Table des matières
1. Résumé et analyse des astuces de réglage des paramètres
1. Angle des données et de l'étiquette
3. Angle de taux d'apprentissage
3.3 Stratégie de décroissance du taux d'apprentissage
4. Exploitation minière dure-négative
5.1 Fusion multi-modèle (Ensemble)
5.2 Distillation des connaissances
5.3 Moyenne mobile exponentielle EMA
5.4、TTA (augmentation du temps de test)
6. Taux d'apprentissage différentiel et apprentissage par transfert
9. Choisissez le bon algorithme d'optimisation
10. J'ai essayé d'adapter un petit ensemble de données
2. Résumé des compétences de formation
3. Une certaine expérience, des essais rapides et des erreurs
1. La formation aux données à petite échelle d'abord
2. La conception des pertes doit être raisonnable
3. L'observation de la perte est meilleure que l'observation de la précision
4. Confirmer que l'apprentissage du réseau classifié est suffisant
5. Le réglage du taux d'apprentissage est raisonnable
6. Comparez la perte de l'ensemble d'apprentissage et de l'ensemble de vérification
7. Connaître la taille du champ récepteur
Autres articles de référence :
1. Augmentation indolore : une astuce pratique pour l'optimisation de la détection des cibles
2. Amenez votre modèle à un niveau supérieur : Résumé des paramètres optimisés
1. Résumé et analyse des astuces de réglage des paramètres
1. Angle des données et de l'étiquette
1.1 Normalisation des données
Normalisation, standardisation et centré/zéro-centré - Blogue de ytusdc - Blogue RPSC
1.2 Amélioration des données
Recadrage et correction d'images aléatoires (RICAP) : Recadrez de manière aléatoire la partie centrale de quatre images, puis assemblez-les en une seule image et mélangez les étiquettes de ces quatre images en même temps. Il s'agit également d'une méthode spéciale d'amélioration des données. L'amélioration générale des données consiste à opérer sur un échantillon, et cette méthode fusionne les échantillons et les étiquettes en même temps, et elle permettra également d'obtenir de bons résultats dans une grande quantité de données.
Cutout : est une nouvelle méthode de régularisation. Le principe est de soustraire aléatoirement une partie de l'image lors de l'apprentissage, ce qui peut améliorer la robustesse du modèle. Son origine est le problème d'occlusion d'objet souvent rencontré dans les tâches de vision par ordinateur. La génération d'objets occultés via la découpe peut non seulement améliorer les performances du modèle lorsqu'il rencontre des problèmes d'occlusion, mais également permettre au modèle de mieux prendre en compte l'environnement (contexte) lors de la prise de décisions. Je crois comprendre qu'il s'agit également d'une méthode d'augmentation des données, qui améliore la capacité de généralisation et réduit le risque de surajustement en rendant l'image incomplète dans une certaine mesure.
Effacement aléatoire : en fait, il est très similaire à la découpe et constitue également une méthode d'amélioration des données pour simuler l'occlusion d'un objet. La différence est que la découpe consiste à définir la valeur de pixel d'une zone rectangulaire sélectionnée au hasard dans l'image sur 0, ce qui équivaut à la couper, et l'effacement aléatoire consiste à remplacer la valeur de pixel d'origine par un nombre aléatoire ou la valeur moyenne de pixels dans le jeu de données. De plus, la taille de la zone découpée par découpe est fixée à chaque fois, et la taille de la zone remplacée par l'effacement aléatoire est aléatoire.
Entraînement au mixage : cette idée est similaire au recadrage et au patch d'images aléatoires ci-dessus. La formation Mixup consiste à retirer 2 images à chaque fois, puis à les combiner de manière linéaire pour obtenir une nouvelle image, qui est utilisée comme nouvel échantillon de formation pour la formation du réseau, comme indiqué dans la formule suivante, où x représente les données d'image et y représente l'étiquette, puis Obtenez le nouveau xhat, yhat.
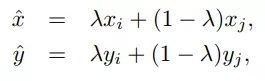
Il semble que la combinaison linéaire des données soit augmentée, ce qui améliore principalement l'expression linéaire entre les échantillons d'apprentissage et améliore la capacité de généralisation du réseau.Cependant, la méthode de mixage prend beaucoup de temps pour mieux converger.
1.3 Lissage des étiquettes
référence:
Lissage d'étiquettes (Label Smoothing) détaillé - Blog de ytusdc - Blog CSDN
2. Initialisation du poids
L'initialisation du poids n'est pas utilisée très fréquemment par rapport aux autres astuces. Étant donné que les modèles que la plupart des gens utilisent sont des modèles pré-formés et que les pondérations utilisées sont des modèles formés sur de grands ensembles de données, il n'est bien sûr pas nécessaire d'initialiser les pondérations vous-même. Seuls les champs sans modèles pré-formés initialiseront les poids eux-mêmes ou initialiseront les poids des dernières couches entièrement connectées du réseau de neurones dans le modèle. L'algorithme d'initialisation de poids couramment utilisé est "kaiming_normal" ou "xavier_normal".
