Endereço do evento: Desafio de Aprendizagem de 21 dias da CSDN
Índice
- prefácio
- Entendendo o conjunto de dados captcha
- Faça o download do conjunto de dados weather_photos
- Se deve usar treinamento de CPU ou treinamento de GPU
- Suporte chinês
- Importar dados
- Ver volume de dados
- Mostre algumas fotos
- pré-processando
- Construir um modelo CNN
- Treine o modelo
- Avaliação do modelo
- prever
prefácio
O ambiente não será repetido aqui. Ele é consistente com o ambiente no [Deep Learning] Texto de treinamento de reconhecimento climático baseado em redes neurais convolucionais. Se a configuração ainda não for bem-sucedida, consulte a configuração detalhada do pacote no final deste artigo.
Entendendo o conjunto de dados captcha
Este contém 1070 imagens de código de verificação manuscritas. E use o código de verificação normal como o nome da imagem. Portanto, no estágio posterior, você precisa dividir manualmente o conjunto de teste e o conjunto de validação, e precisa extrair manualmente os códigos de verificação em todos os nomes de imagem.
Faça o download do conjunto de dados weather_photos
Você pode me enviar uma mensagem privada (porque o conjunto de dados já foi carregado para csdn, então não pode ser carregado novamente)
Se deve usar treinamento de CPU ou treinamento de GPU
De um modo geral, se você tiver uma boa placa gráfica (GPU), use a GPU para treinamento porque ela é rápida , então você precisa baixar o pacote tensorflow-gpu de acordo. Se sua placa gráfica for ruim ou você não tiver fundos suficientes para começar com uma boa placa gráfica, você pode usar o treinamento CUP.
A diferença
(1) A CPU é usada principalmente para operações seriais; enquanto a GPU é para operações massivamente paralelas. Devido à enorme quantidade de amostras e à grande quantidade de parâmetros em deep learning, o papel da GPU é acelerar as operações de rede.
(2) Também é possível calcular a rede neural pela CPU, e a rede neural calculada também é muito eficaz em aplicações práticas, mas a velocidade será muito lenta. Atualmente, as operações da GPU se concentram principalmente na multiplicação e convolução de matrizes, e outras operações lógicas não são tão rápidas quanto as CPUs.
Treinar com CPU
# 使用cpu训练
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
O modelo de CPU não é exibido ao treinar com CPU.

Treinamento com GPU
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0], "GPU")
Ao usar o treinamento de GPU, o modelo de GPU correspondente será exibido.

Suporte chinês
Use import matplotlib.pyplot as plta biblioteca de importação, . plt é uma biblioteca que significa draw. A configuração na biblioteca é fixa, mas às vezes queremos modificar os parâmetros de configuração do plt para atender às necessidades do desenho.
Pode ser plt.rcParams['配置参数']=[修改值]modificado, rcParams (executar parâmetros de configuração) executar parâmetros de configuração.
plt.rcParams['font.sans-serif'] = ['SimHei'] #运行配置参数中的字体(font)为黑体(SimHei)
plt.rcParams['axes.unicode_minus'] = False #运行配置参数总的轴(axes)正常显示正负号(minus)
Importar dados
Aqui vemos que a semente aleatória de numpy e a semente aleatória de tf são definidas para valores fixos, de modo que os resultados do treinamento sejam o mais estáveis possível. Aqui, o caminho onde o conjunto de dados é armazenado localmente é fornecido à variável data_dir.
