Algoritmos de fatoração de matrizes e máquinas de fatoração
decomposição de matriz
idéia principal
O objetivo da decomposição de matrizes é preencher os dados ausentes na matriz de comportamento do usuário (elementos que os usuários não pontuam) por meio de aprendizado de máquina e, finalmente, atingir o objetivo de fazer recomendações para os usuários.
No sistema de recomendação, o comportamento de operação do usuário pode ser transformado na seguinte matriz de comportamento do usuário.
 O algoritmo de fatoração de matriz do comportamento de operação do usuário no objeto alvo é decompor a matriz de classificação do usuário no produto de duas matrizes.
O algoritmo de fatoração de matriz do comportamento de operação do usuário no objeto alvo é decompor a matriz de classificação do usuário no produto de duas matrizes.
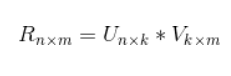
Entre eles, U representa a matriz de características do usuário e V representa a matriz de características do objeto alvo. Para avaliar um determinado objeto por um usuário, pode-se usar o produto da linha correspondente à matriz U (o vetor de características do usuário) e a coluna correspondente à matriz V (o vetor de características do objeto). Com a classificação do usuário do objeto de destino, é fácil fazer recomendações para o usuário. Especificamente, os seguintes métodos podem ser usados para fazer recomendações aos usuários: primeiro, o vetor de características do usuário pode ser
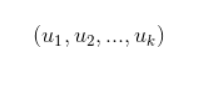
multiplicado pela matriz de características V e, finalmente, a pontuação do usuário para cada alvo pode ser obtida

, ou seja,
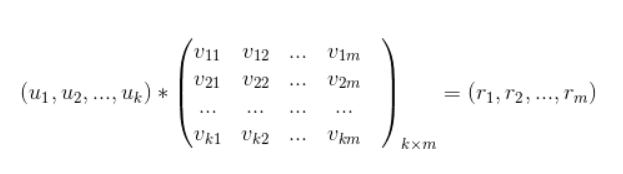
o alvo que o usuário operou é filtrada dos objetos de pontuação, as pontuações restantes do objeto de destino são classificadas em ordem decrescente e topN é recomendado ao usuário. A ideia central do algoritmo de fatoração de matrizes é decompor a matriz de comportamento do usuário no produto de duas matrizes de baixa classificação. Por meio da decomposição, incorporamos o usuário e o alvo no mesmo espaço vetorial k-dimensional (k é geralmente pequeno, dezenas de até 100 superiores), o produto interno do vetor do usuário e o vetor do objeto de destino representa a preferência do usuário pelo objeto de destino. Portanto, o algoritmo de fatoração de matrizes também é um método de incorporação em essência.
Cenários de aplicativos
1. Aplicado ao cenário de recomendação totalmente personalizado (paradigma de recomendação totalmente personalizado)
2. Aplicado ao cenário de objeto de destino relacionado ao objeto de destino (paradigma de objeto de destino relacionado ao objeto de destino)
3. Usado para cluster de usuário e objeto de destino
4. Aplicado a grupos Cenário personalizado (paradigma de recomendação personalizada do grupo)
Vantagens e desvantagens
1. Vantagens
O algoritmo de fatoração de matrizes, como um tipo especial de algoritmo de filtragem colaborativa, tem todas as vantagens do algoritmo de filtragem colaborativa, que são incorporadas em:
(1) Sem depender de outras informações do usuário e do alvo, ele só precisa do comportamento do usuário para fazer recomendações para os usuários.
O algoritmo de decomposição de matriz também é um tipo de algoritmo de filtragem colaborativa. Ele só precisa do comportamento do usuário para gerar resultados de recomendação para os usuários, sem a necessidade de usuários ou outras informações sobre o assunto, e essas outras informações geralmente são informações semiestruturadas ou não estruturadas, que são difíceis de processar e às vezes difíceis de obter. A fatoração matricial é uma classe de algoritmos independentes de domínio, portanto, essa vantagem permite que o algoritmo de fatoração matricial seja aplicado basicamente a todos os cenários de recomendação, o que também é uma importante razão pela qual o algoritmo de fatoração matricial é muito popular na indústria.
(2) A precisão da recomendação é boa.
O algoritmo de fatoração de matrizes é um tipo de algoritmo muito importante entre os algoritmos vencedores na competição de recomendações da Netflix. Muito bom.
(3) Pode recomendar alvos surpreendentes para os usuários.
