
Para alcançar filtragem colaborativa, os passos necessários?
1. preferências do usuário a cobrar
2. Encontrar usuários ou itens semelhantes
3. Calcular recomendados


De usuário e filtragem colaborativa baseada colaborativo filtragem baseada em uma comparação do artigo
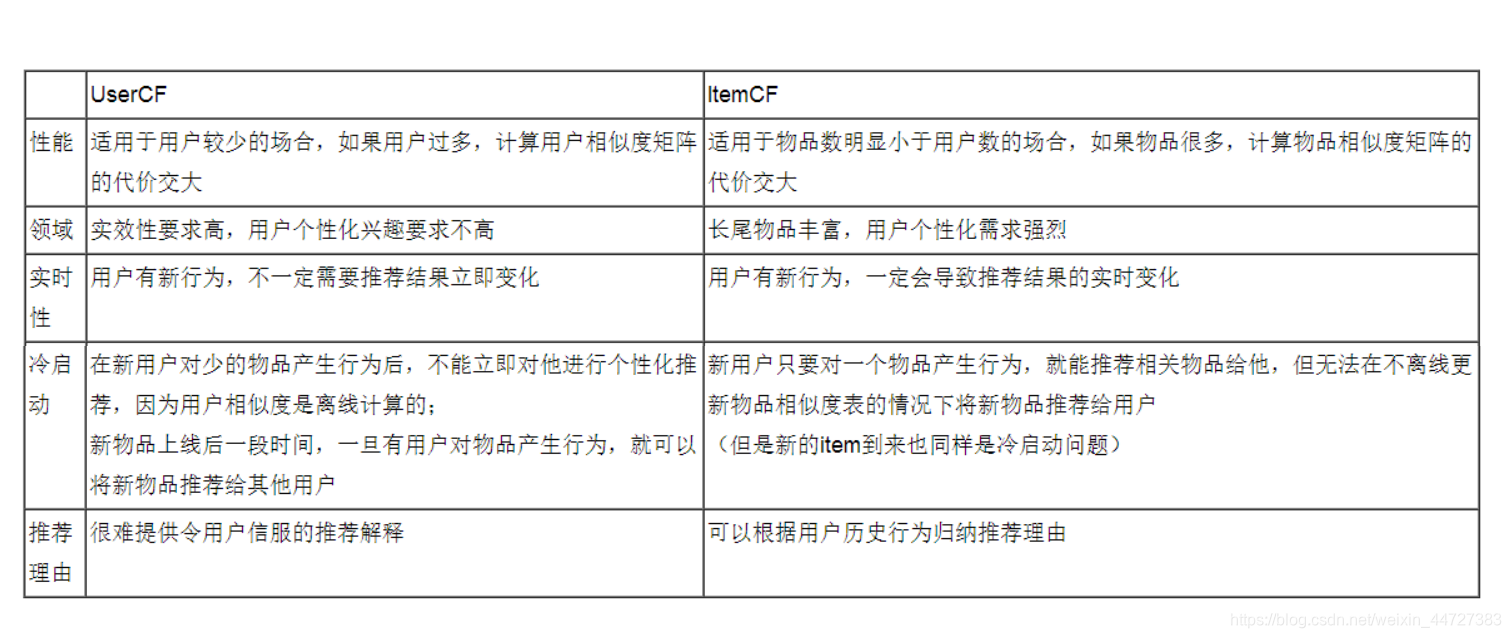



exemplo:
from surprise import KNNBasic,SVD
from surprise import Dataset
from surprise import evaluate, print_perf
# http://surprise.readthedocs.io/en/stable/index.html
# http://files.grouplens.org/datasets/movielens/ml-100k-README.txt
# Load the movielens-100k dataset (download it if needed),
# and split it into 3 folds for cross-validation.
data = Dataset.load_builtin('ml-100k')
data.split(n_folds=3)
# We'll use the famous KNNBasic algorithm.
algo = KNNBasic()
# Evaluate performances of our algorithm on the dataset.
perf = evaluate(algo, data, measures=['RMSE', 'MAE'])
print_perf(perf)
Evaluating RMSE, MAE of algorithm KNNBasic.
