prefácio
Nós o apresentamos na postagem anterior do blog Focal Loss, e o princípio é relativamente simples. Se você não o entender, pode pular para a postagem anterior do blog para saber mais sobre ele. Introdução à Perda Focal . Vamos dar uma olhada na fonte desta postagem do blog Focal Loss: Perda focal para detecção de objetos densosRetainNet , este artigo propõe uma rede one-stageque foi superada pela rede two-stage.
1. Rede RetainNet
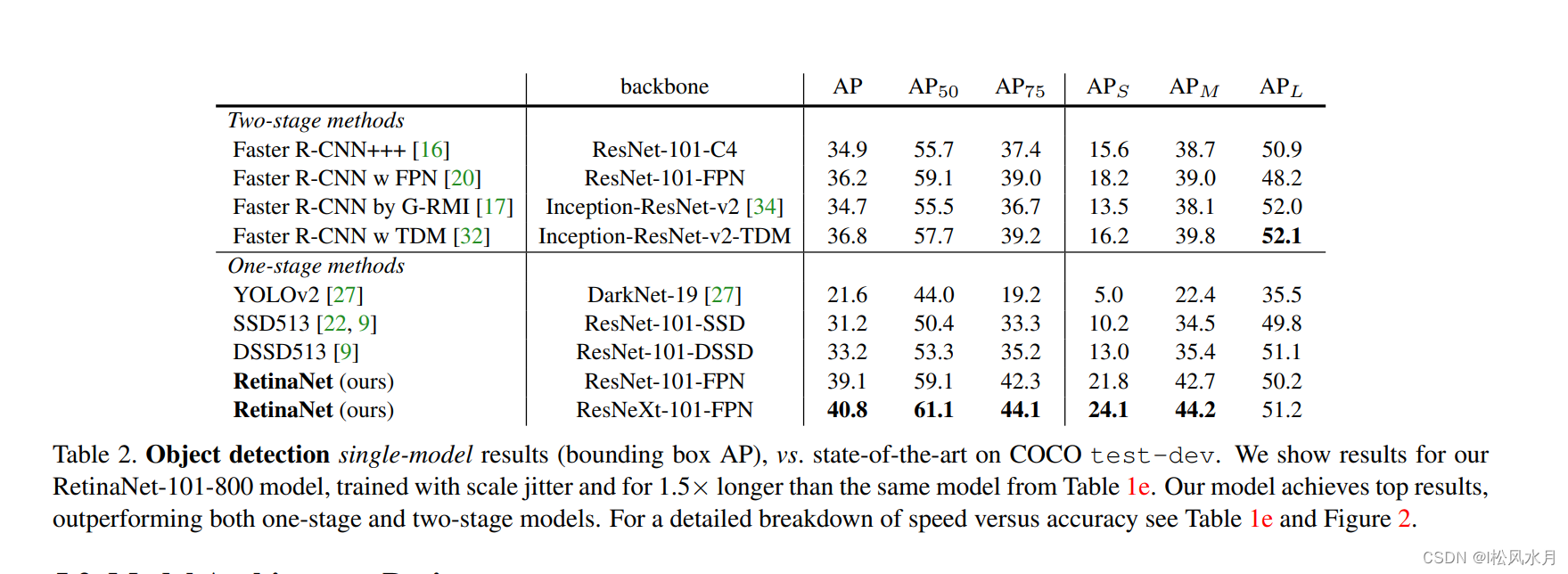
Vejamos primeiro o desempenho RetainNete você pode ver que ele é muito superior Faster R-CNNà rede. Vamos dar uma olhada na estrutura da rede novamente
: podemos ver que uma estrutura semelhante também é adotada , com três diferenças principais .RetainNet

RetainNetFPNFPN
FPNC2Compilações são usadasP2, compilaçõesRetainNetnão são usadas . A razão apresentada no artigo é que mais recursos computacionais serão calculados. Devido aos quatro recursos de baixo nível, a resolução é relativamente grande.C2P2C2C2FPNinP6é reduzido por uma camada de redução de escala máxima eRetainNet é reduzido por uma camada convolucional.FPNÉ deP2-P6, RetainNet é deP3-P7,P7éP6baseado em uma função de ativaçãoReLU e, em seguida, obtido por meio de uma convolução.
