Ideias de design de pingue-pongue
A operação de pingue-pongue é geralmente usada para processar a conversão de fluxo de dados rápido para fluxo de dados lento. Também é frequentemente usada para lidar com problemas de domínio de clock cruzado. A ideia de conversão serial para paralelo é uma ideia estranha de tecnologia de pipeline. Conforme mostrado na figura abaixo:
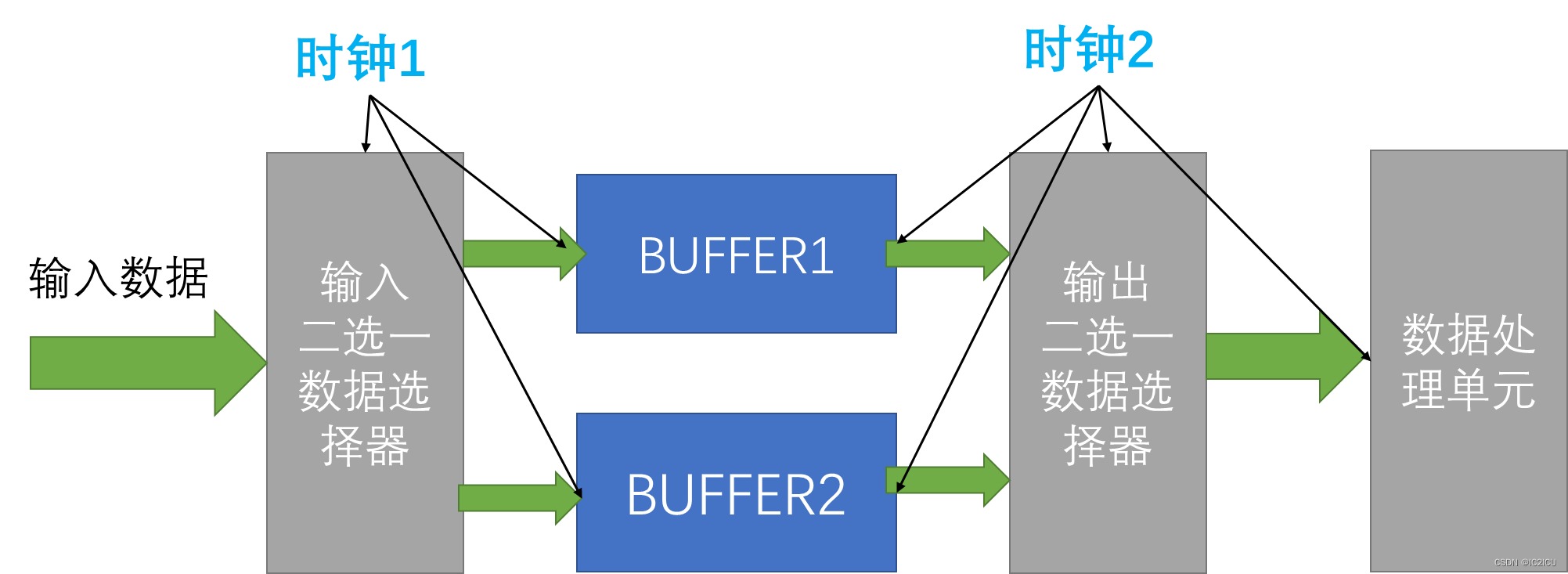
O problema agora é que os dados de entrada precisam ser transferidos do domínio de clock rápido para o domínio de clock lento e como transmitir e processar os dados de maneira eficaz. Neste momento, a operação de pingue-pongue é usada. Agora suponha que a frequência do clock do domínio de clock 1 seja 50 MHz e a frequência do clock 2 seja 25 MHz. Suponha que os dados de 16 e 8 bits precisem ser transmitidos dentro de um ciclo de buffer (na verdade, a capacidade de armazenamento do BUFFER). Grave dados no BUFFER1 durante o primeiro ciclo de buffer. No segundo ciclo de buffer, grave os dados no BUFFER2 e, ao mesmo tempo, leia os dados no BUFFER1 usando a frequência do clock 2, mas neste momento você descobrirá que após a leitura do segundo ciclo de clock, os dados do BUFFER1 são A leitura é apenas pela metade (se for lido apenas de acordo com a largura dos dados originais), ou seja, ao escrever o BUFFER1 no terceiro ciclo de buffer, verifica-se que os dados do BUFFER1 ainda não foram lidos. A forma de resolver esse problema é o que chamamos de serial para paralelo, ou seja, em vez de ler dados de 8 bits a cada vez, lemos dados de 16 bits a cada vez, para que possamos converter os dados do BUFFER1 no segundo ciclo de buffer. a leitura dos dados é concluída, o BUFFER1 é gravado e os dados do BUFFER2 são lidos ao mesmo tempo no terceiro ciclo de buffer, e o pipeline é formado repetidamente.
