
Autor: Huan Xiang
O Grupo Manbang, como uma empresa de plataforma "Internet + Logística", atende às necessidades de transporte dos transportadores em uma extremidade e se conecta com os motoristas de caminhão na outra extremidade para melhorar a eficiência da logística de frete. Ela será listada na bolsa de valores dos EUA em 2021, tornando-se a primeira plataforma digital de frete a ser listada. De acordo com o relatório anual da empresa, em 2021, mais de 3,5 milhões de caminhoneiros completaram mais de 128,3 milhões de pedidos na plataforma, alcançando um valor total de transação de GTV 262,3 bilhões de yuans, representando mais de 60% da participação da plataforma digital de frete da China. Em outubro de 2022, o MAU da versão do driver do Yunmanman atingiu 9,4921 milhões, e o MAU da versão do driver do Wagonmanman foi de 3,9991 milhões, o MAU da versão do proprietário do Yunmanman foi de 2,1868 milhões, e o MAU da versão do proprietário da carga Wagonbang; foi de 637.800. (O conteúdo a seguir foi compilado e produzido por Zikui e Congyan)
O crescimento dos negócios desafia a estabilidade dos serviços
O Grupo Manbang construiu seu próprio gateway de microsserviços no ambiente de produção empresarial, que é responsável pelo agendamento do tráfego norte-sul, proteção de segurança e governança de microsserviços. Ao mesmo tempo, levando em consideração a capacidade multiativa de recuperação de desastres, também fornece serviços desse tipo. como chamadas prioritárias na mesma sala de computadores, chamadas entre salas de computadores para recuperação de desastres, etc. Como componente front-end da arquitetura de microsserviços, o gateway de microsserviços serve como entrada de tráfego para todos os microsserviços. Quando uma solicitação do cliente chega, ela primeiro atinge o ALB (balanceamento de carga), depois vai para o gateway interno e, em seguida, é roteada para o módulo de serviço de negócios específico por meio do gateway.
Portanto, o gateway precisa usar um centro de registro de serviço para descobrir dinamicamente todas as instâncias de microsserviços implantadas no ambiente de produção atual. Quando algumas instâncias de serviço não conseguem fornecer serviços devido a falhas, o gateway também pode trabalhar com o centro de registro de serviço para encaminhar automaticamente. solicitações para instâncias de serviço, failover e elasticidade são alcançados, e uma estrutura autodesenvolvida é usada para cooperar com o centro de registro de serviço para realizar chamadas entre serviços. Ao mesmo tempo, um centro de configuração autoconstruído é usado. para implementar o gerenciamento de configuração e o impulso de mudança. O Grupo Manbang foi o primeiro a adotar Eureka e ZooKeeper de código aberto para construir o centro de registro de serviço de cluster e centro de configuração, esta estrutura também empreendeu bem o rápido crescimento dos negócios do Grupo Manbang no estágio inicial.
No entanto, à medida que o volume de negócios aumenta gradualmente, há cada vez mais módulos de negócios e o número de instâncias de registro de serviço cresce explosivamente . Os problemas de estabilidade do cluster do centro de registro de serviços Eureka e do cluster ZooKeeper autoconstruídos nesta arquitetura tornaram-se cada vez mais óbvios. .
Durante a operação e manutenção, os alunos do Grupo Manbang descobriram que quando o número de instâncias de registro de serviço no cluster Eureka autoconstruído atingiu mais de 2.000, devido à sincronização das informações de registro de instância entre os nós do cluster Eureka, alguns nós não conseguiram lidar com isso, o que foi muito fácil. Surgem problemas onde os nós falham em fornecer serviços e eventualmente causam falhas frequentes no cluster ZooKeeper, causando instabilidade nas chamadas entre serviços e nas liberações de configuração, afetando a estabilidade geral. capacidades habilitadas por padrão, o armazenamento de configuração enfrenta desafios de segurança, esses problemas também trazem grandes desafios para o desenvolvimento estável e duradouro do negócio.
Migração tranquila da arquitetura de negócios
Com o histórico de negócios acima, os alunos de Manbang optaram por migrar para a nuvem com urgência, usando os produtos Alibaba Cloud MSE Nacos e MSE ZooKeeper para substituir os clusters originais Eureka e Zookeeper. No entanto, como podemos também obter atualizações de arquitetura rápidas e de baixo custo. como o negócio durante a migração para a nuvem E quanto à migração de tráfego sem perdas e sem problemas?
