
1. Descrição
Em meus artigos anteriores, discuti os fundamentos dos sistemas de recomendação, fatoração de matrizes e filtragem colaborativa neural (NCF), que você pode encontrar na seção Meu Blog abaixo. A seguir, desta vez explorarei a máquina de fatoração por meio de exemplos e código.
Algumas vantagens de usar máquinas de fatoração para sistemas de recomendação são
- Ele lida relativamente bem com dados esparsos e de alta dimensão.
- Você pode adicionar metainformações sobre usuários e projetos para obter mais contexto. Portanto, as máquinas de fatoração não são métodos de filtragem colaborativa puros, como NCF e fatoração de matrizes, que usam apenas interações usuário-item.
A máquina de fatoração é um algoritmo de ML supervisionado que pode ser usado para classificação e regressão. Embora seja famoso por seu sistema de recomendação. também
Pode ser vista como uma extensão da regressão linear, além de capturar relações lineares,
Relacionamentos de ordem superior também podem ser capturados pela introdução de interações de recursos de ordem superior usando decomposição latente.
2. O que é interação de recursos de alta ordem?
A interação de ordem superior refere-se ao efeito combinado de duas ou mais características na variável alvo, onde o impacto não é linear e não pode ser representado pela soma dos efeitos das características individuais. Por exemplo
Digamos que temos dados classificados sobre se um usuário clicará em um anúncio. O conjunto de recursos tem
ID do usuário, idade do usuário, tipo de anúncio, ID do anúncio, clique ou não (rótulo)
Podemos descobrir que o impacto do tipo de anúncio na probabilidade de um usuário clicar em um anúncio depende da idade do usuário. Por exemplo, os usuários mais jovens podem ter maior probabilidade de clicar em anúncios gráficos, enquanto os usuários mais velhos podem preferir anúncios em vídeo. Esta interação significa que o efeito do “tipo de anúncio” não é consistente em todas as faixas etárias. Para capturar essa interação de ordem superior, o modelo precisa considerar como o “tipo de anúncio” e a “idade do usuário” interagem para afetar as taxas de cliques.
As máquinas de fatoração podem nos ajudar a capturar interações de ordem superior que a regressão linear ignora.
A equação do modelo FM contém interações de n vias entre recursos de diferentes ordens. A configuração mais comum é um modelo de segunda ordem, que contém um peso para um único recurso no conjunto de dados e um termo de interação para cada par de recursos. Explicarei a interação bidirecional neste artigo.
3. Como é implementado? Vamos entender com um exemplo
Suponha que temos os seguintes dados de interação entre usuário e item
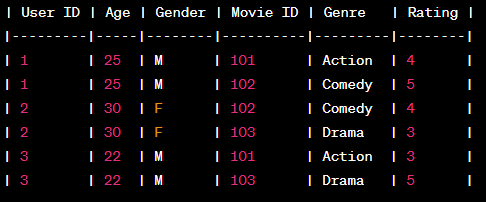
Como você pode ver, além das interações usuário-projeto, ele também contém algumas metainformações sobre usuários e projetos.
- Codificação one-hot de recursos categóricos presentes em um conjunto de dados. Isso incluirá a codificação One-Hot En para as colunas Usuário (ID do usuário) e Projeto (ID do filme), com exceção da coluna Tag (Classificação).
4. Equação da máquina de fatoração
y = w₀ + ∑(wi * xi) + ∑i(∑j(<vi . vj> *xi *xj))
onde
y = rótulo
w₀ = desvio
wi = peso
xi = recursos do conjunto de recursos de codificação One-Hot
<VI.vj> = produto escalar entre vetores potenciais
Nota: Se o termo 3 for ignorado, o termo 1 formará uma equação de regressão linear .
- Os dois primeiros termos são semelhantes à regressão linear onde w₀=viés e
- wi * xi captura o peso de cada recurso One-Hot-Encoding.
- O item 3 é importante para capturar interações de ordem superior
∑i (∑j (<vi . vj> * xi * xj)), multiplicamos cada coluna obtida após a codificação One-Hot por todos os recursos, bem como o produto escalar entre as representações vetoriais latentes dessas colunas OHE.
