Código de referência: https://github.com/yhenon/pytorch-retinanet
1. Função de perda
1) Princípio
Um ponto central de contribuição deste artigo é a perda focal. A perda total ainda é dividida em duas partes, uma é a perda de classificação e a outra é a perda de regressão.
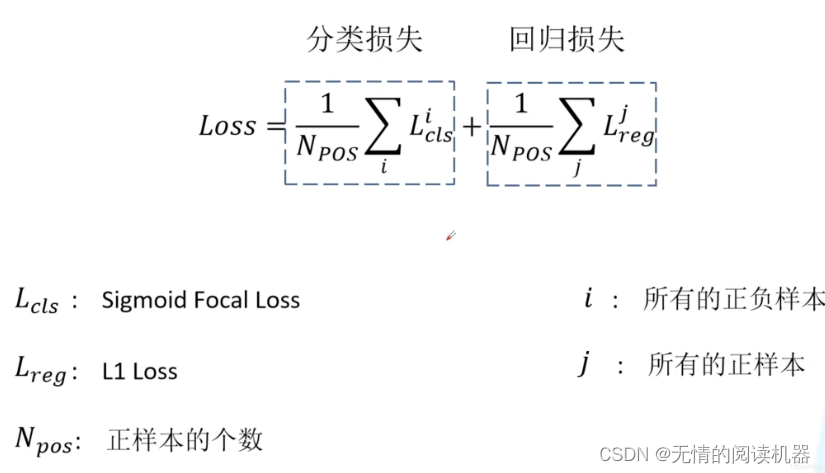
Antes de falar sobre a perda de classificação, vamos revisar a perda de entropia cruzada binária (binary_cross_entropy).

O código de cálculo é o seguinte:
import numpy as npy_true = np.array([0., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
y_pred = np.array([0.2, 0.8, 0.8, 0.8, 0.8, 0.8, 0.8, 0.8, 0.8, 0.8])my_loss = - y_true * np.log(y_pred) - (1 - y_true) * np.log(1 - y_pred)
mean_my_loss = np.mean(my_loss)
print("mean_my_loss:",mean_my_loss)![]()
Chame o cálculo da função que vem com o pytorch
import torch.nn.functional as F
import numpy as np
import torchtorch_pred = torch.tensor(y_pred)
torch_true = torch.tensor(y_true)
bce_loss = F.binary_cross_entropy(torch_pred, torch_true)
print('bce_loss:', bce_loss)

Agora, de volta à perda focal, a origem da perda focal é a entropia cruzada binária.
A perda de entropia cruzada das duas classificações também pode ser expressa da seguinte forma, onde y∈{1,-1}, 1 significa que a caixa candidata é uma amostra positiva e -1 significa que é uma amostra negativa:

Por conveniência, a seguinte fórmula pode ser definida:
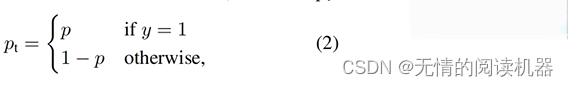
Aí vem o problema, o cenário da aplicação é o seguinte:
No modelo de detecção de objetos de um estágio, há cerca de uma dúzia a dezenas de quadros candidatos (amostras positivas) que podem corresponder ao alvo em uma imagem e, então, não há quadros candidatos correspondentes (amostras negativas) da quarta potência de 10 a cinco potências. A maioria dessas amostras negativas são amostras simples e fáceis de dividir, que não afetam as amostras de treinamento, mas submergem as amostras úteis para o treinamento.
Por exemplo, existem 50 amostras positivas, a perda é de 3 e as amostras negativas são 10.000, a perda é de 0,1
Então 50x3 = 150, 10000x0,1=1000

Portanto, para balancear a entropia cruzada, utiliza-se o coeficiente αt, quando for uma amostra positiva, αt = α, e quando for uma amostra negativa, αt=1-α, α∈[0,1]
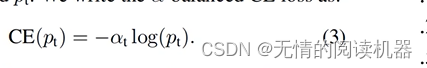
αt pode equilibrar o peso de amostras positivas e negativas, mas não pode distinguir quais são amostras difíceis e quais são amostras fáceis (se é útil para treinamento).
Portanto, continue apresentando a fórmula, que resolve o problema da facilidade de distinguir amostras:

Finalmente, as duas fórmulas são combinadas para formar a fórmula final.

A forma expandida é a seguinte
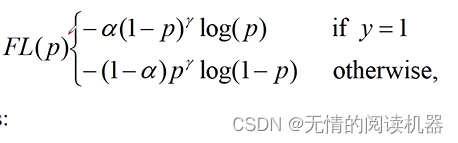
Agora vamos ver o efeito, p representa a probabilidade de prever que o quadro candidato é uma amostra positiva, y é se o quadro candidato é realmente uma amostra positiva ou uma amostra negativa, CE é a perda calculada pela entropia cruzada comum, FL é a perda focal, e a taxa é a taxa de redução. Pode-se ver que a taxa de amostras indistinguíveis nas duas últimas linhas é muito pequena.