import matplotlib.pyplot as plt
import PIL
# 设置随机种子尽可能使结果可以重现
import numpy as np
np.random.seed(1)
# 设置随机种子尽可能使结果可以重现
tf.random.set_seed(1)
from tensorflow import keras
from tensorflow.keras import layers, models
import pathlib
data_dir = "E:\\PythonProject\\day6\\data\\captcha\\"
data_dir = pathlib.Path(data_dir)
# 提取所有照片的路径
all_image_paths = list(data_dir.glob('*'))
all_image_paths = [str(path) for path in all_image_paths]
# 打乱数据 因为文件默认按照文件名的字母排序,所以需要打乱顺序
random.shuffle(all_image_paths)
# 获取数据标签 通过拆分图片名称的后缀见所有的验证码字符串提取出来
# 验证码长度是5位,且都已.png结尾 然后进行拆分
all_label_names = [path.split("\\")[5].split(".")[0] for path in all_image_paths]
Ver volume de dados
image_count = len(all_image_paths)
print("图片总数为:", image_count)
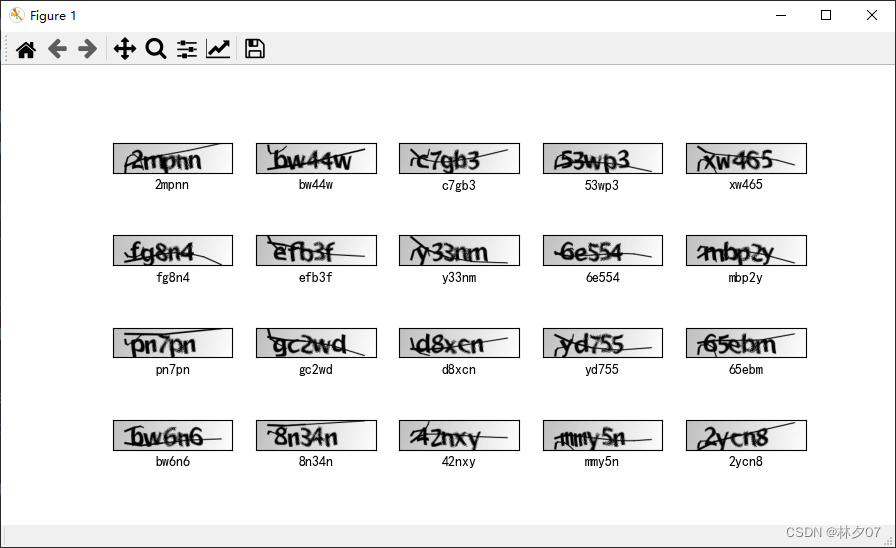
Mostre algumas fotos
Desenhe as primeiras 20 folhas, 5 em cada linha para um total de quatro linhas.
from matplotlib import pyplot as plt
plt.figure(figsize=(10, 5))
for i in range(20):
plt.subplot(4, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 显示图片
images = plt.imread(all_image_paths[i])
plt.imshow(images)
# 显示标签
plt.xlabel(all_label_names[i])
plt.show()
Plote o resultado:
pré-processando
Definir rótulos manualmente
Projete uma matriz para armazenar todos os números + caracteres que aparecem no código de verificação.
number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
'v', 'w', 'x', 'y', 'z']
char_set = number + alphabet
char_set_len = len(char_set)
label_name_len = len(all_label_names[0])
def text2vec(text):
vector = np.zeros([label_name_len, char_set_len])
for i, c in enumerate(text):
idx = char_set.index(c)
vector[i][idx] = 1.0
return vector
all_labels = [text2vec(i) for i in all_label_names]
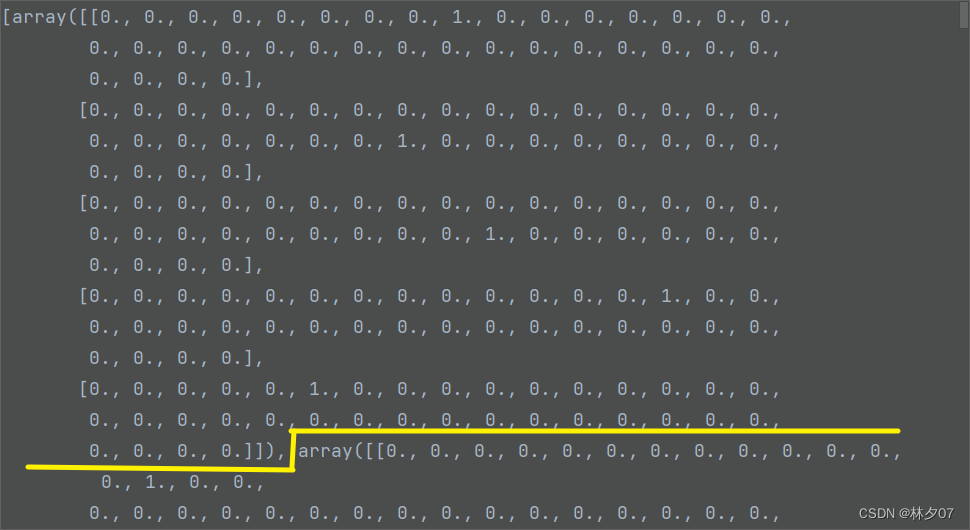
Pode ser um pouco confuso olhar o código diretamente. A imagem a seguir é o efeito final, que é equivalente a uma matriz tridimensional. A primeira dimensão representa cada imagem, a segunda dimensão representa vários conjuntos de caracteres e a terceira dimensão representa qual deve ser o código de verificação de cada pessoa. Caracteres, se houver, é 0 na posição correspondente, se não, é 0.
