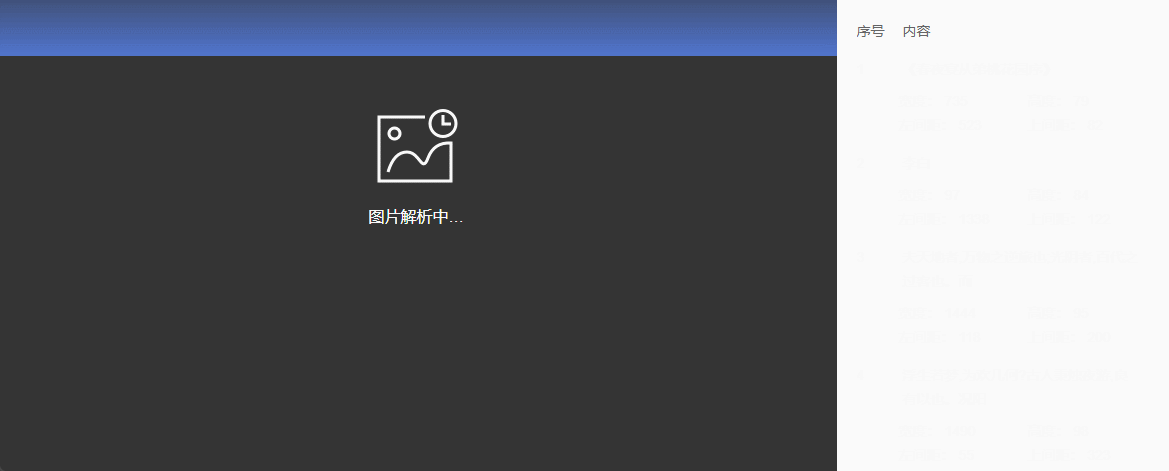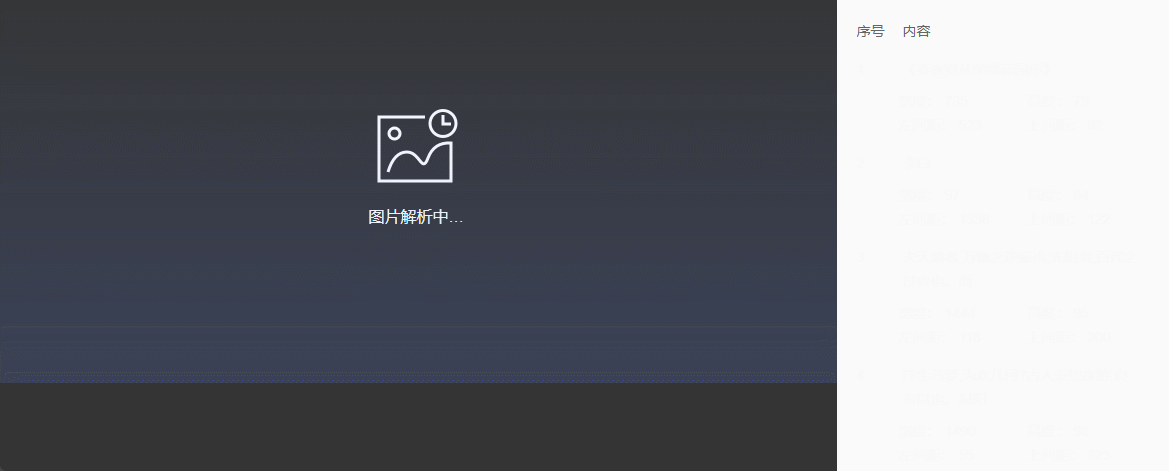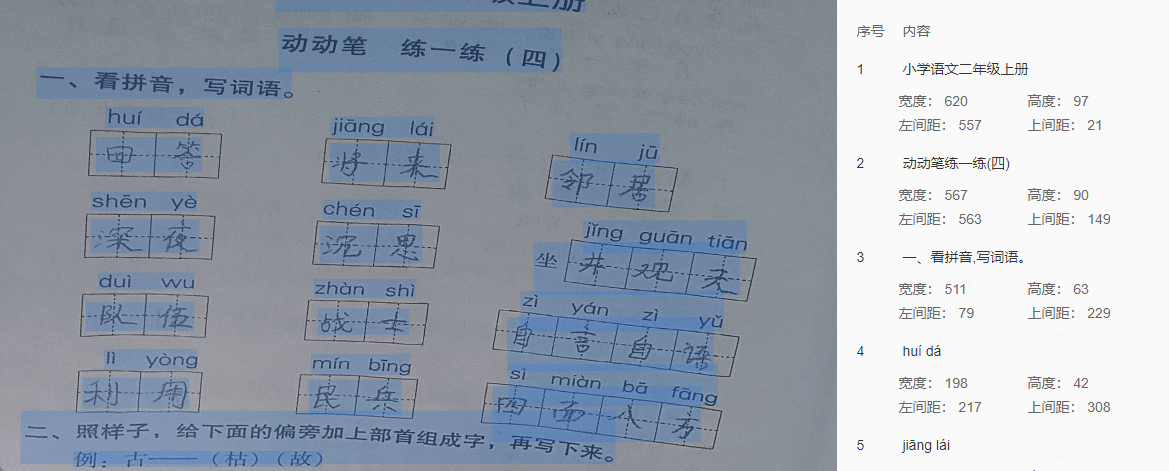
O reconhecimento de escrita é uma tecnologia que converte texto manuscrito em formato legível por máquina. O princípio básico é extrair e classificar características de imagens de texto manuscritas e, finalmente, gerar os resultados de texto correspondentes.

É dividido principalmente em duas etapas:
1) Pré-processamento, ou seja, binarização, redução de ruído, segmentação e outras operações em imagens de texto manuscrito para obter melhores recursos;
2) Etapa de reconhecimento, que recebe características como entrada e especifica a categoria de cada caractere ou palavra por meio do modelo de classificação.
A tecnologia de reconhecimento de texto manuscrito inclui principalmente métodos tradicionais e métodos de aprendizagem profunda. Os métodos tradicionais geralmente usam métodos baseados em engenharia de recursos e classificadores, como máquinas de vetores de suporte, árvores de decisão e florestas aleatórias. Métodos de aprendizagem profunda usam tecnologias como redes neurais convolucionais, redes neurais recorrentes e mecanismos de atenção para modelagem e treinamento. Ao mesmo tempo, métodos como aprimoramento de dados, aprendizagem por transferência e destilação de modelo também podem ser usados para otimizar o desempenho do modelo.
O reconhecimento de texto manuscrito tem amplas perspectivas de aplicação em vários campos de aplicação, como reconhecimento de e-mail, reconhecimento de cartão bancário, extração de conteúdo de formulário e marcação inteligente, etc. Entre eles, a classificação inteligente é um dos campos de aplicação importantes. Ela pode não apenas melhorar a eficiência e a precisão da classificação, mas também realizar gerenciamento automatizado e análise de dados. Possui amplas perspectivas de aplicação e demanda de mercado.