2) Código
import numpy as np
import torch
import torch.nn as nn
class FocalLoss(nn.Module):
#def __init__(self):
def forward(self, classifications, regressions, anchors, annotations):
alpha = 0.25
gamma = 2.0
# classifications是预测结果
batch_size = classifications.shape[0]
# 分类loss
classification_losses = []
# 回归loss
regression_losses = []
# anchors的形状是 [1, 每层anchor数量之和 , 4]
anchor = anchors[0, :, :]
anchor_widths = anchor[:, 2] - anchor[:, 0] # x2-x1
anchor_heights = anchor[:, 3] - anchor[:, 1] # y2-y1
anchor_ctr_x = anchor[:, 0] + 0.5 * anchor_widths # 中心点x坐标
anchor_ctr_y = anchor[:, 1] + 0.5 * anchor_heights # 中心点y坐标
for j in range(batch_size):
# classifications的shape [batch,所有anchor的数量,分类数]
classification = classifications[j, :, :]
# classifications的shape [batch,所有anchor的数量,分类数]
regression = regressions[j, :, :]
bbox_annotation = annotations[j, :, :]
bbox_annotation = bbox_annotation[bbox_annotation[:, 4] != -1]
classification = torch.clamp(classification, 1e-4, 1.0 - 1e-4)
if bbox_annotation.shape[0] == 0:
if torch.cuda.is_available():
alpha_factor = torch.ones(classification.shape).cuda() * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
classification_losses.append(cls_loss.sum())
regression_losses.append(torch.tensor(0).float().cuda())
else:
alpha_factor = torch.ones(classification.shape) * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
classification_losses.append(cls_loss.sum())
regression_losses.append(torch.tensor(0).float())
continue
# 每个anchor 与 每个标注的真实框的iou
IoU = calc_iou(anchors[0, :, :], bbox_annotation[:, :4]) # num_anchors x num_annotations
# 每个anchor对应的最大的iou (anchor与grandtruce进行配对)
# 得到了配对的索引和对应的最大值
IoU_max, IoU_argmax = torch.max(IoU, dim=1)
#import pdb
#pdb.set_trace()
# compute the loss for classification
# classification 的shape[anchor总数,分类数]
targets = torch.ones(classification.shape) * -1
if torch.cuda.is_available():
targets = targets.cuda()
# 判断每个元素是否小于0.4 小于就返回true(anchor对应的最大iou<0.4,那就是背景)
targets[torch.lt(IoU_max, 0.4), :] = 0
# 最大iou大于0.5的anchor索引
positive_indices = torch.ge(IoU_max, 0.5)
num_positive_anchors = positive_indices.sum()
assigned_annotations = bbox_annotation[IoU_argmax, :]
targets[positive_indices, :] = 0
targets[positive_indices, assigned_annotations[positive_indices, 4].long()] = 1
if torch.cuda.is_available():
alpha_factor = torch.ones(targets.shape).cuda() * alpha
else:
alpha_factor = torch.ones(targets.shape) * alpha
alpha_factor = torch.where(torch.eq(targets, 1.), alpha_factor, 1. - alpha_factor)
focal_weight = torch.where(torch.eq(targets, 1.), 1. - classification, classification)
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(targets * torch.log(classification) + (1.0 - targets) * torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
if torch.cuda.is_available():
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape).cuda())
else:
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape))
classification_losses.append(cls_loss.sum()/torch.clamp(num_positive_anchors.float(), min=1.0))
# compute the loss for regression
if positive_indices.sum() > 0:
assigned_annotations = assigned_annotations[positive_indices, :]
anchor_widths_pi = anchor_widths[positive_indices]
anchor_heights_pi = anchor_heights[positive_indices]
anchor_ctr_x_pi = anchor_ctr_x[positive_indices]
anchor_ctr_y_pi = anchor_ctr_y[positive_indices]
gt_widths = assigned_annotations[:, 2] - assigned_annotations[:, 0]
gt_heights = assigned_annotations[:, 3] - assigned_annotations[:, 1]
gt_ctr_x = assigned_annotations[:, 0] + 0.5 * gt_widths
gt_ctr_y = assigned_annotations[:, 1] + 0.5 * gt_heights
# clip widths to 1
gt_widths = torch.clamp(gt_widths, min=1)
gt_heights = torch.clamp(gt_heights, min=1)
targets_dx = (gt_ctr_x - anchor_ctr_x_pi) / anchor_widths_pi
targets_dy = (gt_ctr_y - anchor_ctr_y_pi) / anchor_heights_pi
targets_dw = torch.log(gt_widths / anchor_widths_pi)
targets_dh = torch.log(gt_heights / anchor_heights_pi)
targets = torch.stack((targets_dx, targets_dy, targets_dw, targets_dh))
targets = targets.t()
if torch.cuda.is_available():
targets = targets/torch.Tensor([[0.1, 0.1, 0.2, 0.2]]).cuda()
else:
targets = targets/torch.Tensor([[0.1, 0.1, 0.2, 0.2]])
negative_indices = 1 + (~positive_indices)
regression_diff = torch.abs(targets - regression[positive_indices, :])
regression_loss = torch.where(
torch.le(regression_diff, 1.0 / 9.0),
0.5 * 9.0 * torch.pow(regression_diff, 2),
regression_diff - 0.5 / 9.0
)
regression_losses.append(regression_loss.mean())
else:
if torch.cuda.is_available():
regression_losses.append(torch.tensor(0).float().cuda())
else:
regression_losses.append(torch.tensor(0).float())
return torch.stack(classification_losses).mean(dim=0, keepdim=True), torch.stack(regression_losses).mean(dim=0, keepdim=True)
3) Processo de cálculo da perda de classificação
Suponha que uma imagem tenha n âncoras, m grandtrue e L categorias
1. Obtenha o IOU da âncora e cada grandtrue
# 每个anchor 与 每个标注的真实框的iou
IoU = calc_iou(anchors[0, :, :], bbox_annotation[:, :4]) # num_anchors x num_annotations
2. Obtenha o maior IOU de cada âncora e o grandtrue correspondente
IoU_max, IoU_argmax = torch.max(IoU, dim=1)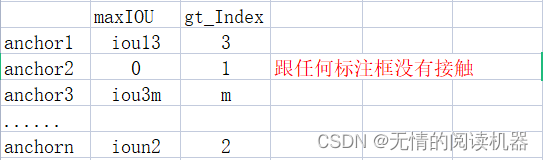
3. Inicialize uma tabela de resultados de meta de classificação, o valor padrão é -1
targets = torch.ones(classification.shape) * -1 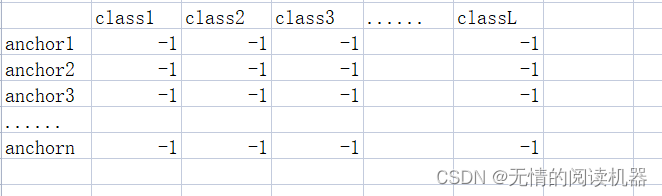
4. Se o IOU máximo de uma âncora for <0,4, então sua classificação correspondente é 0
targets[torch.lt(IoU_max, 0.4), :] = 0Exemplo: iou3m = 0,3, ioun2 = 0,2
Neste ponto, a tabela de resultados de classificação acima atualiza os resultados de classificação de âncora3 e âncora

