Diretório de artigos
1: Histórico do Aplicativo de Estimativa de Profundidade
1. Definição de Estimativa de Profundidade
Suponha que temos uma imagem 2d III , precisamos de uma funçãoFFF para encontrar sua profundidade correspondenteddd . Este processo pode ser escrito como:
d = F(I) d = F(I)d=F ( eu )
Informações de profundidade aqui ddd realmente representaa distância real entre cada pixel na imagem 2D projetada do objeto 3D e da câmera.
Mas como todos sabemos, FFF é uma função muito complexa, pois obter uma profundidade específica a partir de uma única imagem equivale a inferir um espaço tridimensional a partir de uma imagem bidimensional, mesmo que o olho humano use dois olhos para localizar objetos no mundo natural, haverá ainda haverá problemas. , para não mencionar o uso de uma única foto. Portanto, a estimativa de profundidade tradicional não é eficaz na estimativa de profundidade monocular.As pessoas prestam mais atenção ao estudo da visão estéreo (Stereo Vision), ou seja, para obter informações de profundidade de várias imagens. Porque as duas imagens podem obter a mudança de disparidade entre as imagens de acordo com a mudança do ângulo de visão, de modo a atingir o objetivo de obter a profundidade. Muito a dizer, vamos olhar para trás primeiro.
2. Cenários de aplicação de estimativa de profundidade


Além dos cenários de aplicação mencionados nas duas imagens acima, a estimativa de profundidade também pode ser usada em uma série de tarefas a jusante que requerem informações de profundidade, como reconstrução 3D, detecção de obstáculos e SLAM. Portanto, pode-se ver que a estimativa de profundidade geralmente existe como uma tarefa a montante e sua importância é evidente.
3. Vários métodos de estimativa de profundidade
-
Usando lidar ou reflexão de luz estruturada na superfície do objeto para obter nuvem de ponto de profundidade
Este método pode ser descrito como um "método de tirano local" Use diretamente o sensor para digitalizar para obter informações de profundidade de nuvem de ponto de alta precisão, mas o preço é caro! -
Medição de distância binocular tradicional
A visão estéreo binocular consiste em duas câmeras, como os olhos humanos podem ver objetos tridimensionais e obter comprimento, largura e informações de profundidade do objeto. A posição da câmera geralmente é calibrada manualmente (como o algoritmo de calibração da câmera de Zhang Zhengyou) e, em seguida, o processo de derivação da matriz de parâmetros internos e externos da câmera por meio da posição do ponto de destino no sistema de coordenadas da imagem e da coordenada mundial sistema é muitas vezes um processo de transformação de coordenadas. -
A
visão monocular tradicional de medição de distância monocular pode obter informações bidimensionais do objeto, ou seja, comprimento e largura; Uma série de métodos são usados para resolvê-lo. Ao mesmo tempo, a quantidade de cálculo é complicada e a precisão não é tão alta quanto a binocular, por isso é frequentemente usada quando as condições são difíceis.
4. Vantagens e desvantagens de usar a estimativa de aprendizado profundo
Depois de lançar as bases para vários métodos comuns em vários campos tradicionais, vamos falar sobre a estimativa monocular de aprendizagem profunda protagonista de hoje. Como o nome indica, aprendizado profundo, aprendizado profundo, a primeira reação End2End, lança a imagem na rede treinada, sem qualquer participação manual, e obtém diretamente o mapa de profundidade final, uma palavra, conveniente ! Ao mesmo tempo, só precisamos de uma câmera monocular, ou seja, de baixo custo !
Quais são as desvantagens? Em primeiro lugar, a precisão da estimativa de profundidade dentro de 80 m não é ruim, mas o erro é muito grande além disso. Pode-se ver que a baixa precisão e a limitação da distância estimada são todas as suas deficiências. Claro, há outro problema que o aprendizado profundo sempre conseguiu evitar, que requer um grande número de conjuntos de treinamento , o que obviamente é um problema que não pode ser ignorado em alguns ambientes que carecem de dados de treinamento.
Mas afinal está à margem da tecnologia de ponta da época, então vamos bater um papo bom, e vamos ao que interessa.
