Índice
tarefas de visão computacional
1. K algoritmo do vizinho mais próximo
4. Propagar o processo geral adiante
5. Método de cálculo de retropropagação
tarefas de visão computacional
O processo de aprendizado de máquina :
-
coleção de dados
-
engenharia de recursos
-
Modelagem
-
Avaliação e Aplicação
Visão Computacional :
Representação da imagem: a imagem aos olhos do computador, e uma imagem é representada como uma matriz tridimensional, com o valor de cada pixel variando de 0 a 255.
Desafios na Visão Computacional: Ângulo de Iluminação, Mudança de Forma, Oclusão Parcial e Mesclagem de Fundo
1. K algoritmo do vizinho mais próximo
O algoritmo de classificação K (k-Nearest Neighbor, KNN) é um método relativamente maduro em teoria e um dos algoritmos de aprendizado de máquina mais simples. A ideia desse método é: no espaço de recursos, se a maioria das k amostras mais próximas de uma amostra (ou seja, os vizinhos mais próximos no espaço de recursos) pertencem a uma determinada categoria, então a amostra também pertence a essa categoria .
K processo de cálculo do vizinho mais próximo :
-
Calcula a distância de um ponto em um conjunto de dados de tipo conhecido até o ponto atual
-
Classificar por distância
-
Selecione K pontos com a menor distância do ponto atual
-
Determine a probabilidade de ocorrência da categoria dos primeiros K pontos
-
Retorna a categoria com a frequência de ocorrência mais alta dos primeiros K pontos como a categoria de previsão de ponto atual
Amostra de banco de dados: CIFAR-10
Introdução ao banco de dados:
10 tipos de rótulos, 50.000 dados de treinamento, 10.000 dados de teste, tamanho 32*32

O método de cálculo da distância da imagem é realmente muito semelhante à adição e subtração da matriz.
Limitações de K-Nearest Neighbors : Não pode ser usado para classificação de imagem, porque o domínio do fundo é o maior problema, focamos no assunto (componente principal)
2. Função de pontuação
De acordo com a função de pontuação, a pontuação da categoria de cada entrada é calculada da seguinte forma: temos apenas a pontuação da categoria e não podemos julgar o efeito da classificação, e a função de perda é usada para avaliar o efeito da classificação.
Função linear: mapeamento da entrada ---> saída
f(x, W) = Wx
A fórmula da função de pontuação é um método de cálculo usado para descrever a pontuação em uma determinada situação e geralmente é usada na pontuação, avaliação etc. A fórmula da função de pontuação geralmente consiste em vários parâmetros, cada parâmetro representa um fator de influência e a pontuação final é obtida ponderando esses parâmetros.
3. O papel da função de perda
A função de perda é uma função que mapeia eventos aleatórios ou suas variáveis aleatórias relacionadas a números reais não negativos.
No aprendizado de máquina, a função de perda é usada para medir a lacuna entre os resultados previstos do modelo e os resultados reais e, geralmente, quanto menor, melhor. Por exemplo, em problemas de regressão, você pode usar erro quadrático médio (MSE) e erro absoluto médio (MAE) como funções de perda; em problemas de classificação, você pode usar entropia cruzada (CrossEntropy) como uma função de perda ou usar a entropia cruzada binária (BCELoss) etc.
A fonte da matriz é o resultado da otimização.
O papel da rede neural é lidar com os problemas correspondentes por meio da matriz apropriada Wi.

Fazer tarefas diferentes é a diferença na função de perda.
Na verdade, existem muitas funções de perda, e o que precisamos é de uma forma de função que seja mais próxima da realidade.
Função de perda :
1 aqui é equivalente a uma estimativa de um valor aproximado.

