Diretório de artigos
1. Resumo
A detecção de alvos monoculares sempre foi uma tarefa desafiadora no campo da direção autônoma. A maioria dos métodos atuais usa detectores 2D baseados em convolução, que primeiro detectam o centro do objeto e depois prevêem atributos 3D por meio de recursos próximos ao centro.
No entanto, é ineficiente prever características 3D apenas através de características locais, e a relação de profundidade entre alguns objetos de longa distância não é considerada e muitas informações significativas são perdidas.
Neste trabalho, o autor apresenta uma rede para detecção monocular baseada no framework DETR. O autor modificou a rede de transformadores original e adicionou uma estrutura de transformador guiada em profundidade. O autor chamou essa estrutura de rede de MonoDETR.
Especificamente, além de usar um codificador visual para extrair características da imagem, o autor também introduziu um codificador de profundidade para prever o mapa de profundidade do primeiro plano, que foi posteriormente convertido em incorporações de profundidade. Depois disso, é consistente com o DETR ou BevFormer tradicional, usando a consulta de objeto 3D para realizar atenção própria e cruzada, respectivamente, com a incorporação de visão e incorporação de profundidade gerada anteriormente, e os resultados finais 2D e 3D são obtidos através do decodificador. Através deste método, cada objeto 3D obtém informações 3D através de regiões guiadas por profundidade (incorporação) em vez de ficar limitado a recursos visuais locais.

2. Introdução
Em comparação com tarefas de detecção 3D baseadas em lidar e multivisualização, a detecção 3D monocular é relativamente difícil. Porque não há informações de profundidade 3D e relações geométricas de múltiplas visualizações nas quais se possa confiar. Portanto, os resultados dos testes correspondentes não serão tão bons.
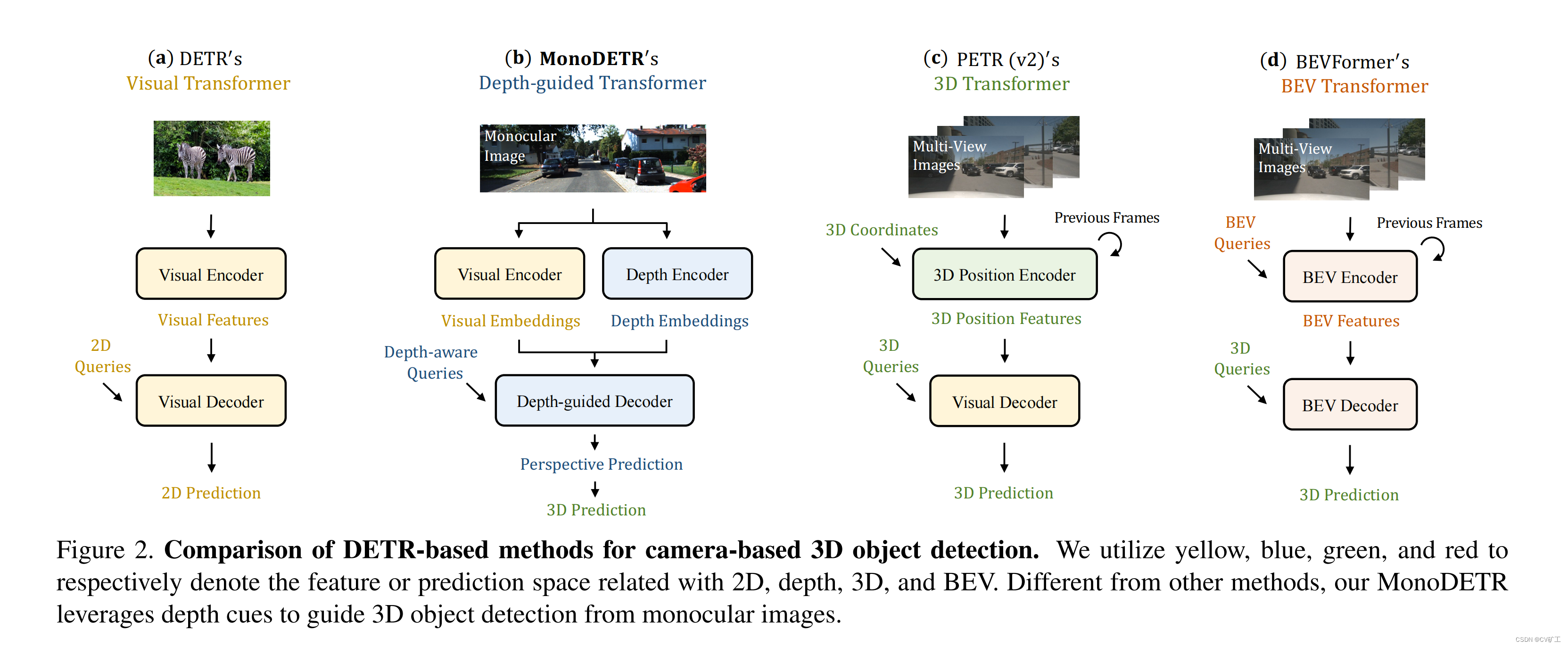
Para resolver estes problemas, propomos a estrutura de rede deste artigo baseada na estrutura de detecção 2D do DETR . Conforme mostrado em b na figura acima: esta estrutura inclui duas partes paralelas, nomeadamente codificador de visão e codificador de profundidade.
