Clique em " Xiaobai Learning Vision " acima e escolha adicionar " Star " ou " Top "
重磅干货,第一时间送达guia do artigo
Introdução: Com o desenvolvimento contínuo da tecnologia de visão computacional, especialmente em algumas pesquisas de ponta, como a direção automática, as informações de profundidade das imagens são muito importantes. A medida de distância monocular tem sido preferida pelos pesquisadores devido ao seu baixo custo. O editor também está aprendendo o conhecimento da medição de distância monocular recentemente, e compartilharei com você um método de medição de distância monocular BTS, vamos aprender juntos.
Parte 01
A diferença entre os princípios de alcance monocular e binocular
Monocular e binocular são dois tipos diferentes de câmeras. Ambas podem obter informações de distância por meio de cálculos por meio das imagens coletadas, mas os princípios de medição de distância dos dois são completamente diferentes. O alcance monocular é geralmente chamado de estimativa de profundidade e sua precisão é relativamente baixa. O alcance monocular é obter o reconhecimento do alvo por meio da correspondência de imagens e, em seguida, estimar a distância do alvo pelo tamanho do alvo na imagem. A medição de distância binocular é para calcular a distância através do mapa de disparidade entre as duas imagens. Este método não precisa identificar o tipo de alvo e a precisão é mais precisa do que a medição de distância monocular.
Parte 02
Vantagens e desvantagens de alcance único e binocular
As vantagens da medição de distância monocular são baixo custo, estrutura de sistema simples e baixa demanda de cálculo. Mas sua desvantagem é que ele precisa atualizar e manter um enorme banco de dados de amostras para garantir uma alta taxa de reconhecimento, e a precisão geral do alcance é baixa.
A vantagem do alcance binocular é que ele tem alta precisão. Ele usa diretamente o princípio do mapa de disparidade para medir a distância diretamente, sem manter o banco de dados da amostra, e a precisão da medição da distância classificada é alta. A desvantagem é que o custo do alcance binocular é maior do que o monocular, e os sistemas binoculares têm requisitos muito altos para desempenho de computação e geralmente precisam ser equipados com um chip de processamento de imagem dedicado.
Parte 03
Dificuldades em alcance monocular
A odometria monocular é um problema mal colocado porque existem infinitas cenas 3D que podem ser projetadas na mesma cena 2D. Para entender as configurações geométricas de uma única imagem, é preciso considerar não apenas as pistas locais, mas também o contexto global.
Nota: Problema bem posto e problema mal posto são ambos termos no campo da matemática. O primeiro precisa atender a três condições, e se uma delas não for satisfeita, é chamado de “problema mal colocado”:
(1) existe uma solução: a solução deve existir
(2) a solução é única: a solução deve ser única
(3) o comportamento da solução muda continuamente com as condições iniciais: a solução pode mudar continuamente de acordo com as condições iniciais sem pular, ou seja, a solução deve ser estável
Parte 04
Proposta do método BTS
Uma rede neural convolucional geralmente consiste em 2 partes, um codificador para extração de recursos densos e um decodificador para prever a profundidade desejada. No esquema do codec, camadas repetidas de convolução e agrupamento espacial reduzem a resolução espacial da saída excessiva e empregam conexões de salto ou técnicas de rede de deconvolução multicamada para restaurar a resolução à resolução original. os métodos atuais de restauração de mapas de recursos para a resolução original da rede são relativamente diretos e perderão informações, que também é o conteúdo principal da melhoria no documento BTS.