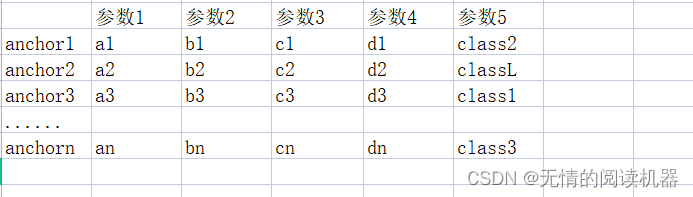
5. Associar cada âncora com as informações de grande trégua correspondentes, onde o parâmetro 5 é a categoria prevista
# 最大iou大于0.5的anchor索引
positive_indices = torch.ge(IoU_max, 0.5)
num_positive_anchors = positive_indices.sum()
assigned_annotations = bbox_annotation[IoU_argmax, :]
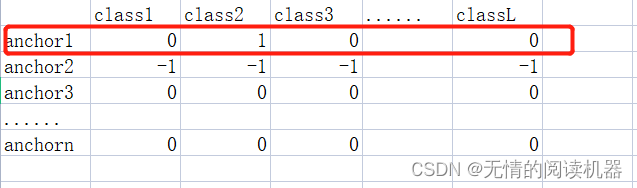
 6. Se o IOU máximo da âncora> 0,5, de acordo com o parâmetro 5, modifique a tabela de resultados de classificação correspondente para a forma one-hot
6. Se o IOU máximo da âncora> 0,5, de acordo com o parâmetro 5, modifique a tabela de resultados de classificação correspondente para a forma one-hot
targets[positive_indices, :] = 0
targets[positive_indices, assigned_annotations[positive_indices, 4].long()] = 1Por exemplo iou12 = 0,6, parâmetro 5 = class2
Modifique a tabela de resultados de classificação
7. Obtenha a parte do peso da perda
alpha_factor = torch.where(torch.eq(targets, 1.), alpha_factor, 1. - alpha_factor)
focal_weight = torch.where(torch.eq(targets, 1.), 1. - classification, classification)
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
tabela α, substitua o lugar de 0 por 1-α e o lugar de 1 por α

A tabela p substitui a probabilidade original de 0 e 1 por 1-p

Os elementos da tabela de pesos são o produto dos elementos correspondentes das duas tabelas
8. Obtenha a parte da perda da perda
bce = -(targets * torch.log(classification) + (1.0 - targets) * torch.log(1.0 - classification))
9. Obter resultados preliminares de perdas
cls_loss = focal_weight * bce10. Onde a tabela de resultados de classificação era originalmente -1, a perda correspondente torna-se 0
Por exemplo, o iou máximo de âncora2 é 0,45, entre 0,4 e 0,5, não vamos calcular a perda dele, ignore
if torch.cuda.is_available():
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape).cuda())
else:
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape))11. Resumo das perdas
classification_losses.append(cls_loss.sum()/torch.clamp(num_positive_anchors.float(), min=1.0))2. Estrutura da rede
No geral, a rede usa o modelo FPN
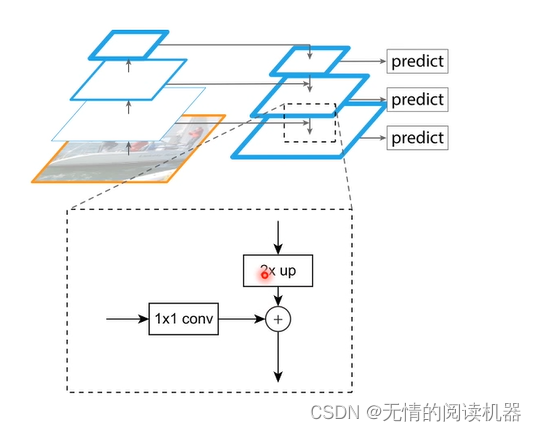
 Essa estrutura também pode ser alterada (pode ser alterada de forma flexível), conforme mostrado abaixo
Essa estrutura também pode ser alterada (pode ser alterada de forma flexível), conforme mostrado abaixo