Les paramètres d'initialisation doivent être aussi petits que possible, de sorte que la sortie de régression de softmax soit plus proche de la distribution uniforme, de sorte que le réseau ne sache pas à quelle catégorie appartiennent les données au début ; d'autre part, du point de vue de optimisation numérique, nous espérons que nos paramètres ont une variance cohérente (ordre de grandeur cohérent), de sorte que notre méthode de descente de gradient descendra également plus rapidement. Parallèlement, afin de maintenir une certaine variance de la valeur d'excitation de chaque couche, la variance de nos paramètres d'initialisation (hors biais) peut être inversement proportionnelle à la racine carrée du neurone d'entrée
- uniforme Initialisation de la distribution uniforme :
- Méthode initiale de Xavier, adaptée aux fonctions d'activation ordinaires (tanh, sigmoïde) :
- Il initialisation, adapté à ReLU :
- La distribution gaussienne normale est initialisée, où stdev est l'écart type de la distribution gaussienne, et la moyenne est définie sur 0 :
3. Angle de taux d'apprentissage
Le taux d'apprentissage est un hyperparamètre très, très important. Pour ce paramètre, face à différentes échelles, différentes tailles de lots, différentes méthodes d'optimisation et différents ensembles de données, sa valeur la plus appropriée est incertaine, et nous ne pouvons pas nous fier uniquement à l'expérience. Pour déterminer avec précision la valeur de lr, la seule chose que nous puissions faire est de trouver en permanence le rythme d'apprentissage le plus adapté à l'état actuel pendant l'entraînement.
Si le taux d'apprentissage est trop grand, la formation sera très instable, et s'il est trop petit, la perte diminuera trop lentement . Le taux d'apprentissage diminue généralement avec la formation. Le coefficient d'atténuation peut être défini sur 0,1, 0,3 ou 0,5 . Le moment de l'atténuation peut être lorsque la précision de l'ensemble de vérification n'augmente plus, ou il s'atténuera automatiquement après un nombre fixe de cycles de formation .
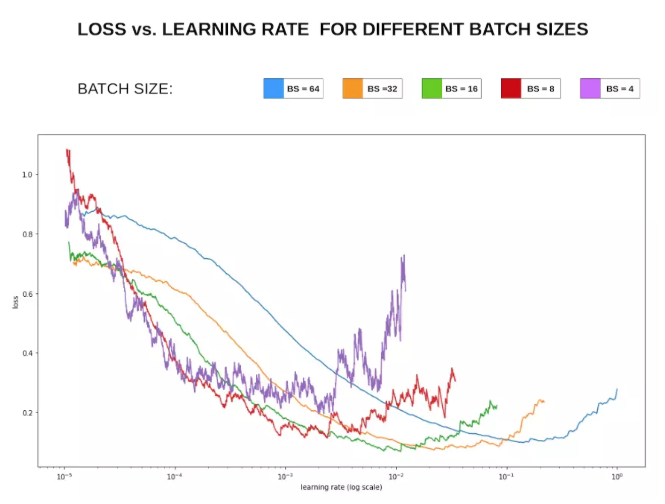
Par exemple, la figure suivante utilise la fonction lr_find() dans fastai pour trouver le taux d'apprentissage approprié, et le taux d'apprentissage approprié à ce moment est 1e-2 selon la courbe taux d'apprentissage-perte ci-dessous.

Recommandez un blog du concepteur en chef de fastai "Sylvain Gugger": Comment trouvez-vous un bon taux d'apprentissage[1], et l'article connexe Taux d'apprentissage cycliques pour les réseaux de neurones de formation[2].
3.1, échauffement
Étape initiale de l'apprentissage : étant donné que les poids du modèle sont initialisés de manière aléatoire au début de l'apprentissage, le choix d'un taux d'apprentissage plus élevé à ce moment peut entraîner une instabilité du modèle. L'échauffement du taux d'apprentissage consiste à utiliser un petit taux d'apprentissage au début de l'entraînement, à entraîner certaines époques ou itérations, puis à le modifier au taux d'apprentissage prédéfini pour l'entraînement lorsque le modèle est stable.
La méthode ci-dessus est un échauffement constant. En 2018, Facebook a amélioré l'échauffement ci-dessus, car le passage d'un petit taux d'apprentissage à un taux d'apprentissage relativement important peut entraîner une augmentation soudaine des erreurs de formation. Un échauffement progressif est proposé pour résoudre ce problème, c'est-à-dire qu'à partir du petit taux d'apprentissage initial, chaque itération augmente un peu jusqu'à ce que le taux d'apprentissage relativement élevé soit initialement défini.