Dois: modelo de estimativa de profundidade monocular
1. Conjuntos de dados usados
O modelo de estimativa de profundidade explicado aqui usa o conjunto de dados KITTI , que é obtido em estradas urbanas e rurais. Este conjunto de dados é amplamente utilizado em muitos campos de pesquisa , conforme mostrado na figura abaixo:


2. Arquitetura geral da rede
O modelo de estimativa de profundidade é para inserir uma imagem e produzir uma imagem contendo informações de profundidade, por isso é um modelo generativo , por isso deve ser inseparável do processo central de codificação e decodificação, conforme mostrado na figura abaixo:
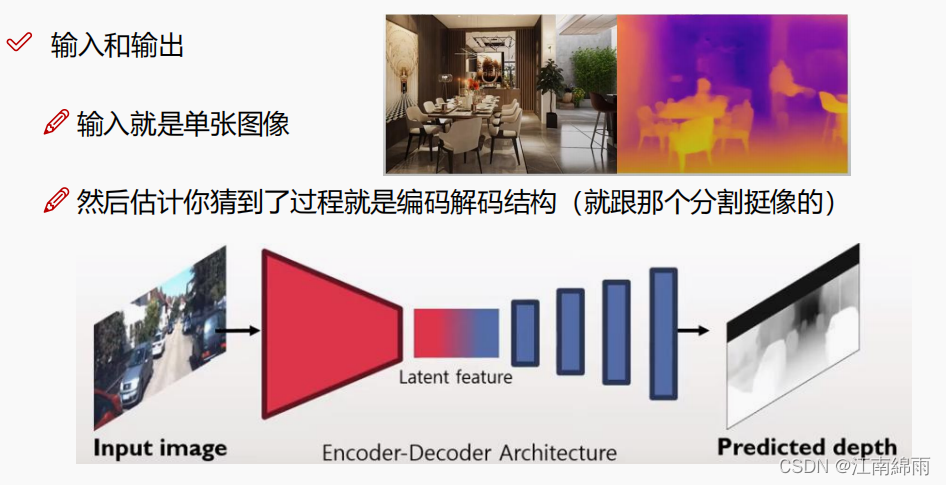
Claro, o real a arquitetura de rede não é tão simples, mas todas giram em torno da codificação-decodificação. A seguir, uma arquitetura de rede lançada recentemente pela CVPR. Vou explicar este "gigante" módulo por módulo:
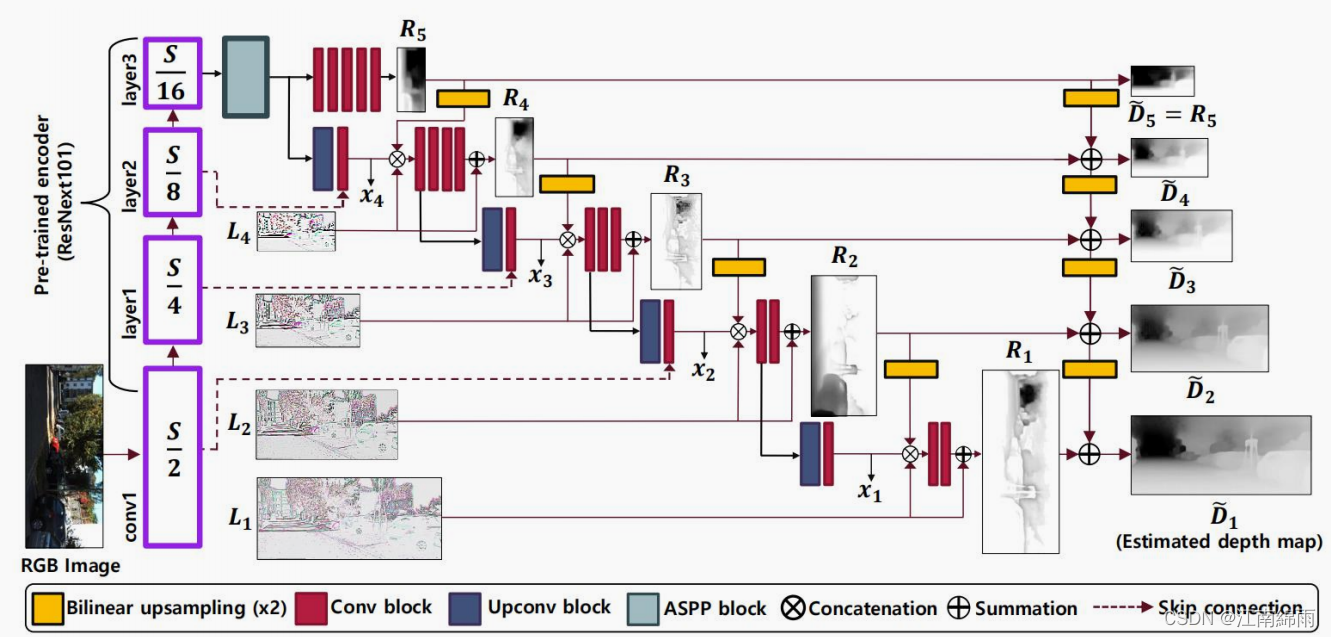
3. Análise do módulo
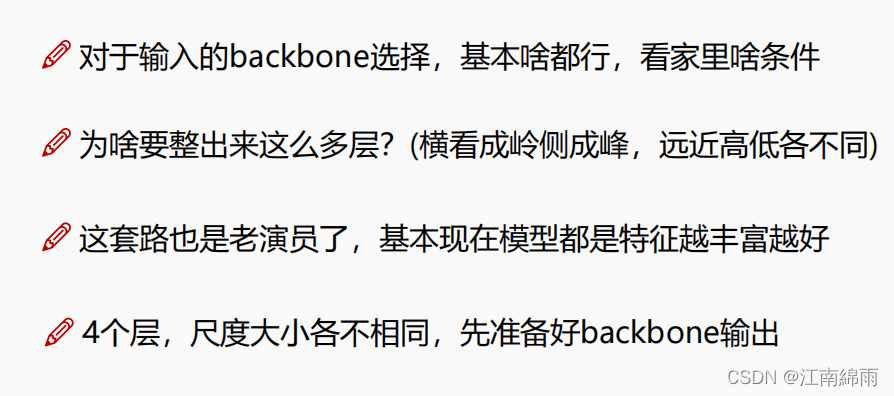
Ⅰ: Nível
Na verdade, após várias camadas de pooling, ele é reduzido pela metade a cada vez.O backbone aqui usa Resnet101. É semelhante ao funcionamento de redes como U-net, principalmente para as seguintes operações, conforme a figura:
