Olá a todos, hoje vou resumir para vocês o modelo de fusão de aprendizado de máquina python: Stacking and Blending (com código).
1 Método de empilhamento Empilhamento
Um sistema fraco pode tornar-se um sistema forte?

Quando se depara com um problema de classificação complexo, como é frequentemente o caso nos mercados financeiros, podem surgir diferentes abordagens na procura de uma solução . Embora esses métodos possam estimar classificações, às vezes nenhum deles é melhor que outras classificações. Neste caso, a escolha lógica é mantê-los todos e depois criar o sistema final integrando as partes. Esta abordagem diversificada é uma das mais convenientes: divida a sua decisão entre vários sistemas para evitar colocar todos os ovos na mesma cesta.
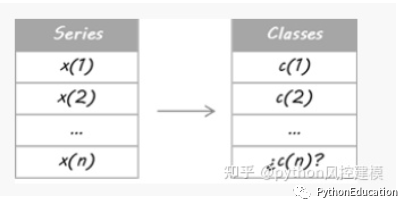
Depois de ter um grande número de estimativas para esta situação, como posso combinar as decisões de N subsistemas? Como resposta rápida, posso tomar uma decisão mediana e usá-la. Mas existe uma maneira diferente de utilizar totalmente meu subsistema? Claro!
Pense criativamente!
Vários classificadores com um objetivo comum são chamados de multiclassificadores . No aprendizado de máquina, um multiclassificador é um conjunto de diferentes classificadores que são estimados e fundidos para obter um resultado que os combina. Muitos termos são usados para se referir a multiclassificadores: multimodelo, sistema multiclassificador, classificador de combinação, comitê de decisão, etc. Eles podem ser divididos em duas categorias principais:
Abordagem integrada: refere-se ao uso da mesma tecnologia de aprendizagem para combinar um conjunto de sistemas para criar um novo sistema. O ensacamento e o levantamento são os mais prolongados. Métodos híbridos: pegar um grupo diversificado de alunos e combiná-los usando novas tecnologias de aprendizagem. O empilhamento (ou generalização empilhada) é um dos principais multiclassificadores híbridos.
Como construir um multiclassificador desenvolvido com Stacking.
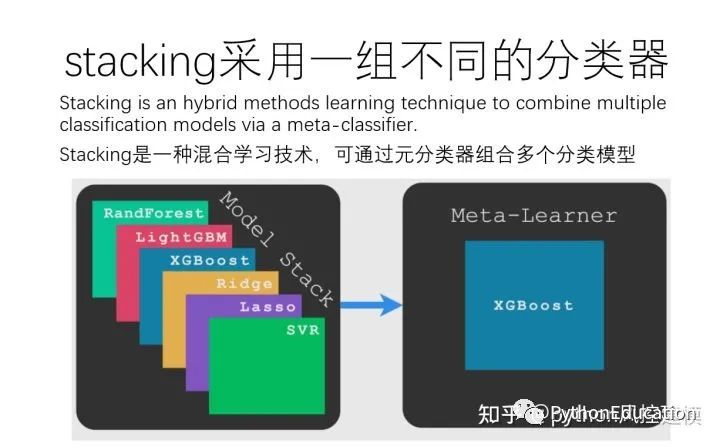
fluxo de trabalho de empilhamento

.
Os metaclassificadores podem ser treinados em rótulos de classes previstas ou em probabilidades de classes previstas.
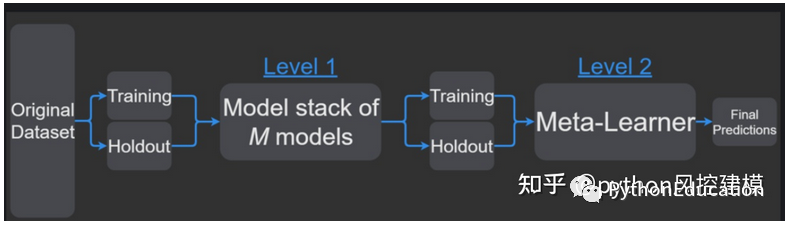
Dê um exemplo de empilhamento para prever a tendência do EURUSD
Imagine que eu quero estimar a tendência do EURUSD (tendência EUR/USD). Primeiro, transformei meu problema em um problema de classificação, então separei os dados de preços em dois tipos (ou classes): movimentos ascendentes e descendentes. Não é minha intenção adivinhar cada movimento que faço todos os dias. Quero apenas detectar as principais tendências: negociações longas para cima (classe = 1) e negociações curtas para baixo (classe = 0).
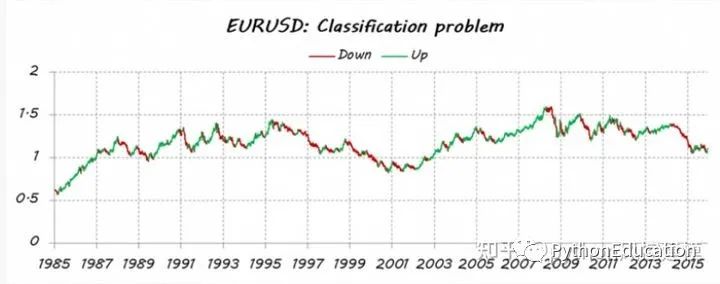
Eu fiz uma divisão a posteriori, ou seja, todos os dados históricos são usados para decidir as classes, então leva em consideração algumas informações futuras. Portanto, atualmente não posso garantir movimento para cima ou para baixo. Portanto, é necessária uma estimativa para o curso de hoje.
Para os fins deste exemplo, projetei três sistemas separados. Eles são três alunos diferentes usando diferentes conjuntos de atributos. Não importa se você usa o mesmo algoritmo de aprendizado ou se eles compartilham algumas/todas as propriedades; a questão é que eles devem ser diferentes o suficiente para garantir a diversidade.
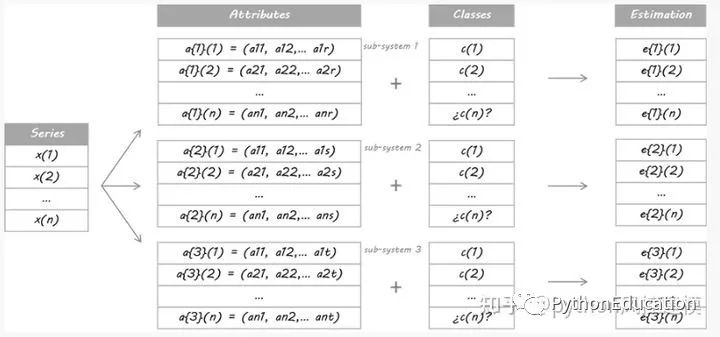
Eles então negociam com base nestas probabilidades: se E estiver acima de 50%, isso significa operar comprado, quanto maior E. Se E for inferior a 50%, é uma entrada curta, menor será o E.
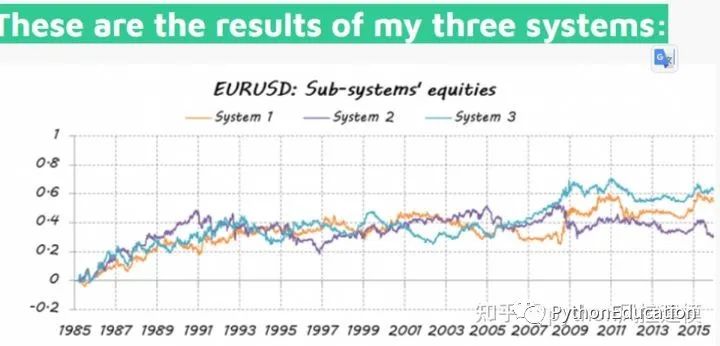
Não é o ideal, apenas melhor que aleatório
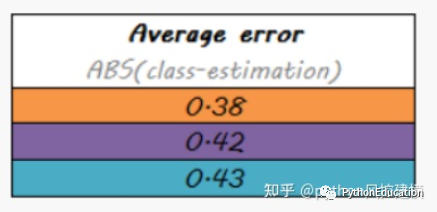
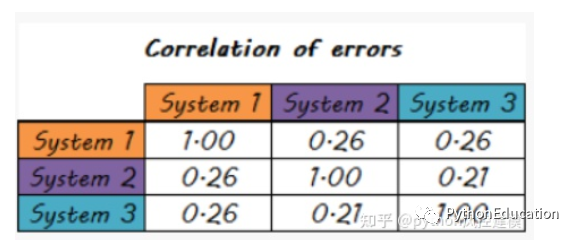
Erros sistemáticos também estão menos correlacionados
Um time dos sonhos pode ser formado a partir de um grupo de jogadores mais fracos? O objetivo de construir múltiplos classificadores é alcançar um melhor desempenho preditivo do que qualquer classificador único pode alcançar. Vamos ver se este é o caso.
O método que usarei neste exemplo é baseado no algoritmo Stacking. A ideia do Stacking é que a saída de um classificador principal denominado modelo de nível 0 seja usada como atributos de outro classificador denominado metamodelo para aproximar o mesmo problema de classificação. Resta ao metamodelo descobrir o mecanismo de fusão. Será responsável por conectar a resposta e a classificação verdadeira do modelo nível 0.
O procedimento rigoroso envolve a divisão do conjunto de treinamento em conjuntos disjuntos. Em seguida, treine cada aluno do nível 0 com todos os dados, exclua um grupo e aplique-o ao grupo excluído. Ao repetir para cada grupo, uma estimativa de cada dado é obtida para cada aluno. Essas estimativas se tornarão os atributos do metamodelo treinado ou modelo de nível 1. Como meus dados são uma série temporal, decidi usar o conjunto do dia 1 ao dia d-1 para construir a estimativa para o dia d.
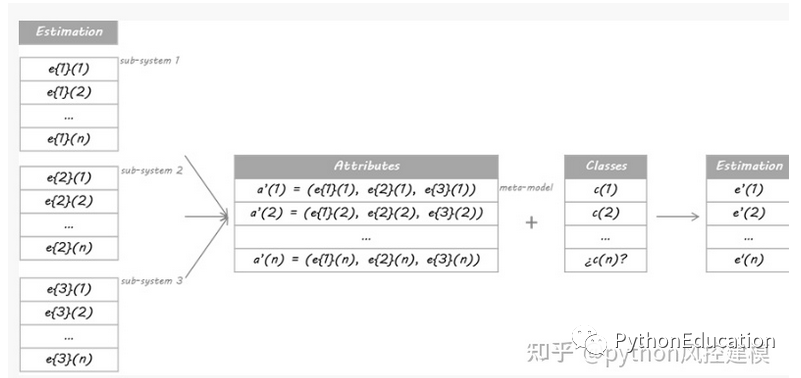
Com qual modo isso funciona? Os metamodelos podem ser árvores de classificação, florestas aleatórias, máquinas de vetores de suporte... qualquer aluno de classificação é válido. Para este exemplo, optei por usar o algoritmo do vizinho mais próximo. Isso significa que o metamodelo estimará as categorias de novos dados para descobrir configurações semelhantes de classificações de classe 0 em dados anteriores e, então, atribuirá categorias a essas situações semelhantes.