Processamento em escala de cinza
Tons de cinza, no modelo RGB, se R=G=B, a cor representa uma cor em tons de cinza, e o valor de R=G=B é chamado de valor em tons de cinza. Portanto, cada pixel da imagem em tons de cinza precisa apenas de um armazenamento de Bytes em tons de cinza valores (também conhecidos como valores de intensidade, valores de brilho) e o intervalo de tons de cinza é de 0 a 255. A fórmula é a seguinte:

Método médio
Uma imagem em tons de cinza é obtida pela média das luminâncias de três componentes na imagem colorida. Este artigo usa as fotos processadas pelo método médio.

A figura abaixo está em tons de cinza pelo método de média. A esquerda é a imagem original e a direita é a imagem em escala de cinza.
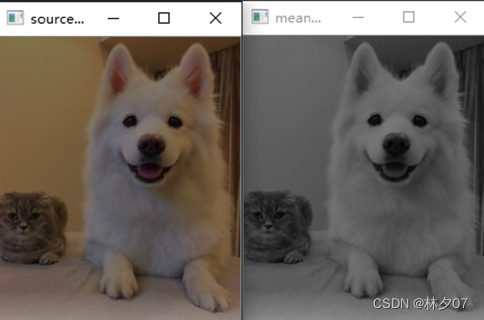
Método de média ponderada
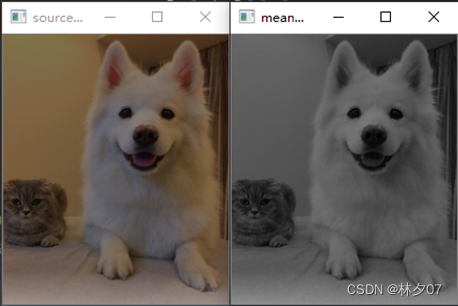
Este método é um método de estimar a direção provável desse valor no futuro com base no valor observado durante um determinado período de tempo no passado.
A figura abaixo está em tons de cinza pelo método de média. A esquerda é a imagem original e a direita é a imagem em escala de cinza.
cvtColor
A função API cvtColor do OpenCV também pode obter processamento em escala de cinza. A figura abaixo está em tons de cinza pelo método de média. A esquerda é a imagem original e a direita é a imagem em escala de cinza.
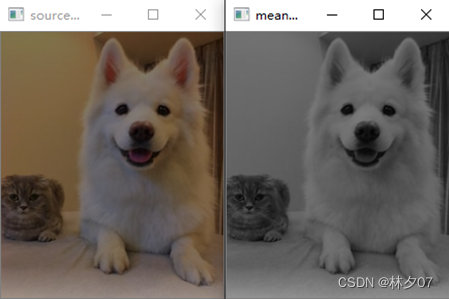
Baixar dados
O método from_tensor_slices é usado aqui. Esta função é uma das funções centrais do conjunto de dados, sua função é fatiar os dados fornecidos, como tuplas, listas e tensores. A extensão da fatia começa na dimensão mais externa. Se houver vários recursos a serem combinados, uma fatia deve cortar os dados da dimensão mais externa de cada combinação e dividi-los em grupos.
