O vídeo original é o ensino da estação B de Zuo Chengyun
Diretório de artigos
- 1 tipo de bolha O (N 2) O(N^2)O ( N2 )(independentemente do status dos dados)
- 2 tipo de seleção O ( N 2 ) O(N^2)O ( N2 )(independentemente do status dos dados)
- 3 Ordenação por inserção O ( N 2 ) O(N^2)O ( N2 )(em relação ao status dos dados)
- 4 Classificação de mesclagem O ( N log N ) O(NlogN)O ( Nl o g N ) (o status dos dados não importa)
- 5 Classificação rápida
Para todas as seguintes funções swap(), a função é definida como
void swap(int& a, int& b)
{
int t = a;
a = b;
b = t;
}
// 也可以用异或,但不能传入同一个变量,可以是不同变量相同值
void swap(int& a, int& b)
{
a = a ^ b;
b = a ^ b;
a = a ^ b;
}
1 tipo de bolha O (N 2) O(N^2)O ( N2 )(independentemente do status dos dados)
A classificação mais básica e simples, nada a dizer
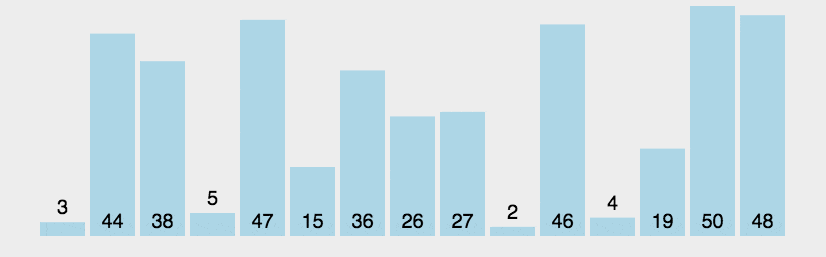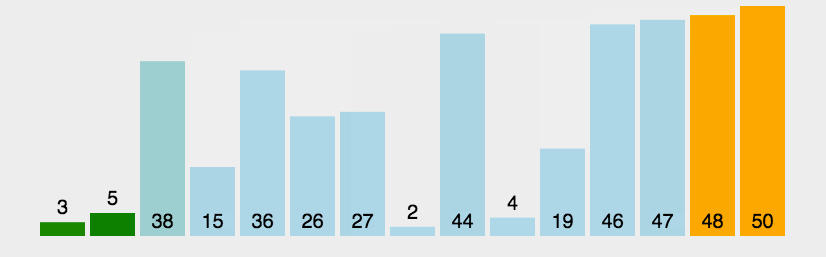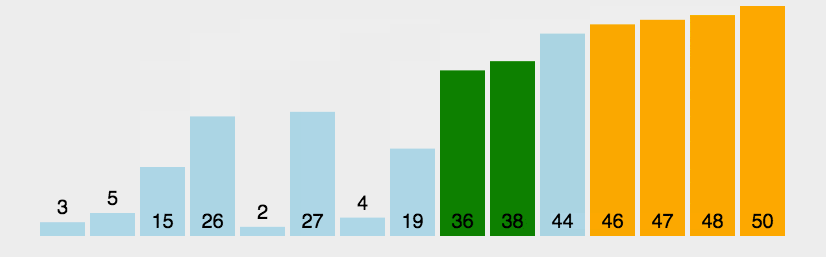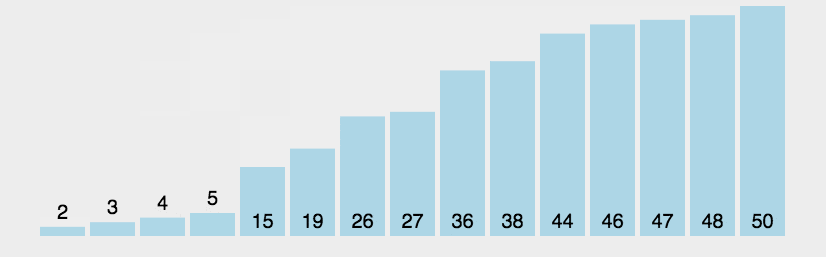
#incldue <vector>
void bubbleSort(std::vector<int>& arr)
{
for (int i = 0; i < arr.size() - 1; i++) {
for (int j = 0; j < arr.size() - 1 - i; j++) {
if (arr[j] > arr[j+1]) {
// 相邻元素两两对比
swap(arr[j], arr[j+1]);
}
}
}
}
2 tipo de seleção O ( N 2 ) O(N^2)O ( N2 )(independentemente do status dos dados)
A ideia básica é selecionar o menor (ou maior) elemento dos elementos a serem classificados a cada vez e colocá-lo no final da sequência classificada. As principais etapas da ordenação por seleção são as seguintes:
- 1. Percorra a sequência a ser classificada e defina a posição atual como a posição do valor mínimo.
- 2. Partindo da posição atual, compare o elemento atual com os seguintes elementos sucessivamente, encontre o menor elemento e registre sua posição.