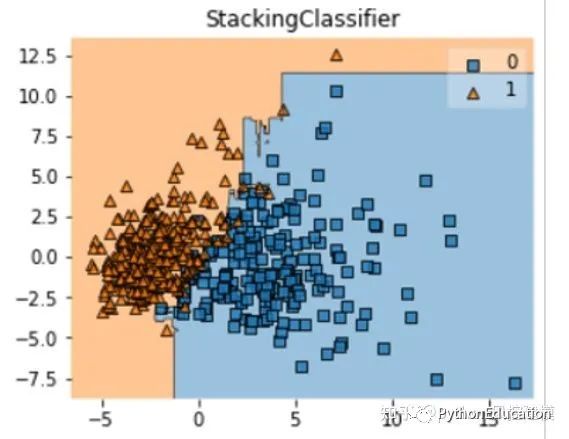
Vamos ver o quão bem meu time dos sonhos ficou…
O valor médio do erro do modelo de empilhamento é o mais baixo
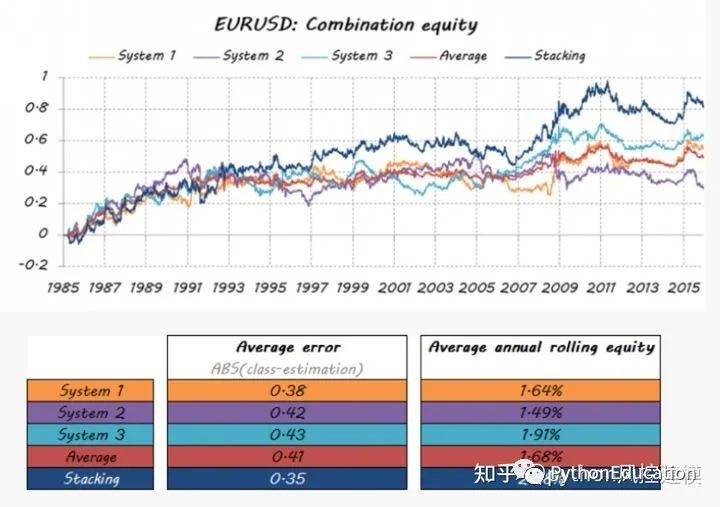
Conclusão Este é apenas um exemplo do grande número de multiclassificadores disponíveis. Eles não só podem ajudá-lo a incorporar parte da sua solução em uma resposta única por meio de técnicas modernas e originais, mas também podem criar uma equipe verdadeiramente dos sonhos. Há também espaço significativo para melhorias na forma como os componentes individuais são integrados num sistema.
Então, da próxima vez que precisar de uma combinação, gaste um pouco mais de tempo pesquisando as possibilidades. Evite as médias tradicionais e explore abordagens mais sofisticadas através da força do hábito. Eles podem oferecer desempenho extra
Aplicação de fusão de modelos na competição kaggle
A fusão de modelos é uma técnica muito poderosa que pode melhorar a precisão de várias tarefas de ML. Neste artigo, compartilharei meu método de integração para competições Kaggle.
Na primeira parte, veremos como criar uma integração a partir de um arquivo commit. A segunda parte examinará a criação de conjuntos por meio de generalização/hibridização empilhada.
Eu respondo por que o conjunto reduz erros de generalização. Por fim, mostro diferentes métodos de integração, juntamente com seus resultados e código para você experimentar. Guia Kaggle Ensembling Eu respondo por que os conjuntos reduzem erros de generalização. Por fim, mostro diferentes métodos de integração, juntamente com seus resultados e código para você experimentar.
O método de geração empilhada é um método completamente diferente de combinar vários modelos. Ele fala sobre o conceito de alunos combinados, mas é menos usado do que bagging e boosting. Não é como bagging e boosting, mas combina diferentes modelos. , o processo específico é o seguinte:
1. Divida o conjunto de dados de treinamento em dois conjuntos disjuntos.
2. Treine vários alunos no primeiro conjunto.
3. Teste esses alunos no segundo conjunto.
4. Use os resultados de previsão obtidos na terceira etapa como entrada e a resposta correta como saída para treinar um aluno de alto nível. O que
precisa ser prestado atenção aqui são as etapas 1-3 . Efeito e validação cruzada, não usamos o vencedor leva tudo, mas usamos um método de aprendizagem de combinação não linear
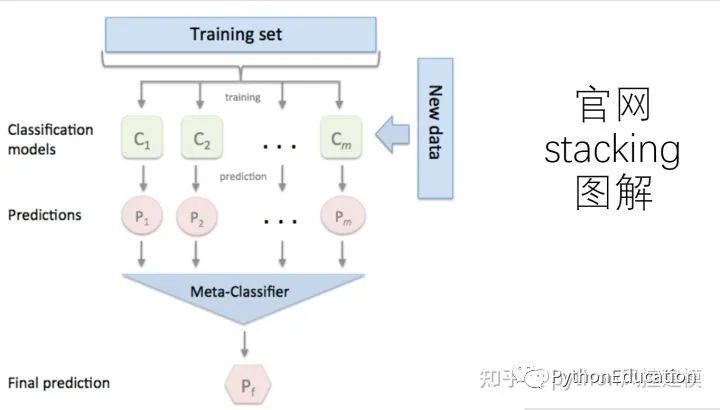
Todos os modelos base treinados serão usados para prever todo o conjunto de treinamento. O valor previsto do j-ésimo modelo base para a i-ésima amostra de treinamento será usado como o j-ésimo valor do recurso da i-ésima amostra na nova conjunto de treinamento.Finalmente, com base no novo conjunto de treinamento para treinamento. Da mesma forma, o processo de previsão deve primeiro passar pelas previsões de todos os modelos básicos para formar um novo conjunto de testes e, finalmente, prever o conjunto de testes:
Abaixo apresentamos uma poderosa ferramenta de empilhamento, a biblioteca mlxtend, que pode empilhar rapidamente o modelo sklearn.
StackingClassifier usa API e análise de parâmetros:
StackingClassifier(classificadores, meta_classificador, use_probas=False, Average_probas=False, detalhado=0, use_features_in_secondary=False)
parâmetro:
classificadores: classificador base, forma de array, [cl1, cl2, cl3]. Os atributos de cada classificador base são armazenados no atributo de classe self.clfs_. meta_classifier : classificador de destino, que é o classificador que
combina os classificadores anteriores
use_probas: bool ( padrão: False), se definido como True, então a entrada do classificador de destino será o valor de probabilidade da categoria da saída da classificação anterior em vez do rótulo da categoria Average_probas: bool (padrão: False), usado para definir o parâmetro anterior ao usar
o saída do valor de probabilidade Se deve usar o valor médio quando
detalhado: int, opcional (padrão=0). Usado para controlar a saída do log durante o uso. Quando detalhado = 0, nada é gerado. Quando detalhado = 1, o número de série e o nome do regressor são exibidos. verbose = 2, gera informações detalhadas dos parâmetros. detalhado > 2, define automaticamente verboso como menor que 2, detalhado -2.
use_features_in_secondary : bool (padrão: False). Se definido como True, o classificador de destino final serão os dados gerados pelo classificador base e o conjunto de dados original Train at o mesmo tempo. Se definido como False, o classificador final só será treinado usando os dados produzidos pelo classificador base.
Atributos:
clfs_: atributos de cada classificador base, lista, forma são [n_classificadores].
meta_clf_: atributos do classificador de destino final
método:
fit(X, y)
fit_transform(X, y=None, fit_params)
get_params(deep=True), se o método GridSearch do sklearn for usado, os parâmetros do classificador serão retornados.
prever (X)
prever_proba (X)
pontuação (X, y, sample_weight = Nenhum), para um determinado conjunto de dados e um determinado rótulo, retornar a precisão da avaliação
set_params (params), definir os parâmetros do classificador, o método de configuração de params é o mesmo do sklearn O formato é o mesmo
Parte do código real do modelo de fusão python
-
from sklearn.datasets import load_iris -
from mlxtend.classifier import StackingClassifier -
from mlxtend.feature_selection import ColumnSelector -
from sklearn.pipeline import make_pipeline -
from sklearn.linear_model import LogisticRegression -
pipe1 = make_pipeline(ColumnSelector(cols=(0, 2)), -
LogisticRegression()) -
pipe2 = make_pipeline(ColumnSelector(cols=(1, 2, 3)), -
LogisticRegression()) -
sclf = StackingClassifier(classifiers=[pipe1, pipe2], -
meta_classifier=LogisticRegression())
1.1 Ideia básica do método de empilhamento
O método de empilhamento é o método mais popular na área de fusão de modelos nos últimos anos. Não é apenas um dos métodos de fusão mais utilizados pelas equipes campeãs de competição, mas também uma das soluções que serão consideradas na implementação efetiva da inteligência artificial. na indústria. Como um método de fusão para alunos fortes, o Stacking combina as três principais vantagens de um bom efeito de modelo, forte interpretabilidade e adaptabilidade a dados complexos.É o método pioneiro mais prático no campo da fusão. Entre as muitas aplicações de empilhamento, o empilhamento prático GBDT+LR em CTR (previsão da taxa de cliques publicitários) é particularmente famoso. Portanto, no curso principal " Prática de aprendizado de máquina 2022 ", depois de explicar os métodos comuns de empilhamento, explicarei em detalhes o uso de GBDT+LR no CTR e concluirei uma prática de CTR.