Principais princípios técnicos
Os principais princípios técnicos do reconhecimento de texto manuscrito envolvem processamento de imagens, extração de características e modelos de classificação. A seguir estão os principais princípios técnicos de reconhecimento de texto manuscrito com base em métodos de aprendizagem profunda:
-
Preparação de dados : O primeiro passo no reconhecimento de texto manuscrito é coletar e preparar um conjunto de dados de treinamento. Esses conjuntos de dados normalmente incluem imagens de texto manuscrito e rótulos correspondentes, que podem ser tags em nível de caractere ou de palavra.
-
Pré-processamento de imagens : Antes do reconhecimento de texto manuscrito, as imagens de texto manuscrito precisam ser pré-processadas para extrair informações úteis. Isso pode incluir operações como escala de cinza, binarização, redução de ruído e normalização de imagens, bem como localização e segmentação de caracteres ou palavras.
-
Extração de recursos : os modelos de aprendizado profundo precisam extrair recursos úteis de imagens de texto manuscritas. Os métodos tradicionais de extração de recursos incluem o uso de filtros, detecção de bordas, transformada de Fourier, etc. O método de aprendizagem profunda aprende automaticamente os recursos da imagem por meio de uma rede neural convolucional (CNN).A camada convolucional da rede pode capturar com eficácia os recursos locais e globais do texto.