O modelo é assim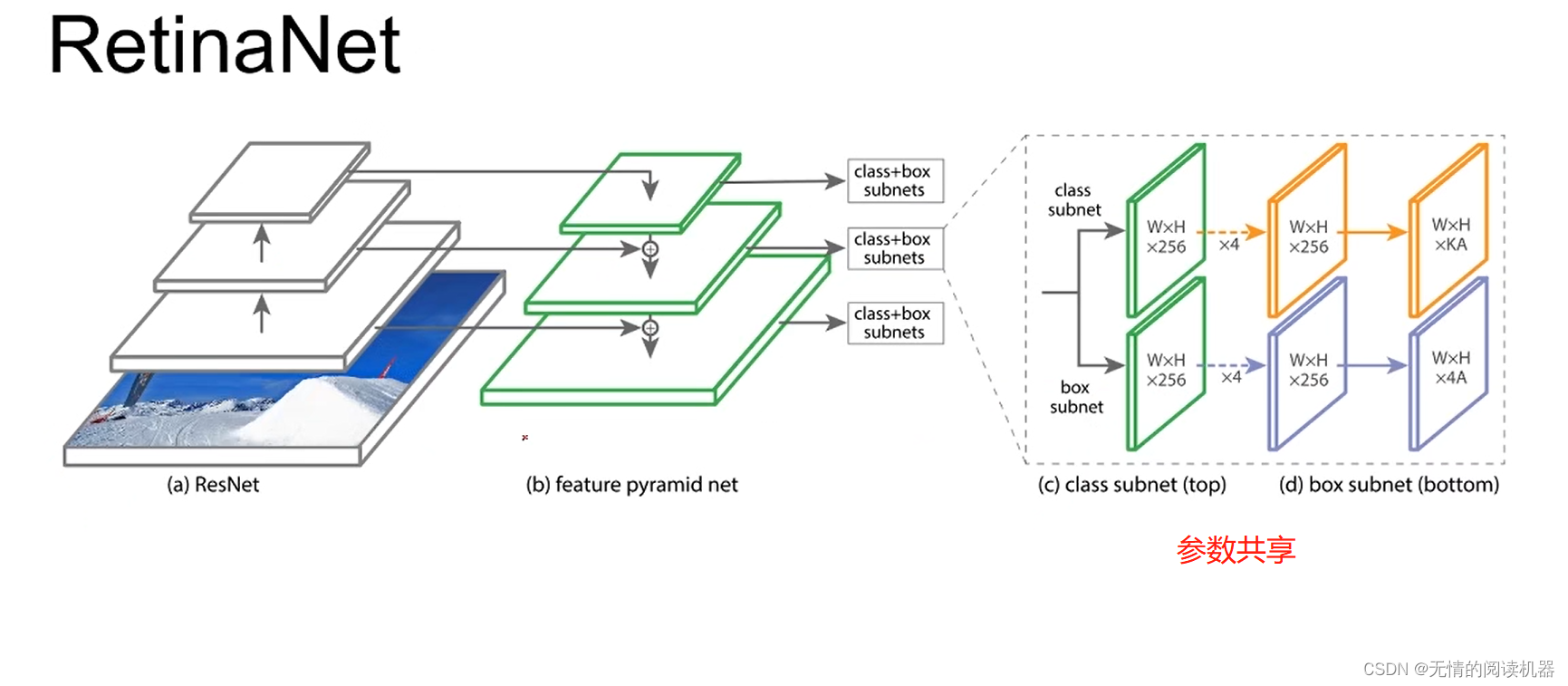
Existem 9 âncoras para cada posição, três formas x três proporções
K é o número de categorias, A é o número de cada âncora de posição
4A, 4 são quatro parâmetros que podem determinar a posição e o tamanho da âncora.
3. Explicação do código:
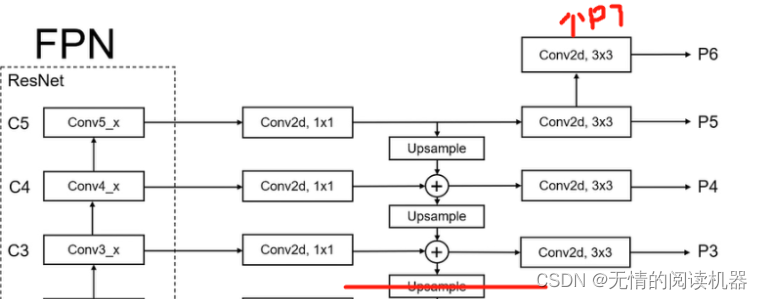
1. Parte da ramificação FPN