Nesta questão, o MSE Nacos alcançou total compatibilidade com o protocolo nativo Eureka de código aberto. O kernel ainda é conduzido pelo Nacos. A camada de adaptação de negócios mapeia o modelo de dados Eureka InstanceInfo e o modelo de dados Nacos (Serviço e Instância). Tudo isso é completamente transparente para as partes empresariais de que o Grupo Manbang assumiu o controle do cluster Eureka autoconstruído.
Isso significa que o lado comercial original não precisa ser alterado no nível do código. Você só precisa modificar a configuração do Endpoint da instância do servidor conectada pelo Cliente Eureka ao Endpoint do MSE Nacos. Também é muito flexível em uso. Você pode continuar a usar o protocolo Eureka nativo para usar a instância MSE Nacos como um cluster Eureka ou pode usar protocolos duplos de cliente Nacos e Eureka para coexistir. As informações de registro de serviço de diferentes protocolos oferecem suporte mútuo. conversão, garantindo assim a conectividade das chamadas de microsserviços empresariais.
Além disso, durante o processo de migração para a nuvem, a MSE forneceu oficialmente a solução MSE-Sync, que é uma ferramenta de migração otimizada que suporta sincronização de dados baseada no Nacos-Sync de código aberto. Suporta sincronização bidirecional, serviços pull automáticos e um clique. funções de sincronização. Por meio do MSE-Sync, os alunos do Manbang podem migrar facilmente os dados de estoque de registro de serviço on-line existentes no cluster Eureka original construído por eles mesmos para o novo cluster MSE Nacos com um clique. Ao mesmo tempo, os dados incrementais recém-registrados no cluster antigo podem. também será migrado com um clique. Ele será sincronizado de forma contínua e automática com o novo cluster, garantindo assim que as informações da instância de registro do serviço de cluster em ambos os lados sejam sempre completamente consistentes antes da migração real do fluxo de negócios. Depois que a verificação de sincronização de dados for aprovada, substitua a configuração original do Eureka Client Endpoint, publique e atualize novamente e migre com êxito para o novo cluster MSE Nacos.
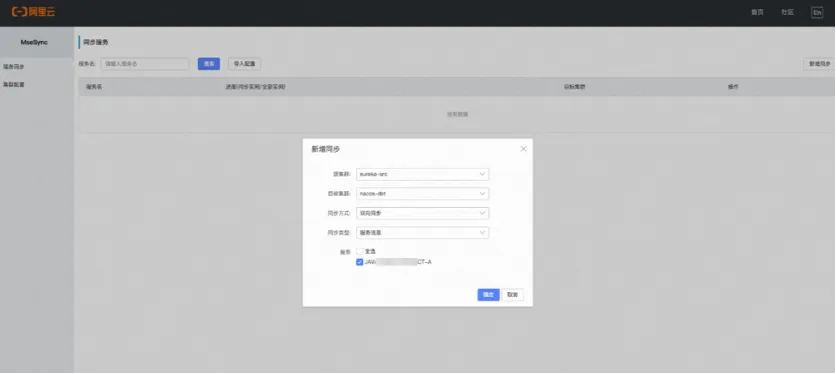
Rompendo o gargalo de desempenho da arquitetura de cluster nativa Eureka
Quando o Grupo Manbang encontrou a atualização da arquitetura técnica de cooperação da equipe MSE, a solicitação mais importante era resolver o problema original de alta pressão para sincronizar as informações de registro de serviço entre os clusters Eureka . para o modelo de sincronização AP, as funções de cada nó do servidor são iguais e completamente equivalentes. Para cada alteração (registro/cancelamento de registro/renovação de pulsação/mudança de status de serviço, etc.), uma tarefa de sincronização correspondente será gerada para sincronização de todos os dados da instância. Dessa forma, a quantidade de jobs de sincronização aumenta em correlação direta com o tamanho do cluster e o número de instâncias.
Através da prática, os alunos do Grupo Manbang descobriram que quando a escala de registro do serviço de cluster atingia mais de 2.000, eles descobriram que a taxa de ocupação da CPU e a carga de alguns nós eram muito altas e, às vezes, eles fingiam morrer de vez em quando, causando nervosismo nos negócios. Isso também é mencionado na documentação oficial do Eureka. O modelo de replicação de transmissão do Eureka de código aberto não apenas causa sua própria vulnerabilidade arquitetônica, mas também afeta a escalabilidade horizontal geral do cluster.