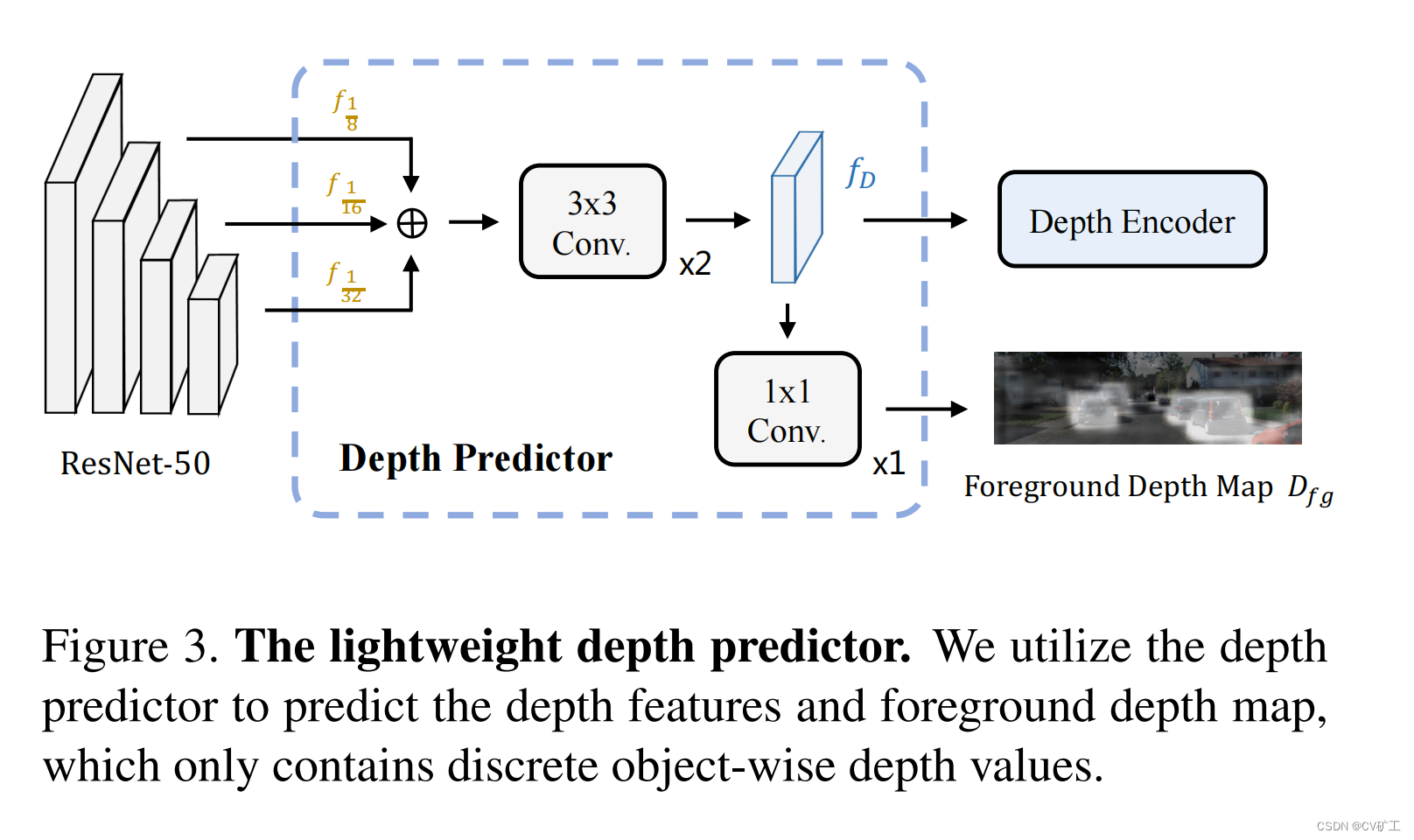
Foco: Como aprender informações profundas? O artigo aqui usa uma supervisão “leve” para obter as informações de profundidade da imagem de entrada. Especificamente, um preditor de profundidade é conectado após o backbone da imagem para gerar o mapa de profundidade do primeiro plano. Ao mesmo tempo, o recurso de profundidade gerado durante o processo será inserido no codificador de profundidade subsequente para extrair informações de profundidade. Ao mesmo tempo, supervisionamos o mapa de primeiro plano de saída. Esta supervisão consiste apenas no nosso objeto rotulado, que é uma profundidade discreta de objetos. Isso elimina a necessidade de rótulos densos de mapas de profundidade. Pressão reduzida sobre os dados. Também pode obter as informações de profundidade utilizadas.