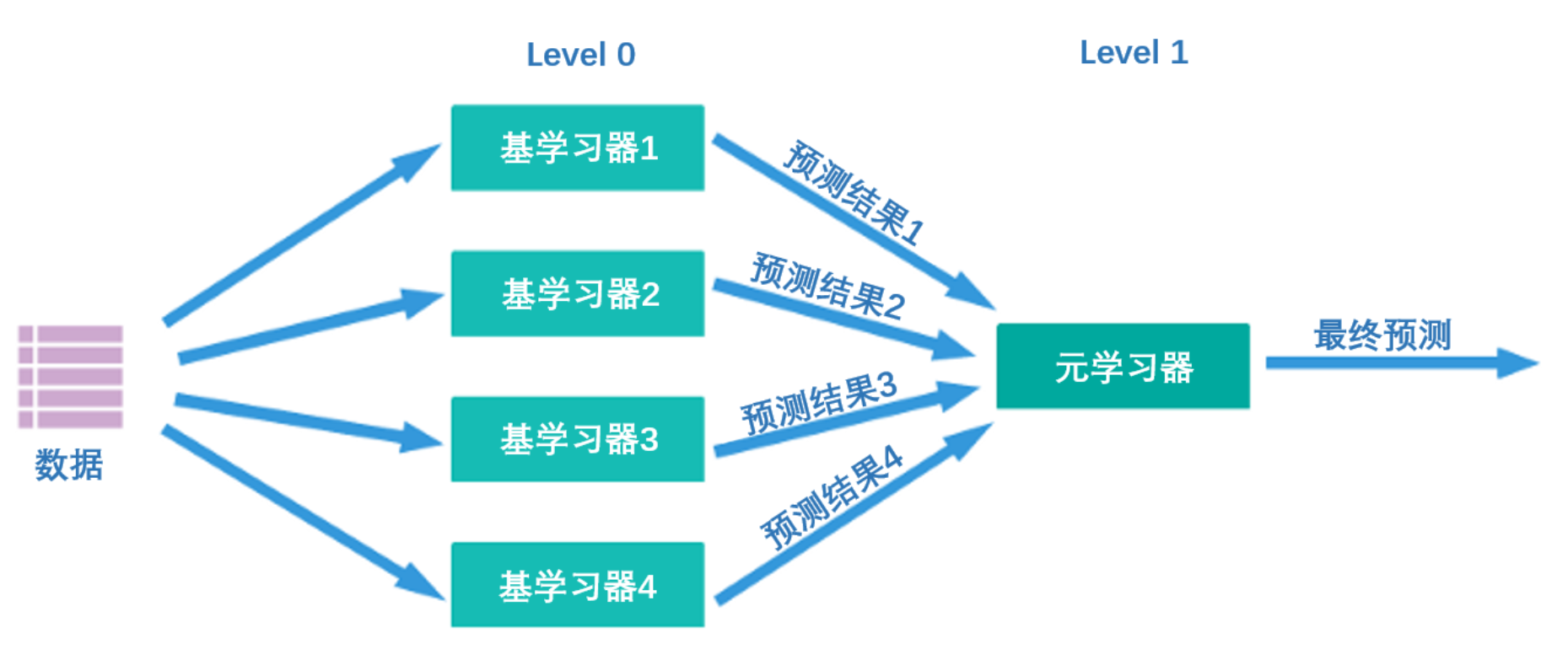
Que tipo de algoritmo é empilhamento? Sua ideia central é na verdade muito simples - primeiro, conforme mostrado na figura abaixo, existem duas camadas de algoritmos na estrutura de empilhamento, a primeira camada é chamada de nível 0 e a segunda camada é chamada de nível 1. O nível 0 pode conter um ou algoritmos mais fortes. Aluno, enquanto o nível 1 pode conter apenas um aluno. Durante o treinamento, os dados serão primeiro inseridos no nível 0. Após o treinamento, cada algoritmo no nível 0 produzirá os resultados de previsão correspondentes. Reunimos esses resultados de previsão em uma nova matriz de recursos e, em seguida, inserimos no algoritmo de nível 1 para treinamento. O resultado final da previsão produzido pelo modelo de fusão é o resultado produzido pelo aluno de nível 1.
Neste processo, os resultados da previsão gerados pelo nível 0 são geralmente organizados da seguinte forma:
| Aluno 1 | Aluno 2 | ... | aprender | |
|---|---|---|---|---|
| Amostra 1 | xxx | xxx | ... | xxx |
| Amostra 2 | xxx | xxx | ... | xxx |
| Amostra 3 | xxx | xxx | ... | xxx |
| ... | ... | ... | ... | ... |
| Amostra m | xxx | xxx | ... | xxx |
A primeira coluna é o resultado produzido pelo aluno 1 em todas as amostras, a segunda coluna é o resultado produzido pelo aluno 2 em todas as amostras e assim por diante.
Ao mesmo tempo, vários alunos fortes treinados no nível 0 são chamados de alunos básicos (modelo base), também chamados de alunos individuais. O aluno treinado no nível 1 é denominado meta-aluno (metamodelo). De acordo com a prática da indústria, os alunos no nível 0 são alunos com alta complexidade e fortes capacidades de aprendizagem , como algoritmos de conjunto e máquinas de vetores de suporte, enquanto os alunos no nível 1 são alunos com forte interpretabilidade e capacidades relativamente simples , como árvores de decisão, regressão linear , regressão logística, etc. Existe tal exigência porque a responsabilidade dos algoritmos no nível 0 é encontrar a relação entre os dados originais e o rótulo, ou seja, estabelecer a hipótese entre os dados originais e o rótulo, por isso requer fortes capacidades de aprendizagem. No entanto, a responsabilidade do algoritmo no nível 1 é fundir as suposições feitas pelos alunos individuais e, finalmente, produzir os resultados do modelo de fusão, o que equivale a encontrar a "melhor regra de fusão", em vez de estabelecer suposições diretamente entre os dados originais. e rótulos.
Falando nisso, me pergunto se você notou que a essência do Stacking é deixar o algoritmo descobrir as regras de fusão . Embora a maioria das pessoas nunca tenha sido exposta a uma estrutura de série semelhante ao algoritmo de empilhamento, na verdade o processo de empilhamento é completamente consistente com o método de votação e o método de média:
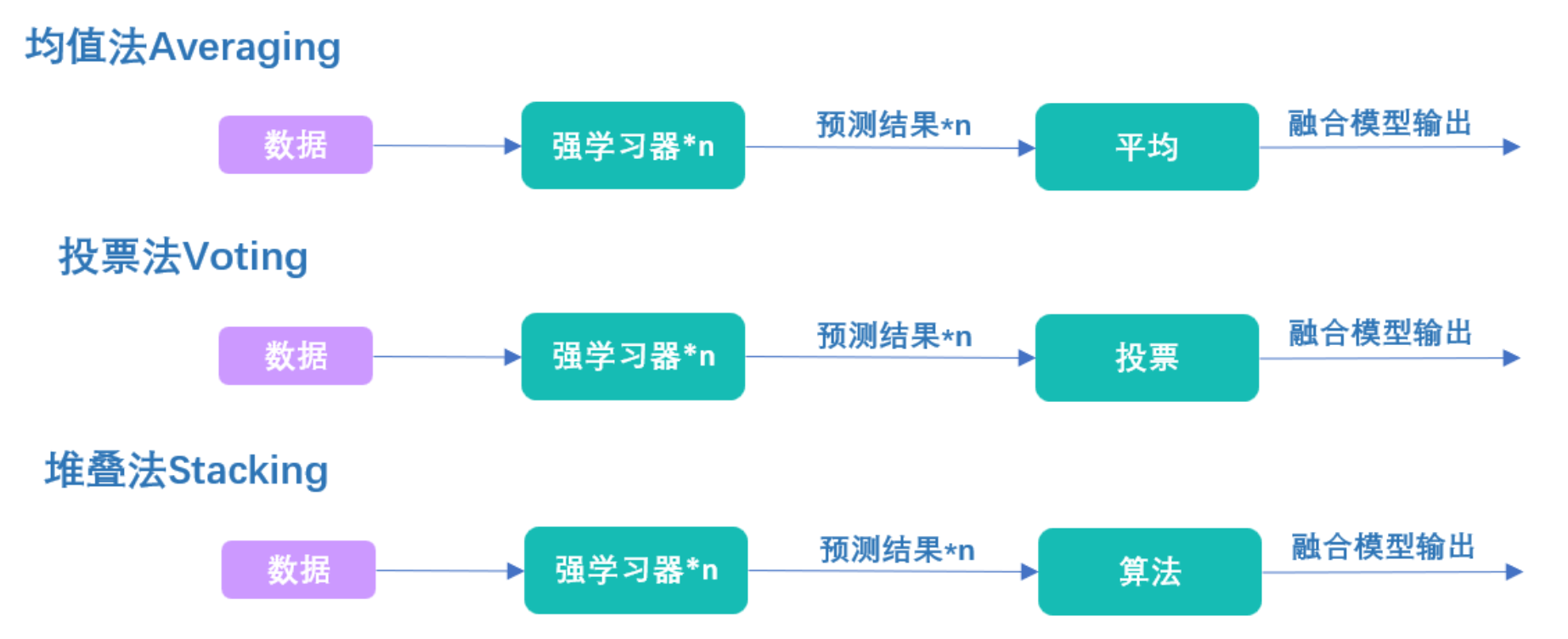
No método de votação, usamos a votação para fundir os resultados de alunos fortes. No método de média, usamos a média para fundir os resultados de alunos fortes. No método de empilhamento, usamos algoritmos para fundir os resultados de alunos fortes. Quando o algoritmo no nível 1 é a regressão linear, estamos na verdade resolvendo a soma ponderada de todos os resultados fortes do aluno, e o processo de treinamento da regressão linear é o processo de encontrar o peso da soma ponderada. Da mesma forma, quando o algoritmo no nível 1 é a regressão logística, estamos na verdade resolvendo a soma ponderada de todos os resultados fortes do aluno e, em seguida, aplicando a função sigmóide com base na soma. O processo de treinamento de regressão logística é o processo de encontrar os pesos da soma ponderada. O mesmo vale para qualquer outro algoritmo simples.
Embora para a maioria dos algoritmos seja difícil encontrar um nome claro como "soma ponderada" para resumir as regras de fusão encontradas pelo algoritmo, mas em essência, o algoritmo de nível 1 está apenas aprendendo como combinar os resultados gerados no nível 0. Melhor combinados, então Stacking é um método para fundir os resultados do aluno treinando o aluno . O método de cálculo da média é a média dos resultados de saída, e o método de votação é a votação dos resultados de saída.Os dois primeiros são métodos de fusão definidos artificialmente, mas este empilhamento permite que a máquina nos ajude a encontrar o melhor método de fusão. A vantagem fundamental deste método é que podemos treinar o meta-aluno no nível 1 no sentido de minimizar a função de perda, enquanto outros métodos de fusão só podem garantir uma certa melhoria nos resultados de fusão. Portanto, o empilhamento é um método mais eficaz do que a votação e a média. Em aplicações práticas, o empilhamento geralmente supera os métodos de votação ou de cálculo da média.
Depois de entendermos a essência do Stacking, muitos problemas detalhados no processo de implementação serão facilmente resolvidos, tais como:
- Você precisa realizar ajustes precisos de parâmetros no algoritmo de fusão?
O aluno individual é ajustado grosseiramente e o meta-aluno é ajustado. Se o ajuste for insuficiente, ambos os tipos de alunos podem ser ajustados. Teoricamente, quanto mais próximo o resultado do algoritmo estiver do rótulo real, melhor.No entanto, os alunos individuais podem facilmente ajustar-se demais depois de serem ajustados e depois fundidos.
- Como escolher o algoritmo individual do aluno para maximizar o efeito do empilhamento?
Consistente com a votação e a média, controle o overfitting, aumente a diversidade e preste atenção ao tempo geral de computação do algoritmo.
- O aluno individual pode ser um algoritmo menos complexo, como regressão logística ou árvore de decisão? O meta-aluno pode ser um algoritmo muito complexo como o xgboost?
Estão todos OK, tudo está sujeito ao efeito modelo. Para o nível 0, ao adicionar alunos fracos para aumentar a diversidade do modelo e os efeitos dos alunos fracos serem melhores, esses algoritmos podem ser retidos. Para o nível 1, qualquer algoritmo pode ser usado, desde que não se ajuste demais. A recomendação pessoal é que você pode usar algoritmos mais complexos para classificação, mas é melhor usar algoritmos simples para regressão.
- Os algoritmos de nível 0 e nível 1 podem usar funções de perda diferentes?
Sim, porque diferentes funções de perda medem, na verdade, diferenças semelhantes: a diferença entre o valor verdadeiro e o valor previsto. No entanto, perdas diferentes têm sensibilidades diferentes às diferenças e recomenda-se a utilização de funções de perda semelhantes, se possível.
- Os algoritmos de nível 0 e nível 1 podem usar métricas de avaliação diferentes?