O algoritmo de replicação limita a escalabilidade: Eureka segue um modelo de replicação de transmissão, ou seja, todos os servidores replicam dados e pulsações para todos os pares. Isso é simples e eficaz para o conjunto de dados que o eureka contém, no entanto, a replicação é implementada retransmitindo todas as chamadas HTTP que um servidor recebe como estão para todos os pares. Isso limita a escalabilidade, pois cada nó precisa suportar toda a carga de gravação no eureka.
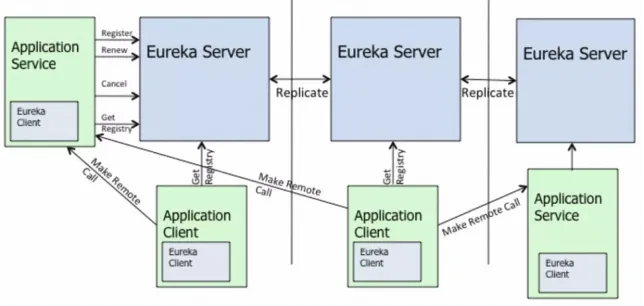
MSE Nacos levou esse problema em consideração na seleção da arquitetura e forneceu uma solução melhor, que é o protocolo Distro do modelo AP autodesenvolvido. Com base na manutenção do modelo de sincronização em estrela, o Nacos registra dados de instância para todos os serviços. a fragmentação é executada e um nó de responsabilidade do cluster é atribuído aos dados de cada instância de serviço. Cada nó do servidor é responsável apenas pela lógica de sincronização e renovação de sua própria parte dos dados. relativamente O Eureka também é menor. A vantagem disso é que mesmo em implantações em larga escala e grandes dados de instâncias de serviço, a quantidade de tarefas de sincronização entre clusters pode ser relativamente controlável e quanto maior o tamanho do cluster, maior será a melhoria de desempenho trazida por esse modelo.
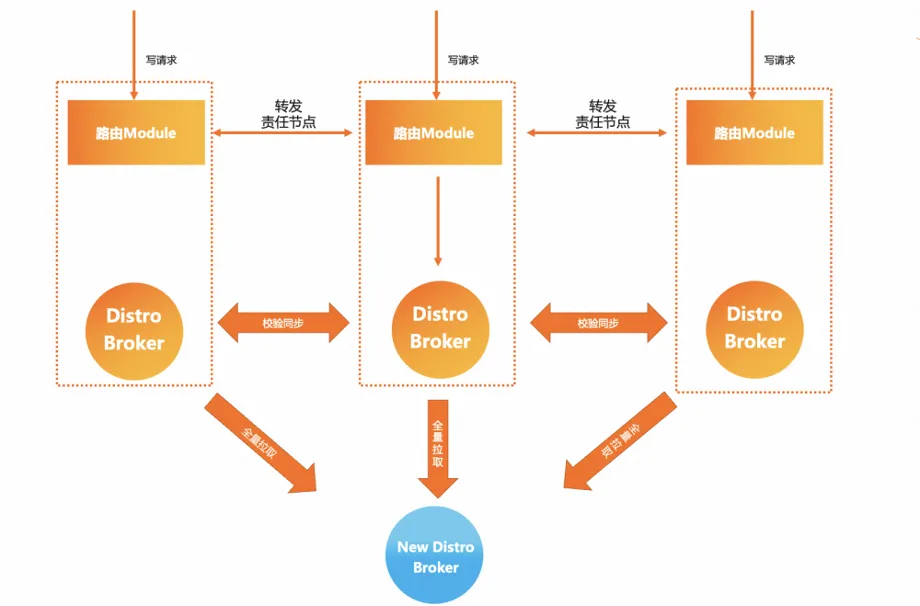
A otimização iterativa contínua busca o melhor desempenho
Depois que MSE Nacos e MSE ZooKeeper concluíram o negócio completo do centro de registro de microsserviços do Grupo Manbang, eles continuaram a otimizar iterativamente nas versões atualizadas subsequentes e continuaram a otimizar o desempenho do servidor em todos os detalhes por meio de um grande número de testes de comparação de testes de estresse de desempenho para otimizar o. experiência empresarial, os pontos de otimização da versão atualizada serão analisados e introduzidos um por um.