IP da RAM
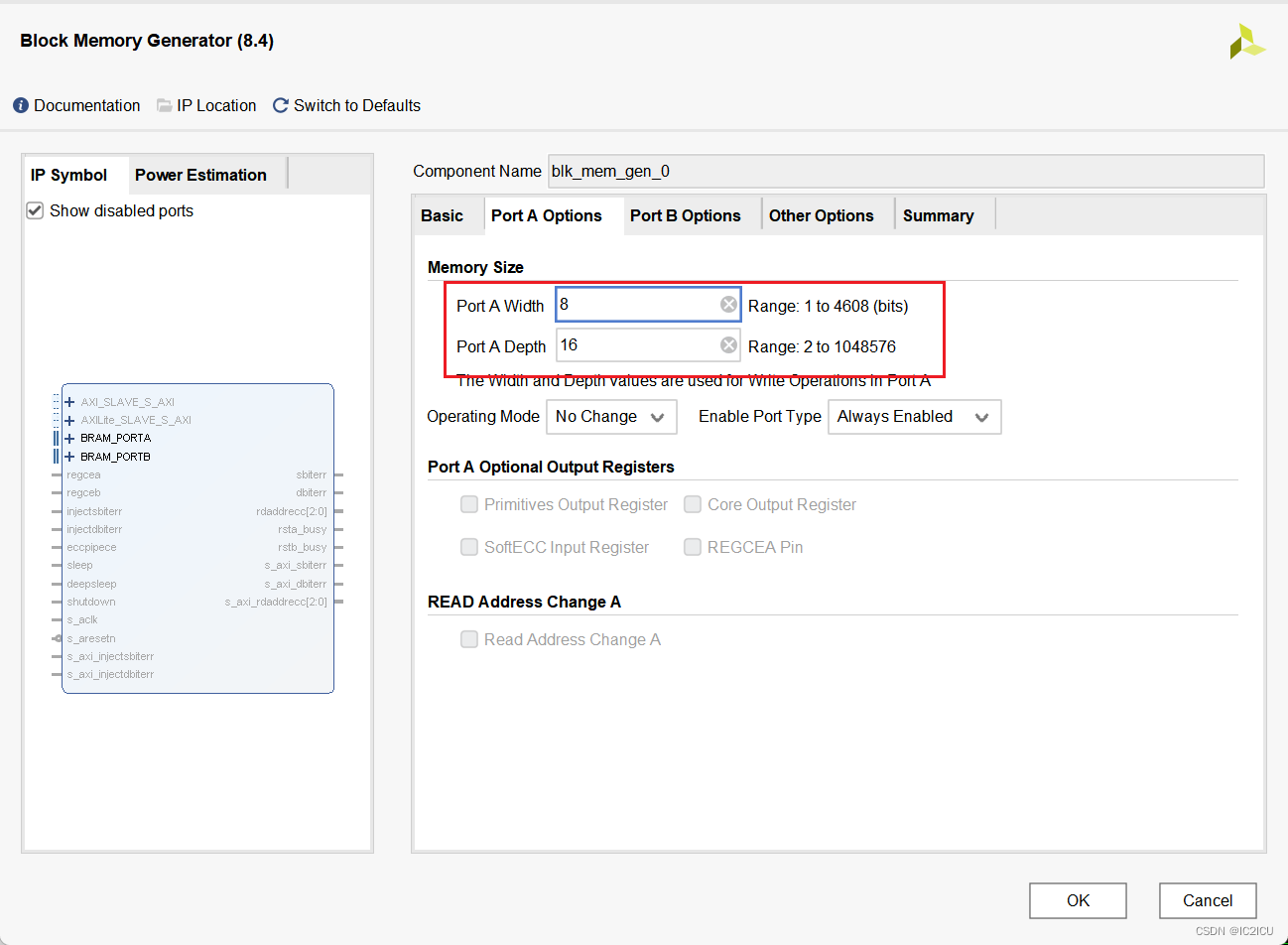
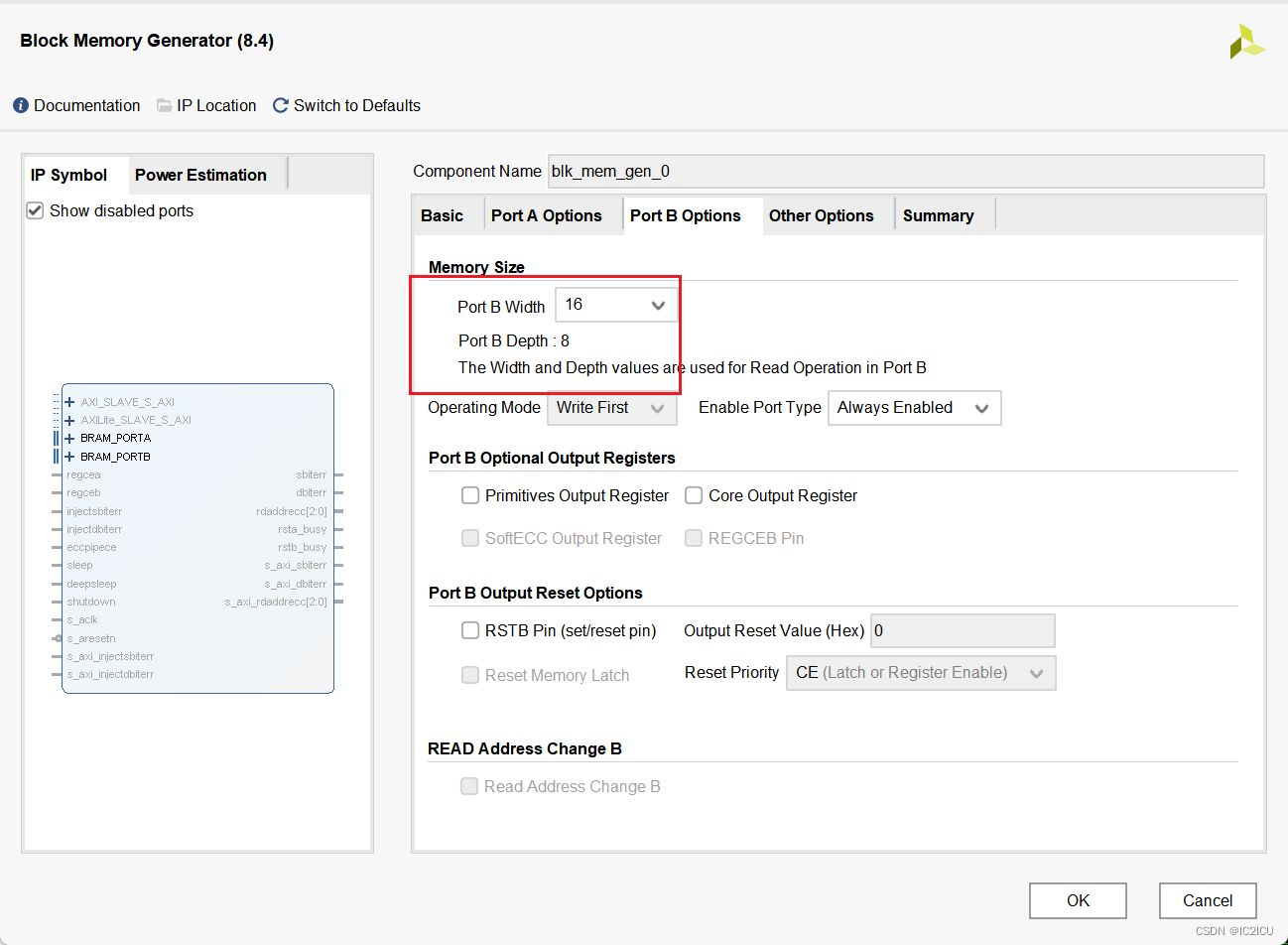
O IP da RAM declarado é uma RAM de porta dupla, a largura