Artigo Diretório
- Configuração de ambiente
- Progresso do programa
- Código fonte completo
Configuração de ambiente
Python 3.6
tensorflow 1.13.1
hard 2.2.4
pip install tensorflow==1.13.1
pip install keras==2.2.4
Progresso do programa
Leia em conjunto de dados manuscritos
import keras
from keras.datasets import mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
O conjunto de dados manuscritos está localizado no pacote keras . Neste momento, o programa baixa automaticamente os dados do site oficial; o
conjunto de dados manuscritos:
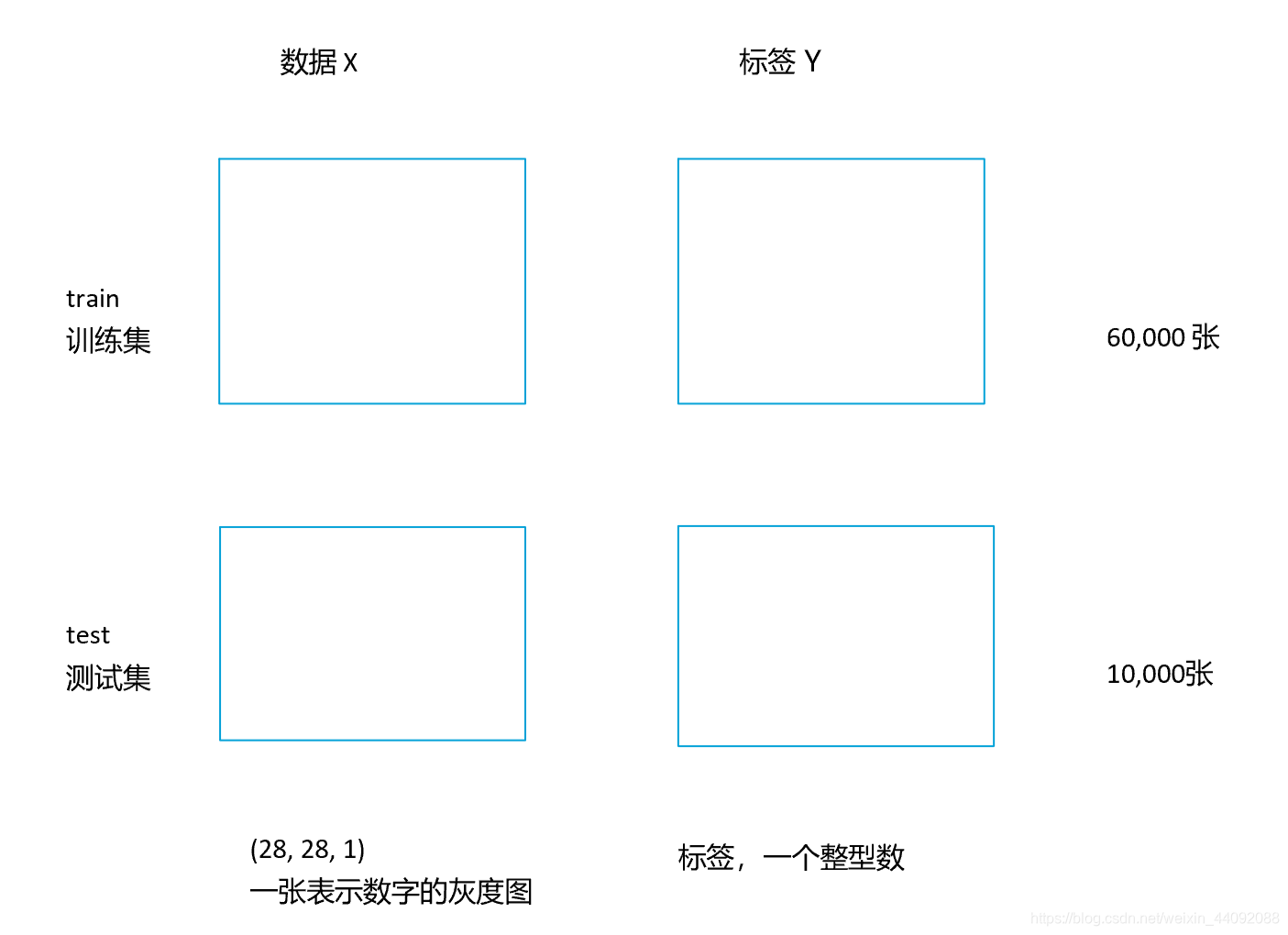
ver X, Y no seguinte formato:
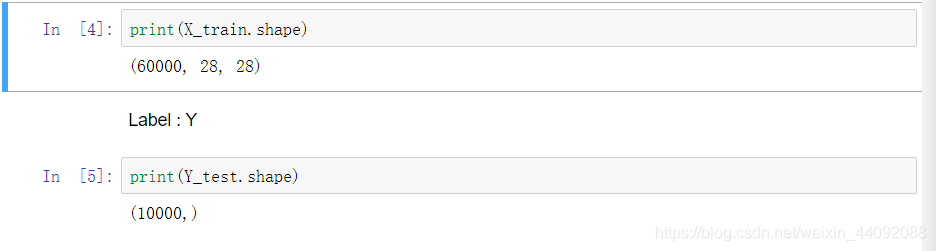
X_train contém uma imagem: o
rótulo correspondente Y_train é um número inteiro, que representa a imagem Qual é o número:

Organize os dados de entrada em um formato aceitável para o modelo
X_train = X_train.reshape(60000, 28, 28, 1)
X_test = X_test.reshape(10000, 28, 28, 1)
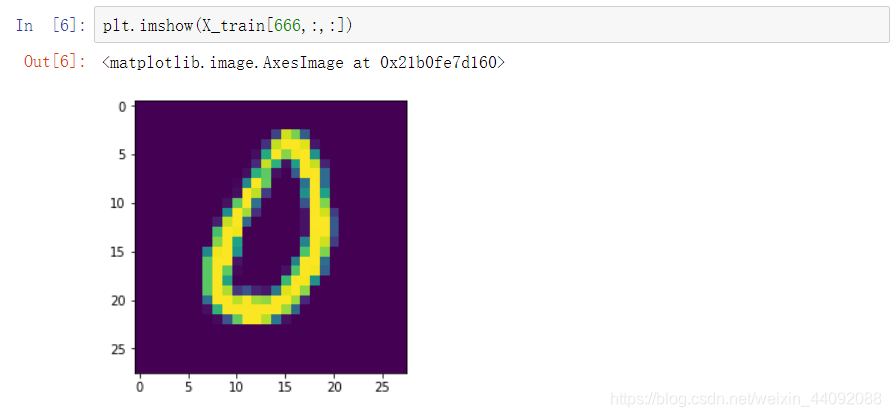
Os dados da primeira imagem do conjunto de treinamento parecem ser 5. (observe que o último parâmetro deve ser escrito como 0, tentado ":" não funciona)
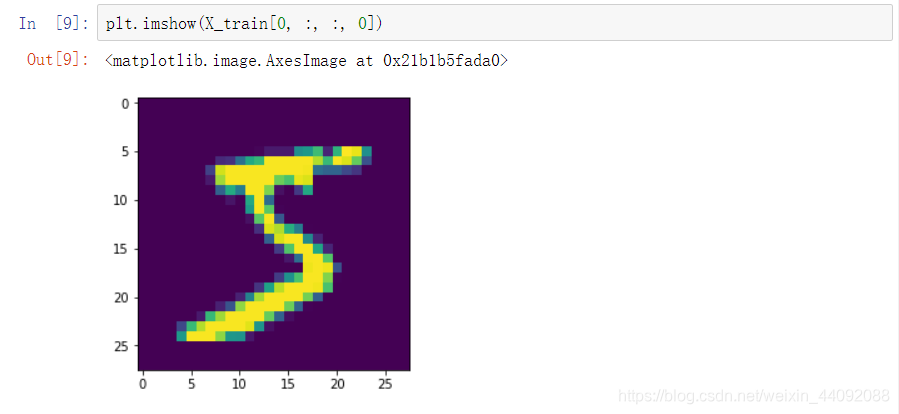
Os dados do conjunto de teste são semelhantes, a primeira imagem de teste:
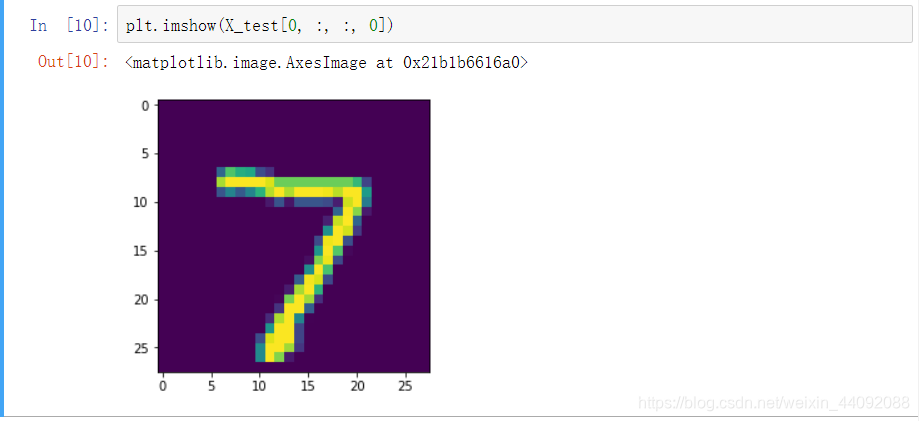
veja o convertido formato:

é apenas uma dimensão extra
Verifique o intervalo dos dados da imagem de entrada: o

valor está entre 0 e 255, o seguinte é convertido para entre 0 e 1, para normalização:
X_train = X_train / 255
X_test = X_test / 255

Codifique os dados de saída com um só hot
Para simplificar, uma matriz esparsa é usada para representar os resultados da previsão. Existem n tipos de resultados de classificação e a matriz tem n colunas. A j-ésima coluna é 1, o que significa que o j-ésimo tipo de resultado da previsão é mais provável.
Y_train = keras.utils.to_categorical(Y_train, 10)
Y_test = keras.utils.to_categorical(Y_test, 10)
Verifique o formato:

é realmente mais amplo.
Verifique o 101º rótulo e dê uma olhada nos dados da imagem:
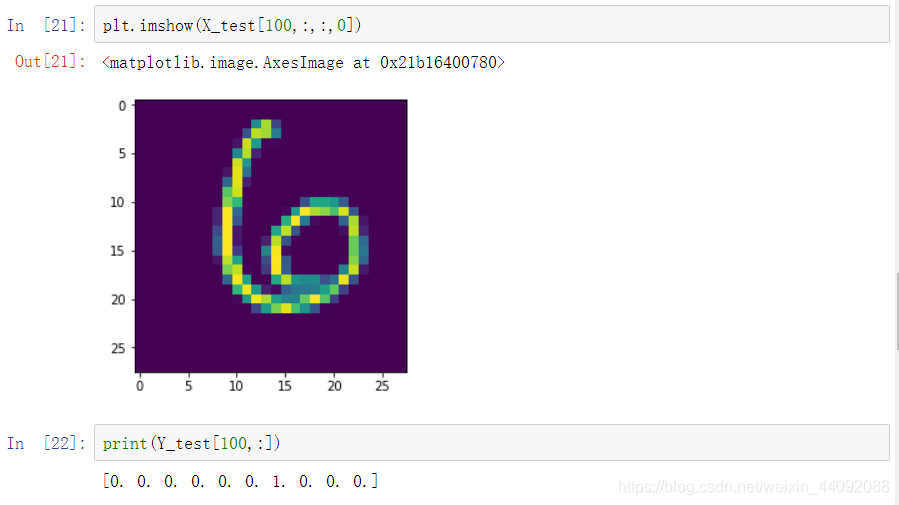
Existem 10 categorias, 0, 1, 2,…, 9, onde a 7ª coluna é 1, o que significa que o resultado é 6, que realmente se parece com 6.
Construir um modelo
model = Sequential() # 空模型
model.add(Conv2D(32, (3, 3), input_shape=(28, 28, 1)))
model.add(Activation("relu"))
model.add(Conv2D(32, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten()) # 展开成一维
model.add(Dense(200))
model.add(Activation("relu"))
model.add(Dense(200))
model.add(Activation("relu"))
model.add(Dense(10, activation="softmax"))
Breve explicação:
model.add(Conv2D(32, (3, 3), input_shape=(28, 28, 1)))
O primeiro parâmetro do Conv2D 32 significa que o resultado final é de 32 camadas ( m ∗ n ∗ 3 m * n * 3m∗n∗3 ->m ′ ∗ n ′ ∗ 32 m '* n' * 32m′∗n′∗3 2 ) O
segundo parâmetro (3, 3) representa o tamanho do operador de convolução;
input_shape é o formato dos dados de entrada
model.add(Dense(200))
Sobrepor 200 camadas de rede neural (parece ser o tipo mais comum, ou camada oculta ... eu não entendo muito)
Ver informações do modelo: (ignore o número entre colchetes que representa o processo em execução)