self.P5_1 = nn.Conv2d(C5_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P5_upsampled = nn.Upsample(scale_factor=2, mode='nearest')
self.P5_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
self.P4_1 = nn.Conv2d(C4_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P4_upsampled = nn.Upsample(scale_factor=2, mode='nearest')
self.P4_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
self.P3_1 = nn.Conv2d(C3_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P3_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1) 
self.P6 = nn.Conv2d(C5_size, feature_size, kernel_size=3, stride=2, padding=1) 
self.P7_1 = nn.ReLU()
self.P7_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=2, padding=1)avançar
def forward(self, inputs):
#inputs 是主干模块conv3、conv4、conv5的输出
C3, C4, C5 = inputs
P5_x = self.P5_1(C5)
P5_upsampled_x = self.P5_upsampled(P5_x)
P5_x = self.P5_2(P5_x)
P4_x = self.P4_1(C4)
P4_x = P5_upsampled_x + P4_x
P4_upsampled_x = self.P4_upsampled(P4_x)
P4_x = self.P4_2(P4_x)
P3_x = self.P3_1(C3)
P3_x = P3_x + P4_upsampled_x
P3_x = self.P3_2(P3_x)
P6_x = self.P6(C5)
P7_x = self.P7_1(P6_x)
P7_x = self.P7_2(P7_x)
return [P3_x, P4_x, P5_x, P6_x, P7_x]
2. Retorno da rede

class RegressionModel(nn.Module):
def __init__(self, num_features_in, num_anchors=9, feature_size=256):
super(RegressionModel, self).__init__()
#其实num_features_in就等于256
self.conv1 = nn.Conv2d(num_features_in, feature_size, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.conv2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act2 = nn.ReLU()
self.conv3 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act3 = nn.ReLU()
self.conv4 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act4 = nn.ReLU()
#4个参数就能确定anchor的大小
self.output = nn.Conv2d(feature_size, num_anchors * 4, kernel_size=3, padding=1)
def forward(self, x):
out = self.conv1(x)
out = self.act1(out)
out = self.conv2(out)
out = self.act2(out)
out = self.conv3(out)
out = self.act3(out)
out = self.conv4(out)
out = self.act4(out)
out = self.output(out)
# out is B x C x W x H, with C = 4*num_anchors
out = out.permute(0, 2, 3, 1)
#相当于展平了,-1的位置相当于所有anchor的数目
return out.contiguous().view(out.shape[0], -1, 4)3. Rede de classificação

class ClassificationModel(nn.Module):
def __init__(self, num_features_in, num_anchors=9, num_classes=80, prior=0.01, feature_size=256):
super(ClassificationModel, self).__init__()
self.num_classes = num_classes
self.num_anchors = num_anchors
self.conv1 = nn.Conv2d(num_features_in, feature_size, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.conv2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act2 = nn.ReLU()
self.conv3 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act3 = nn.ReLU()
self.conv4 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act4 = nn.ReLU()
self.output = nn.Conv2d(feature_size, num_anchors * num_classes, kernel_size=3, padding=1)
self.output_act = nn.Sigmoid()
def forward(self, x):
out = self.conv1(x)
out = self.act1(out)
out = self.conv2(out)
out = self.act2(out)
out = self.conv3(out)
out = self.act3(out)
out = self.conv4(out)
out = self.act4(out)
out = self.output(out)
out = self.output_act(out)
# out is B x C x W x H, with C = n_classes + n_anchors
out1 = out.permute(0, 2, 3, 1)
batch_size, width, height, channels = out1.shape
out2 = out1.view(batch_size, width, height, self.num_anchors, self.num_classes)
return out2.contiguous().view(x.shape[0], -1, self.num_classes)4. Rede de backbone, treinamento e processo de previsão
1. Estrutura da rede