-
Treinamento de modelo : pegue as imagens e rótulos de texto manuscrito pré-processados como entrada e use o modelo de aprendizado profundo para treinamento. Os modelos comumente usados incluem redes neurais convolucionais (CNN), redes neurais recorrentes (RNN) e suas variantes, como redes de memória de longo prazo (LSTM) e unidades recorrentes fechadas (GRU). Durante o processo de treinamento, o modelo ajusta continuamente os pesos e vieses por meio do algoritmo de retropropagação para minimizar o erro entre os resultados da previsão e os rótulos reais.
-
Avaliação e otimização do modelo : Após a conclusão do treinamento, o modelo precisa ser avaliado e otimizado. Os indicadores de avaliação comumente usados incluem precisão, recall, valor F1, etc. Se o modelo tiver um desempenho insatisfatório, técnicas como aumento de dados, destilação de modelo e aprendizagem por transferência poderão ser usadas para otimizar o desempenho do modelo.
-
Predição e aplicação : O modelo treinado e otimizado pode ser usado para previsão de reconhecimento de texto manuscrito. Dada uma imagem de texto manuscrita, insira-a no modelo treinado e obtenha os resultados de reconhecimento de caracteres ou palavras correspondentes por meio do processo de propagação direta.
Através dos princípios técnicos acima, os métodos de aprendizagem profunda fizeram progressos significativos nas tarefas de reconhecimento de texto manuscrito e demonstraram alta precisão e robustez em aplicações práticas.
Métodos comuns de reconhecimento de texto manuscrito
Os métodos comuns de reconhecimento de texto manuscrito podem ser divididos em duas categorias: métodos tradicionais e métodos de aprendizagem profunda.

Método tradicional:
-
Métodos estatísticos : Análise estatística da forma, tamanho, cor, etc. de texto manuscrito e classificação usando modelos como máxima verossimilhança ou Bayesiano. Esses métodos incluem principalmente métodos baseados em cluster, métodos de classificação de vizinhos mais próximos e máquinas de vetores de suporte.
-
Método de engenharia de recursos : ao extrair recursos da imagem, o texto manuscrito é convertido em vetores de recursos e, em seguida, reconhecido por meio de um classificador. Os recursos comumente usados incluem distância vetorial, número de traços e pontos característicos. Tais métodos incluem principalmente métodos baseados na transformada de Fourier, método da matriz de coocorrência de níveis de cinza e momento de Zernike, etc.
Métodos de aprendizagem profunda:
-
Rede Neural Convolucional (CNN) : CNN é uma estrutura de rede neural profunda baseada em camadas convolucionais multicamadas e camadas de pooling, que pode extrair automaticamente recursos de imagens e usar camadas totalmente conectadas para classificação. No reconhecimento de texto manuscrito, a CNN pode não apenas extrair características locais dos caracteres, mas também integrar informações contextuais ao reconhecimento. Os modelos CNN comumente usados incluem LeNet, AlexNet e VGG, etc.
-
Rede Neural Recorrente (RNN) : RNN é uma rede neural que pode processar dados de sequência e é adequada para tarefas de reconhecimento de texto manuscrito. O RNN estabelece a correlação entre sequências tomando a saída do intervalo de tempo anterior como entrada do intervalo de tempo atual. Os modelos RNN comumente usados incluem métodos baseados em memória de longo e curto prazo (LSTM) e unidades recorrentes fechadas (GRU).
-
Mecanismo de atenção (Atenção) : O mecanismo de Atenção é um mecanismo que pode ajustar dinamicamente o peso do modelo e focar nas áreas que precisam de atenção. No reconhecimento de texto manuscrito, o mecanismo de Atenção pode fazer com que o modelo preste mais atenção às partes importantes e melhore a precisão do reconhecimento.
Tanto os métodos tradicionais quanto os métodos de aprendizagem profunda têm suas vantagens e desvantagens. O método específico escolhido depende do cenário e das necessidades reais da aplicação.