Defina o otimizador do modelo
adam = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model.compile(loss="categorical_crossentropy", optimizer=adam, metrics=["accuracy"])
Escolha o otimizador Adam e introduza o parâmetro β 1 β_1b1, β 2 β_2b2, ε εε , pegue um valor comumente usado, lr é a taxa de aprendizagem, definida como 0,001, a
função de perda usa entropia cruzada e a fórmula de cálculo para medir a precisão do desempenho do modelo é a precisão
Modelo de treinamento
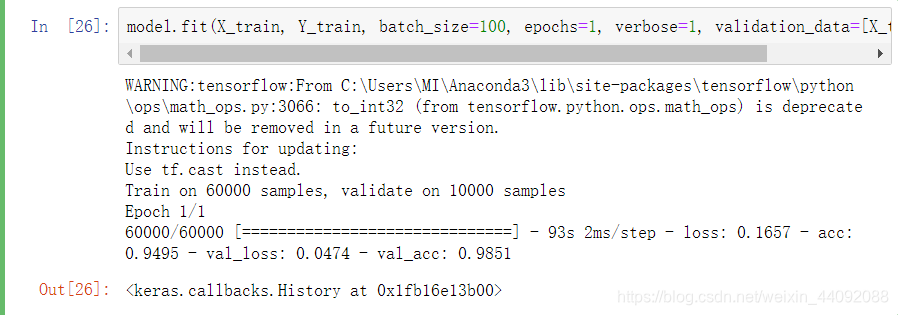
model.fit(X_train, Y_train, batch_size=100, epochs=1, verbose=1, validation_data=[X_test, Y_test])
No treinamento em lote, os dados são divididos em 100 partes e treinados apenas uma vez (epochs é o número de iterações). Não está claro o que é detalhado. . .
Roar, ventilador elétrico!
Insira uma imagem para fazer uma previsão
Primeiro, olhe para a terceira imagem do conjunto de teste: (esta imagem é a que ele viu antes)
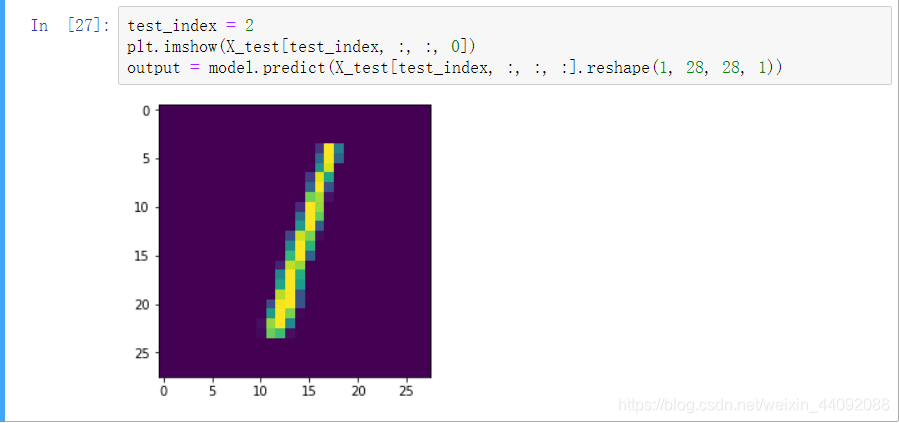
impressão, o resultado previsto é o número 1, que é consistente com a etiqueta de dados. A

saída é uma lista que registra a possibilidade de cada resultado da classificação, precisamos extrair manualmente o maior resultado possível como nosso resultado de previsão final.
Aqui a função np.round () é manter várias casas decimais, o primeiro parâmetro são os dados de entrada, o segundo parâmetro é manter várias casas decimais, o padrão é 1 dígito
O .reshape acima (1, 28, 28, 1) é necessário, porque outros métodos estão relatando erros. . .
(1)


(2)