AUTOTUNE = tf.data.experimental.AUTOTUNE
path_ds = tf.data.Dataset.from_tensor_slices(all_image_paths)
image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE)
label_ds = tf.data.Dataset.from_tensor_slices(all_labels)
image_label_ds = tf.data.Dataset.zip((image_ds, label_ds))
# 拆分数据集 将前1000个作为训练集 剩余的作为测试集
train_ds = image_label_ds.take(1000)
val_ds = image_label_ds.skip(1000)
Configurar o conjunto de dados (acelerar)
shuffle(): Esta função ordena aleatoriamente todos os elementos da lista. Às vezes, nossas tarefas amostram aleatoriamente determinados números de um conjunto de dados. Por exemplo, há 10 linhas em um texto e precisamos selecionar aleatoriamente as 5 primeiras.
prefetch(): pré-busca é o conteúdo da memória de pré-busca, o programador informa à CPU qual conteúdo pode ser usado imediatamente e a CPU faz a pré-busca para otimização.
BATCH_SIZE = 16
train_ds = train_ds.batch(BATCH_SIZE)
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.batch(BATCH_SIZE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)
Construir um modelo CNN
O modelo aqui é praticamente o mesmo dos anteriores, então não vou apresentá-lo muito.
from tensorflow.keras import datasets, layers, models
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(50, 200, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(1000, activation='relu'),
layers.Dense(label_name_len * char_set_len),
layers.Reshape([label_name_len, char_set_len]),
layers.Softmax()
])
model.summary() # 打印网络结构
estrutura de rede
Um total de 10 camadas, incluindo a camada de entrada
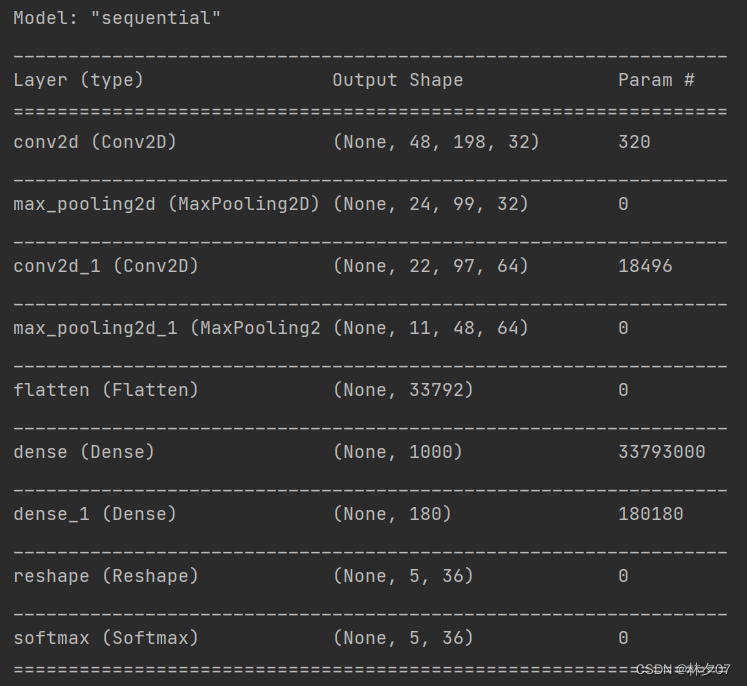
quantidade de parâmetro
O número total de parâmetros é 33M, e a quantidade de parâmetros é maior, mas o conjunto de dados não é muito grande. O treinamento da GPU é recomendado.
Total params: 33,991,996
Trainable params: 33,991,996
Non-trainable params: 0
Treine o modelo
Treine o modelo por 10 épocas.