Pessoalmente, é recomendado que os algoritmos no nível 0 e no nível 1 usem os mesmos indicadores de avaliação do modelo . Embora dois grupos de algoritmos estejam conectados em série no Stacking, o treinamento desses dois grupos de algoritmos é completamente separado. No aprendizado profundo, também temos uma estrutura semelhante de algoritmos poderosos conectados em série com algoritmos fracos. Por exemplo, uma rede neural convolucional consiste em uma camada convolucional poderosa e uma camada linear fraca conectada em série. A principal responsabilidade da camada convolucional é para descobrir a relação entre recursos e rótulos.A principal responsabilidade da camada linear é integrar suposições e resultados. Porém, no aprendizado profundo, o treinamento de todas as camadas de uma rede é realizado simultaneamente, e os pesos de toda a rede precisam ser atualizados cada vez que a função de perda é reduzida. Porém, no Stacking, o algoritmo do nível 1 não afeta em nada os resultados do nível 0 ao ajustar o peso. Portanto, para garantir que os dois grupos de algoritmos possam obter os resultados que desejamos após a fusão final, o único O índice de avaliação deve ser usado durante o treinamento. Linha de base para o treinamento.
2 Implementar empilhamento no sklearn
class sklearn.ensemble.StackingClassifier (
estimadores,
final_estimator=None, *,
cv=None,
stack_method="auto",
n_jobs=None,
passthrough=False,
verbose=0)
class sklearn.ensemble.StackingRegressor (
estimadores,
final_estimator=None,*,
cv=None,
n_jobs=None,
passthrough=False,
verbose=0)
| parâmetro | ilustrar |
|---|---|
| estimadores | Lista de avaliadores individuais. No sklearn, ao usar apenas um único avaliador como estimador individual, o modelo pode ser executado, mas o efeito geralmente não é muito bom. |
| estimador_final | Um meta-aluno só pode ter um avaliador. Quando o modelo de fusão executa uma tarefa de classificação, o meta-aluno deve ser um algoritmo de classificação; quando o modelo de fusão executa uma tarefa de regressão, o meta-aluno deve ser um algoritmo de regressão. |
| cv | Usado para especificar o tipo específico, número de dobra e outros detalhes de validação cruzada. Você pode realizar uma validação cruzada K-fold simples ou inserir a classe de validação cruzada no sklearn. |
| stack_method | Parâmetros exclusivos dos classificadores representam os resultados de testes específicos produzidos por alunos individuais. |
| atravessar | Ao treinar o meta-aluno, adicione os dados originais como a matriz de recursos. |
| n_jobs, detalhado | Número de threads e parâmetros de monitoramento. |
No sklearn, desde que você insira estimatorsa soma final_estimator, você pode realizar o empilhamento. Podemos continuar a usar a combinação de alunos individuais usados no método de votação e usar florestas aleatórias como meta-aprendizes para completar o empilhamento:
- Biblioteca e dados de ferramentas
-
import matplotlib.pyplot as plt -
from sklearn.model_selection import KFold, cross_validate -
from sklearn.datasets import load_digits #分类 - 手写数字数据集 -
from sklearn.datasets import load_iris -
from sklearn.datasets import load_boston -
from sklearn.model_selection import train_test_split -
from sklearn.neighbors import KNeighborsClassifier as KNNC -
from sklearn.neighbors import KNeighborsRegressor as KNNR -
from sklearn.tree import DecisionTreeRegressor as DTR -
from sklearn.tree import DecisionTreeClassifier as DTC -
from sklearn.linear_model import LinearRegression as LR -
from sklearn.linear_model import LogisticRegression as LogiR -
from sklearn.ensemble import RandomForestRegressor as RFR -
from sklearn.ensemble import RandomForestClassifier as RFC -
from sklearn.ensemble import GradientBoostingRegressor as GBR -
from sklearn.ensemble import GradientBoostingClassifier as GBC -
from sklearn.naive_bayes import GaussianNB -
from sklearn.ensemble import StackingClassifier
-
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.2,random_state=1412)

- Definir função de validação cruzada
-
def fusion_estimators(clf): -
对融合模型做交叉验证,对融合模型的表现进行评估 -
cv = KFold(n_splits=5,shuffle=True,random_state=1412) -
results = cross_validate(clf,Xtrain,Ytrain -
,cv = cv -
,scoring = "accuracy" -
,n_jobs = -1 -
,return_train_score = True -
,verbose=False) -
test = clf.fit(Xtrain,Ytrain).score(Xtest,Ytest) -
print("train_score:{}".format(results["train_score"].mean()) -
cv_mean:{}".format(results["test_score"].mean()) -
test_score:{}".format(test)
-
def individual_estimators(estimators): -
对模型融合中每个评估器做交叉验证,对单一评估器的表现进行评估 -
for estimator in estimators: -
cv = KFold(n_splits=5,shuffle=True,random_state=1412) -
results = cross_validate(estimator[1],Xtrain,Ytrain -
,cv = cv -
,scoring = "accuracy" -
,n_jobs = -1 -
,return_train_score = True -
,verbose=False) -
test = estimator[1].fit(Xtrain,Ytrain).score(Xtest,Ytest) -
print(estimator[0] -
train_score:{}".format(results["train_score"].mean()) -
cv_mean:{}".format(results["test_score"].mean()) -
test_score:{}".format(test)
- Definição de alunos individuais e meta-alunos
Quando explicamos o método de votação anteriormente, demos uma explicação detalhada sobre como definir alunos individuais e também fizemos muitos esforços para encontrar os 7 modelos a seguir. Aqui, utilizaremos os 7 modelos selecionados em Votação:
-
clf1 = LogiR(max_iter = 3000, C=0.1, random_state=1412,n_jobs=8) -
clf2 = RFC(n_estimators= 100,max_features="sqrt",max_samples=0.9, random_state=1412,n_jobs=8) -
clf3 = GBC(n_estimators= 100,max_features=16,random_state=1412) -
clf4 = DTC(max_depth=8,random_state=1412) -
clf5 = KNNC(n_neighbors=10,n_jobs=8) -
clf7 = RFC(n_estimators= 100,max_features="sqrt",max_samples=0.9, random_state=4869,n_jobs=8) -
clf8 = GBC(n_estimators= 100,max_features=16,random_state=4869) -
estimators = [("Logistic Regression",clf1), ("RandomForest", clf2) -
, ("GBDT",clf3), ("Decision Tree", clf4), ("KNN",clf5) -
#, ("Bayes",clf6) -
, ("RandomForest2", clf7), ("GBDT2", clf8)
- Importar sklearn para modelagem
-
final_estimator = RFC(n_estimators=100 -
, min_impurity_decrease=0.0025 -
, random_state= 420, n_jobs=8) -
clf = StackingClassifier(estimators=estimators #level0的7个体学习器 -
,final_estimator=final_estimator #level 1的元学习器 -
,n_jobs=8)
Antes de ajustar o ajuste: ou seja, sem adicionar min_impurity_decrease=0,0025
-
fusion_estimators(clf) #没有过拟合限制 -
cv_mean:0.9812112853271389 -
test_score:0.9861111111111112
Depois de adicionar overfitting
-
fusion_estimators(clf) #精调过拟合 -
cv_mean:0.9812185443283005 -
test_score:0.9888888888888889
| referência | leis de votação | método de empilhamento | |
|---|---|---|---|
| Validação cruzada de 5 vezes | 0,9666 | 0,9833 | 0,9812(↓) |
| Resultados do conjunto de testes | 0,9527 | 0,9889 | 0,9889(-) |
Pode-se observar que a pontuação do empilhamento no conjunto de teste é a mesma do método de votação, mas a pontuação da validação cruzada 5 vezes não é tão alta quanto o método de votação. Isso pode ocorrer porque os dados que treinamos agora são relativamente simples, mas quando o aprendizado dos dados for mais difícil, as vantagens do empilhamento surgirão lentamente. Claro, o meta-aluno que estamos usando agora tem parâmetros quase padrão. Podemos usar a otimização bayesiana para ajustar os parâmetros do meta-aluno e depois compará-los. O efeito do método de empilhamento pode superar o método de votação.
Matriz de recursos do aluno de 3 elementos
3.1 Dois problemas com matrizes de recursos de meta-aluno
No processo de empilhamento, os alunos individuais treinam e preveem os dados originais e, em seguida, organizam os resultados da previsão em uma nova matriz de recursos e os colocam no meta-aluno para aprendizagem. Entre eles, os resultados de predição de alunos individuais, ou seja, a matriz que precisa ser treinada pelo meta-aluno, são geralmente organizados da seguinte forma:
| Aluno 1 | Aluno 2 | ... | aprender | |
|---|---|---|---|---|
| Amostra 1 | xxx | xxx | ... | xxx |
| Amostra 2 | xxx | xxx | ... | xxx |
| Amostra 3 | xxx | xxx | ... | xxx |
| ... | ... | ... | ... | ... |
| Amostra m | xxx | xxx | ... | xxx |
Com base em nossa compreensão de aprendizado de máquina e fusão de modelos, não é difícil encontrar os dois problemas a seguir:
- Primeiro, deve haver muito poucos recursos na matriz de recursos do meta-aluno
Um aluno individual só pode produzir um conjunto de resultados de previsão. Organizamos esses resultados de previsão e o número de recursos na nova matriz de recursos é igual ao número de alunos individuais. Geralmente, há no máximo 20 a 30 alunos individuais no modelo de fusão, o que significa que há no máximo 20 a 30 recursos na matriz de recursos do meta-aluno. Essa quantidade de recursos está longe de ser suficiente para algoritmos de aprendizado de máquina na indústria e em competições.
- Em segundo lugar, não há muitas amostras na matriz de características do meta-aluno.
A responsabilidade do aluno individual é encontrar a hipótese entre os dados originais e o rótulo. Para verificar se esta hipótese é precisa, o que precisamos de observar é a capacidade de generalização do aluno individual. Somente quando a capacidade de generalização do aluno individual for forte, poderemos colocar com segurança os resultados de previsão produzidos pelo aluno individual no meta-aluno para fusão.