A estrutura da rede BTS é mostrada na figura abaixo:
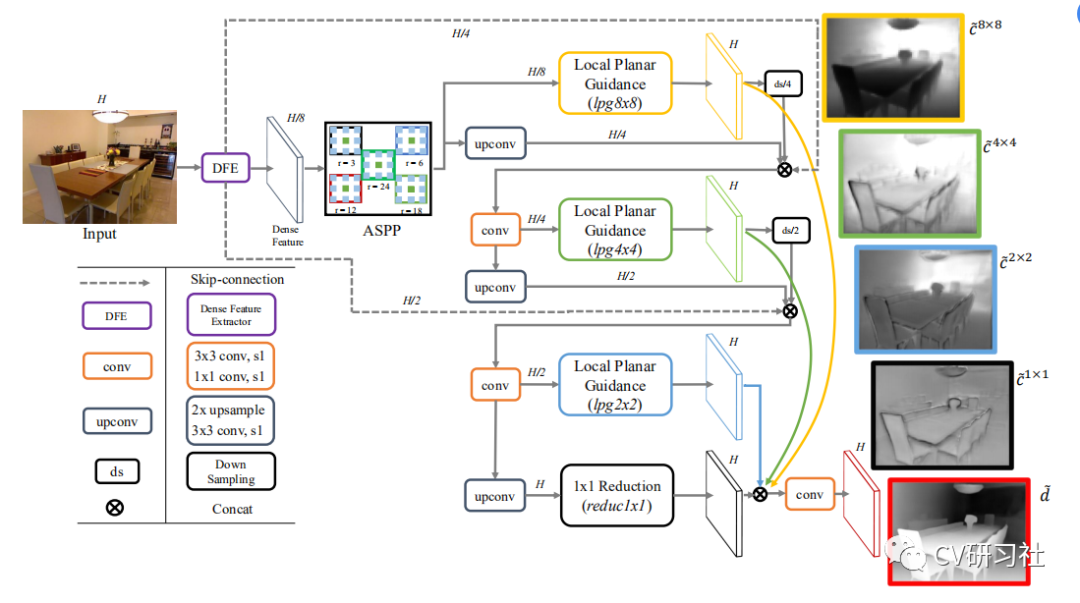
Diagrama de estrutura de rede BTS
A estrutura da rede inclui: estrutura do codificador, conexão de salto, agrupamento de pirâmide de espaço poroso (ASPP) e camada de LPG.
A inovação do BTS: É proposta uma estrutura de rede de camada de orientação planar local (camadas de orientação planar local), que associa as características de diferentes escalas no estágio de decodificação com a previsão final de profundidade. O codec usual é impor restrições de perda de treinamento na saída final da decodificação para produzir o mapa de profundidade.O editor acha que a estrutura de rede da camada LPG proposta neste artigo deve desempenhar um papel na imposição de restrições na rede.
Desempenho da rede: A partir de agora, o método BTS ocupa o 7º lugar na lista de estimativa de profundidade monocular KITTI, com uma velocidade de inferência de 60ms, alcançando um equilíbrio entre precisão e velocidade.
Parte 05
A implementação específica da camada LPG
A ideia central proposta pela camada de rede LPG: diferente do método tradicional que simplesmente usa o upsampling do vizinho mais próximo e ignora a conexão para restaurar a imagem ao tamanho original, o método BTS define os recursos internos e a saída final de maneira eficaz ( camadas LPG) Existe uma relação direta e explícita entre elas, orientando as características para a resolução global e combinando-as para obter a estimativa final de profundidade.
Especificamente, dado um mapa de feições com resolução espacial de H/K, a camada LPG proposta estima um coeficiente de plano 4D para cada unidade espacial, com o tamanho do plano correspondente à resolução da feição. Os coeficientes se ajustam a k × k patches definidos localmente na resolução total H e são concatenados por uma camada convolucional final para a previsão final. Por exemplo, quando a resolução do recurso de entrada é 1/4, a saída do vetor 4D em cada posição caberá em um plano 4*4. Em termos simples, o coeficiente do plano 4D ajustará um plano com uma resolução maior do que o recurso de entrada, de modo que, embora a resolução do mapa de recursos de entrada seja diferente, ele eventualmente produzirá um plano com o mesmo tamanho. O diagrama esquemático da camada de GLP é o seguinte:
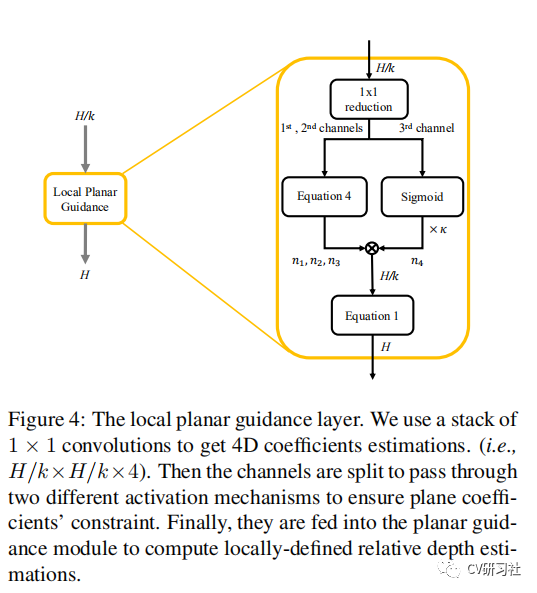
(1) Use a convolução 1 × 1 para reduzir o número de canais e reduza o número de canais em 2 vezes cada vez que a convolução 1 × 1 for executada até o canal = 3, porque o número de canais da imagem colorida é 3, então até um mapa de características H/ K×H/K×3.