# 设置优化器
model.compile(optimizer="adam",
loss='categorical_crossentropy',
metrics=['accuracy'])
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
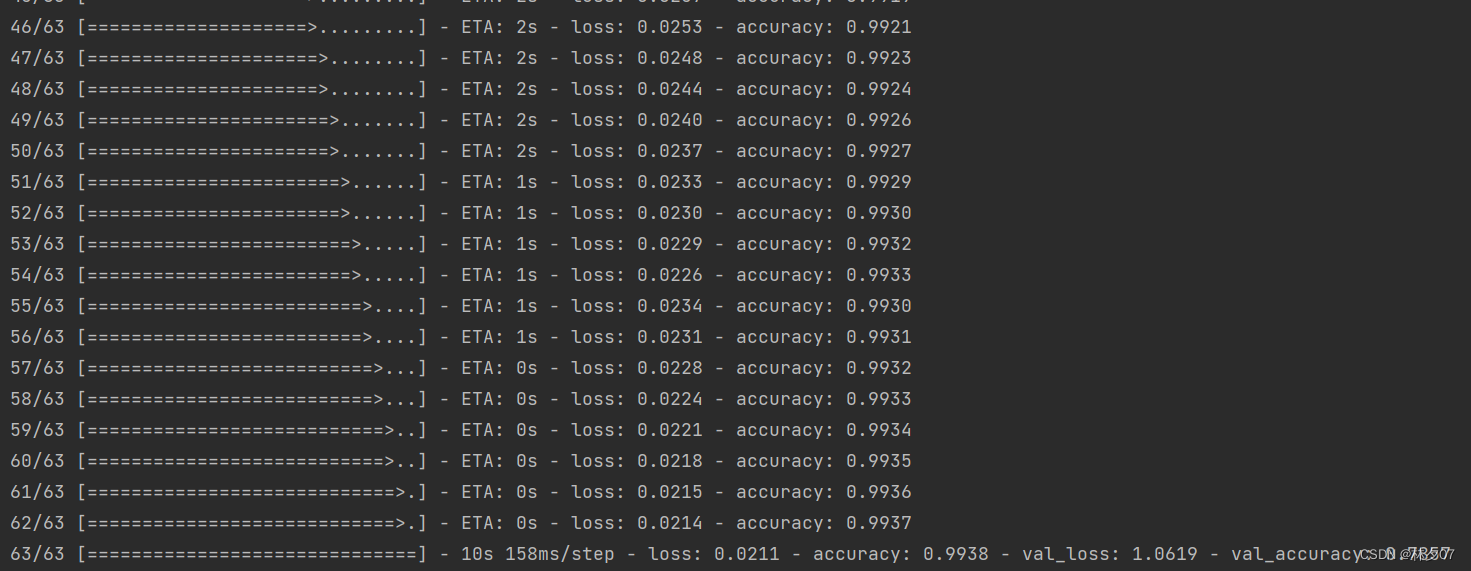
Resultados do treinamento: Após 10 rodadas, a taxa correta do conjunto de testes é de apenas 78,57%, o que mostra que ainda há muito espaço para otimização.