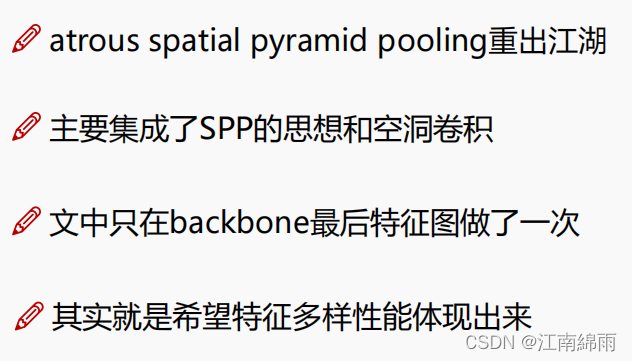
Ⅱ:ASPP
O autor fez ASPP no último mapa de recursos do backbone. Não vou repetir o que é ASPP aqui. É a combinação de convolução atrosa e SPP . O objetivo de usar o ASPP é adicionar alguma diversidade de recursos, mantendo uma certa resolução ( também operações de rotina de domínio de divisão de imagem). como a imagem mostra:
Ⅲ: operação de subtração do mapa de recursos
No campo da pesquisa de estimativa de profundidade, a informação de profundidade de contorno de objetos é um desafio. Para resolver efetivamente este problema, o autor realizou uma operação divina , combinando dois mapas de recursos A − B ABA−B é subtraído (o mapa de características B é um mapa de características do mesmo tamanho que A após o upsampling), as características de diferença são extraídas e o mapa de características de contorno L é obtido. Como mostrado abaixo:


IV: fusão de recursos
Para uma superposição, primeiro faça pleno uso da fusão do mapa de recursos de alto nível e do mapa de recursos desta camada para obter o mapa de recursos intermediário X para aumentar o recurso multiescala. Em