Registro de serviço, proteção de recuperação de desastres de alta disponibilidade
Native Nacos fornece funções de alto nível: proteção push O consumidor do serviço (Consumidor) se inscreve na lista de instâncias do provedor de serviços (Provedor) por meio da central de registro Quando a central de registro muda ou encontra uma emergência, ou o provedor de serviços e o. centro de registro Quando o link entre os centros treme devido à rede, CPU e outros fatores, isso pode causar exceções de assinatura, fazendo com que os consumidores do serviço obtenham uma lista vazia de instâncias do provedor de serviços.
Para resolver este problema, você pode habilitar a função de proteção push no cliente Nacos ou no servidor MSE Nacos para melhorar a disponibilidade de todo o sistema. Também introduzimos esta função de estabilidade no suporte de protocolo para Eureka. Quando os dados do servidor MSE Nacos são anormais, quando o cliente Eureka extrai dados do servidor, ele receberá suporte de proteção de recuperação de desastres por padrão para garantir o uso comercial. isso, você não obterá uma lista de instâncias de provedores de serviços que não atendem às expectativas, causando falhas nos negócios.
Além disso, MSE Nacos e MSE ZooKeeper também fornecem vários mecanismos de garantia de alta disponibilidade . Se o lado comercial tiver requisitos mais altos de confiabilidade e segurança de dados, você pode optar por implantar com pelo menos 3 nós ao criar uma instância. Quando uma das instâncias falha, a alternância entre nós é concluída em segundos e o nó com falha sai automaticamente do cluster. Ao mesmo tempo, cada região MSE contém várias zonas de disponibilidade. O atraso da rede entre diferentes zonas na mesma região é muito pequeno (dentro de 3 ms, as instâncias da zona de disponibilidade múltipla podem implantar nós de serviço em diferentes zonas de disponibilidade). , , o tráfego será comutado para outra zona de disponibilidade B em um curto período de tempo. O lado comercial não tem conhecimento de todo o processo, e o nível do código do aplicativo não tem conhecimento e nenhuma alteração é necessária. Esse mecanismo requer apenas a configuração da implantação de vários nós, e o MSE o ajudará automaticamente a implantar em diversas zonas de disponibilidade para recuperação de desastres dispersos.
Apoie o cliente Eureka para extrair dados de forma incremental
Depois que os alunos de Manbang migraram para o MSE Nacos, o problema original da instância do servidor ser suspensa e incapaz de fornecer serviços foi bem resolvido. No entanto, descobriu-se que a largura de banda da rede da sala de computadores era muito alta e, ocasionalmente, a largura de banda ficava cheia. durante os períodos de pico de serviço. Posteriormente, descobriu-se que o motivo era que toda vez que o cliente Eureka extraía as informações de registro do serviço do MSE Nacos, ele suportava apenas pull completo, e milhares de níveis de dados eram extraídos regularmente, resultando em um aumento no número de FGCs em o nível do gateway muito.
Para resolver este problema, o MSE Nacos lançou um mecanismo de extração incremental para informações de registro do serviço Eureka. Em conjunto com o ajuste do uso do cliente, o cliente só precisa extrair a quantidade total de dados uma vez após a primeira inicialização e, posteriormente, apenas. precisa extrair a quantidade total de dados com base no incremental Os dados são usados para manter a consistência dos dados locais e dos dados do servidor, e extrações periódicas em grande escala não são mais necessárias. A quantidade de dados incrementais alterados em um ambiente de produção normal é muito. pequeno, o que pode reduzir significativamente a pressão sobre a largura de banda de exportação. Depois de atualizar para esta versão otimizada, os alunos do Manbang descobriram que a largura de banda caiu repentinamente de 40 MB/s antes da atualização para 200 KB/s, e o problema de largura de banda total foi resolvido.

Teste de estresse completo para otimizar o desempenho do servidor
A equipe MSE posteriormente conduziu um teste de estresse de desempenho em larga escala no cenário MSE Nacos Cluster For Eureka e usou várias ferramentas de análise de desempenho para identificar gargalos de desempenho nos links de negócios e conduziu mais otimização de desempenho e otimização das funções originais. ajuste de parâmetros de desempenho de nível.