Embora os valores da função de perda dos dois modelos sejam iguais, o modelo A considera a área local e o modelo B considera a situação geral. As duas ênfases são diferentes, mas os resultados são exatamente os mesmos.
Função de perda = perda de dados + penalidade de regularização (R(W))
Sempre esperamos que o modelo não seja muito complicado e que o modelo de overfitting seja inútil.
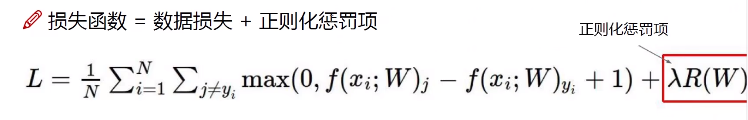
4. Propagar o processo geral adiante
O algoritmo de propagação direta, também conhecido como algoritmo de propagação direta, como o nome sugere, é um algoritmo executado da frente para trás.
Classificador Softmax
Agora obtemos uma pontuação para a entrada, mas não seria bom me dar uma probabilidade!
Como converter um valor de pontuação em um valor de taxa?
Isso tem algo em comum com a modelagem matemática, que geralmente pode ser dividida por uma função semelhante para obter um valor de probabilidade.
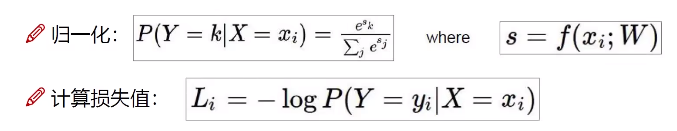
Normalizar e calcular o valor da perda
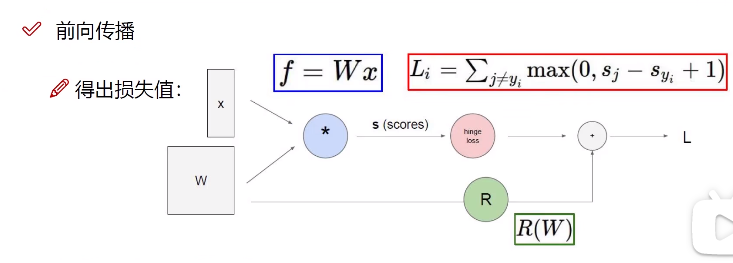
Propagar para a frente:
5. Método de cálculo de retropropagação
Como um exemplo:
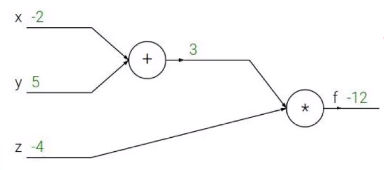
Sua fórmula funcional é: f(x,y,z) = (x+y)z
q=x+yf=q*z

O valor que você deseja solicitar: a derivada parcial de f até x, a derivada parcial de f até y e a derivada parcial de f até z.
Esta é a regra da cadeia que aprendemos em matemática avançada, o gradiente é propagado passo a passo
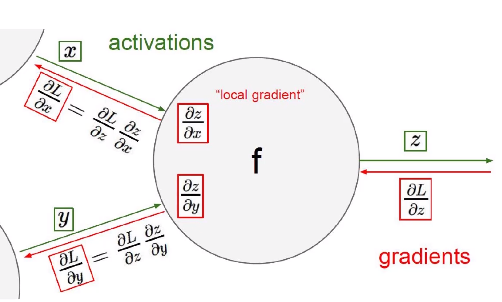
A linha verde que vemos é nossa parte anterior do cálculo de propagação para frente, e a parte vermelha carregará o gradiente anterior para o cálculo de propagação de volta da próxima camada.
O algoritmo de retropropagação, conhecido como algoritmo BP, é um algoritmo de aprendizado adequado para redes neurais multicamadas, baseado no método de gradiente descendente. A relação entrada-saída da rede BP é essencialmente uma relação de mapeamento: a função completada por uma rede neural BP com n entradas e m saídas é um mapeamento contínuo do espaço euclidiano n-dimensional para um campo finito no espaço euclidiano m-dimensional. O mapeamento é altamente não linear. Sua capacidade de processamento de informações vem da composição múltipla de funções não lineares simples, por isso tem uma forte capacidade de reproduzir funções. Esta é a base para a aplicação do algoritmo BP.