------------
Fold 1
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9876
MAE: 0.7807
------------
Fold 2
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9871
MAE: 0.7796
------------
Fold 3
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9902
MAE: 0.7818
------------
------------
Mean RMSE: 0.9883
Mean MAE : 0.7807
------------
------------
Fold 1 Fold 2 Fold 3 Mean
MAE 0.7807 0.7796 0.7818 0.7807
RMSE 0.9876 0.9871 0.9902 0.9883
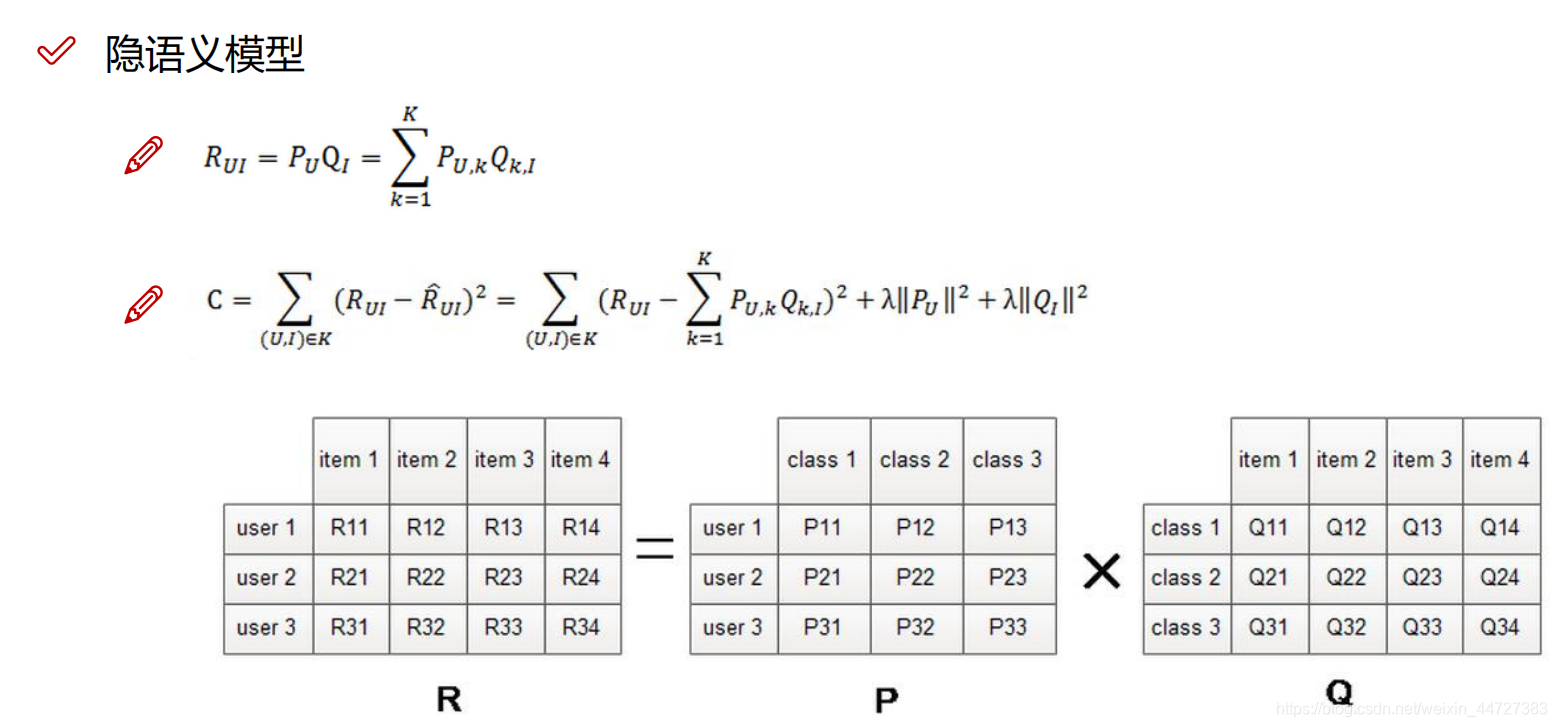
modelo de decomposição Matrix
from surprise import GridSearch
param_grid = {'n_epochs': [5, 10], 'lr_all': [0.002, 0.005],
'reg_all': [0.4, 0.6]}
grid_search = GridSearch(SVD, param_grid, measures=['RMSE', 'FCP'])
data = Dataset.load_builtin('ml-100k')
data.split(n_folds=3)
grid_search.evaluate(data)
------------
Parameters combination 1 of 8
params: {'lr_all': 0.002, 'n_epochs': 5, 'reg_all': 0.4}
------------
Mean RMSE: 0.9972
Mean FCP : 0.6843
------------
------------
Parameters combination 2 of 8
params: {'lr_all': 0.005, 'n_epochs': 5, 'reg_all': 0.4}
------------
Mean RMSE: 0.9734
Mean FCP : 0.6946
------------
------------
Parameters combination 3 of 8
params: {'lr_all': 0.002, 'n_epochs': 10, 'reg_all': 0.4}
------------
Mean RMSE: 0.9777
Mean FCP : 0.6926
------------
------------
Parameters combination 4 of 8
params: {'lr_all': 0.005, 'n_epochs': 10, 'reg_all': 0.4}
------------
Mean RMSE: 0.9635
Mean FCP : 0.6987
------------
------------
Parameters combination 5 of 8
params: {'lr_all': 0.002, 'n_epochs': 5, 'reg_all': 0.6}
------------
Mean RMSE: 1.0029
Mean FCP : 0.6875
------------
------------
Parameters combination 6 of 8
params: {'lr_all': 0.005, 'n_epochs': 5, 'reg_all': 0.6}
------------
Mean RMSE: 0.9820
Mean FCP : 0.6953
------------
------------