Após esses dois codificadores, continue com uma estrutura de transformador, usando consulta de objeto para agregar informações de incorporação visual e incorporação de profundidade para detectar objetos.
A vantagem aqui é óbvia: em comparação com vários pipelines de dados pesados no campo atual da direção autônoma, este método requer apenas resultados convencionais de rotulagem de objetos para completar todo o processo de detecção. Não são necessários mapas de profundidade densos adicionais ou informações Lidar. E alcançou resultados SOTA em Kitti.
Ao mesmo tempo, o codificador de profundidade mencionado aqui também pode ser usado como um plug-in plug and play para aprimorar diretamente o efeito de detecção 3D multivisual, como o BEVFormer. (Claro, esses pontos parecem inúteis para mim~)
3. Trabalho relacionado
Vamos ler o jornal nós mesmos ~ Não tem muito a ver com este artigo
De repente, vi uma introdução interessante, então vou explicá-la brevemente aqui:
Métodos básicos DETR
- MonoDTR: Basta introduzir o transformador para aprimorar a extração de dados. Ainda é um recurso local extraído, baseado no centro do objeto, que não é estritamente baseado em DETR. Para obter detalhes, consulte: Interpretação MonoDTR
- DETR3D e PETR v2: detecção 3D multivisualização, usando a estrutura detr, mas o codificador da base de transformação não é usado. Da mesma forma, apenas informações visuais são utilizadas, sem informações profundas. Para referência específica, consulte PETR v2 para interpretar DETR 3D.
- BEVFormer: Adicionado um codificador do recurso de imagem ao recurso bev para extração de informações. A detecção 3D subsequente é realizada no espaço bev. BOM! BEV Antiga Interpretação
4. Método
Chegou novamente a hora da tão querida parte de olhar fotos e falar sobre teses, na foto acima
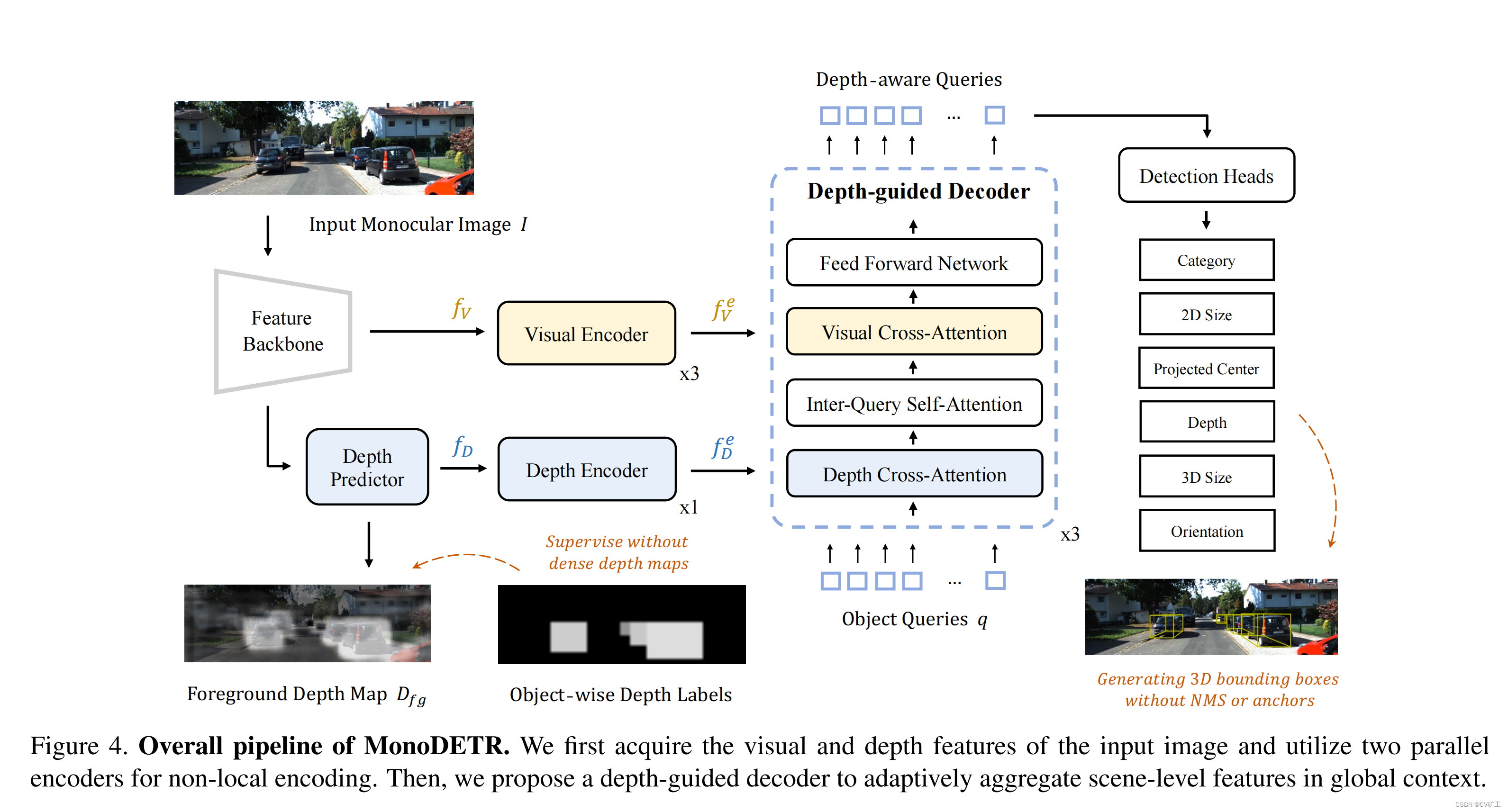
4.1 Extração de recursos
Recursos visuais
Sem entrar em muitos detalhes, a rede CNN convencional usada para extrair recursos de imagens de alta ordem basicamente converge para o uso de resnet. As taxas de redução da resolução definidas aqui são 1/8, 1/16 e 1/32. Neste artigo, os resultados do fpn de três camadas não são usados, mas a última camada com a informação semântica mais rica é selecionada como o codificador de visão de entrada de recurso visual.
recursos de profundidade
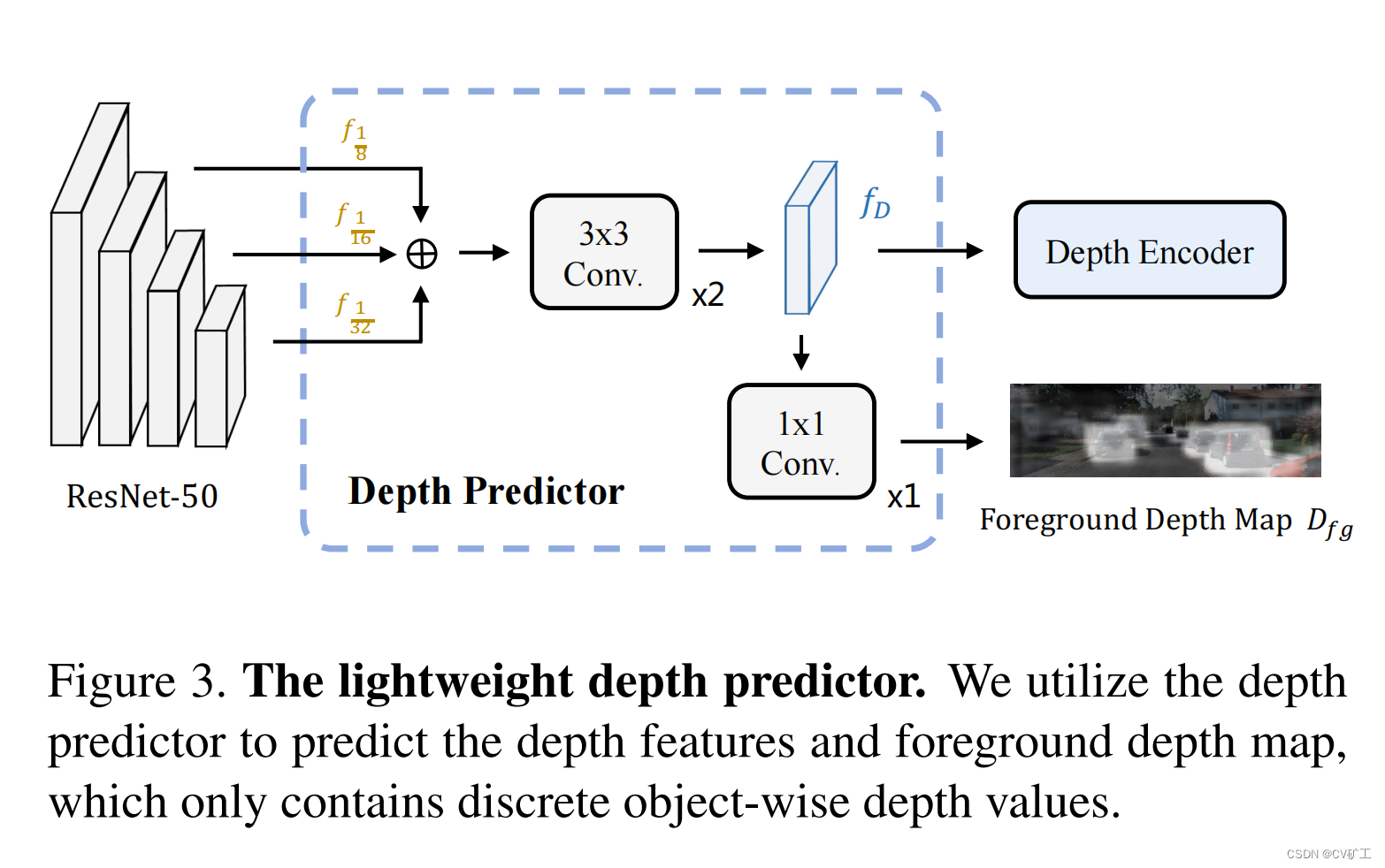
Aqui, os recursos profundos são primeiro fundidos (adição de elementos) às três camadas de recursos extraídos do backbone. O objetivo principal é reter as características de alvos pequenos. Em seguida, use uma rede 3*3 para extrair recursos de profundidade.