Depois que conv1 é reduzido em 4 vezes, depois que conv2 permanece inalterado, conv3, v4 e v5 são todos reduzidos em duas vezes, p5 a p6 são reduzidos em duas vezes e p6 a p7 são reduzidos em duas vezes
p3 é reduzido à 3ª potência de 2 em relação à imagem, p4 é reduzido à 4ª potência de 2 em relação à imagem e assim por diante
class ResNet(nn.Module):
#layers是层数
def __init__(self, num_classes, block, layers):
self.inplanes = 64
super(ResNet, self).__init__()
#这个是输入 conv1
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
#这是c2
self.layer1 = self._make_layer(block, 64, layers[0])
#这是c3
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
#这是c4
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
#这是c5
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
#得到c3、c4、c5输出的通道数
if block == BasicBlock:
fpn_sizes = [self.layer2[layers[1] - 1].conv2.out_channels, self.layer3[layers[2] - 1].conv2.out_channels,
self.layer4[layers[3] - 1].conv2.out_channels]
elif block == Bottleneck:
fpn_sizes = [self.layer2[layers[1] - 1].conv3.out_channels, self.layer3[layers[2] - 1].conv3.out_channels,
self.layer4[layers[3] - 1].conv3.out_channels]
else:
raise ValueError(f"Block type {block} not understood")
#创建FPN的分支部分
self.fpn = PyramidFeatures(fpn_sizes[0], fpn_sizes[1], fpn_sizes[2])
#创建回归网络
self.regressionModel = RegressionModel(256)
#创建分类网络
self.classificationModel = ClassificationModel(256, num_classes=num_classes)
self.anchors = Anchors()
self.regressBoxes = BBoxTransform()
self.clipBoxes = ClipBoxes()
self.focalLoss = losses.FocalLoss()
#权重初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
prior = 0.01
self.classificationModel.output.weight.data.fill_(0)
self.classificationModel.output.bias.data.fill_(-math.log((1.0 - prior) / prior))
self.regressionModel.output.weight.data.fill_(0)
self.regressionModel.output.bias.data.fill_(0)
#冻结bn层参数更新,因为预训练的参数已经很好了
self.freeze_bn()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = [block(self.inplanes, planes, stride, downsample)]
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def freeze_bn(self):
'''Freeze BatchNorm layers.'''
for layer in self.modules():
if isinstance(layer, nn.BatchNorm2d):
layer.eval()2. Processo de treinamento e processo de previsão
1) Ajuste da âncora
A regressão do valor de previsão gerada [lote, o número de âncoras, 4] regressão[:, :, 0] e [:, :, 1] são usadas para mover o ponto central da âncora [:, :, 2] e [:, :, 3 ] é usado para alterar o comprimento do quadro
import torch.nn as nn
import torch
import numpy as np
# 生成的预测值 regression [batch, anchor的数量,4] regression[:, :, 0]和[:, :, 1]用来移动anchor中心点 [:, :, 2]和[:, :, 3]用来改变框子的长度
class BBoxTransform(nn.Module):
def __init__(self, mean=None, std=None):
super(BBoxTransform, self).__init__()
if mean is None:
if torch.cuda.is_available():
self.mean = torch.from_numpy(np.array([0, 0, 0, 0]).astype(np.float32)).cuda()
else:
self.mean = torch.from_numpy(np.array([0, 0, 0, 0]).astype(np.float32))
else:
self.mean = mean
if std is None:
if torch.cuda.is_available():
self.std = torch.from_numpy(np.array([0.1, 0.1, 0.2, 0.2]).astype(np.float32)).cuda()
else:
self.std = torch.from_numpy(np.array([0.1, 0.1, 0.2, 0.2]).astype(np.float32))
else:
self.std = std
def forward(self, boxes, deltas):
#boxes就是图片所有的anchor[batch , 一张图片上anchor的总数 ,4]
widths = boxes[:, :, 2] - boxes[:, :, 0] # x2 - x1 = 宽
heights = boxes[:, :, 3] - boxes[:, :, 1] # y2 - y1 = 高
ctr_x = boxes[:, :, 0] + 0.5 * widths # x1 + 宽/2 = 中心点 x
ctr_y = boxes[:, :, 1] + 0.5 * heights # y1 + 高/2 = 中心点 y
dx = deltas[:, :, 0] * self.std[0] + self.mean[0]
dy = deltas[:, :, 1] * self.std[1] + self.mean[1]
dw = deltas[:, :, 2] * self.std[2] + self.mean[2]
dh = deltas[:, :, 3] * self.std[3] + self.mean[3]
pred_ctr_x = ctr_x + dx * widths
pred_ctr_y = ctr_y + dy * heights
pred_w = torch.exp(dw) * widths
pred_h = torch.exp(dh) * heights
pred_boxes_x1 = pred_ctr_x - 0.5 * pred_w
pred_boxes_y1 = pred_ctr_y - 0.5 * pred_h
pred_boxes_x2 = pred_ctr_x + 0.5 * pred_w
pred_boxes_y2 = pred_ctr_y + 0.5 * pred_h
pred_boxes = torch.stack([pred_boxes_x1, pred_boxes_y1, pred_boxes_x2, pred_boxes_y2], dim=2)
return pred_boxes2 processo total
def forward(self, inputs):
if self.training:
img_batch, annotations = inputs
else:
img_batch = inputs
x = self.conv1(img_batch)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x1 = self.layer1(x)
x2 = self.layer2(x1)
x3 = self.layer3(x2)
x4 = self.layer4(x3)
features = self.fpn([x2, x3, x4])
#shape[batch,每次anchor总数之和,4个值]
regression = torch.cat([self.regressionModel(feature) for feature in features], dim=1)