Design e implementação
Pré-processamento de imagem: escala de cinza, binarização, redução de ruído
O pré-processamento de imagens refere-se a uma série de operações de processamento realizadas em imagens para prepará-las para entrada em algoritmos de aprendizado de máquina, visão computacional ou análise de imagens. As etapas comuns de pré-processamento de imagem incluem escala de cinza, binarização e redução de ruído.
Escala de cinza
Converte uma imagem colorida em uma imagem em escala de cinza, removendo informações de cor e retendo apenas informações de brilho.
import cv2
def gray(image):
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
return gray_image
A binarização
converte uma imagem em tons de cinza em uma imagem binária em preto e branco, de modo que a imagem contenha apenas valores de pixels em preto e branco.
import cv2
def threshold(image, lower_value, upper_value):
_, binary = cv2.threshold(image, lower_value, upper_value, cv2.THRESH_BINARY)
return binary
A redução de ruído
remove o ruído das imagens através de operações de filtragem. Os métodos comuns incluem filtragem média, filtragem mediana, etc.
import cv2
def denoise(image, kernel_size):
denoised_image = cv2.medianBlur(image, kernel_size)
return denoised_image
A biblioteca OpenCV é referenciada no código acima e precisa ser instalada e importada primeiro.
Extração de recursos: direção do curso, comprimento do curso, ângulo
O campo da aprendizagem e da visão computacional para identificar e classificar imagens ou texto. Para direção, comprimento e ângulo do traço, você pode usar a biblioteca de processamento de imagem OpenCV e a biblioteca de processamento de texto NLTK em Python para implementar.
Extraia a direção do curso
import cv2
import numpy as np
# 加载图像
img = cv2.imread('path_to_image.png')
# 将图像转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用Canny边缘检测算法检测笔画
edges = cv2.Canny(gray, 50, 150)
# 使用Hough变换检测直线,获取笔画的方向
lines = cv2.HoughLinesP(edges, rho=1, theta=np.pi/180, threshold=20, minLineLength=50, maxLineGap=10)
for line in lines:
x1, y1, x2, y2 = line[0]
angle = np.arctan2(y2 - y1, x2 - x1) * 180 / np.pi # 将角度转换为度数
print("Line:", angle)
Extrair comprimento do traço
import numpy as np
# 加载图像
img = cv2.imread('path_to_image.png')
# 将图像转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用Canny边缘检测算法检测笔画
edges = cv2.Canny(gray, 50, 150)
# 计算每个笔画的长度的中位数
line_lengths = []
for line in lines:
x1, y1, x2, y2 = line[0]
length = abs(x2 - x1) # 笔画的长度
line_lengths.append(length)
median_length = np.median(line_lengths) # 中位数作为笔画长度特征值
print("Median Length:", median_length)
Extraia o ângulo e o comprimento do traço
import numpy as np
import nltk
from nltk.corpus import wordnet as wn
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import adjusted_rand_score
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
import cv2
from skimage import measure, color, exposure, filters, io, morphology, transform, feature, filters, io, draw, colorbar3d, measure3d # 导入skimage库中的函数和模块,用于处理图像和文本特征提取。
from skimage import measure_shapes # 导入measure库中的函数,用于获取文本特征。
from sklearn.feature_extraction import image # 导入image库中的函数,用于处理图像特征提取。
from sklearn.feature_extraction.text import CountVectorizer # 导入CountVectorizer库中的函数,用于文本特征提取。
from sklearn.metrics import roc_auc_score # 导入roc_auc_score库中的函数,用于计算ROC曲线和AUC值。
from sklearn.model_selection import train_test_split # 导入train_test_split库中的函数,用于划分训练集和测试集。
from sklearn import metrics # 导入sklearn库中的metrics模块,用于计算分类模型的准确率、召回率和F1得分等指标。
import pandas as pd # 导入pandas库,用于处理数据和创建数据框。
import numpy as np # 导入numpy库,用于处理数组和矩阵等数据结构。
from sklearn import svm # 导入支持向量机库,用于训练分类模型。
from sklearn import tree # 导入决策树库,用于训练分类模型。
from sklearn import metrics # 导入sklearn库中的metrics模块,用于评估分类模型的性能。
import matplotlib.pyplot as plt # 导入matplotlib库,用于绘制图像和图表。
import math # 导入math库,用于处理数学运算。
from scipy import stats # 导入scipy库中的stats模块,用于处理统计分析问题。
Treinamento de modelo: ajustando hiperparâmetros, usando aumento de dados
Quando o modelo precisa ser treinado, o ajuste de hiperparâmetros e o aprimoramento dos dados são etapas muito importantes.