dos dados de entrada é de 8 bits e a profundidade é de 16. A largura dos dados de saída é de 16 bits e a profundidade é de 8. Conforme mostrado na figura abaixo:
IP de loop bloqueado por fase
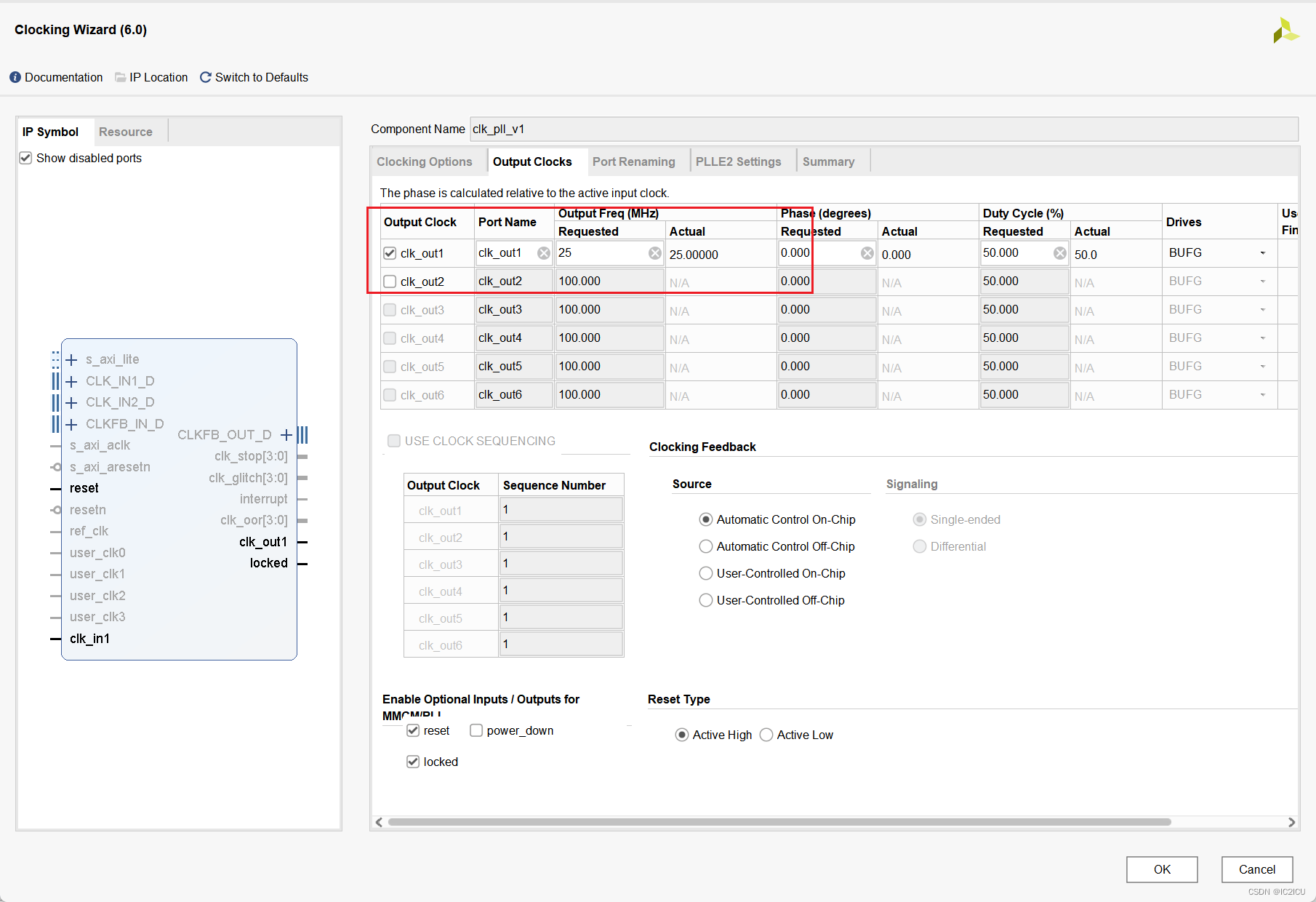
Sua função é inserir um clock de 50 MHz e gerar um clock de 25 MHz.