- O cache é introduzido para as informações completas e incrementais de registro de dados no lado do servidor, e se as alterações ocorreram é determinado com base no hash de dados do lado do servidor. Em cenários em que o servidor Eureka lê mais e grava menos, ele pode reduzir significativamente a sobrecarga de desempenho dos cálculos da CPU para gerar resultados retornados.
- Foi descoberto que o StringHttpMessageConverter nativo do SpringBoot tinha um gargalo de desempenho ao processar retornos de dados em grande escala, e o EnhancedStringHttpMessageConverter foi fornecido para otimizar o desempenho da transmissão de IO de dados de string.
- O retorno de dados do lado do servidor oferece suporte a blocos.
- O número de conjuntos de encadeamentos do Tomcat é ajustado de forma adaptativa de acordo com a configuração do contêiner.
Depois que o Grupo Manbang concluiu a atualização iterativa da versão acima, vários parâmetros do lado do servidor também alcançaram ótimos resultados de otimização:
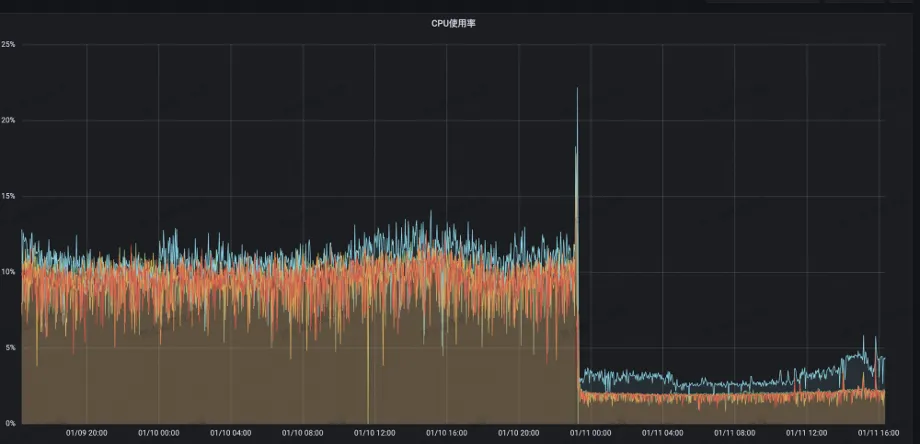
A utilização da CPU do servidor caiu de 13% para 2%
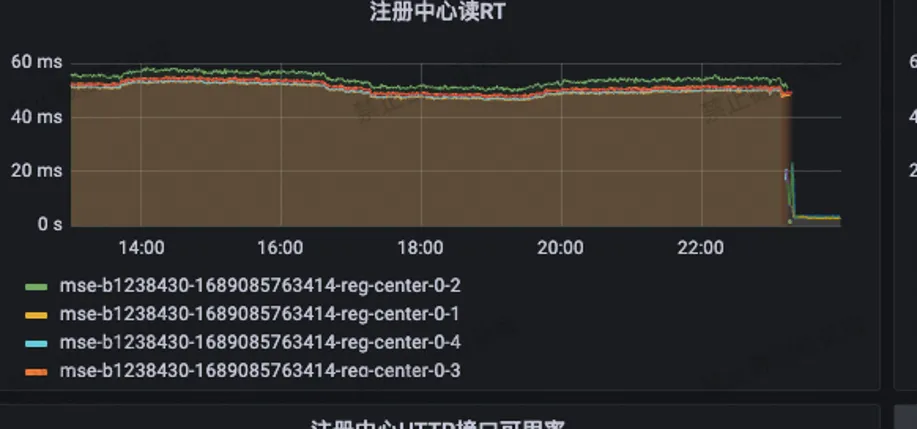
A leitura do RT do centro de registro foi reduzida dos 55ms originais para menos de 3ms.