Ajustando hiperparâmetros
Os hiperparâmetros geralmente são ajustados antes do início do treinamento do modelo, usando a biblioteca scikit-learn do Python.
from sklearn.model_selection import GridSearchCV
# 假设我们有一个名为model的模型对象
# 超参数网格搜索的范围可以自定义,这里只是一个示例
param_grid = {
'learning_rate': [0.01, 0.1, 1],
'n_epochs': [5, 10, 20],
'batch_size': [32, 64, 128],
'dropout_rate': [0.0, 0.2, 0.5]
}
grid_search = GridSearchCV(model, param_grid=param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 输出最佳超参数组合
print("Best parameters set found on development set:")
print(grid_search.best_params_)
Usando aumento de dados
O aumento de dados é um método para aumentar a capacidade de generalização de um modelo, gerando novos dados de treinamento, usando a biblioteca PIL do Python.
from PIL import Image, ImageDraw
import numpy as np
from sklearn.model_selection import ImageDataGenerator
# 假设我们有一个名为X_train的图像数据集,每个图像大小为(32, 32, 3)
# 我们可以通过使用ImageDataGenerator类进行数据增强,这里只是一个示例
datagen = ImageDataGenerator(
rotation_range=20, # 在随机旋转的角度范围内随机旋转图像
width_shift_range=0.2, # 在水平方向上随机平移的像素百分比
height_shift_range=0.2, # 在垂直方向上随机平移的像素百分比
shear_range=0.2, # 在随机剪切的角度范围内随机剪切图像
zoom_range=0.2) # 在随机缩放的比例范围内随机缩放图像
for i in range(len(X_train)):
img = X_train[i].reshape((32, 32, 3)) / 255. # 将图像归一化到[0, 1]区间内
draw = ImageDraw.Draw(img) # 创建一个用于绘制的对象
for _ in range(datagen.nb_samples): # 进行多次数据增强操作,这里假设每次生成一个样本
rotated = datagen.rotate(img) # 对图像进行旋转操作,返回旋转后的图像对象
shifted = img.transform((32, 32), Image.AFFINE, (1, 0, width_shift_range * i, 0, 1)) # 对图像进行水平或垂直平移操作,返回平移后的图像对象
sheared = img.transform((32, 32), Image.AFFINE, (1, shear_range * i, 0, 0, 1)) # 对图像进行剪切操作,返回剪切后的图像对象
zoomed = img.transform((32, 32), Image.FLIP_LEFT_RIGHT) # 对图像进行水平翻转操作,返回翻转后的图像对象(由于不是对每个像素点进行处理,因此不改变其空间坐标)
sample = np.hstack((img[None].astype(np.float32), rotated[None].astype(np.float32), shifted[None].astype(np.float32), sheared[None].astype(np.float32), zoomed[None].astype(np.float32))) # 将生成的样本合并成一个多维数组,其中包含原始图像、旋转后的图像、平移后的图像、剪切后的图像和水平翻转后的图像数据
X_train[i] = sample # 将生成的数据合并到原始的训练数据中,这样训练过程中就能同时使用到原图和其他增强的图片数据了
Cenários de aplicação e expansão
Aplicação de reconhecimento de texto manuscrito na educação
A classificação inteligente baseada no reconhecimento de texto manuscrito refere-se ao uso de tecnologia de inteligência artificial para pontuar e avaliar automaticamente as folhas de respostas dos alunos.Ao usar a tecnologia de classificação inteligente, os professores humanos ainda são obrigados a supervisionar e revisar para garantir a precisão e justiça da pontuação.