mapa de profundidade em primeiro plano
Para tornar os recursos profundos mais eficientes e ricos. Uma profundidade adicional de supervisão é adicionada aqui. Ao passar o recurso de profundidade por uma convolução 1*1, um mapa de profundidade de primeiro plano é gerado. E nós supervisionamos isso por meio de rótulos profundos discretos baseados em GT. Regras específicas: Os pixels no bbox 2D são atribuídos uniformemente à profundidade do objeto. Se for um pixel dentro de duas bboxes, selecione o valor de distância mais próximo da câmera para atribuição. Ao mesmo tempo, a profundidade também é codificada discretamente aqui. Para métodos de referência, consulte: Rede de distribuição de profundidade categórica para detecção monocular de objetos 3D
Resumo simples: na distância de detecção [dx, dy] [d_x, d_y][ dx,dvocê] , use a distribuição de discretização linear crescente (LID) para codificá-lo e codificá-lo em k+1 compartimentos no total. Dentre eles, k são o primeiro plano e o último é o fundo. A fórmula específica usada é a seguinte:
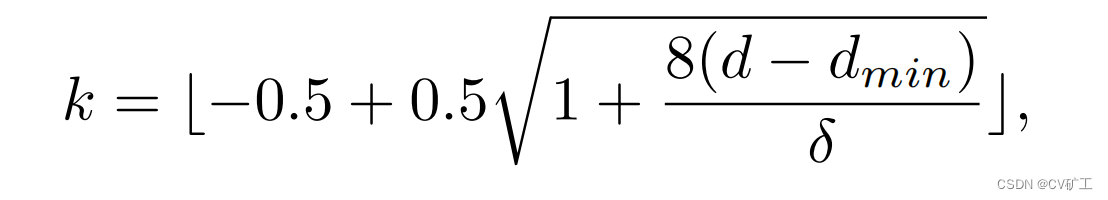
ondeδ \deltaδ é a tolerância do parâmetro relevante. Pode ser obtido com base na distância de detecção e no número de bins necessários.