Em FPN, cada camada de feição de previsão usa apenas um scalee três ratios, e RetainNecada camada de feição de predição em t usa três scalee três ratios. RetainNetin scalee ratios如a seguinte tabela:
| camadas | passo largo | tamanhos_âncora | anchor_aspect_ratios | O número de âncoras geradas (multiplicado por 3 significa 3 proporções) |
|---|---|---|---|---|
| P2 | 4(2 ( ^)2) | 32 | 0,5,1,2 | (1024//4) ( ^)2×3=196608 |
| P3 | 8(2 ( ^)3) | 64 | 0,5,1,2 | (1024//8) ( ^)2xx3=49152 |
| P4 | 16(2 ( ^)4) | 128 | 0,5,1,2 | (1024//16)^^2xx3=12288 |
| P5 | 32(2 ( ^)5) | 256 | 0,5,1,2 | (1024//32) ( ^)2xx3=3072 |
| P6 | 64(2 ( ^)6) | 512 | 0,5,1,2 | (1024//64) ( ^)2×3=768 |
Vejamos novamente a parte do preditor do RetainNet:
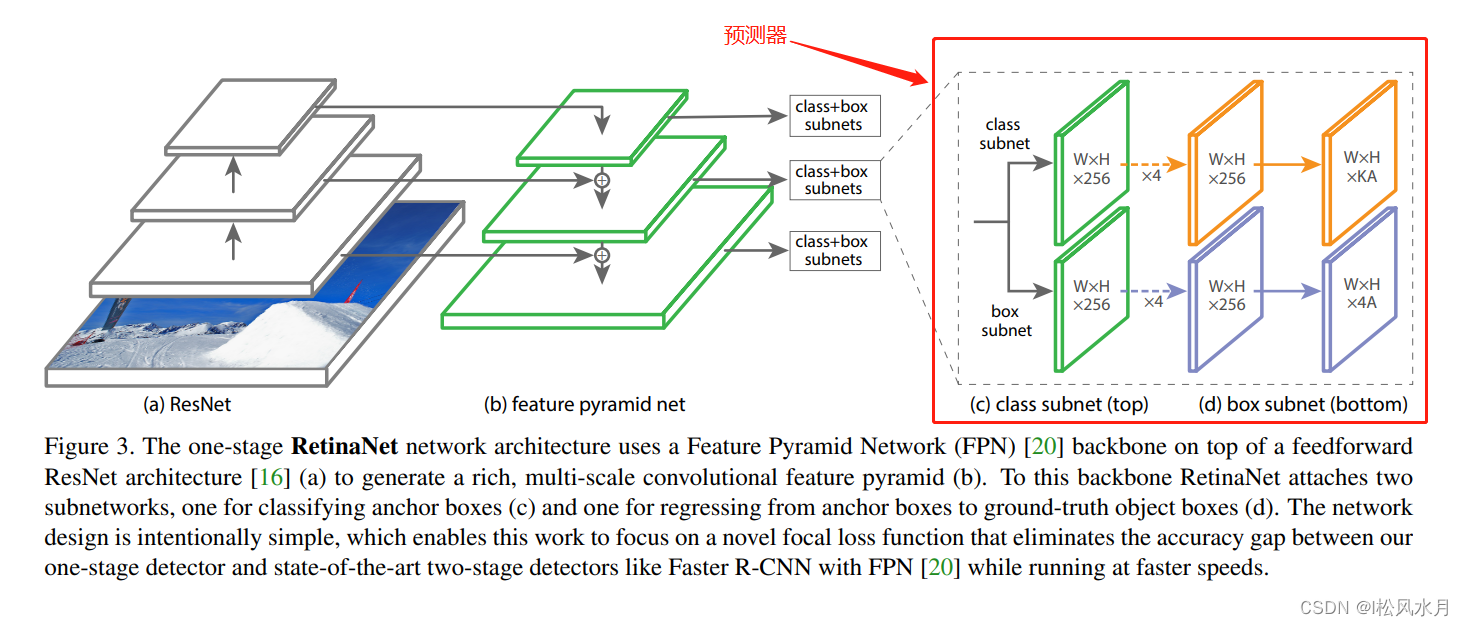
o preditor é dividido em duas ramificações, uma prevê a categoria e a outra é o parâmetro de regressão da caixa delimitadora de destino. A saída final K representa o número de categorias de alvos de detecção (excluindo o plano de fundo) e A representa anchoro número de cada camada de recurso de previsão. No FasterRCNNmeio, para a camada de previsão, cada um anchorirá gerar um conjunto de parâmetros de regressão de caixa delimitadora para cada categoria, que é ligeiramente diferente da previsão aqui, e é o mesmo aqui SSD. Agora, as amostras basicamente não estão disponíveis para esta categoria. O método de previsão conhecido pode reduzir os parâmetros de treinamento da rede.
2. Cálculo de perdas
Antes de tudo, faremos uma partida, ou seja, cálculo, para cada um dos anchornossos gt pré-marcados, iouas regras são as seguintes:
- Se iou >= 0,5 iou>=0,5eu ou você>=0,5 , marcado como uma amostra positiva
- iou < = 0,4 iou <=0,4eu ou você<=0,4 , marcado como uma amostra negativa
- iou ∈ [ 0.4 , 0.5 ) iou \in[0.4, 0.5)eu ou você∈[ 0,4 ,0,5 ) , descartar
A perda total ainda usa perda de classificação e perda de regressão, como segue:
Perda = 1 NPOS ∑ i L clsi + 1 NPOS ∑ j L regj \text { Perda } =\frac{1}{N_{POS}} \sum_i L_ { cls}^i+\frac{1}{N_{POS}} \sum_j L_{reg}^j Perda =NPDV1eu∑euc l seu+NPDV1j∑eure gj
- L cls L_{cls}euc l s: Perda Focal Sigmóide, apresentamos no último post do blog, se você não entendeu pode voltar e ver: Introdução à Perda Focal .
- L reg L_{reg}eure g:L1 Perda
- iii : todas as amostras positivas e negativas
- nenhuma palavraj : todas as amostras positivas
- N pos N_{pos}Np os: o número de amostras positivas
O texto acima é RetainNetuma introdução sobre a rede, se houver algum erro, por favor me corrija!