No entanto. Quando treinamos o modelo de empilhamento, devemos dividir o conjunto de dados original em três partes: conjunto de treinamento, conjunto de verificação e conjunto de teste - o conjunto de teste
é usado para testar o efeito de todo o modelo de fusão, portanto não pode ser usado durante o treinamento processo. O conjunto de treinamento é usado para treinar alunos individuais e é um conteúdo que foi totalmente divulgado a cada aluno. Se as previsões forem feitas no conjunto de treinamento, os resultados da previsão serão "altos" e não poderão representar a capacidade de generalização do indivíduo aprendizes. Portanto, no final, resta apenas um pequeno conjunto de verificação que pode ser usado para previsão e representa o verdadeiro nível de aprendizagem do aluno individual . Geralmente, o conjunto de verificação representa no máximo 30% -40% de todo o conjunto de dados, o que significa que o tamanho da amostra na matriz de recursos usada pelo meta-aluno é no máximo 40% dos dados originais. Não é de admirar que, na prática da indústria, o meta-aluno precise ser um algoritmo menos complexo, porque a matriz de recursos do meta-aluno é muito menor do que os padrões exigidos pelo aprendizado de máquina industrial em termos de volume de recursos e tamanho da amostra. Para resolver esses dois problemas, existem múltiplas soluções no método Stacking, e essas soluções podem ser implementadas através da classe stacking no sklearn.
class sklearn.ensemble.StackingClassifier (estimadores, final_estimator=None, *, cv=None, stack_method="auto", n_jobs=None, passthrough=False, detalhado=0)
class sklearn.ensemble.StackingRegressor (estimadores, final_estimator=None, *, cv=None, n_jobs=None, passthrough=False, detalhado=0)
| parâmetro | ilustrar |
|---|---|
| estimadores | Lista de avaliadores individuais. No sklearn, ao usar apenas um único avaliador como estimador individual, o modelo pode ser executado, mas o efeito geralmente não é muito bom. |
| estimador_final | Um meta-aluno só pode ter um avaliador. Quando o modelo de fusão executa uma tarefa de classificação, o meta-aluno deve ser um algoritmo de classificação; quando o modelo de fusão executa uma tarefa de regressão, o meta-aluno deve ser um algoritmo de regressão. |
| cv | Usado para especificar o tipo específico, número de dobra e outros detalhes de validação cruzada. Você pode realizar uma validação cruzada K-fold simples ou inserir a classe de validação cruzada no sklearn. |
| stack_method | Parâmetros exclusivos dos classificadores representam os resultados de testes específicos produzidos por alunos individuais. |
| atravessar | Ao treinar o meta-aluno, adicione os dados originais como a matriz de recursos. |
| n_jobs, detalhado | Número de threads e parâmetros de monitoramento. |
3.2 Solução para tamanho de amostra muito pequeno: validação cruzada
- 参数
cv,在stacking中执行交叉验证
在stacking方法被提出的原始论文当中,原作者自然也意识到了元学习器的特征矩阵样本量太少这个问题,因此提出了在stacking流程内部使用交叉验证来扩充元学习器特征矩阵的想法,即在内部对每个个体学习器做交叉验证,但并不用这个交叉验证的结果来验证泛化能力,而是直接把交叉验证当成了生产数据的工具。
具体的来看,在stacking过程中,我们是这样执行交叉验证的——
对任意个体学习器来说,假设我们执行5折交叉验证,我们会将训练数据分成5份,并按照4份训练、1份验证的方式总共建立5个模型,训练5次:
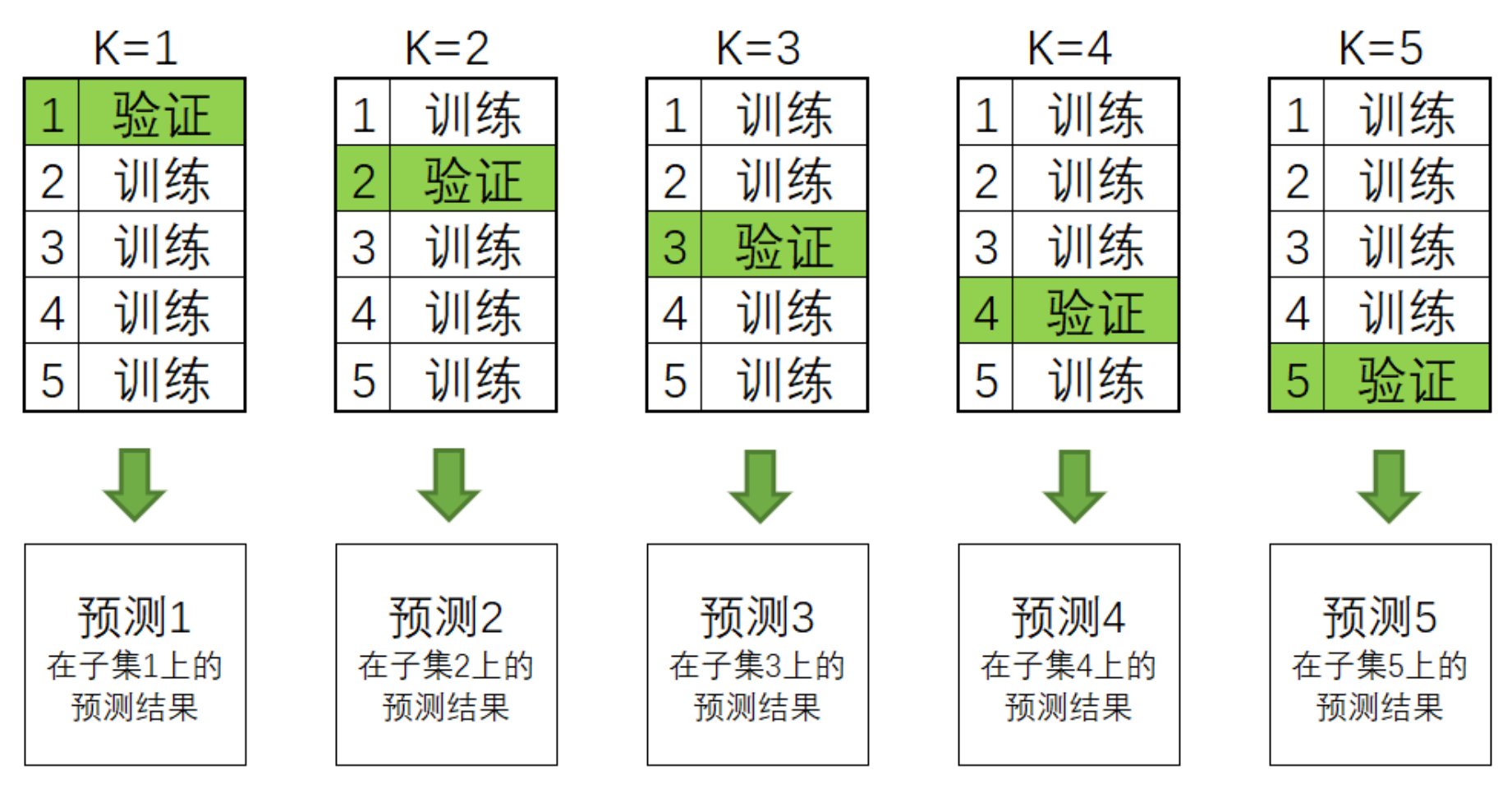
在交叉验证过程中,每次验证集中的数据都是没有被放入模型进行训练的,因此这些验证集上的预测结果都可以衡量模型的泛化能力。
一般来说,交叉验证的最终输出是5个验证集上的分数,但计算分数之前我们一定是在5个验证集上分别进行预测,并输出了结果。所以我们可以在交叉验证中建立5个模型,轮流得到5个模型输出的预测结果,而这5个预测结果刚好对应全数据集中分割的5个子集。这是说,我们完成交叉验证的同时,也对原始数据中全部的数据完成了预测。现在,只要将5个子集的预测结果纵向堆叠,就可以得到一个和原始数据中的样本一一对应的预测结果。这种纵向堆叠正像我们在海滩上堆石子(stacking)一样,这也是“堆叠法”这个名字的由来。

用这样的方法来进行预测,可以让任意个体学习器输出的预测值数量 = 样本量,如此,元学习器的特征矩阵的行数也就等于原始数据的样本量了:
| 学习器1 | 学习器2 | ... | 学习器n | |
|---|---|---|---|---|
| 样本1 | xxx | xxx | ... | xxx |
| 样本2 | xxx | xxx | ... | xxx |
| 样本3 | xxx | xxx | ... | xxx |
| ... | ... | ... | ... | ... |
| 样本m | xxx | xxx | ... | xxx |
在stacking过程中,这个交叉验证流程是一定会发生的,不属于我们可以人为干涉的范畴。不过,我们可以使用参数cv来决定具体要使用怎样的交叉验证,包括具体使用几折验证,是否考虑分类标签的分布等等。具体来说,参数cv中可以输入:
输入None,默认使用5折交叉验证
输入sklearn中任意交叉验证对象
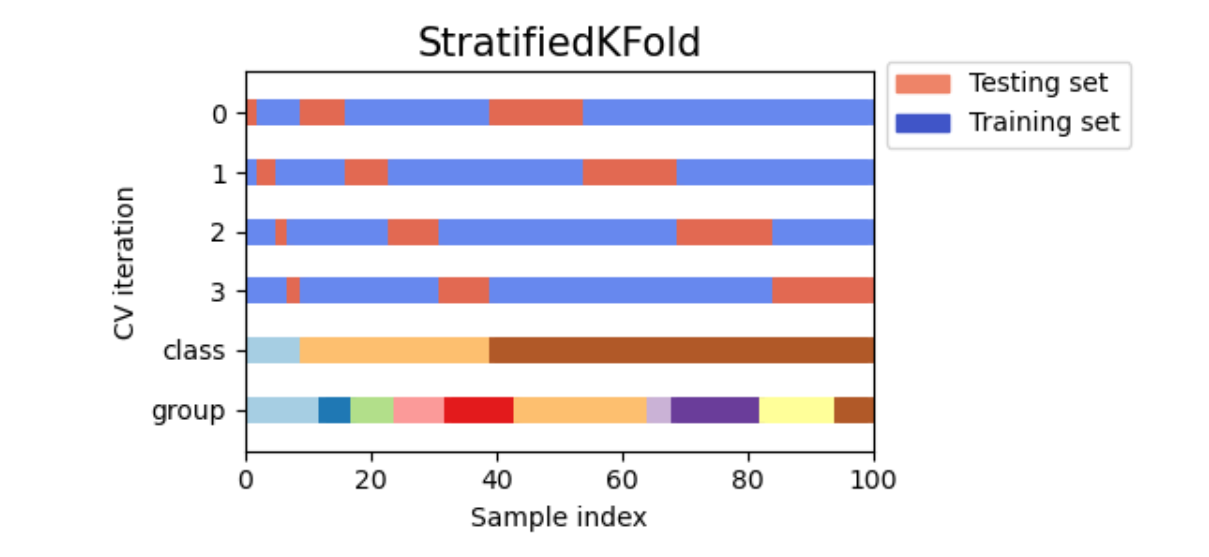
输入任意整数,表示在Stratified K折验证中的折数。Stratified K折验证是会考虑标签中每个类别占比的交叉验证,如果选择Stratified K折交叉验证,那每次训练时交叉验证会保证原始标签中的类别比例 = 训练标签的类别比例 = 验证标签的类别比例。
现在你知道Stacking是如何处理元学习器的特征矩阵样本太少的问题了。需要再次强调的是,内部交叉验证的并不是在验证泛化能力,而是一个生产数据的工具,因此交叉验证本身没有太多可以调整的地方。唯一值得一提的是,当交叉验证的折数较大时,模型的抗体过拟合能力会上升、同时学习能力会略有下降。当交叉验证的折数很小时,模型更容易过拟合。但如果数据量足够大,那使用过多的交叉验证折数并不会带来好处,反而只会让训练时间增加而已:
-
estimators = [("Logistic Regression",clf1), ("RandomForest", clf2) -
, ("GBDT",clf3), ("Decision Tree", clf4), ("KNN",clf5) -
#, ("Bayes",clf6) -
, ("RandomForest2", clf7), ("GBDT2", clf8) -
final_estimator = RFC(n_estimators=100 -
, min_impurity_decrease=0.0025 -
, random_state= 420, n_jobs=8)
-
clf = StackingClassifier(estimators=estimators -
,final_estimator=final_estimator -
, cv = cv -
, n_jobs=8) -
clf.fit(Xtrain,Ytrain) -
print((time.time() - start)) #消耗时间 -
print(clf.score(Xtrain,Ytrain)) #训练集上的结果 -
print(clf.score(Xtest,Ytest)) #测试集上的结果
可以看到,随着cv中折数的上升,训练时间一定会上升,但是模型的表现却不一定。因此,选择5~10折交叉验证即可。同时,由于stacking当中自带交叉验证,又有元学习器这个算法,因此堆叠法的运行速度是比投票法、均值法缓慢很多的,这是stacking堆叠法不太人性化的地方。
3.3 特征太少的解决方案
- 参数
stack_method,更换个体学习器输出的结果类型
对于分类stacking来说,如果特征量太少,我们可以更换个体学习器输出的结果类型。具体来说,如果个体学习器输出的是具体类别(如[0,1,2]),那1个个体学习器的确只能输出一列预测结果。但如果把输出的结果类型更换成概率值、置信度等内容,输出结果的结构一下就可以从一列拓展到多列。
如果这个行为由参数stack_method控制,这是只有StackingClassifier才拥有的参数,它控制个体分类器具体的输出。stack_method里面可以输入四种字符串:"auto", "predict_proba", "decision_function", "predict",除了"auto"之外其他三个都是sklearn常见的接口。
-
clf = LogiR(max_iter=3000, random_state=1412) -
clf = clf.fit(Xtrain,Ytrain)
-
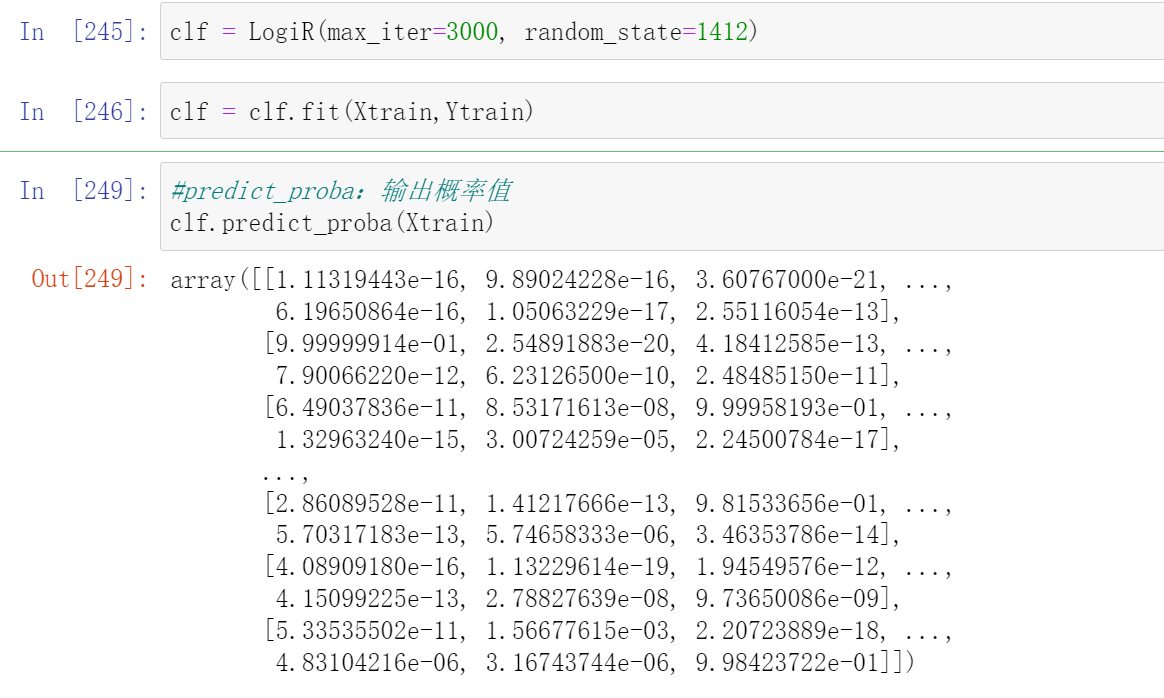
clf.predict_proba(Xtrain)
-
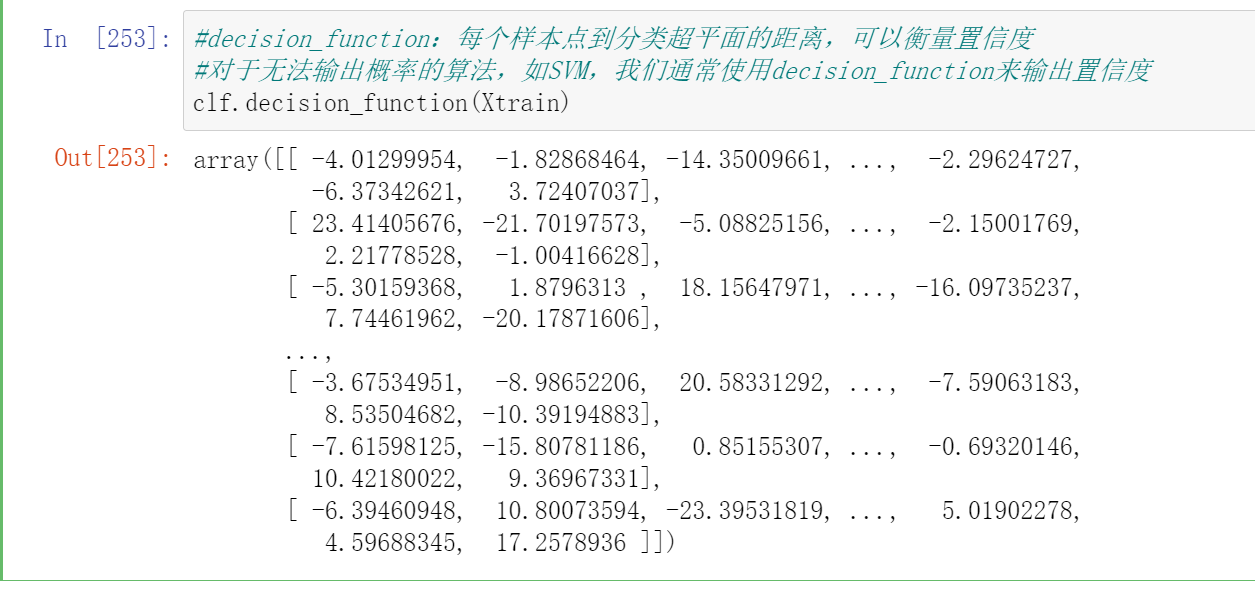
#decision_function:每个样本点到分类超平面的距离,可以衡量置信度 -
#对于无法输出概率的算法,如SVM,我们通常使用decision_function来输出置信度 -
clf.decision_function(Xtrain)

对参数stack_method有:
输入"auto",sklearn会在每个个体学习器上按照"predict_proba", "decision_function", "predict"的顺序,分别尝试学习器可以使用哪个接口进行输出。即,如果一个算法可以使用predict_proba接口,那就不再尝试后面两个接口,如果无法使用predict_proba,就尝试能否使用decision_function。
输入三大接口中的任意一个接口名,则默认全部个体学习器都按照这一接口进行输出。然而,如果遇见某个算法无法按照选定的接口进行输出,stacking就会报错。
因此,我们一般都默认让stack_method保持为"auto"。从上面的我们在逻辑回归上尝试的三个接口结果来看,很明显,当我们把输出的结果类型更换成概率值、置信度等内容,输出结果的结构一下就可以从一列拓展到多列。
- predict_proba
对二分类,输出样本的真实标签1的概率,一列
对n分类,输出样本的真实标签为[0,1,2,3...n]的概率,一共n列
- decision_function
对二分类,输出样本的真实标签为1的置信度,一列
对n分类,输出样本的真实标签为[0,1,2,3...n]的置信度,一共n列
- predict
对任意分类形式,输出算法在样本上的预测标签,一列