4. Transformador guiado de 2 profundidades
Codificadores visuais e de profundidade
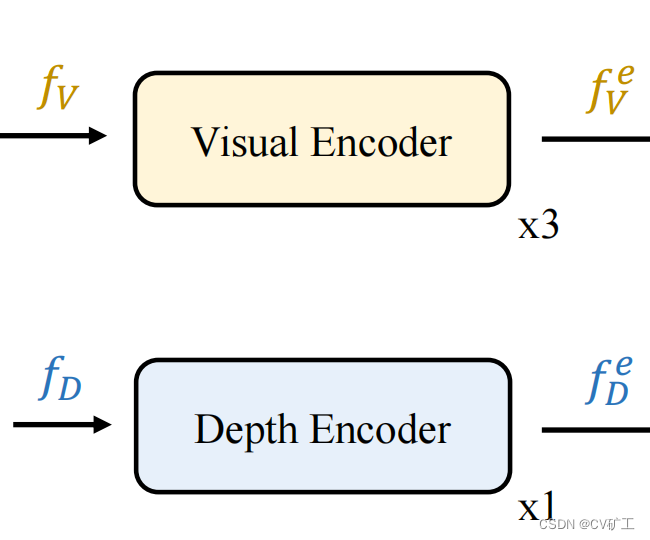
O autor usa dois codificadores para realizar extração adicional de recursos globais nas imagens adquiridas e recursos de profundidade. Aqui, o autor também mostra cuidadosamente a operação de nivelamento de recursos que precisa ser executada ao usar o transformador, descrevendo a dimensão do recurso. As dimensões são H ∗ W / 1 6 2 H*W/16^2H∗C /1 62 somaH ∗ W / 3 2 2 H*W/32^2H∗C /3 22 . A composição específica é que cada bloco codificador consiste em uma autoatenção e ffn. A função do codificador aqui é atualizar o recurso local para o recurso global. Como o recurso de visão contém informações mais complexas, três blocos são usados para extrair melhor as informações de visão.
Decodificador guiado por profundidade
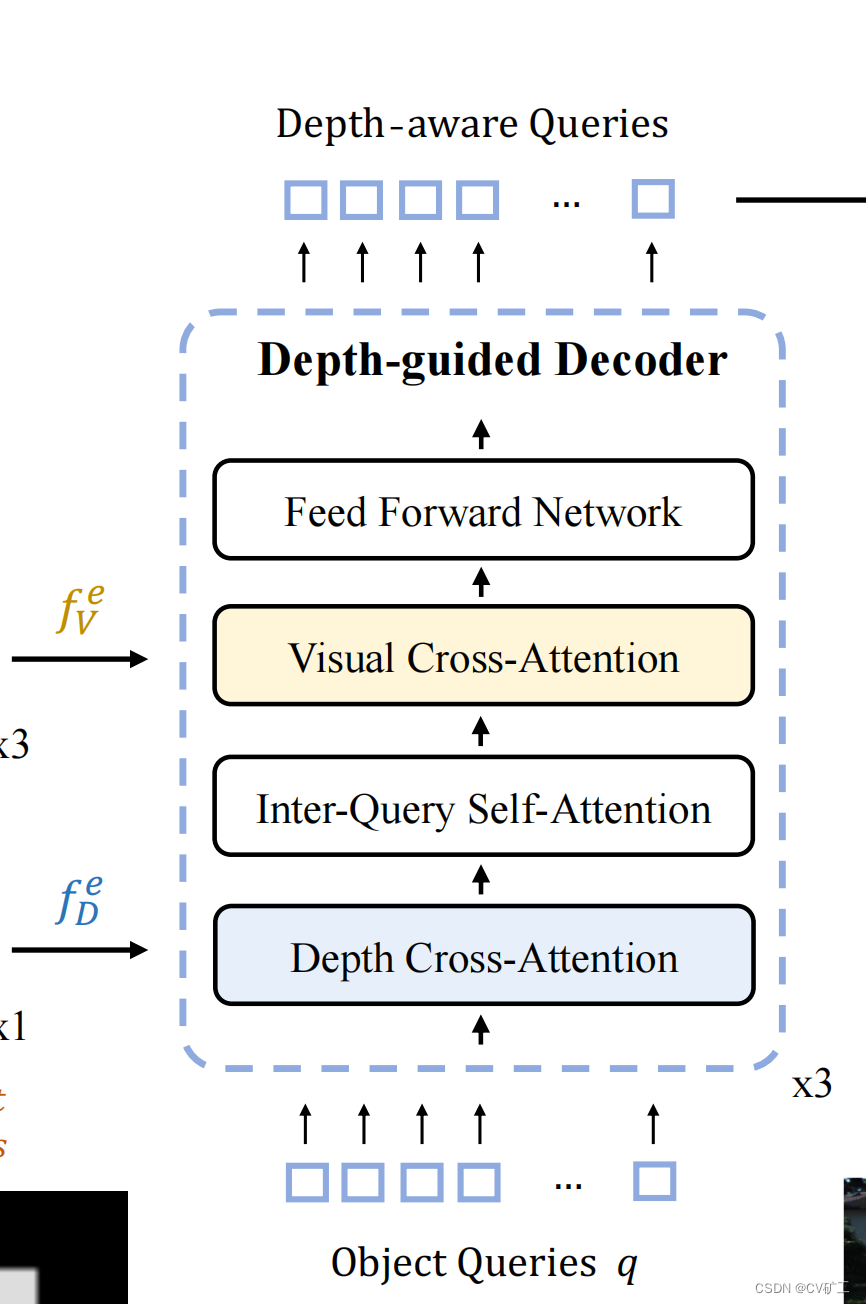
Concentre-se em: a parte central.