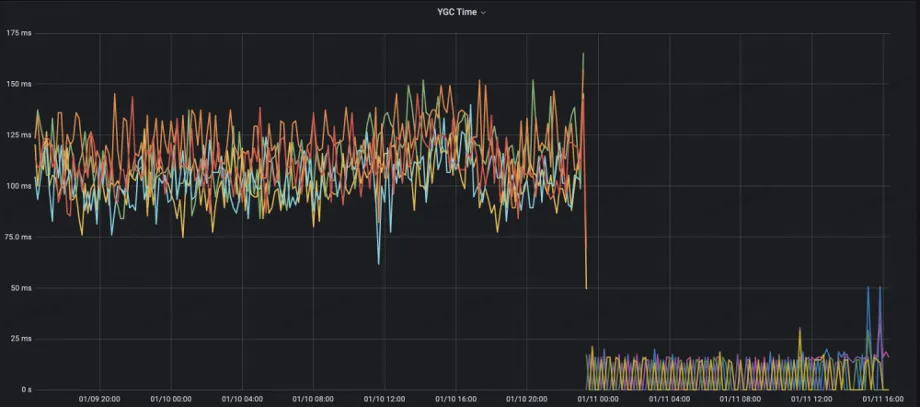
A contagem de YGC do lado do servidor foi reduzida dos 10+ originais para 1
Tempo YGC reduzido dos 125ms originais para menos de 10ms
A otimização de bypass garante a estabilidade do cluster sob alta pressão
Depois que os alunos de Manbang migraram para o MSE ZooKeeper por um período de tempo, o GC completo ocorreu novamente no cluster, fazendo com que o cluster se tornasse instável. Após a investigação de emergência do MSE, descobriu-se que o motivo era um indicador estatístico de métricas relacionado ao relógio. O ZooKeeper foi salvo no nó atual durante o cálculo. Os dados de observação são totalmente copiados e a escala de observação é muito grande em um cenário de grupo completo. A observação de cópia de cálculo de métricas gera uma grande quantidade de fragmentos de memória em tal cenário, resultando no. o cluster final não consegue alocar recursos de memória qualificados e, em última análise, GC completo.
Para resolver este problema, o MSE ZooKeeper toma medidas de downgrade para métricas não importantes para garantir que essas métricas não afetem a estabilidade do cluster. Para métricas de cópia de observação, ele adota uma estratégia de aquisição dinâmica para evitar problemas de fragmentação de memória causados por cálculos de cópia de dados. Depois de aplicar essa otimização, o tempo e o número do cluster Young GC são significativamente reduzidos.
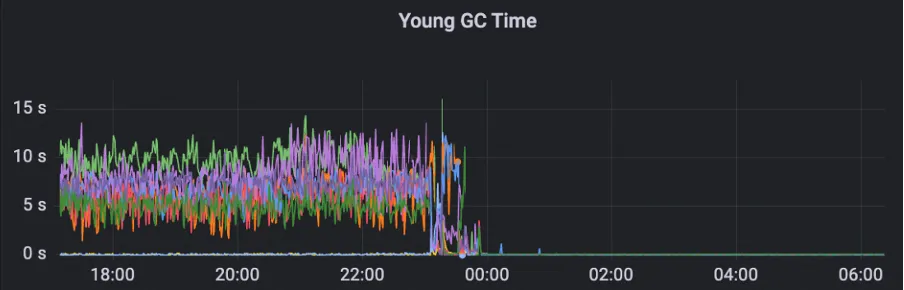

Após a otimização, o cluster pode lidar facilmente com QPS de 200 W e o GC é estável.
Otimização contínua de parâmetros para encontrar o melhor ponto de equilíbrio entre latência e taxa de transferência
Depois que os alunos de Manbang migraram seu ZooKeeper autoconstruído para o MSE ZooKeeper, eles descobriram que quando o aplicativo foi lançado, o atraso do cliente na leitura dos dados no ZooKeeper era muito grande e o tempo limite de configuração de leitura de inicialização do aplicativo, resultando em tempo limite de inicialização do aplicativo. Para resolver esse problema, a análise de teste de estresse direcionado do MSE ZooKeeper mostra que, em um cenário de serviço completo, o ZooKeeper precisa lidar com um grande número de solicitações quando o aplicativo é lançado, e os objetos gerados pelas solicitações causam Young GC frequente no existente configuração.