Parameters combination 7 of 8
params: {'lr_all': 0.002, 'n_epochs': 10, 'reg_all': 0.6}
------------
Mean RMSE: 0.9860
Mean FCP : 0.6943
------------
------------
Parameters combination 8 of 8
params: {'lr_all': 0.005, 'n_epochs': 10, 'reg_all': 0.6}
------------
Mean RMSE: 0.9733
Mean FCP : 0.6991
------------
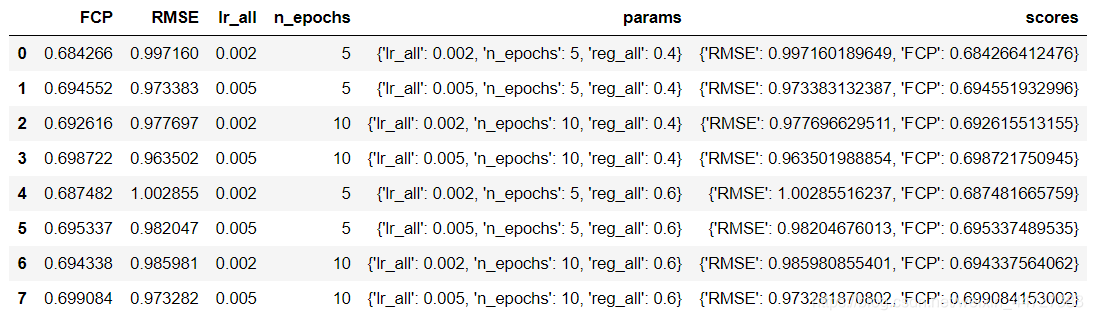
avaliação do impacto
import pandas as pd
results_df = pd.DataFrame.from_dict(grid_search.cv_results)
results_df
Com base em item de filtragem colaborativa
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import os
import io
from surprise import KNNBaseline
from surprise import Dataset
def read_item_names():
file_name = ('./ml-100k/u.item')
rid_to_name = {}
name_to_rid = {}
with io.open(file_name, 'r', encoding='ISO-8859-1') as f:
for line in f:
line = line.split('|')
rid_to_name[line[0]] = line[1]
name_to_rid[line[1]] = line[0]
return rid_to_name, name_to_rid
data = Dataset.load_builtin('ml-100k')
trainset = data.build_full_trainset()
sim_options = {'name': 'pearson_baseline', 'user_based': False}
algo = KNNBaseline(sim_options=sim_options)
algo.train(trainset)
usuários recomendados como 10 filmes
toy_story_neighbors = algo.get_neighbors(toy_story_inner_id, k=10)
toy_story_neighbors
toy_story_neighbors = (algo.trainset.to_raw_iid(inner_id)
for inner_id in toy_story_neighbors)
toy_story_neighbors = (rid_to_name[rid]
for rid in toy_story_neighbors)
print()
print('The 10 nearest neighbors of Toy Story are:')
for movie in toy_story_neighbors:
print(movie)
The 10 nearest neighbors of Toy Story are:
While You Were Sleeping (1995)
Batman (1989)
Dave (1993)
Mrs. Doubtfire (1993)
Groundhog Day (1993)
Raiders of the Lost Ark (1981)
Maverick (1994)
French Kiss (1995)
Stand by Me (1986)
Net, The (1995)