Suponha que tenhamos 2 recursos, Idade e Gênero, onde Gênero tem dois valores possíveis: Ação e Comédia, então o terceiro termo em FM após o Gênero codificado One-Hot (Gênero_Ação e Gênero_Comédia) ficará assim
<v_age .v_age> * idade * idade +
<v_genre_action .v_genre_action> * gênero_ação* gênero_ação+
<v_genre_comedy .v_genre_comedy> * gênero_comédia* gênero_comédia+
<v_age .v_genre_action> * idade * gênero_action +
<v_age .v_genre_action>idade* gênero_comédia +
<v_genre_action .v_genre_comedy> * gênero_comédia* gênero_ação
Aqui você pode ver que para cada par possível de colunas OHE, teremos um termo que captura sua interação, bem como sua representação vetorial subjacente. Como “ gênero” possui dois valores possíveis, ele é dividido em duas colunas. "Idade" é um número, portanto não há OHE para esta coluna. Então para 3 colunas obtemos 6 combinações diferentes
W₀, WI e VI são as entidades que o modelo aprenderá durante o treinamento.
ultima questão
Por que não usamos uma matriz de pesos em vez de um vetor latente no terceiro termo? Ou o vetor latente é semelhante a alguma matriz de pesos?
Vetores latentes não são iguais a matrizes de peso. Eles geralmente são menores em tamanho.
Isto é feito porque o número de vetores latentes é geralmente muito menor que o número de combinações de características únicas formadas no termo 3. Isto é particularmente vantajoso quando se trabalha com conjuntos de dados de alta dimensão, pois a matriz de peso completa se tornará computacionalmente cara e consumirá muita memória.
Chega de matemática, hora de agir
Primeiro, precisamos de um conjunto de dados fictício. Criaremos um usando sklearn.datasets com 10 recursos.
Nota: Este exemplo funciona para qualquer tipo de classificação. Para recomendações, todo o processo permanece o mesmo
#pip install git+https://github.com/coreylynch/pyFM
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from pyfm import pylibfm
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=100000,n_features=10, n_clusters_per_class=1)Vejamos nosso conjunto de dados de treinamento
e etiquetas

- A seguir, usaremos o conjunto de dados carregado para criar um dicionário com os nomes dos recursos como chaves e os valores correspondentes como valores. Cada linha do conjunto de dados de treinamento será representada por um dicionário como este
data = [ {v: k for k, v in dict(zip(i, range(len(i)))).items()} for i in X]
Tempo parcial de teste de trem
X_train, X_test, y_train, y_test = train_test_split(data, y, test_size=0.1, random_state=42)- Agora, conforme discutido em Factorization Machine, converteremos todos os recursos em vetores One-Hot. Isso será feito usando DictVectorizer. Isso produzirá uma matriz esparsa
v = DictVectorizer()
X_train = v.fit_transform(X_train)
X_test = v.transform(X_test)A seguir, vamos treinar a máquina de fatoração e analisar os resultados nos dados de teste
fm = pylibfm.FM(num_factors=50,num_iter=10, verbose=True, task="classification", initial_learning_rate=0.0001, learning_rate_schedule="optimal")
fm.fit(X_train,y_train)
# Evaluate
from sklearn.metrics import log_loss,accuracy_score
print("Validation log loss: %.4f" % log_loss(y_test,fm.predict(X_test)))
print("Validation accuracy: %.4f" % accuracy_score(y_test,np.where(fm.predict(X_test)<0.5,0,1)))A implementação mostrada acima é muito simples. No entanto, existem alguns hiperparâmetros principais que você deve considerar ajustar
num_factors : Tamanho do vetor latente (v). Quanto maior o tamanho, mais complexidade ele pode capturar, mas os custos computacionais e de memória são altos.
Tarefa: tarefa de classificação (feedback implícito)/regressão (feedback explícito)
As capturas de tela anexadas abaixo retratam o treinamento em andamento
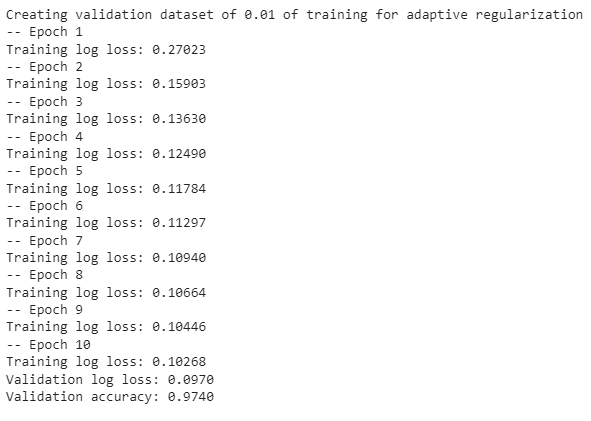
Como você pode ver, alcançamos 097% de precisão com logloss=97,0, o que é ótimo! !
Muitas outras bibliotecas também fornecem implementações de máquinas de fatoração, como xlearn, fastFM, etc., você pode experimentar. Mehul Gupta