Avaliação do modelo
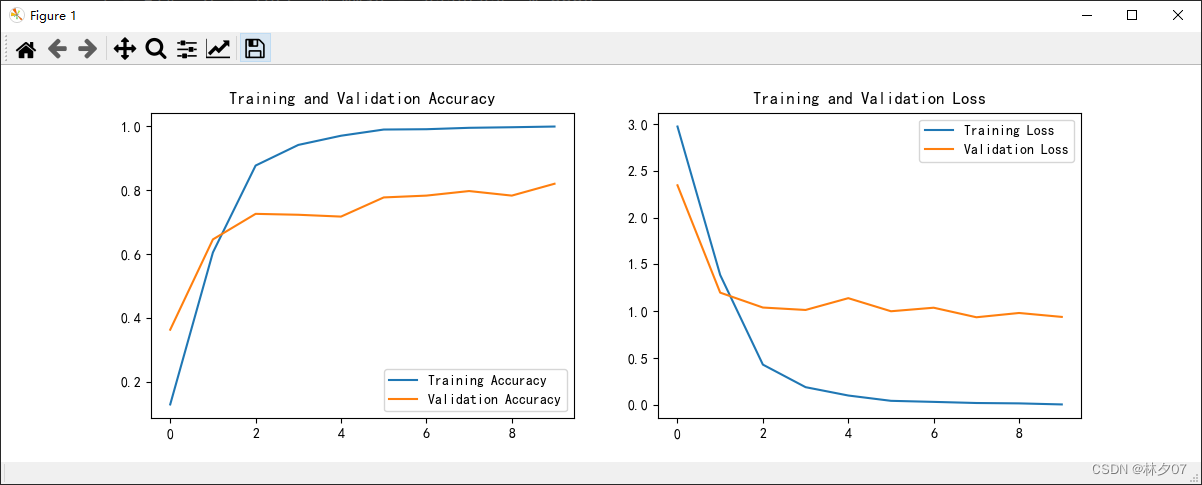
Os dados do modelo treinado são transformados em uma tabela de curvas, o que é conveniente para a otimização do modelo posteriormente, seja overfitting ou underfitting ou necessidade de expandir os dados e assim por diante.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
resultado da operação:
prever
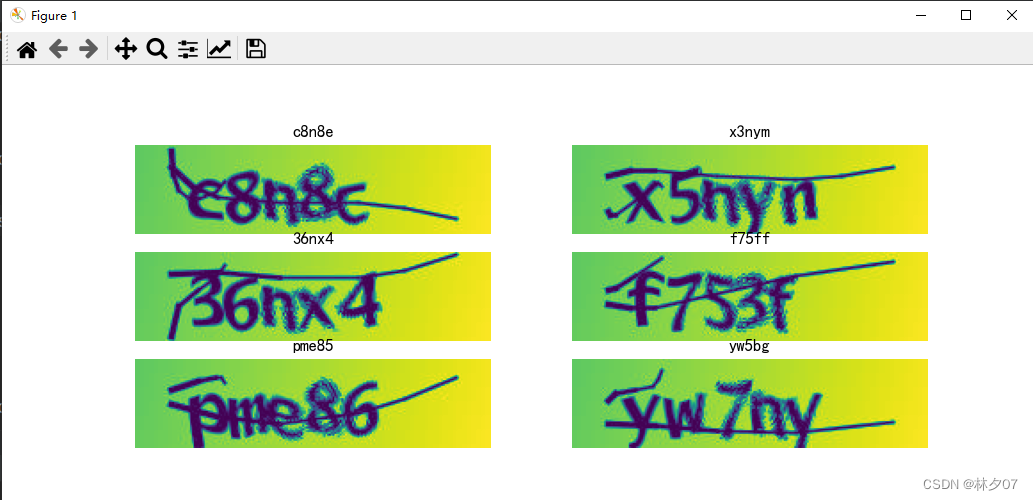
Aqui realizamos um efeito de pré-processamento no modelo treinado.As seis figuras a seguir são usadas como exemplo para teste.
def vec2text(vec):
text = []
for i, c in enumerate(vec):
text.append(char_set[c])
return "".join(text)
plt.figure(figsize=(8, 8))
for images, labels in val_ds.take(1):
for i in range(6):
ax = plt.subplot(5, 2, i + 1)
# 显示图片
image = tf.reshape(images, [16, 50, 200])
plt.imshow(image[i])
# 需要给图片增加一个维度
img_array = tf.expand_dims(images[i], 0)
# 使用模型预测验证码
predictions = model.predict(img_array)
plt.title(vec2text(np.argmax(predictions, axis=2)[0]))
plt.axis("off")
plt.show()
Pode-se observar que a taxa de erro ainda é bastante alta, e o modelo precisa ser melhorado ainda mais.