在实践当中,我们会发现输出概率/置信度的效果比直接输出预测标签的效果好很多,既可以向元学习器提供更多的特征、还可以向元学习器提供个体学习器的置信度。我们在投票法中发现使用概率的“软投票”比使用标签类被的“硬投票”更有效,也是因为考虑了置信度。
- 参数
passthrough,将原始特征矩阵加入新特征矩阵
对于分类算法,我们可以使用stack_method,但是对于回归类算法,我们没有这么多可以选择的接口。回归类算法的输出永远就只有一列连续值,因而我们可以考虑将原始特征矩阵加入个体学习器的预测值,构成新特征矩阵。这样的话,元学习器所使用的特征也不会过于少了。当然,这个操作有较高的过拟合风险,因此当特征过于少、且stacking算法的效果的确不太好的时候,我们才会考虑这个方案。
控制是否将原始数据加入特征矩阵的参数是passthrough,我们可以在该参数中输入布尔值。当设置为False时,表示不将原始特征矩阵加入个体学习器的预测值,设置为True时,则将原始特征矩阵加入个体学习器的预测值、构成大特征矩阵。
- 接口
transform与属性stack_method_
-
estimators = [("Logistic Regression",clf1), ("RandomForest", clf2) -
, ("GBDT",clf3), ("Decision Tree", clf4), ("KNN",clf5) -
#, ("Bayes",clf6) -
, ("RandomForest2", clf7), ("GBDT2", clf8)
-
final_estimator = RFC(n_estimators=100 -
, min_impurity_decrease=0.0025 -
, random_state= 420, n_jobs=8) -
clf = StackingClassifier(estimators=estimators -
,final_estimator=final_estimator -
,stack_method = "auto" -
,n_jobs=8)
clf = clf.fit(Xtrain,Ytrain)
当我们训练完毕stacking算法后,可以使用接口transform来查看当前元学习器所使用的训练特征矩阵的结构:
-
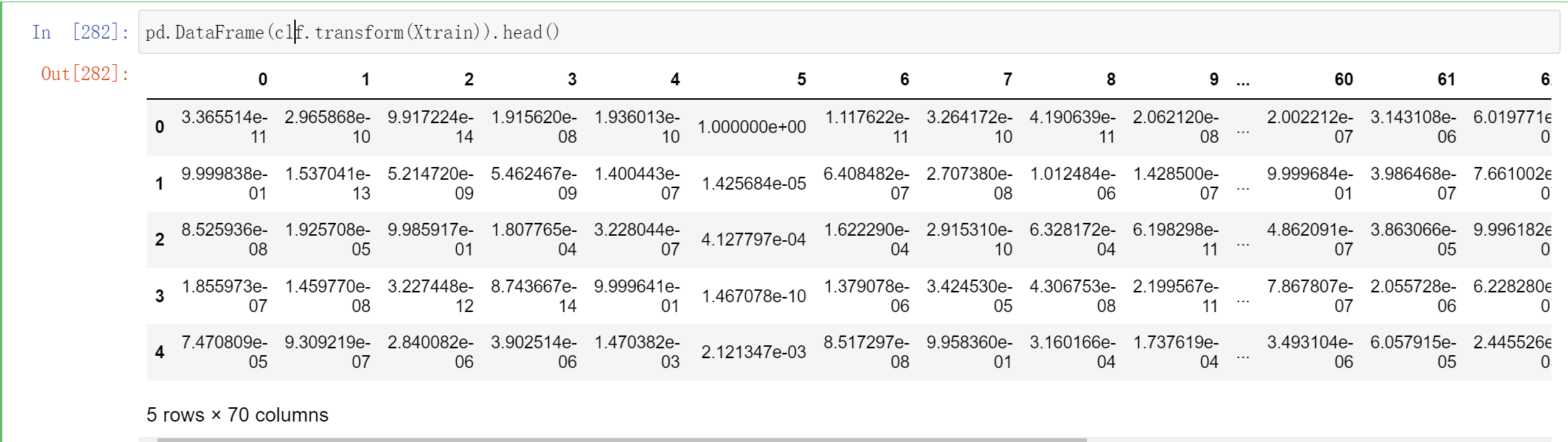
clf.transform(Xtrain).shape

这个70 代表这个一共有7个个体学习器,每个个体学习器都有10个概率输出
如之前所说,这个特征矩阵的行数就等于训练的样本量:
不过你能判断为什么这里有70列吗?因为我们有7个个体学习器,而现在数据是10分类的数据,因此每个个体学习器都输出了类别[0,1,2,3,4,5,6,7,8,9]所对应的概率,因此总共产出了70列数据:
pd.DataFrame(clf.transform(Xtrain)).head()
如果加入参数passthrough,特征矩阵的特征量会变得更大:
-
clf = StackingClassifier(estimators=estimators -
,final_estimator=final_estimator -
,stack_method = "auto" -
,passthrough = True -
,n_jobs=8)
clf = clf.fit(Xtrain,Ytrain)
-
clf.transform(Xtrain).shape #这里就等于70 + 原始特征矩阵的特征数量64
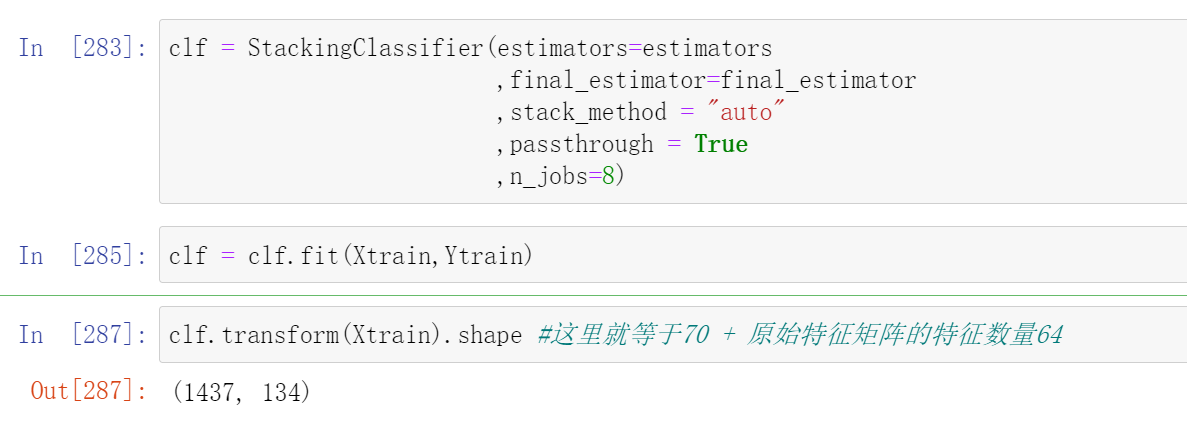
使用属性stack_method_,我们可以查看现在每个个体学习器都使用了什么接口做为预测输出:
clf.stack_method_
["predict_proba",
"predict_proba",
"predict_proba",
"predict_proba",
"predict_proba",
"predict_proba",
"predict_proba"]
不难发现,7个个体学习器都使用了predict_proba的概率接口进行输出,这与我们选择的算法都是可以输出概率的算法有很大的关系
4 Stacking融合的训练/测试流程
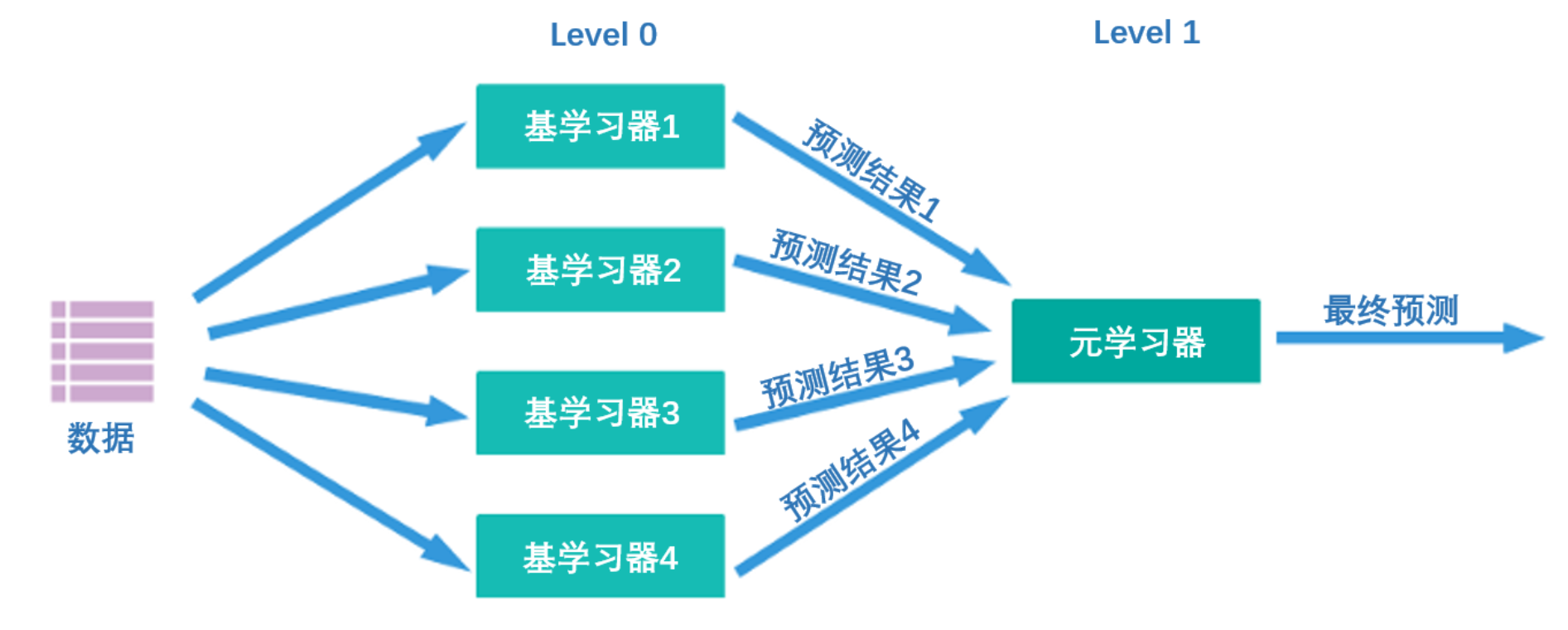
现在我们已经知道了stacking算法中所有关于训练的信息,我们可以梳理出如下训练流程:
- stacking的训练
- 将数据分割为训练集、测试集,其中训练集上的样本为(M_{train}),测试集上的样本量为(M_{test})
- 将训练集输入level 0的个体学习器,分别在每个个体学习器上进行交叉验证。在每个个体学习器上,将所有交叉验证的验证结果纵向堆叠形成预测结果。假设预测结果为概率值,当融合模型执行回归或二分类任务时,该预测结果的结构为((M_{train},1)),当融合模型执行K分类任务时(K>2),该预测结果的结构为((M_{train},K))
- 将所有个体学习器的预测结果横向拼接,形成新特征矩阵。假设共有N个个体学习器,则新特征矩阵的结构为((M_{train}, N))。如果是输出多分类的概率,那最终得出的新特征矩阵的结构为((M_{train}, N*K))
- 将新特征矩阵放入元学习器进行训练。
不难发现,虽然训练的流程看起来比较流畅,但是测试却不知道从何做起,因为:
-
最终输出预测结果的是元学习器,因此直觉上来说测试数据集或许应该被输入到元学习器当中。然而,元学习器是使用新特征矩阵进行预测的,新特征矩阵的结构与规律都与原始数据不同,所以元学习器根本不可能接受从原始数据中分割出来的测试数据。因此正确的做法应该是让测试集输入level 0的个体学习器。
-
然而,这又存在问题了:level 0的个体学习器们在训练过程中做的是交叉验证,而交叉验证只会输出验证结果,不会留下被训练的模型。因此在level 0中没有可以用于预测的、已经训练完毕的模型。
为了解决这个矛盾在我们的训练流程中,存在着隐藏的步骤:
- stacking的训练
- 将数据分割为训练集、测试集,其中训练集上的样本为(M_{train}),测试集上的样本量为(M_{test})
- 将训练集输入level 0的个体学习器,分别在每个个体学习器上进行交叉验证。在每个个体学习器上,将所有交叉验证的验证结果纵向堆叠形成预测结果。假设预测结果为概率值,当融合模型执行回归或二分类任务时,该预测结果的结构为((M_{train},1)),当融合模型执行K分类任务时(K>2),该预测结果的结构为((M_{train},K))
- 隐藏步骤:使用全部训练数据对所有个体学习器进行训练,为测试做好准备。
- 将所有个体学习器的预测结果横向拼接,形成新特征矩阵。假设共有N个个体学习器,则新特征矩阵的结构为((M_{train}, N)).
- 将新特征矩阵放入元学习器进行训练。
- stacking的测试
- 将测试集输入level0的个体学习器,分别在每个个体学习器上预测出相应结果。假设测试结果为概率值,当融合模型执行回归或二分类任务时,该测试结果的结构为((M_{test},1)),当融合模型执行K分类任务时(K>2),该测试结果的结构为((M_{test},K))
- 将所有个体学习器的预测结果横向拼接为新特征矩阵。假设共有N个个体学习器,则新特征矩阵的结构为((M_{test}, N)).