A ideia de design do BUFFER de pingue-pongue
Escreva BUFFER
Uma máquina de estado é usada como lógica de controle para decidir se deve escrever BUFFER1 ou BUFFER2.
| PARADO | Estado inativo |
|---|---|
| WR_BUF1 | Escreva BUFFER1 |
| WR_BUF2 | Escreva BUFFER2 |
| END_WR | status de gravação final |
O código a seguir salta entre estados:
always @(*) begin
case(state)
IDLE: next_state <= start ? WR_BFR1 : IDLE;
WR_BFR1:next_state <= wr_buf1_end ? WR_BFR2 : WR_BFR1;
WR_BFR2:next_state <= wr_buf2_end ? END_WR : WR_BFR2;
END_WR: next_state <= IDLE;
endcase
end
Ler BUFFER
Uma máquina de estado é usada como lógica de controle para decidir se deve ler BUFFER1 ou BUFFER2.
| PARADO | Estado inativo |
|---|---|
| RD_BUF1 | Leia BUFFER1 |
| RD_BUF2 | Leia BUFFER2 |
| END_RD | status de leitura final |
| A lógica do salto é a seguinte: |
always @(*) begin
case(read_state)
IDLE: rd_nxt_state <= wr_buf1_end ? RD_BFR1 : IDLE;
RD_BFR1:rd_nxt_state <= rd_buf1_end ? RD_BUBBLE : RD_BFR1;
RD_BUBBLE:rd_nxt_state <= RD_BFR2;
RD_BFR2:rd_nxt_state <= rd_buf2_end ? END_RD : RD_BFR2;
END_RD: rd_nxt_state <= IDLE;
endcase
end
Todo o código implementado (comentários detalhados)
//date:2022/9/7
//function:实现一个ram的pingpongbuffer
//输入数据流的时钟是50MHz
//输出数据流(处理数据流)的时钟是25MHz
//采用vivado的IP生成的ram
module pingpong_buffer(
input wire clk ,
input wire rst_n ,
input wire [7:0] data_in ,
input wire start ,
output wire [15:0] data_out ,
output wire locked
);
parameter IDLE = 3'd0 , //空闲状态
WR_BFR1 = 3'd1 , //写BUF1状态
WR_BFR2 = 3'd2 , //写BUF2状态
END_WR = 3'd3 , //写BUF结束状态
RD_BFR1 = 3'd4 , //读BUF1状态
RD_BFR2 = 3'd5 , //读BUF2状态
END_RD = 3'd6 , //结束读状态
RD_BUBBLE= 3'd7 ; //读气泡
wire clk_25mhz ;
//wire locked ;
wire asso_rst_n ;
wire wr_buf1_end ;
wire wr_buf2_end ;
wire rd_buf1_end ;
wire rd_buf2_end ;
wire [15:0] data_o_buf1 ;
wire [15:0] data_o_buf2 ;
reg wea ; //ram写使能信号
reg [2:0] state ;
reg [2:0] next_state ;
reg [3:0] wr_buf1_addr; //写ram1地址
reg [3:0] wr_buf2_addr; //写ram2地址
reg [3:0] read_state ;
reg [3:0] rd_nxt_state;
reg [2:0] rd_buf1_addr; //读ram1地址