O algoritmo de filtragem colaborativa usa a sabedoria do grupo para recomendar aos usuários e tem a capacidade de recomendar alvos diferenciados e surpreendentes para os usuários. Algoritmo de decomposição de matriz, como uma classe de algoritmos de filtragem colaborativa, é baseado em O algoritmo do fator oculto, é claro, também tem essa vantagem, e ainda tem um efeito melhor do que os algoritmos de filtragem colaborativa baseados em usuário e baseado em item.
(4) Facilidade de paralelização
A decomposição de matrizes é muito fácil de paralelizar, e o Spark MLlib usa o algoritmo ALS para decomposição de matrizes distribuídas.
2. Desvantagens
As vantagens de tantos algoritmos de decomposição de matrizes foram descritas acima, além dessas vantagens, a decomposição de matrizes apresenta defeitos nos dois pontos seguintes, que precisam ser compensados ou evitados por outros métodos.
(1) Há um problema de inicialização a frio
Quando um usuário tem poucos comportamentos de usuário, basicamente não podemos usar a decomposição de matriz para obter uma representação de autovetor mais precisa do usuário, portanto, é impossível gerar resultados de recomendação para o usuário . Neste momento, um algoritmo de recomendação de conteúdo pode ser usado para gerar uma recomendação para o usuário. O mesmo vale para o assunto recém-armazenado, o assunto pode ser exposto adequadamente por arranjo manual para obter mais operações do usuário sobre o assunto, de modo a facilitar o algoritmo de recomendação do assunto. A referência 9 fornece um algoritmo eficaz lightFM para resolver o problema de partida a frio de decomposição de matriz. Ao integrar informações de metadados na decomposição de matriz, ele pode resolver efetivamente o problema de partida a frio. Tem um melhor efeito de recomendação para os objetos de destino de mais comportamentos do usuário. O algoritmo lightFM deste artigo tem a implementação do código python correspondente no github (consulte https://github.com/lyst/lightfm), que pode ser usado como um bom material de aprendizado.
(2) A interpretabilidade não é forte.
O algoritmo de decomposição de matrizes obtém a representação de recursos (embutida) do usuário e do alvo através da decomposição de matrizes. Esses recursos são implícitos e não podem ser explicados pelos recursos exibidos na realidade. Portanto, a decomposição de matrizes algoritmo é usado para fazer Não podemos explicar os resultados da recomendação, e só podemos avaliar o efeito do algoritmo através de avaliação offline ou online . Ao contrário dos algoritmos de filtragem colaborativa baseados em usuários e itens, que se baseiam na ideia muito simples de "as coisas se agrupam e as pessoas se agrupam", eles podem ser facilmente explicados.
máquina de fatoração
ideia básica
Máquina de fatoração (FM abreviada, conhecida como máquina de fatoração em chinês), a ideia central deste algoritmo vem do algoritmo de fatoração de matrizes, que pode ser considerado um caso especial da máquina de fatoração.
Diferente do modelo linear simples tradicional, a máquina de fatoração considera a interseção entre recursos e modelos de todas as interações variáveis de recursos (semelhante à função kernel no SVM), portanto, a taxa de cliques de interesse em sistemas de recomendação e campos de publicidade computacional. (taxa de cliques) e taxa de conversão CVR (taxa de conversão) têm bom desempenho. Além disso, o modelo FM também tem as vantagens de poder ser calculado em tempo linear, integrando uma variedade de informações e podendo se fundir com muitos outros modelos.
Nossos modelos simples comumente usados incluem modelo de regressão linear e modelo de regressão logística (LR) (veja as duas fórmulas a seguir), que são modelos lineares simples com princípios simples, fáceis de entender e muito fáceis de treinar. Para problemas gerais de classificação e previsão, pode fornecer uma solução simples. No entanto, os recursos são independentes uns dos outros e a relação não linear entre os recursos não pode ser ajustada. Na vida real, os recursos geralmente não são independentes, mas têm uma certa relação interna. Tomando como exemplo a recomendação de notícias, o usuário masculino médio vê Há muitas notícias militares e usuários do sexo feminino gostam de notícias emocionais, então pode-se ver que há uma certa correlação entre gênero e categorias de notícias. É muito significativo encontrar esses recursos relacionados, que podem melhorar significativamente a precisão do modelo previsão. Gaste.