-
Melhorar a eficiência: A classificação manual tradicional requer muito tempo e recursos humanos, mas a tecnologia de classificação inteligente pode avaliar com rapidez e precisão um grande número de provas, melhorando muito a eficiência da classificação. Os professores podem dedicar mais tempo à preparação das aulas e às atividades de ensino, melhorando a qualidade do ensino.
-
Precisão da pontuação: A avaliação inteligente pode pontuar objetivamente as respostas dos alunos com base em padrões de pontuação predefinidos, evitando diferenças individuais e preconceitos no processo subjetivo de pontuação. Através de padrões de pontuação unificados, a justiça e a precisão da pontuação podem ser melhoradas.
-
Feedback instantâneo: O sistema de pontuação inteligente pode fornecer aos alunos pontuações e feedback sobre suas respostas em um curto espaço de tempo, permitindo que os alunos entendam suas pontuações e erros em tempo hábil, para que possam aprender e melhorar de maneira direcionada. Esse feedback imediato tem um impacto positivo no aprendizado e na motivação dos alunos.
-
Suporte a diversos tipos de perguntas: O sistema de avaliação inteligente pode se adaptar a uma variedade de tipos de perguntas, incluindo questões de múltipla escolha, questões de preenchimento de lacunas, dissertações, etc., para atender às necessidades de avaliação de diferentes disciplinas e estágios acadêmicos. Ao mesmo tempo, o sistema de classificação inteligente também pode realizar análise semântica, detecção gramatical, etc., para ajudar os professores a compreender plenamente a capacidade de expressão e o modo de pensar dos alunos.
-
Análise de dados e ensino personalizado: O sistema de classificação inteligente pode analisar e extrair uma grande quantidade de dados de respostas, ajudando os professores a compreender o estado de aprendizagem e o domínio do conhecimento dos alunos, de modo a conduzir um projeto e orientação de ensino personalizados.
Melhorias e extensões
Há muitas direções para melhorar e expandir a tecnologia de classificação inteligente no campo da educação. Questões como precisão, justiça e proteção da privacidade da avaliação precisam ser totalmente consideradas. Ao mesmo tempo, devem ser combinadas com as necessidades reais da educação. para garantir a eficácia e viabilidade da tecnologia.
-
Avaliação multimodal: O atual sistema de classificação inteligente depende principalmente da análise e pontuação do conteúdo do texto, podendo ainda introduzir dados multimodais, como imagens, áudios, vídeos, etc., e combinar análise semântica e métodos de reconhecimento de emoções para avaliar de forma abrangente expressões dos alunos.Capacidade e criatividade.
-
Avaliação de questões subjetivas: A avaliação de questões subjetivas é relativamente complexa.Ao introduzir modelos generativos e tecnologia de processamento de linguagem natural, o sistema de pontuação inteligente pode compreender melhor a lógica e a expressão das respostas dos alunos, de modo a realizar avaliações e pontuações mais precisas.
-
Avaliação e feedback personalizados: O sistema de notas inteligente pode usar dados históricos de respostas e trajetórias de aprendizagem dos alunos, combinados com algoritmos de recomendação personalizados, para fornecer a cada aluno avaliação e feedback adequados ao seu nível e necessidades, ajudando-os a aprender e aprender em um de maneira mais direcionada.
-
Padrões de pontuação adaptáveis: O sistema de classificação inteligente pode ajustar automaticamente os padrões de pontuação de acordo com diferentes tipos de perguntas e níveis de dificuldade para melhor se adaptar às mudanças e necessidades no campo educacional.
-
Assistência pedagógica e apoio ao professor: O sistema de classificação inteligente pode fornecer aos professores relatórios detalhados de pontuação e resultados de análise de dados, ajudando os professores a compreender melhor o estado e os problemas de aprendizagem dos alunos, de modo a fornecer assistência pedagógica direcionada.
-
Pontuação conjunta e avaliação interativa: O sistema de classificação inteligente pode introduzir um mecanismo de pontuação conjunta para integrar as pontuações de vários juízes para melhorar a consistência e a precisão da pontuação. Ao mesmo tempo, uma função de avaliação interativa também pode ser adicionada para permitir a comunicação bidirecional entre alunos e professores, promovendo ainda mais a melhoria dos efeitos de aprendizagem.