reg [2:0] rd_buf2_addr; //读ram1地址
reg wr_end ; //写结束
reg rd_end ; //读结束
assign asso_rst_n = rst_n && locked; //生成一个新的复位信号
always @(posedge clk or negedge asso_rst_n) begin
if(!asso_rst_n) begin
state <= IDLE;
end
else begin
state <= next_state;
end
end
always @(posedge clk_25mhz or negedge asso_rst_n) begin
if(!asso_rst_n) begin
read_state <= IDLE;
end
else begin
read_state <= rd_nxt_state;
end
end
always @(posedge clk or negedge asso_rst_n) begin
if(~asso_rst_n) begin
wea <= 1'b0;
end
else if (next_state == WR_BFR1) begin
wea <= 1'b1;
end
else if (next_state == WR_BFR2) begin
wea <= 1'b0;
end
else begin
wea <= 1'b0;
end
end
always @(posedge clk or negedge asso_rst_n) begin
if(!asso_rst_n) begin
wr_buf1_addr <= 4'd0;
wr_buf2_addr <= 4'd0;
wr_end <= 1'b0;
end
else begin
case(state)
IDLE: begin
wr_buf1_addr <= 4'd0;
wr_buf2_addr <= 4'd0;
wr_end <= 1'b0;
end
WR_BFR1: begin
wr_buf1_addr <= (wr_buf1_addr == 4'd15) ? 4'd0 : wr_buf1_addr + 1'b1;
wr_buf2_addr <= 4'd0;
end
WR_BFR2: begin
wr_buf1_addr <= 4'd0;
wr_buf2_addr <= (wr_buf2_addr == 4'd15) ? 4'd0 : wr_buf2_addr + 1'b1;
end
END_WR: begin
wr_buf1_addr <= 4'd0;
wr_buf2_addr <= 4'd0;
wr_end <= 1'b1;
end
default: begin
wr_buf1_addr <= 4'd0;
wr_buf2_addr <= 4'd0;
wr_end <= 1'b0;
end
endcase
end
end
always @(*) begin
case(state)
IDLE: next_state <= start ? WR_BFR1 : IDLE;
WR_BFR1:next_state <= wr_buf1_end ? WR_BFR2 : WR_BFR1;
WR_BFR2:next_state <= wr_buf2_end ? END_WR : WR_BFR2;
END_WR: next_state <= IDLE;
endcase
end
assign wr_buf1_end = (wr_buf1_addr == 4'd15) ? 1'b1 : 1'b0;
assign wr_buf2_end = (wr_buf2_addr == 4'd15) ? 1'b1 : 1'b0;
assign rd_buf1_end = (rd_buf1_addr == 3'd7) ? 1'b1 : 1'b0;
assign rd_buf2_end = (rd_buf2_addr == 3'd7) ? 1'b1 : 1'b0;
always @(posedge clk_25mhz or negedge asso_rst_n) begin
if(!asso_rst_n) begin
rd_buf1_addr <= 3'd0;
rd_buf2_addr <= 3'd0;
rd_end <= 1'b0;
end
else begin
case(read_state)
IDLE: begin
rd_buf1_addr <= 3'd0;
rd_buf2_addr <= 3'd0;
rd_end <= 1'b0;
end
RD_BFR1: begin
rd_buf1_addr <= (rd_buf1_addr == 3'd7) ? 3'd0 : rd_buf1_addr + 1'b1;