O modelo LR é o modelo de maior sucesso no estágio inicial do campo de previsão de CTR e também é amplamente utilizado no estágio de classificação do algoritmo de recomendação. A maioria dos sistemas de classificação de recomendações industriais integra recursos não lineares artificiais e, finalmente, usa este " modelo linear + combinação de recursos artificiais para introduzir o modo ". não linear para treinar o modelo LR. Como o modelo LR tem muitas vantagens, como simplicidade, conveniência e facilidade de uso, forte interpretação e fácil implementação distribuída, ainda existem muitos sistemas de algoritmos na indústria que adotam esse modelo. No entanto, a maior falha do modelo LR é a engenharia manual de recursos, que é demorada e trabalhosa e desperdiça muitos recursos humanos para selecionar e combinar recursos não lineares. A capacidade de combinação de recursos pode ser refletida no nível do modelo ? Ou seja, existe um modelo que possa combinar e filtrar automaticamente recursos cruzados? A resposta é sim. Na verdade, não é difícil conseguir isso. Como mostrado na figura acima, a combinação de recursos de segunda ordem pode ser adicionada à fórmula de cálculo do modelo linear. Quaisquer dois recursos podem ser combinados em pares e os recursos combinados podem ser considerado como um novo recurso, adicionando linear no modelo. O peso do recurso combinado é igual ao peso do recurso de primeira ordem, que é aprendido na fase de treinamento. De fato, o uso dessa combinação de recursos de segunda ordem é equivalente ao kernel polinomial SVM. Com a ideia da função kernel no SVM, podemos integrar o recurso cruzado de segunda ordem no modelo linear para obter o seguinte modelo.

Então, temos uma solução para este problema? Na verdade existe,Podemos usar a ideia de decomposição de matrizes para ajustar os coeficientes das características cruzadas de segunda ordem, para que os coeficientes não sejam independentes e irrelevantes, reduzindo assim o número de coeficientes independentes do modelo e resolvendo o problema que os parâmetros não pode ser treinado devido a dados esparsos, especificamente, o modelo acima é modificado

para que não haja dados de treinamento suficientes para suportar o treinamento do modelo no caso esparso, e um k menor é geralmente selecionado. Embora o espaço de expressão do modelo fique menor, ele pode alcançar um melhor desempenho no caso esparso case., e tem boa escalabilidade.
Complexidade computacional

Como o modelo da máquina de decomposição pode ser calculado em tempo linear, é muito valioso para nós fazer previsões, especialmente para produtos de Internet com um grande número de usuários. Tome a recomendação como exemplo, precisamos calcular a recomendação para cada usuário todos os dias (esta é uma recomendação offline, o cálculo de recomendação em tempo real será maior), a complexidade do tempo linear pode tornar todo o processo de cálculo mais eficiente e o cálculo pode ser concluído em um tempo menor, Economize recursos do servidor.
inscrição
A máquina de decomposição pode ser usada como um modelo geral de previsão para regressão e classificação, especialmente em cenários de negócios, como sistemas de recomendação e estimativa de taxa de cliques em anúncios. A aplicação da máquina de decomposição no sistema de recomendação pode utilizar dois tipos de métodos: regressão e predição. Quando prevemos a classificação do usuário no alvo, é um problema de regressão. Quando prevemos se o usuário clica no alvo, pode ser considerado um problema de duas classes. Neste momento, podemos adicionar uma transformação logit para prever a pergunta de probabilidade de clique do usuário.
Como construir os recursos requeridos pelo FM e quais informações podem ser usadas como entrada do modelo. Os recursos da construção de modelos FM são divididos principalmente nas quatro categorias a seguir , que apresentaremos separadamente.
1. Informações interativas de comportamento entre o usuário e o objeto de destino,
incluindo vários comportamentos (implícitos), como clique, reprodução, favorito, pesquisa e curtidas do usuário. Esses comportamentos podem ser integrados em recursos por meio de nivelamento. Por exemplo, existem n usuários e m objetos. Em seguida, o comportamento do usuário em um determinado destino é achatado em um subvetor de recurso n+m-dimensional, onde a coluna onde o usuário e o destino estão localizados é diferente de zero e as demais são zero, conforme mostrado na figura a seguir .
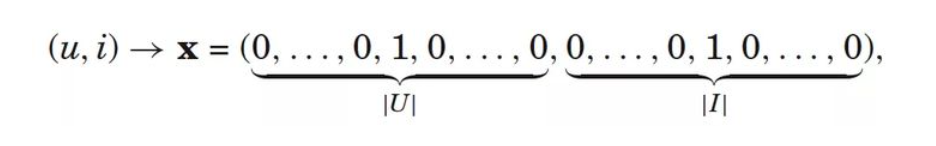
A figura acima mostra que a operação implícita do comportamento do usuário é convertida em um subvetor de recurso. O recurso é representado por 0 ou 1. Se houver uma operação implícita, é 1, caso contrário, é 0. Também é possível usar cada operação do usuário como uma dimensão, e o valor de cada dimensão representa se o usuário executou uma operação ou a pontuação da operação correspondente (por exemplo, a razão entre o tempo de reprodução do usuário e o tempo total de vídeo é a pontuação), conforme mostrado na figura a seguir.