# shape[batch,每次anchor总数之和,分类个数]
classification = torch.cat([self.classificationModel(feature) for feature in features], dim=1)
anchors = self.anchors(img_batch)
if self.training:
return self.focalLoss(classification, regression, anchors, annotations)
else:
#得到调节参数之后的框子
transformed_anchors = self.regressBoxes(anchors, regression)
#保证框子在图片之内
transformed_anchors = self.clipBoxes(transformed_anchors, img_batch)
finalResult = [[], [], []]
#每个框对应类别的置信度
finalScores = torch.Tensor([])
#框对应的分类序号:第几类
finalAnchorBoxesIndexes = torch.Tensor([]).long()
#框的坐标
finalAnchorBoxesCoordinates = torch.Tensor([])
if torch.cuda.is_available():
finalScores = finalScores.cuda()
finalAnchorBoxesIndexes = finalAnchorBoxesIndexes.cuda()
finalAnchorBoxesCoordinates = finalAnchorBoxesCoordinates.cuda()
for i in range(classification.shape[2]):
scores = torch.squeeze(classification[:, :, i])
scores_over_thresh = (scores > 0.05)
if scores_over_thresh.sum() == 0:
# no boxes to NMS, just continue
continue
scores = scores[scores_over_thresh]
anchorBoxes = torch.squeeze(transformed_anchors)
anchorBoxes = anchorBoxes[scores_over_thresh]
anchors_nms_idx = nms(anchorBoxes, scores, 0.5)
finalResult[0].extend(scores[anchors_nms_idx])
finalResult[1].extend(torch.tensor([i] * anchors_nms_idx.shape[0]))
finalResult[2].extend(anchorBoxes[anchors_nms_idx])
finalScores = torch.cat((finalScores, scores[anchors_nms_idx]))
finalAnchorBoxesIndexesValue = torch.tensor([i] * anchors_nms_idx.shape[0])
if torch.cuda.is_available():
finalAnchorBoxesIndexesValue = finalAnchorBoxesIndexesValue.cuda()
finalAnchorBoxesIndexes = torch.cat((finalAnchorBoxesIndexes, finalAnchorBoxesIndexesValue))
finalAnchorBoxesCoordinates = torch.cat((finalAnchorBoxesCoordinates, anchorBoxes[anchors_nms_idx]))
return [finalScores, finalAnchorBoxesIndexes, finalAnchorBoxesCoordinates]5. Definição de dois blocos
import torch.nn as nn
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out6. âncora
1. Gerar função de âncora para cada posição
A geração de âncoras é baseada na imagem originalA função desta função é gerar todas as âncoras em uma posição, a forma é (x1, y1, x2, y2) e (X1, y1) e (x2, y2) são simétricas em relação ao centro, portanto, dado um ponto médio, você pode pegar diretamente (x1, y1, x2, y2) calcular a âncora correspondente
Etapas funcionais aproximadas:
1. Determine o número de âncoras para cada posição: o número de proporções x o número de proporções de escala de comprimento lateral
2. Obtenha o resultado do dimensionamento do comprimento lateral padrão da âncora: base_size x scales
3. Obtenha a área padrão através dos resultados acima: o quadrado de (base_size x escalas)
2. Obtenha largura e altura por h = sqrt(áreas / ratio) e w = h * ratio
3. Obtenha as duas coordenadas (0-h/2 , 0-w/2) e (h/2 , w/2) de cada âncora
4. Âncora de saída
def generate_anchors(base_size=16, ratios=None, scales=None):
"""
Generate anchor (reference) windows by enumerating aspect ratios X
scales w.r.t. a reference window.
"""
if ratios is None:
ratios = np.array([0.5, 1, 2])
if scales is None:
scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])
#每个位置的anchor总数 n种规模 * m种比例
num_anchors = len(ratios) * len(scales)
# 初始化anchor的参数 x,y,w,h
anchors = np.zeros((num_anchors, 4))
# scale base_size
#np.tile(scales, (2, len(ratios))).T结果如下:
#[[1. 1. ]
# [1.25992105 1.25992105]
# [1.58740105 1.58740105]
# [1. 1. ]
# [1.25992105 1.25992105]
# [1.58740105 1.58740105]
# [1. 1. ]
# [1.25992105 1.25992105]
# [1.58740105 1.58740105]]
# shape (9, 2)
#设置anchor的w、h的基础大小(1:1)
anchors[:, 2:] = base_size * np.tile(scales, (2, len(ratios))).T
# 计算anchor的基础面积
#[area1,area2,area3,area1,area2,area3,area1,area2,area3]
areas = anchors[:, 2] * anchors[:, 3]
# correct for ratios
#利用面积和宽高比得到真正的宽和高
#根据公式1: areas / (w/h) = areas / ratio = hxh => h = sqrt(areas / ratio)
# 公式2:w = h * ratio
#np.repeat(ratios, len(scales))) = [0.5,0.5,0.5 ,1,1,1,2,2,2]
# 最终的效果就是 面积1的高宽,面积2的高宽,面积3的高宽
anchors[:, 2] = np.sqrt(areas / np.repeat(ratios, len(scales)))
anchors[:, 3] = anchors[:, 2] * np.repeat(ratios, len(scales))
# 转换anchor的形式 (x_ctr, y_ctr, w, h) -> (x1, y1, x2, y2)
# 左上角为中心点,形成9个anchor
anchors[:, 0::2] -= np.tile(anchors[:, 2] * 0.5, (2, 1)).T
anchors[:, 1::2] -= np.tile(anchors[:, 3] * 0.5, (2, 1)).T
return anchorsOs passos e efeitos da demonstração são os seguintes:
pyramid_levels = [3, 4, 5, 6, 7]
strides = [2 ** x for x in pyramid_levels]
sizes = [2 ** (x + 2) for x in pyramid_levels]
ratios = np.array([0.5, 1, 2])
scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])num_anchors = len(ratios) * len(scales)