- 3. Troque o menor elemento pelo elemento na posição atual.
- 4. Repita os passos 2 e 3 até percorrer toda a sequência.
#include<vector>
void selectionSort(std::vector<int>& arr)
{
int len = arr.size();
if (arr.empty() || len < 2) return;
for (int i = 0; i < len -1; i++){
// len -1 位置不用再循环了,因为最后剩一个必然是最值
int minIndex = i; // 在i ~ len-1 上寻找最小值的下标
for (int j = i; j < len - 1; j++){
minIndex = arr[j] < arr[minIndex] ? j : minIndex;
}
swap(arr[minIndex], arr[i]);
}
}
3 Ordenação por inserção O ( N 2 ) O(N^2)O ( N2 )(em relação ao status dos dados)
O princípio é semelhante ao processo de classificação das mãos de pôquer. Insira os elementos não classificados um a um na parte classificada na posição apropriada.
A ordem lógica é primeiro fazer 0~0 ordenado, então 0~1 ordenado, 0~2 ... 0~n-1 ordenado
O fluxo do algoritmo é:
- 1. A partir do primeiro elemento, o elemento pode ser considerado classificado.
- 2. Pegue o primeiro valor da parte não classificada e insira-o na posição apropriada na parte classificada . O método de seleção desta posição é: compare o valor não classificado atual com o valor vizinho esquerdo e troque a posição se for menor . Ele terminará até encontrar o limite ou não ser menor que o valor do vizinho esquerdo. (Loop interno: encontre uma posição apropriada para inserir)
- 3. Repita a etapa 2 até que todos os elementos sejam inseridos na sequência classificada. (loop externo: percorra cada número não classificado)
Ao contrário da classificação por bolha e classificação por seleção, esta é uma operação fixa (o status dos dados é irrelevante). Na classificação por inserção, se a ordem for dada, o loop externo será concluído todas as vezes, portanto será O(N) , mas dizemos que a complexidade de tempo é o pior caso, portanto ainda é O ( N 2 ) O (N^2)O ( N2 )
#include <vector>
void insertionSort(std::vector<int>& arr)
{
int len = arr.size();
if (arr.empty() || len < 2) return;
// 0~0已经有序了
for (int i = 1; i < len; i++){
// 0~i做到有序
// 把当前值(j+1)对比左邻值(j),比他小则交换,不满足循环条件则说明找到合适位置了
for (int j = i - 1; j >= 0 && arr[j] > arr[j + 1]; j--){
swap(arr[j+1], arr[j]);
}
}
}
No loop interno, comparamos o elemento atual arr[j + 1] com seu elemento vizinho esquerdo arr[j] e transpomos se for menor até que uma posição de inserção adequada seja encontrada.
A condição para o fim do loop (encontrar uma posição adequada) é: o limite esquerdo é alcançado ou o valor atual é maior que o valor do vizinho esquerdo
Continue a olhar para baixo, é recomendável dominar a pesquisa binária e a recursão básica primeiro
4 Classificação de mesclagem O ( N log N ) O(NlogN)O ( Nl o g N ) (o status dos dados não importa)
Sua ideia central é dividir a sequência a ser classificada em subsequências menores até que cada subsequência tenha apenas um elemento e, em seguida, mesclar essas subsequências em pares até que toda a sequência seja finalmente classificada.
A seguir estão as etapas gerais do merge sort:
- Segmentação : divida a sequência a ser classificada em duas subsequências a partir da posição intermediária e continue a dividir recursivamente cada subsequência até que haja apenas um elemento restante em cada subsequência.
- Mesclar : mescla duas subsequências classificadas em uma sequência classificada. Inicie a comparação a partir dos primeiros elementos das duas subsequências, coloque os elementos menores na matriz temporária e mova o índice da subsequência correspondente um bit para trás, até que todos os elementos de uma das subsequências sejam colocados na matriz temporária. Em seguida, coloque os elementos restantes da outra subsequência diretamente na matriz temporária.
- Mesclagem repetida : A operação de mesclagem é repetida até que todas as subsequências sejam mescladas em uma sequência ordenada.
Sempre complexidade de tempo O(NlogN) , independente dos dados. Embora seja mais rápido do que a ordenação anterior por bolhas, seleção e inserção, a complexidade do espaço é O(N)
A figura a seguir descreve esse processo com muita precisão.