De acordo com os recursos globais f D e f_D^e extraídos do codificadorfDeSoma V e f_V^efVe, o autor projetou uma estrutura de decodificador baseada em orientação profunda. Use consultas de objetos predefinidos q para somar f D e f_D^efDeSoma V e f_V^efVeCruze a atenção. Cada bloco contém uma atenção cruzada de profundidade, uma autoatenção entre consultas, uma atenção cruzada visual e um FFN. A incorporação do objeto de saída dessa forma inclui informações visuais e informações de profundidade, que podem realizar melhor o trabalho de previsão.
Para melhor integrar e extrair informações, o autor utilizou um total de 3 blocos para fazer o trabalho de decodificação.
Codificação posicional de profundidade
A incorporação de posição é necessária no transformador. Não há uso direto de uma função sin como codificação de posição como outras estruturas. Em vez disso, são usadas codificações posicionais de profundidade que podem ser aprendidas. Os detalhes específicos são usar o mapa de profundidade obtido na sequência anterior para obter a diferença e f D e f_D^efDeAs informações de profundidade correspondentes são então comparadas com f D e f_D^efDeExecute a adição ponto a ponto. Dessa forma, a consulta de objetos pode capturar melhor informações de profundidade no nível da cena e compreender melhor as informações geométricas 3D.