(2) Channel1 e channel2 representam os dois graus de liberdade do vetor plano normal, que são os ângulos polar(θ) e azimutal(φ), respectivamente. Em seguida, os dois primeiros canais do mapa de recursos são considerados como ângulos, e o a fórmula a seguir é usada Converta-os em vetores normais unitários.
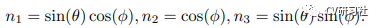
Channel3 representa a distância vertical entre o plano e a origem (distância perpendicular).
(3) Após a transformação, cada pixel corresponde a um conjunto de vetores 4D (n1, n2, n3, n4).
(4) Para usar as suposições do plano local para guiar os recursos, um método de interseção raio-plano é usado para converter cada coeficiente estimado do plano 4D em pistas de profundidade local K × K. A fórmula de conversão é mostrada na figura abaixo, onde (ui, vi) são as coordenadas normalizadas bloco a bloco k × k do pixel i e c é o resultado final do ajuste.
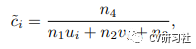
Parte 06
experimentar
Indicadores de avaliação:

Resultados experimentais: O autor realizou experimentos em dois grandes conjuntos de dados públicos: KITTI e NYU Depth V2. A seguir estão os resultados experimentais específicos.
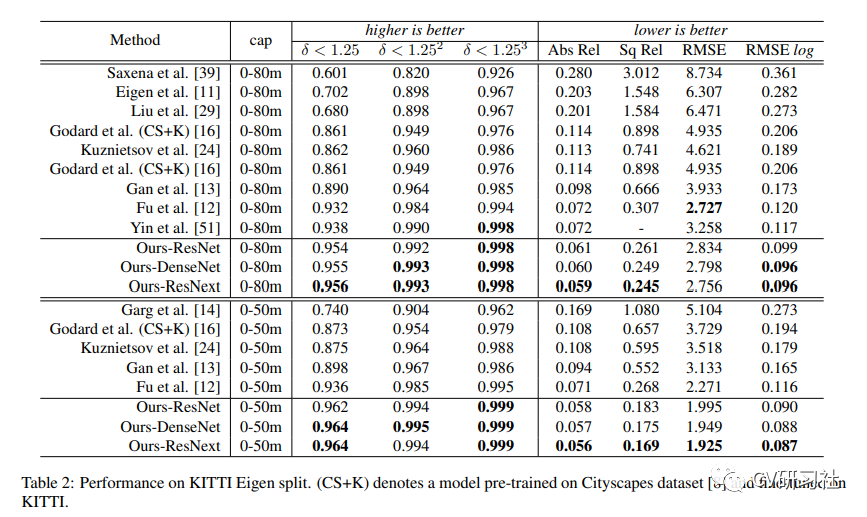
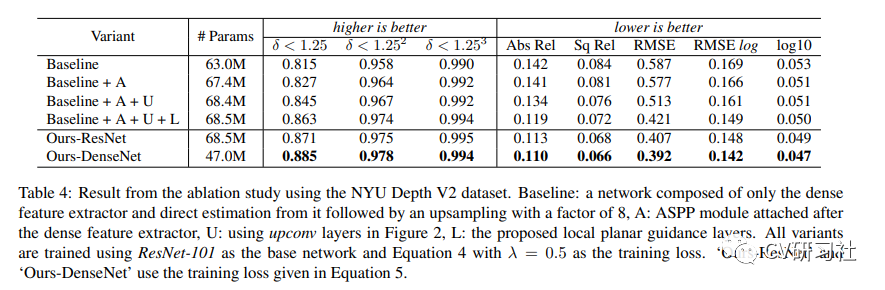


Parte 07
Resumir
Neste artigo, o autor estuda a estrutura do codificador-decodificador e analisa as deficiências do método existente para upsampling violento na parte do decodificador. A estrutura da camada de rede LPG é proposta. Ao associar os recursos de diferentes escalas no estágio do decodificador com a previsão de profundidade de saída final, é realizado um uso mais suficiente e eficaz dos recursos, melhorando assim o efeito geral da rede. Eu acho que este módulo pode ser migrado para outras tarefas de uso, e também deve ajudar a melhorar o desempenho da rede.
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~