rd_buf2_addr <= 3'd0;
end
RD_BFR2:begin
rd_buf1_addr <= 3'd0;
rd_buf2_addr <= (rd_buf2_addr == 3'd7) ? 3'd0 : rd_buf2_addr + 1'b1;
end
END_RD:begin
rd_buf1_addr <= 3'd0;
rd_buf2_addr <= 3'd0;
rd_end <= 1'b1;
end
default: begin
rd_buf1_addr <= 3'd0;
rd_buf2_addr <= 3'd0;
rd_end <= 1'b0;
end
endcase
end
end
always @(*) begin
case(read_state)
IDLE: rd_nxt_state <= wr_buf1_end ? RD_BFR1 : IDLE;
RD_BFR1:rd_nxt_state <= rd_buf1_end ? RD_BUBBLE : RD_BFR1;
RD_BUBBLE:rd_nxt_state <= RD_BFR2;
RD_BFR2:rd_nxt_state <= rd_buf2_end ? END_RD : RD_BFR2;
END_RD: rd_nxt_state <= IDLE;
endcase
end
//调用时钟锁相环的ip
clk_pll_v1 u_clk_pll (
.clk_in1 (clk) ,
.reset (~rst_n) ,
.locked (locked) ,
.clk_out1 (clk_25mhz)
);
//调用ram的ip
blk_mem_gen_0 buffer1(
.clka (clk) ,
.clkb (clk_25mhz) ,
.wea (wea) ,
.addra (wr_buf1_addr) ,
.addrb (rd_buf1_addr) ,
.dina (data_in) ,
.doutb (data_o_buf1)
);
blk_mem_gen_0 buffer2(
.clka (clk) ,
.clkb (clk_25mhz) ,
.wea (~wea) ,
.addra (wr_buf2_addr) ,
.addrb (rd_buf2_addr) ,
.dina (data_in) ,
.doutb (data_o_buf2)
);
assign data_out = ((read_state == RD_BFR1 && rd_buf1_addr >= 1) || read_state == RD_BUBBLE ) ? data_o_buf1 : (read_state == RD_BFR2) ? data_o_buf2 : 16'd0;
endmodule
O banco de testes é o seguinte:
`timescale 1ns/1ns
`define CLK_CYCLE 20
module pingpong_tb();
reg clk ;
reg rst_n ;
reg [7:0] data_in ;
reg start ;
wire [15:0] data_out ;
wire locked ;
pingpong_buffer u_pingpong_buffer(
. clk (clk),
. rst_n (rst_n),
. data_in (data_in),
. start (start),
. data_out (data_out),
. locked (locked)
);
initial begin
clk = 0;
rst_n = 0;
data_in = 8'd0;
start = 1'b0;
#30
rst_n = 1;
#40
@(posedge locked);
start = 1'b1;
#20
start = 1'b0;
repeat(50) begin
data_in = $random() % 256;
@(posedge clk);
end
end
always # (`CLK_CYCLE / 2) clk = ~clk;
endmodule
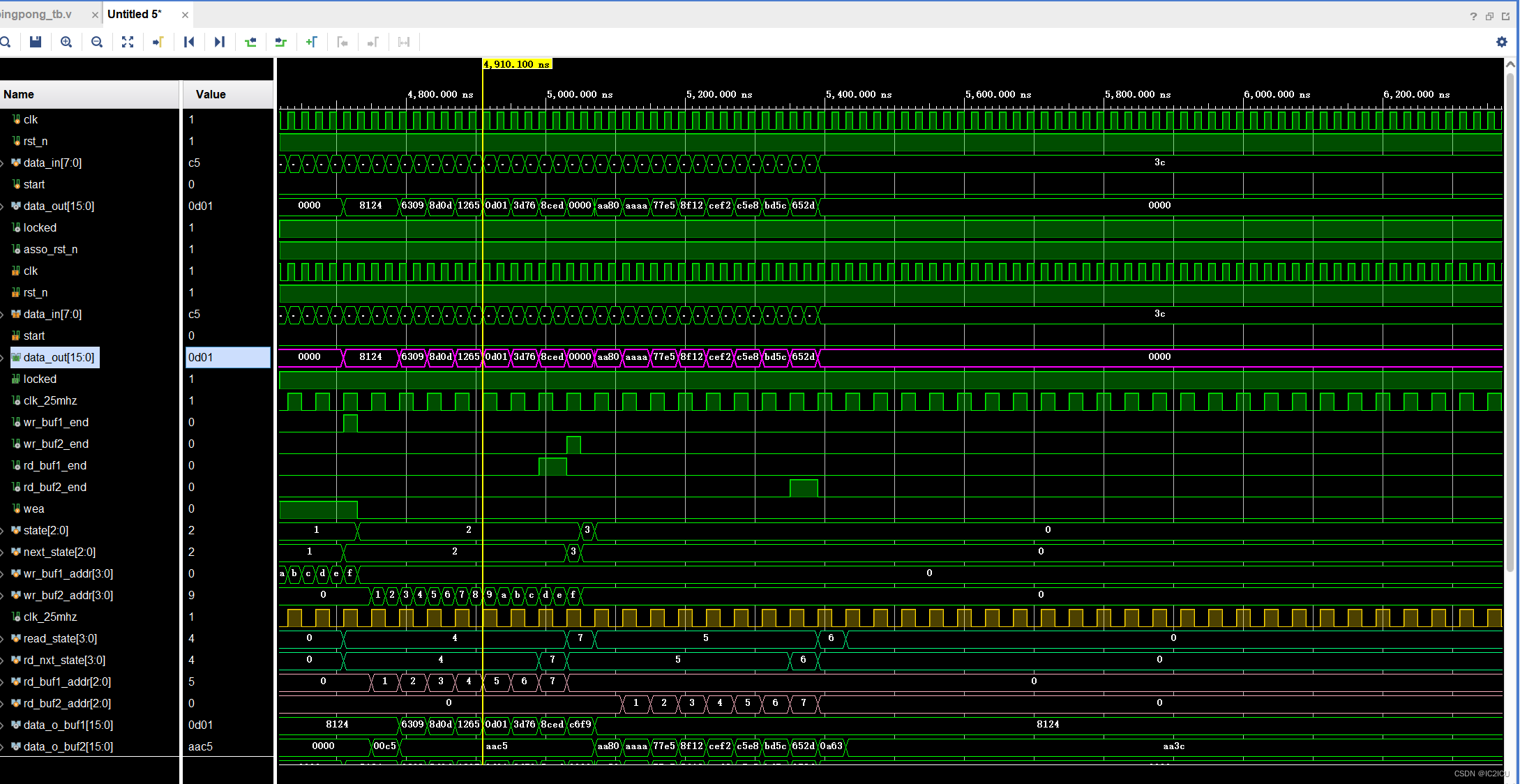
Forma de onda de simulação (pode-se verificar que o resultado está correto):
Resumir
Depois de conhecer a ideia do design de pingue-pongue, tornei-me mais proficiente no design de máquinas de estado. Mantenha o bom trabalho!