#include <vector>
// 第二阶段:merge阶段时,L~M 和 M~R 之间的数必然有序
void merge(std::vector<int>& arr, int L, int M, int R)
{
std::vector help(R - L + 1);
int i = 0; // 临时数组的起始索引
int p1 = L; // 左半部分的起始索引
int p2 = M + 1; // 右半部分的起始索引
//外排序,把两个子数组中的元素从小到大放到help数组
while (p1 <= M && p2 <= R){
help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];
}
// 如果左边部分还有剩的,全部依次加到help的末尾
while (p1 <= M){
help[i++] = arr[p1++];
}
// 同理如果右边还有剩的
while (p2 <= R){
help[i++] = arr[p2++];
}
// 结束,把临时数组的内容覆盖到原数组中
for (i = 0; i < R - L + 1; i++){
arr[L + i] = help[i]; // 注意arr从L位置开始写入的
}
}
// 务必先看这个函数 这算是第一阶段拆分
void mergeSort(std::vector<int>& arr, int L, int R)
{
if (L == R) return; // 拆分完毕,不能再拆了
int mid = L + ((R - L) >> 1);
mergeSort(arr, L, mid);
mergeSort(arr, mid+1, R);
merge(arr, L, mid, R); // 执行到这一步的条件是 L == mid 且 mid+1 == R 即左右子树都已二分到只有一个元素
}
Complexidade de tempo (consulte a fórmula mestre 2.1 )
- T ( N ) = 2 ⋅ T ( N 2 ) + O ( N ) T(N) = 2·T(\frac{N}{2})+O(N)T ( N )=2 ⋅T (2n)+O ( N )
- a = 2; b = 2; d = 1
- logab = 1 = d log_ab=1=dl o gumb=1=d , então a complexidade de tempo éO ( N ⋅ log N ) O(N·logN)O ( N ⋅log N ) _ _
Complexidade do Espaço: O (N) O(N)O ( N ) . Porque toda vez que uma mesclagem é aberta um espaço, o tamanho é N
4.1 Extensão do Merge Sort (Encontre a Pequena Soma de Arrays)
Tópico: Em uma matriz, a soma dos números à esquerda de cada número menor que o número atual é chamada de pequena soma da matriz. Encontre a soma mínima de uma matriz.
Exemplo: [1,3,4,2,5]
O número à esquerda de 1 é menor que 1, nenhum; o
número à esquerda de 3 é menor que 3, 1; o número
à esquerda de 4 é menor que 4, 1, 3;
o número à esquerda de 2 é menor que 2 O número, 1;
o número à esquerda de 5 é menor que 5, 1, 3, 4, 2;
então a pequena soma é 1+1 +3+1+1+3+4+2=16
exigindo complexidade de tempo O(NlogN) , complexidade de espaço O(N)
Se os elementos em cada posição passarem por todos os elementos à esquerda, encontre o número menor que ele e some-os, o resultado pode ser facilmente obtido e a complexidade de tempo é O ( N 2 ) O (N ^ 2 )O ( N2 )_
Mude o pensamento: em vez de descobrir quantos números no lado esquerdo são menores que o número na posição atual e, em seguida, somar, mas contar quantos números são maiores que o número na posição atual, quantas vezes o número atual deve ser acumulado, e este processo está em Pode ser feito no tipo externo de classificação por mesclagem
Explicação detalhada do vídeo e preciso no ar , muito melhor que ler texto
#include <iostream>
#include <vector>
long long mergeAndCount(std::vector<int>& arr, int left, int mid, int right)
{
std::vector<int> temp(right - left + 1); // 临时数组用于存储合并后的结果
int i = 0; // 临时数组的起始索引
int p1 = left; // 左半部分的起始索引
int p2 = mid + 1; // 右半部分的起始索引
long long count = 0; // 记录小和的累加和
while (p1 <= mid && p2 <= right) {
if (arr[p1] <= arr[p2]) {
// 重点:如果arr[p1]比arr[p2]小,则arr[p1]比p2后面所有数都小!
count += arr[p1] * (right - p2 + 1);
temp[i++] = arr[p1++];
} else {
temp[i++] = arr[p2++];
}
}
while (p1 <= mid) temp[i++] = arr[p1++];
while (p2 <= right) temp[i++] = arr[p2++];
// 将临时数组的结果复制回原数组
for (i = 0; i < R - L + 1; i++) {
arr[left + i] = temp[i];
}
return count;
}
long long mergeSortAndCount(std::vector<int>& arr, int left, int right)
{
if (left >= right) {
return 0; // 单个元素无小和
}
int mid = left + (right - left) / 2;
long long leftCount = mergeSortAndCount(arr, left, mid); // 左半部分的小和
long long rightCount = mergeSortAndCount(arr, mid + 1, right); // 右半部分的小和
long long mergeCount = mergeAndCount(arr, left, mid, right); // 合并过程中的小和
return leftCount + rightCount + mergeCount; // 总的小和
}
long long calculateSmallSum(std::vector<int>& arr)
{
if (arr.empty()) return 0; // 空数组无小和
int left = 0;
int right = arr.size() - 1;
return mergeSortAndCount(arr, left, right);
}
int main()
{
std::vector<int> arr = {
3, 1, 4, 2, 5};
long long smallSum = calculateSmallSum(arr);
std::cout << "Small Sum: " << smallSum << std::endl;
std::cin.get();
return 0;
}
5 Classificação rápida
Quicksort 3.0 (veja em outro lugar para 1.0 e 2.0)