Em resposta a esse cenário, a equipe do MSE ajustou a configuração do cluster por meio de diversas rodadas de testes de estresse para encontrar o ponto de interseção ideal entre o atraso da solicitação e o TPS. Com a premissa de atender aos requisitos de atraso, a equipe do MSE explorou o desempenho ideal do cluster. e garantiu o atraso da solicitação de 20ms No nível QPS diário de 10w do cluster, a CPU é reduzida de 20% para 5% e a carga do cluster é significativamente reduzida.
pós-escrito
Num contexto de concorrência acirrada na indústria de frete digital e de rápido desenvolvimento tecnológico, o Grupo Manbang atualizou com sucesso sua própria arquitetura técnica, migrando suavemente do centro de registro Eureka autoconstruído para a plataforma MSE Nacos, mais eficiente e estável. Isto não só representa a firme determinação do Grupo Manbang na inovação tecnológica e na expansão dos negócios, mas também demonstra os seus planos de longo alcance para o desenvolvimento futuro. O Grupo Manbang considera a estabilidade e o alto desempenho da arquitetura de microsserviços como o núcleo de sua transformação digital. A melhoria significativa do desempenho e o aprimoramento da estabilidade trazidos pela nova arquitetura do centro de registro fornecem um forte suporte para o Manbang, permitindo que a plataforma esteja mais preparada para lidar com negócios em crescimento. demandas e ter o poder de lidar com quaisquer desafios que possam surgir no futuro.
Vale ressaltar que a resposta ágil do Grupo Manbang ao longo de todo o processo de migração e a execução profissional de sua equipe técnica também aceleraram o ritmo de atualização da arquitetura. A transformação bem-sucedida da plataforma de negócios não apenas aumenta a confiança dos usuários nos serviços da Manbang, mas também proporciona uma experiência valiosa para outras empresas. No futuro, a Manbang continuará a trabalhar em estreita colaboração com a MSE para melhorar ainda mais a estabilidade, escalabilidade e desempenho da arquitectura técnica, continuar a estabelecer padrões de referência para a indústria e promover a transformação digital de toda a indústria logística.
Durante este processo de migração, o negócio pôde ser migrado sem problemas e sem perdas e o desempenho melhorou significativamente, o que comprovou o excelente desempenho e confiabilidade do MSE na área de centros de registro de serviços. Acredito que com a evolução contínua das MPE, a sua busca contínua pela facilidade de utilização e estabilidade trará, sem dúvida, um enorme valor comercial a mais empresas e desempenhará um papel cada vez mais importante no processo de digitalização das empresas.
Além disso, o MSE também oferece suporte total às funções de governança de microsserviços, incluindo proteção de tráfego, liberação de escala de cinza de link completo, etc. Ao aplicar regras de limitação de corrente totalmente configuradas desde o gateway de entrada até o backend, os riscos de estabilidade do sistema causados pelo tráfego repentino são efetivamente resolvidos, garantindo a operação contínua e estável do sistema, e as empresas podem se concentrar mais no desenvolvimento do negócio principal. O caso de sucesso do Grupo Manbang estabeleceu um novo marco para a indústria. Esperamos ver mais empresas alcançando conquistas mais brilhantes em sua jornada digital.
Mensagem do CTO da Manbang, Wang Dong (Dongtian): Compreender e utilizar totalmente os recursos da nuvem pode liberar a equipe técnica da Manbang do investimento contínuo no nível inferior, focar na estabilidade do sistema de nível superior e na eficiência de engenharia e obter melhores resultados do nível arquitetônico.
Atividades recomendadas:

Clique aqui para se inscrever na primeira sessão de arquitetura de aplicativos nativos de IA do Feitian Technology Salon.
A equipe de IA da Microsoft na China fez as malas e foi para os Estados Unidos, envolvendo centenas de pessoas. Quanta receita um projeto de código aberto desconhecido pode trazer? A Huawei anunciou oficialmente que a posição da Universidade de Ciência e Tecnologia de Yu Chengdong foi ajustada. abriu oficialmente o acesso à rede externa Os fraudadores usaram o TeamViewer para transferir 3,98 milhões! O que os fornecedores de desktop remoto devem fazer? A primeira biblioteca de visualização front-end e fundador do conhecido projeto de código aberto ECharts do Baidu - um ex-funcionário de uma conhecida empresa de código aberto que "foi para o mar" deu a notícia: Depois de ser desafiado por seus subordinados, o técnico O líder ficou furioso e rude e demitiu a funcionária grávida. A OpenAI considerou permitir que a IA gerasse conteúdo pornográfico. A Microsoft relatou à The Rust Foundation doou 1 milhão de dólares americanos. ?