anchors = np.zeros((num_anchors, 4))anchors[:, 2:] = 16 * np.tile(scales, (2, len(ratios))).T
print("anchor的w、h的基础大小(1:1): ")
print(anchors[:, 2:])
areas = anchors[:, 2] * anchors[:, 3]
print("基础面积:" )
print(areas)
anchors[:, 2] = np.sqrt(areas / np.repeat(ratios, len(scales)))
anchors[:, 3] = anchors[:, 2] * np.repeat(ratios, len(scales))
print("宽度:")
print(anchors[:, 2])
print("高度:")
print(anchors[:, 3])
anchors[:, 0::2] -= np.tile(anchors[:, 2] * 0.5, (2, 1)).T
anchors[:, 1::2] -= np.tile(anchors[:, 3] * 0.5, (2, 1)).T
print("一个位置生成的anchor如下")
print("个数为:",anchors.shape[0] )
print(anchors)
2. Gere âncora para cada posição
A ideia básica ainda é: a geração da âncora é baseada na imagem original
Para realizar a ideia acima, o mais importante é obter a proporção de escala (tamanho do passo) entre o mapa de recursos e a imagem original, como stride=8, então se o tamanho da imagem original for (image_w, image_h) então o mapa de recursos será reduzido em relação ao tamanho da imagem original É (image_w/8, image_h/8) (o resultado do cálculo é aumentado)
Em seguida, a posição de cada âncora é determinada pelo mapa de características
x1∈( 0,1,2,3......image_w/8) y1∈( 0,1,2,3......image_h/8)
A posição onde a âncora é gerada é c_x1 = x1+0,5, c_y1 = y1+0,5
Como a geração da âncora é baseada na imagem original, a posição da âncora no mapa de recursos deve ser ampliada para a imagem original, ou seja, a posição da âncora gerada na imagem original é c_x = c_x1 * passo, c_y = c_y1 * passo
def shift(shape, stride, anchors):
shift_x = (np.arange(0, shape[1]) + 0.5) * stride
shift_y = (np.arange(0, shape[0]) + 0.5) * stride
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
shifts = np.vstack((
shift_x.ravel(), shift_y.ravel(),
shift_x.ravel(), shift_y.ravel()
)).transpose()
# add A anchors (1, A, 4) to
# cell K shifts (K, 1, 4) to get
# shift anchors (K, A, 4)
# reshape to (K*A, 4) shifted anchors
A = anchors.shape[0]
K = shifts.shape[0]
all_anchors = (anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2)))
all_anchors = all_anchors.reshape((K * A, 4))
return all_anchorsNo nível do código (anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2)))
Mecanismo de transmissão usando adição vetorial
A dimensão do vetor a1 é (k, 1, 4), o que significa que existem K posições, cada posição tem 1 dado e cada dado tem 4 parâmetros (ponto central)
A dimensão do vetor a2 é (1, A, 4), o que significa 1 posição, cada posição A dados, cada dados 4 parâmetros (coordenadas de posição da âncora em relação ao ponto central)
Onde k é para gerar âncoras em k posições da imagem e A é para gerar várias âncoras para cada posição
Primeiro, a2 precisa copiar o vetor (A,4) k vezes na 0ª dimensão (para cada posição)
Então a1 é copiado A vezes (4) para baixo na primeira dimensão (para cada cópia âncora em cada posição)
3. O processo de geração de âncoras de imagem
A forma de saída final é [1, a soma do número de âncoras em cada camada, 4]
class Anchors(nn.Module):
def __init__(self, pyramid_levels=None, strides=None, sizes=None, ratios=None, scales=None):
super(Anchors, self).__init__()
#提取的特征
if pyramid_levels is None:
self.pyramid_levels = [3, 4, 5, 6, 7]
#步长,在每层中,一个像素等于原始图像中几个像素
if strides is None:
self.strides = [2 ** x for x in self.pyramid_levels] #这个参数设置我没看懂
#每层框子的基本边长
if sizes is None:
self.sizes = [2 ** (x + 2) for x in self.pyramid_levels] #这个参数设置我也没看懂
#长宽比例
if ratios is None:
self.ratios = np.array([0.5, 1, 2])
#边长缩放比例
if scales is None:
self.scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])
def forward(self, image):
#image是原图 shape为 batch,channel,w,h
#这一步是获得宽和高
image_shape = image.shape[2:]
image_shape = np.array(image_shape)
#‘//’是向下取整 整个式子相当于向上取整,因为不满1步的也要算1步
#图像大小除以步长
#在对应的每一层中,原图在该层对应的大小
image_shapes = [(image_shape + 2 ** x - 1) // (2 ** x) for x in self.pyramid_levels]
# 创建x1,y1 x2,y2 anchor的位置坐标
all_anchors = np.zeros((0, 4)).astype(np.float32)
for idx, p in enumerate(self.pyramid_levels):
#传入该层anchor的基本边长,生成对应大小的anchor
anchors = generate_anchors(base_size=self.sizes[idx], ratios=self.ratios, scales=self.scales)
# 传入生成的anchor,和该层相对于原图的大小
shifted_anchors = shift(image_shapes[idx], self.strides[idx], anchors)
# 循环遍历完成之后,all_anchors的shape为 [每层anchor数量之和, 4]
all_anchors = np.append(all_anchors, shifted_anchors, axis=0)
# 最后输出的形状是 [1, 每层anchor数量之和 , 4]
all_anchors = np.expand_dims(all_anchors, axis=0)
if torch.cuda.is_available():
return torch.from_numpy(all_anchors.astype(np.float32)).cuda()
else:
return torch.from_numpy(all_anchors.astype(np.float32))7. conjunto de dados
Tome csvdataset como exemplo