2. Informações relacionadas ao usuário
Há muitas informações relacionadas ao usuário, incluindo informações demográficas, como idade, sexo, ocupação, renda, região, nível de educação e assim por diante. Além disso, também pode incluir informações sobre o comportamento do usuário, se o usuário é membro, quando se registrou, o último horário de login, o último horário de pagamento, etc. Essas informações podem ser injetadas no modelo FM como uma característica de uma determinada dimensão.
3. Informações sobre
o assunto As informações de metadados do assunto podem ser usadas como um recurso do FM. Tome como exemplo a recomendação de filme, a classificação do filme, idade, gravadora, elenco e equipe, se ganhou o prêmio, se foi é de alta definição, região, idioma, se é um programa pago, etc. podem ser usados como recursos. Entre eles, classificação e idade são recursos numéricos, e rótulos e atores são recursos de categoria, que podem ser codificados por n-hot (cada filme possui vários rótulos e o valor no rótulo correspondente é 1, por isso é chamado de n-hot codificação aqui, não um -hot). Além disso, o comportamento do usuário do programa também pode ser usado como um recurso, como o número de vezes que o programa é reproduzido, o grau médio de conclusão do programa e similares.
4. Informações contextuais
Quando o usuário opera o objeto alvo, as informações contextuais são incluídas. Tais contextos 
incluem principalmente tempo, local, operação anterior, caminho e até clima, humor, etc. A hora pode ser a hora da operação, seja feriado, seja dia útil, um evento especial (como Double Eleven), um sistema operacional, uma versão, etc. A região é muito importante para aplicativos LBS. Para produtos ou negócios com conversão de comportamento de funil, como compras, a operação e o caminho anteriores do usuário são fundamentais para o treinamento do modelo. Depois de integrar as quatro categorias de informações acima, podemos construir o seguinte conjunto de treinamento, usar o modelo FM para treinar, obter os parâmetros e, finalmente, obter o modelo treinado para previsão online.
Vantagem
As vantagens do desintegrador
A razão pela qual o FM é procurado na academia e na indústria deve-se às suas várias vantagens, que se refletem principalmente nos seguintes aspectos.
(1) Ele pode integrar recursos cruzados e o efeito é bom.
Em cenários de negócios reais, o cruzamento entre recursos geralmente é muito útil para a previsão do modelo, e a máquina de decomposição pode integrar automaticamente recursos cruzados de segunda ordem (ordem alta), eliminando a necessidade de trabalho manual A engenharia de recursos (como regressão logística requer muita engenharia de recursos manual) trabalha, de modo que (em comparação com modelos como decomposição de matriz e regressão logística), melhores resultados de treinamento possam ser alcançados.
(2) Complexidade de tempo linear
FM reduz o cálculo de recursos cruzados de segunda ordem de complexidade polinomial de segunda ordem para complexidade linear, transformando matematicamente a função de previsão, que é conveniente para previsão de modelo e estimativa de parâmetro por meio de métodos iterativos, como SGD, de modo que A aplicação do FM em cenários de dados de larga escala na indústria (sistemas de recomendação, estimativa de CTR, etc.) torna-se viável.
(3) Ele pode lidar com a situação de dados esparsos.
Ao decompor os coeficientes dos traços cruzados de segunda ordem em um espaço de baixa dimensão, FM evita a independência dos coeficientes dos traços cruzados, reduz o espaço paramétrico e porque o coeficientes entre diferentes termos cruzados estão relacionados. , no caso de alta esparsidade, os coeficientes do modelo também podem ser facilmente estimados, e o modelo tem forte capacidade de generalização.
(4) O modelo é relativamente simples e fácil de implementar em engenharia. O
princípio do modelo FM é muito simples, e a ideia é muito simples, e o processo de previsão pode ser reduzido a uma complexidade de tempo linear. Algoritmos comuns como SGD podem ser usado para treinamento, que é relativamente fácil de implementar em engenharia. , existem muitas ferramentas de código aberto com implementação FM, podemos usá-lo diretamente. É justamente pela simplicidade do projeto que ele vem sendo amplamente divulgado e aplicado na indústria.