- 将新特征矩阵放入元学习器进行预测。
因此在stacking中,不仅要对个体学习器完成全部交叉验证,还需要在交叉验证结束后,重新使用训练数据来训练所有的模型。无怪Stacking融合的复杂度较高、并且运行缓慢了。
到现在,我们已经讲解完毕投票法和堆叠法了。在sklearn中,我们讲解了下面4个类:
| 融合方法 | 类 |
|---|---|
| 投票法 | ensemble.VotingClassifier |
| 平均法 | ensemble.VotingRegressor |
| 堆叠法分类 | ensemble.StackingClassifier |
| 堆叠法回归 | ensemble.StackingRegressor |
虽然这些类是模型融合方法,但我们可以像使用任意单一算法类一样任意地使用这些方法——我们可以很轻松地对这些类执行手动调参、交叉验证、网格搜索、贝叶斯优化、管道打包等操作,而无需担心代码的兼容问题。但需要注意的是,sklearn中的融合工具只支持sklearn中的评估器,不支持xgb、lgbm的原生代码。因此,如果我们想要对原生代码下的模型进行融合,必须自己手写融合过程。
二 改进后的堆叠法:Blending
1 Blending的基本思想与流程
Blending融合是在Stacking融合的基础上改进过后的算法。在之前的课程中我们提到,堆叠法stacking在level1上使用算法,这可以令融合本身向着损失函数最小化的方向进行,同时stacking使用自带的内部交叉验证来生成数据,可以深度使用训练数据,让模型整体的效果更好。但在这些操作的背后,存在两个巨大的问题:
-
stacking融合需要巨大的计算量,需要的时间和算力成本较高,以及
-
stacking融合在数据和算法上都过于复杂,因此融合模型过拟合的可能性太高。
针对stacking存在的这两个问题,竞赛冠军队们持续探索,并且在实践过程中创造了多种改进的stacking方法。今天,多种stacking方法中较为有效的方法之一就是著名的Blending方法。Blending直译为“混合”,但它的核心思路其实与Stacking完全一致:使用两层算法串联,level0上存在多个强学习器,level1上有且只有一个元学习器,且level0上的强学习器负责拟合数据与真实标签之间的关系、并输出预测结果、组成新的特征矩阵,然后让level1上的元学习器在新的特征矩阵上学习并预测。
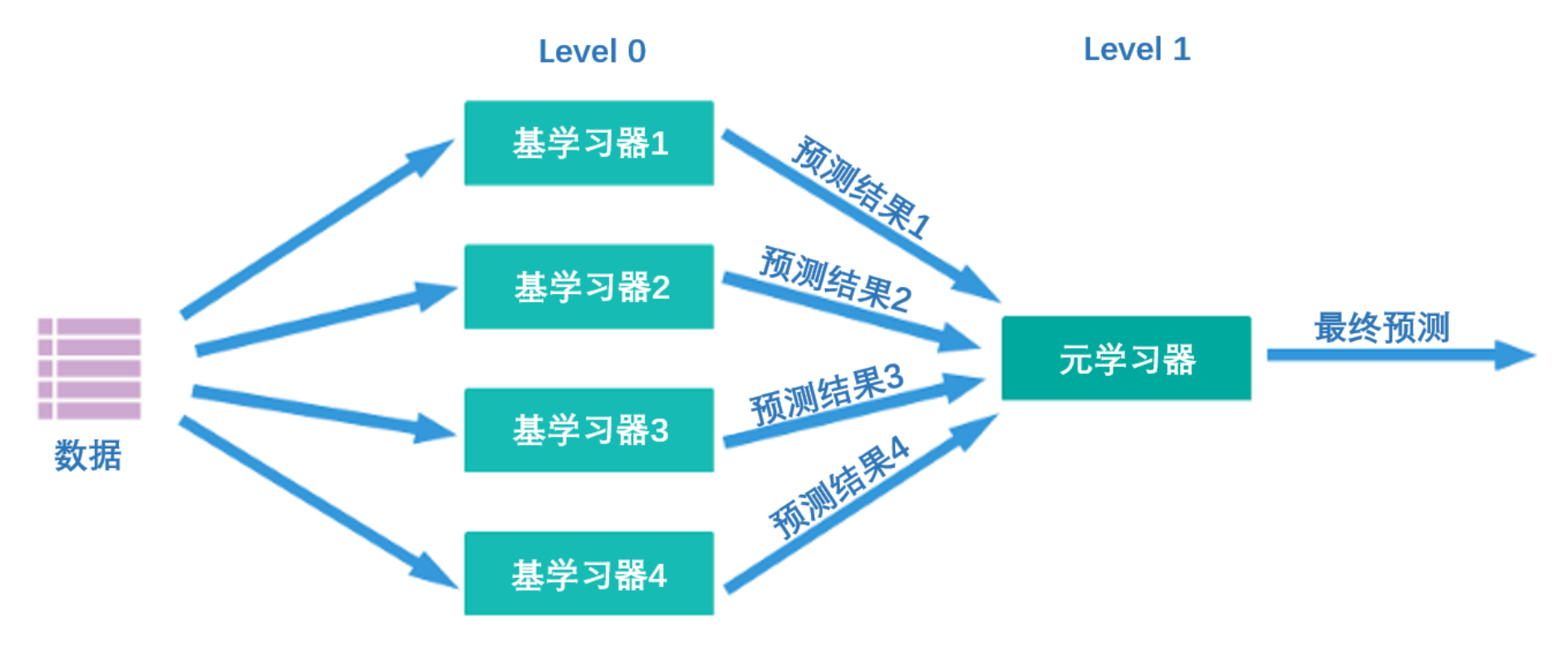
然而,与stacking不同的是,为了降低计算量、降低融合模型过拟合风险,Blending取消了K折交叉验证、并且大大地降低了元学习器所需要训练的数据量,其具体流程如下:
- blending的训练
- 将数据分割为训练集、验证集与测试集,其中训练集上的样本为(M_{train}),验证集上的样本为(M_v),测试集上的样本量为(M_{test})
- 将训练集输入level 0的个体学习器,分别在每个个体学习器上训练。训练完毕后,在验证集上进行验证,输出验证集上的预测结果。假设预测结果为概率值,当融合模型执行回归或二分类任务时,该预测结果的结构为((M_v,1)),当融合模型执行K分类任务时(K>2),该预测结果的结构为((M_v,K))。此时此刻,所有个体学习器都被训练完毕了。
- 将所有个体学习器的验证结果横向拼接,形成新特征矩阵。假设共有N个个体学习器,则新特征矩阵的结构为((M_v, N))。
- 将新特征矩阵放入元学习器进行训练。
- blending的测试
- 将测试集输入level0的个体学习器,分别在每个个体学习器上预测出相应结果。假设测试结果为概率值,当融合模型执行回归或二分类任务时,该测试结果的结构为((M_{test},1)),当融合模型执行K分类任务时(K>2),该测试结果的结构为((M_{test},K))
- 将所有个体学习器的预测结果横向拼接为新特征矩阵。假设共有N个个体学习器,则新特征矩阵的结构为((M_{test}, N)).
- 将新特征矩阵放入元学习器进行预
测。
2 手动实现Blending算法
-
def BlendingClassifier(X,y,estimators,final_estimator,test_size=0.2,vali_size=0.4): -
X,y:整体数据集,会被分割为训练集、测试集、验证集三部分 -
estimators: level0的个体学习器,输入格式形如sklearn中要求的[(名字,算法),(名字,算法)...] -
test_size:测试集占全数据集的比例 -
vali_size:验证集站全数据集的比例 -
#2.分训练和验证集,验证集占完整数据集的比例为0.4,因此占排除测试集之后的比例为0.4/(1-0.2) -
X_,Xtest,y_,Ytest = train_test_split(X,y,test_size=test_size,random_state=1412) -
Xtrain,Xvali,Ytrain,Yvali = train_test_split(X_,y_,test_size=vali_size/(1-test_size),random_state=1412) -
#建立空dataframe用于保存个体学习器上的验证结果,即用于生成新特征矩阵 -
#新建空列表用于保存训练完毕的个体学习器,以便在测试中使用 -
NewX_vali = pd.DataFrame() -
trained_estimators = [] -
#循环、训练每个个体学习器、并收集个体学习器在验证集上输出的概率 -
for clf_id, clf in estimators: -
clf = clf.fit(Xtrain,Ytrain) -
val_predictions = pd.DataFrame(clf.predict_proba(Xvali)) -
#保存结果,在循环中逐渐构筑新特征矩阵 -
NewX_vali = pd.concat([NewX_vali,val_predictions],axis=1) -
trained_estimators.append((clf_id,clf)) -
#元学习器在新特征矩阵上训练、并输出训练分数 -
final_estimator = final_estimator.fit(NewX_vali,Yvali) -
train_score = final_estimator.score(NewX_vali,Yvali) -
#建立空dataframe用于保存个体学习器上的预测结果,即用于生成新特征矩阵 -
NewX_test = pd.DataFrame() -
#循环,在每个训练完毕的个体学习器上进行预测,并收集每个个体学习器上输出的概率 -
for clf_id,clf in trained_estimators: -
test_prediction = pd.DataFrame(clf.predict_proba(Xtest)) -
#保存结果,在循环中逐渐构筑特征矩阵 -
NewX_test = pd.concat([NewX_test,test_prediction],axis=1) -
#元学习器在新特征矩阵上测试、并输出测试分数 -
test_score = final_estimator.score(NewX_test,Ytest) -
print(train_score,test_score)
-
clf1 = LogiR(max_iter = 3000, C=0.1, random_state=1412,n_jobs=8) -
clf2 = RFC(n_estimators= 100,max_features="sqrt",max_samples=0.9, random_state=1412,n_jobs=8) -
clf3 = GBC(n_estimators= 100,max_features=16,random_state=1412) -
clf4 = DTC(max_depth=8,random_state=1412) -
clf5 = KNNC(n_neighbors=10,n_jobs=8) -
clf7 = RFC(n_estimators= 100,max_features="sqrt",max_samples=0.9, random_state=4869,n_jobs=8) -
clf8 = GBC(n_estimators= 100,max_features=16,random_state=4869) -
estimators = [("Logistic Regression",clf1), ("RandomForest", clf2) -
, ("GBDT",clf3), ("Decision Tree", clf4), ("KNN",clf5) -
#, ("Bayes",clf6) -
#, ("RandomForest2", clf7), ("GBDT2", clf8)
-
final_estimator = RFC(n_estimators= 100 -
#, max_depth = 8 -
, min_impurity_decrease=0.0025 -
, random_state= 420, n_jobs=8)
-
#很明显,过拟合程度比Stacking要轻,但是测试集的表现没有stacking强 -
BlendingClassifier(X,y,estimators,final_estimator)

-
#验证比例越大,模型学习能力越弱 - 注意验证集比例上限0.8,因为有0.2是测试数据 -
BlendingClassifier(X,y,estimators,final_estimator,vali_size=0.7)

-
#blending的运行速度比stacking快了不止一个档次…… -
BlendingClassifier(X,y,estimators,final_estimator,vali_size=0.1)

| benchmark | 投票法 | Stacking | Blending | |
|---|---|---|---|---|
| 5折交叉验证 | 0.9666 | 0.9833 | 0.9812(↓) | - |
| 测试集结果 | 0.9527 | 0.9889 | 0.9889(-) | 0.9833(↓) |
从结果来看,投票法表现最稳定和优异,这与我们选择的数据集是较为简单的数据集有关,同时投票法也是我们调整最多、最到位的算法。在大型数据集上运行时,stacking和blending会展现出更多的优势。到这里我们的blending就讲解完毕了,在《2022机器学习实战》正式课程当中,我们将会更详细地讲解Blending在xgboost等复杂算法上的应用。
参考:https://www.cnblogs.com/lipu123/p/17563377.html
Para obter mais conhecimento sobre aprendizado de máquina python, siga a conta oficial (modelo de controle de risco python)