seguida, una o resultado de previsão de alto nível R'' e o mapa de contorno L da camada atual e obtenha o resultado de previsão R da camada atual após uma miscelânea. Cada camada é operada assim, conforme mostrado na figura:
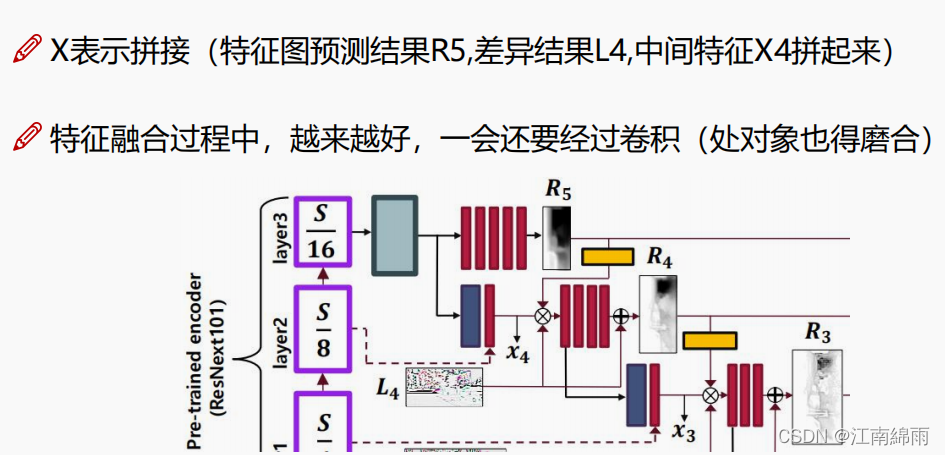
Ⅴ:grosseiro a fino
Por fim, há a etapa de “esculpir” os detalhes, onde o R de cada camada é fundido para se obter o resultado final da previsão R''', conforme mostra a figura:

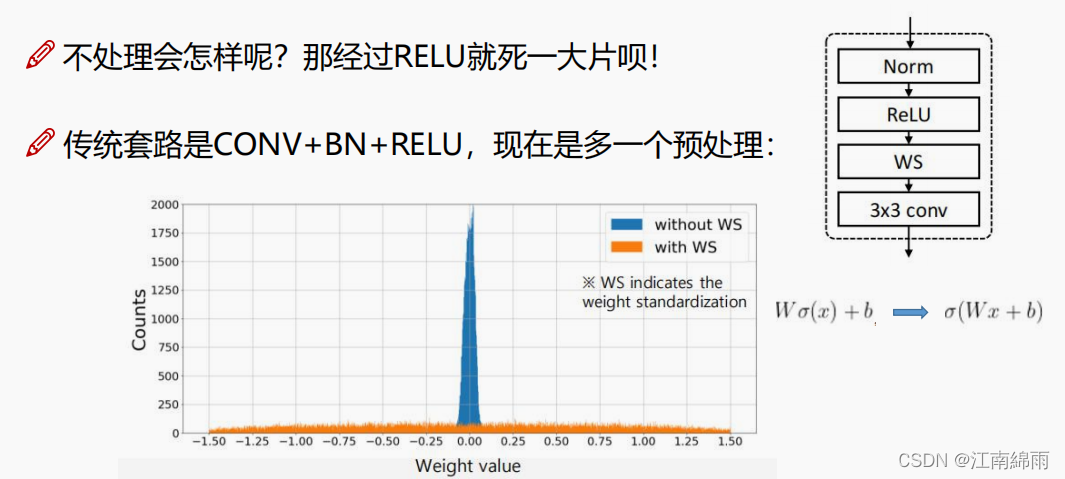
Ⅵ: Pré-processamento do parâmetro de peso WS e operação pre_act
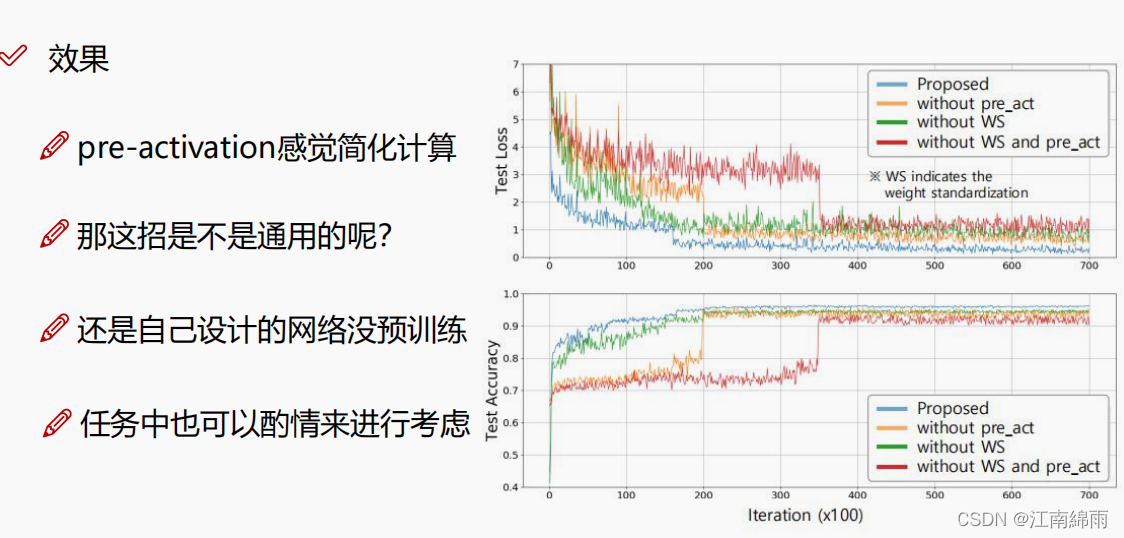
Alguns detalhes foram adicionados à rede real. Em primeiro lugar, a operação WS de padronização de peso é adicionada para tornar a distribuição dos parâmetros de peso mais uniforme. Funções, como Mish, Leaky ReLU, Swish, etc.?) pre_act , que é executar ReLU em x primeiro e depois entrar na camada de convolução. Em comparação com o sistema budista, para seus experimentos, a precisão realmente melhorou. salto, conforme mostrado na figura abaixo:
VII: Função de perda
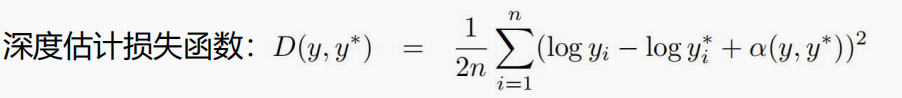
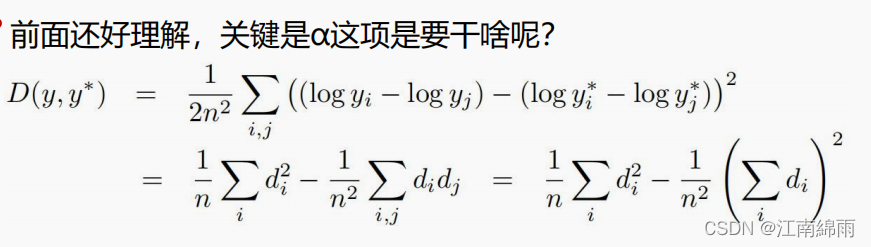
dd na função de perda simplificadad é na verdade a diferença entre a profundidade prevista e a profundidade real de cada pixel, o foco está no últimodidj di djO que significa a soma de d i d j e por que há um sinal negativo na frente dela. Por exemplo, todos entendem que se dois pixels forem encontrados, a diferença entre o valor previsto e o valor real éd 1 d1d 1 ed 2 d2d 2 , se as duas diferenças forem negativas, então a multiplicação é um valor positivo, e um sinal negativo é adicionado na frente, o que significa que não será punido. Pelo contrário, se os dois tiverem sinais diferentes, será ser punido. visívelO objetivo deste item na função de perda é esperar que os valores previstos a serem obtidos sejam um pouco mais baixos ou um pouco mais altos, ao invés de uma grande previsão aqui e uma pequena previsão ali., de modo que o efeito é realmente pior e o modelo é menos confiável.
Até agora, expliquei brevemente o princípio do uso de aprendizado profundo para estimativa de profundidade monocular. Espero que seja útil para todos. Se você tiver alguma dúvida ou sugestão, deixe um comentário abaixo.
Eu sou um peixe salgado de Jiangnan lutando no pântano CV, vamos trabalhar duro juntos e não deixar arrependimentos!