Meu entendimento, como o último parâmetro, se for 0, ou seja, se houver apenas uma camada, então considera-se que não existe tal dimensão (ver (1)), apenas para tomar todos , use o símbolo ":", Eles são considerados como tendo esta dimensão, mas parecem ser os mesmos em minha opinião.
Portanto, o primeiro parâmetro usa apenas um número, e considera-se que não existe essa dimensão para relatar um erro.
Isso também deve provar porque quando a informação da imagem foi exibida antes, o último parâmetro com o símbolo ":" para tirar tudo isso reportará um erro, pois isso será considerado como uma dimensão a mais que a imagem.
Armazenamento de modelo
Acesse principalmente uma série de parâmetros obtidos no treinamento:
model.save("model/My_Alexnet_mnist.h5")
# 这里我之前手动创建了文件夹 model, 如果没有的话,应该会报文件不存在的错
Salve no arquivo .h5 na pasta do modelo no diretório principal do arquivo do programa
Carregamento de modelo
from keras.models import load_model
model = load_model("model/My_Alexnet_mnist.h5")
O modelo original está de volta!
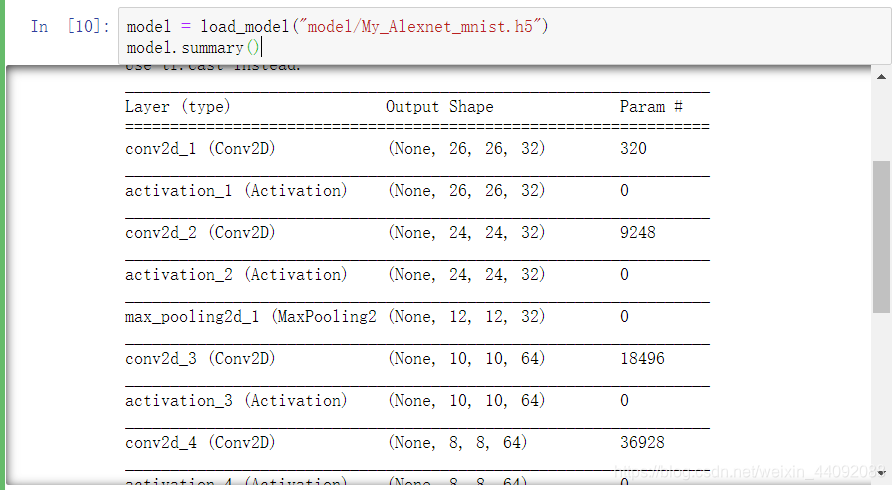
Não precisa se preocupar em correr novamente depois que o computador for desligado!
Código fonte completo
Sem saída desnecessária;
# 完整版
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Activation
from keras.layers import Conv2D, MaxPooling2D
#from keras import backend as K
# 手写数据集读入
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
# 把输入数据整理成模型可以接受的格式
X_train = X_train.reshape(60000, 28, 28, 1)
X_test = X_test.reshape(10000, 28, 28, 1)
# 进行归一化处理
X_train = X_train / 255
X_test = X_test / 255
# 对于输出进行 one-hot-codeing
Y_train = keras.utils.to_categorical(Y_train, 10)
Y_test = keras.utils.to_categorical(Y_test, 10)
# 搭建模型
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(28, 28, 1)))
model.add(Activation("relu"))
model.add(Conv2D(32, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten()) # 展开成一维
model.add(Dense(200))
model.add(Activation("relu"))
model.add(Dense(200))
model.add(Activation("relu"))
model.add(Dense(10, activation="softmax"))
# 定义模型的优化器
adam = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model.compile(loss="categorical_crossentropy", optimizer=adam, metrics=["accuracy"])
# 训练模型
model.fit(X_train, Y_train, batch_size=100, epochs=1, verbose=1, validation_data=[X_test, Y_test])
# 模型预测
test_index = 2
plt.imshow(X_test[test_index, :, :, 0])
output = model.predict(X_test[test_index, :, :, :].reshape(1, 28, 28, 1))
print("predicted output: ", np.round(output))
print("the label is: ", Y_test[test_index])
# 模型的存储
model.save("model/My_Alexnet_mnist.h5")
# 载入训练完成的模型
# from keras.models import load_model
# model = load_model("model/My_Alexnet_mnist.h5")
model.summary()