4. 3 Cabeças de detecção e perda
correspondência bipartida
Usando correspondência binária, dois conjuntos de métricas são projetados. Um conjunto é de informações 2D, incluindo categoria, posição 2D e tamanho 2D. O segundo grupo contém posição 3D, tamanho 3D e orientação. Teoricamente, a soma dos dois conjuntos de custos deveria ser utilizada para a correspondência. No entanto, como as informações 3D são difíceis de aprender e instáveis, isso causará falha na correspondência, de modo que apenas o primeiro conjunto de informações será usado para correspondência.
perda geral
A fórmula de perda 2D + perda 3D + perda do mapa de profundidade
é a seguinte:
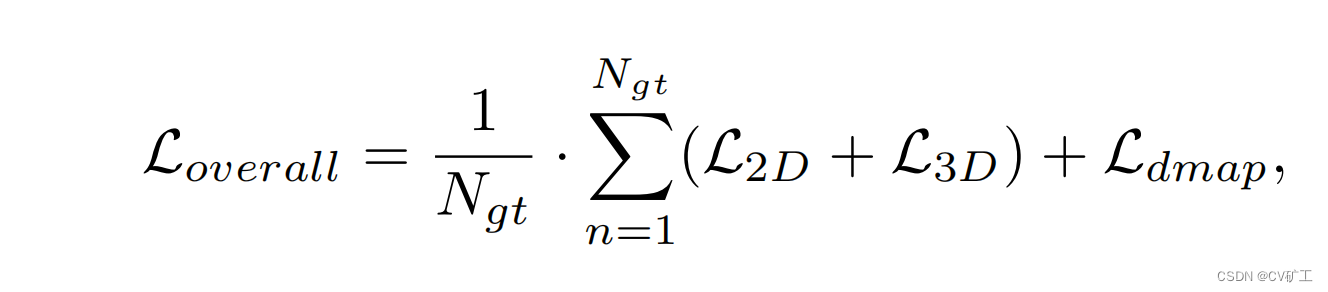
4.4 Plug-and-play para detectores multivisualização
A principal conclusão é que ele pode ser adicionado à detecção de alvos multivisualização como um complemento à informação 3D, e melhores resultados podem ser obtidos. Não vou entrar em detalhes um por um. Durante a implantação de engenharia, os benefícios definitivamente não são tão grandes quanto o poder computacional gasto. (Autor, por favor, não me bata)
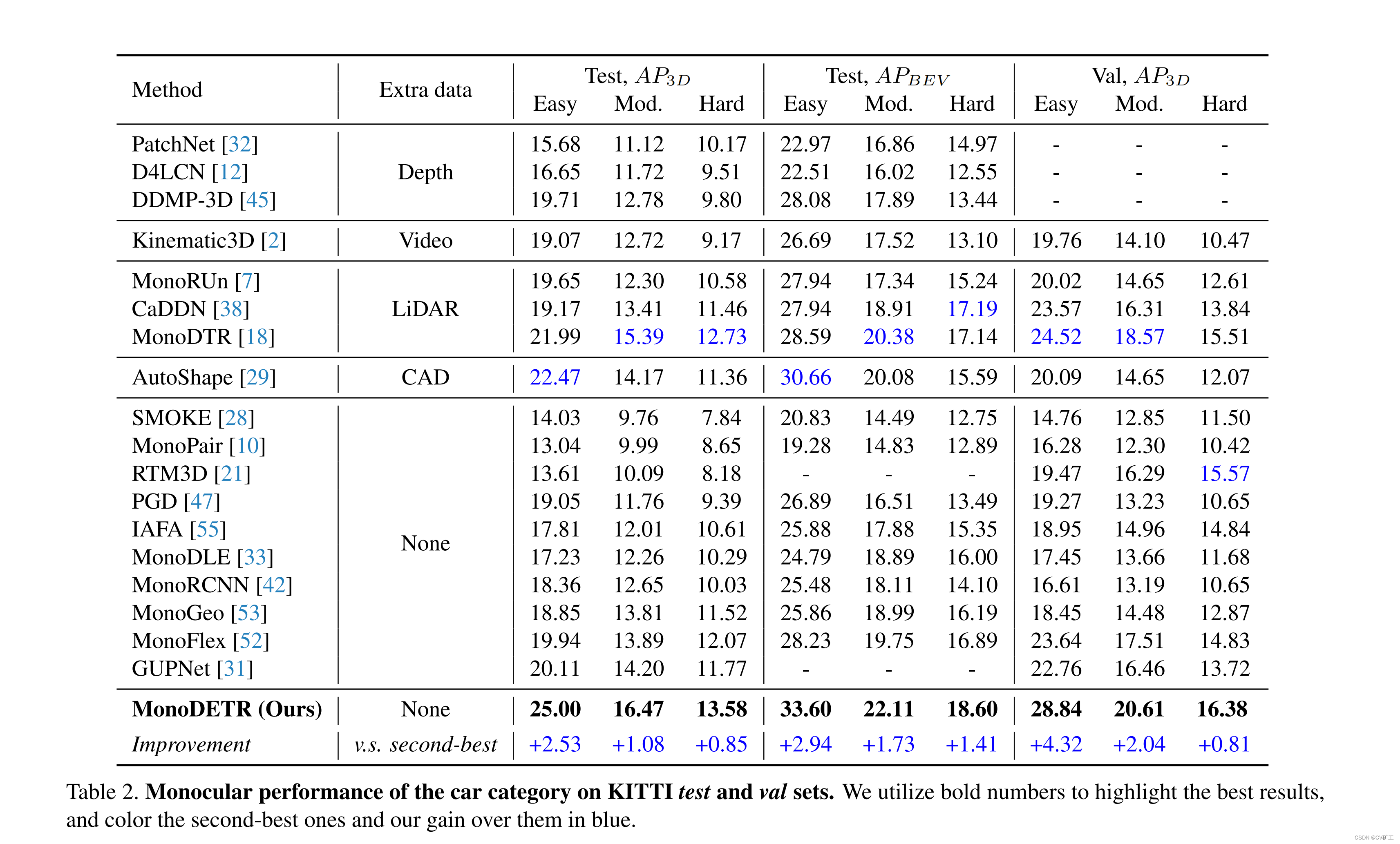
5 experimentos
Nós somos os melhores. Todos os experimentos de ablação podem provar que a estrutura atual é a melhor ~ Vou postar apenas os resultados do mapa.