3.2, Taux d'apprentissage de mise à l'échelle linéaire - la relation entre le taux d'apprentissage et la taille du lot
Des expériences ont prouvé qu'un lot de grande taille aura un taux de précision inférieur à la même époque. L'utilisation du préchauffage peut résoudre ce problème dans une certaine mesure, et le taux d'apprentissage de la mise à l'échelle linéaire est également une méthode efficace.
En général, une taille de lot plus grande utilise un taux d'apprentissage plus élevé.
Lors de la formation SGD en mini-lot, la valeur de descente de gradient est aléatoire, car les données de chaque lot sont sélectionnées de manière aléatoire. L'augmentation de la taille du lot ne modifie pas l'attente du gradient, mais réduit sa variance. En d'autres termes, une grande taille de lot réduira le bruit dans le gradient, nous pouvons donc augmenter le taux d'apprentissage pour accélérer la convergence.
La méthode spécifique est très simple. Par exemple, dans l'article ResNet original, le taux d'apprentissage sélectionné lorsque la taille du lot est de 256 est de 0,1. Lorsque nous modifions la taille du lot en un nombre plus grand b, le taux d'apprentissage devrait devenir 0,1 × b/ 256. C'est-à-dire que le taux d'apprentissage est défini de manière linéaire en fonction de la taille du lot, de manière à obtenir un meilleur effet d'apprentissage.
En termes simples, le bruit de gradient calculé par une grande taille de lot est plus petit, de sorte qu'un taux d'apprentissage plus élevé peut être utilisé pour augmenter la convergence. Voici donc une question, pourquoi une petite taille de lot converge-t-elle généralement plus rapidement ? En effet, bien que la direction de la petite taille de lot ne soit pas nécessairement précise, mais que le nombre de mises à jour soit important, la vitesse de convergence finale sera plus rapide. Bien qu'une grande taille de lot ait moins de bruit et des directions plus précises, l'effet du taux d'apprentissage ne sera pas très bon, donc augmenter linéairement le taux d'apprentissage équivaut en fait à utiliser une seule quantité de mise à jour pour augmenter pour compenser le fait que le le nombre de mises à jour est faible.
En résumé, une taille de lot plus grande signifie que lorsque nous apprenons, plus la confiance dans la direction de convergence est grande, plus notre direction de progression est déterminée, tandis qu'une petite taille de lot semble être plus chaotique et irrégulière, car par rapport au lot Lorsqu'il est grand, il est impossible de prendre en charge plus de situations lorsque le lot est petit, donc un petit taux d'apprentissage est nécessaire pour s'assurer qu'aucune erreur ne se produira.
Vous pouvez voir la relation entre la perte Loss et le taux d'apprentissage Lr dans la figure ci-dessous :
Sous réserve d'une mémoire vidéo suffisante, il est préférable d'utiliser une plus grande taille de lot pour la formation.Après avoir trouvé un taux d'apprentissage approprié, la vitesse de convergence peut être accélérée. De plus, une taille de lot plus grande peut éviter certains problèmes mineurs de normalisation des lots,
3.3 Stratégie de décroissance du taux d'apprentissage
Pendant le processus d'entraînement après l'échauffement, la décroissance continue du taux d'apprentissage est un bon moyen d'améliorer la précision. Par conséquent, une stratégie appropriée de décroissance du taux d'apprentissage peut être sélectionnée :
Stratégie de déclin du taux d'apprentissage - Zhihu
Descente de gradient stochastique avec recuit cosinus et redémarrage à chaud
"Cosinus" est une courbe similaire à une fonction cosinus, "recuit" est un déclin et "recuit cosinus" est un taux d'apprentissage qui est similaire à une fonction cosinus et diminue lentement.
« Redémarrage à chaud » signifie que pendant le processus d'apprentissage, le « taux d'apprentissage » diminue lentement, puis subitement « rebondit » (redémarrage) et continue ensuite à diminuer lentement.
Redémarrez le taux d'apprentissage de temps en temps, de sorte que plusieurs minima locaux puissent converger en une unité de temps et que de nombreux modèles puissent être intégrés pour l'intégration.

Notez également que certains paramètres ont des taux d'apprentissage plus rapides ou plus lents, nous pouvons donc définir des taux d'apprentissage différents pour différents groupes de paramètres dans le modèle. Également décrit dans le lien ci-dessus
Avec inondation
Lorsque la perte d'entraînement est supérieure à un seuil, la descente de gradient normale est effectuée ; lorsque la perte d'entraînement est inférieure au seuil, le gradient est inversé pour maintenir la perte d'entraînement près d'un seuil, et le modèle continue à effectuer une "marche aléatoire" , et attendez le modèle Il peut être optimisé pour une zone de perte plate, il est donc constaté que la perte de test a effectué une double descente.
flood = (loss - b).abs() + b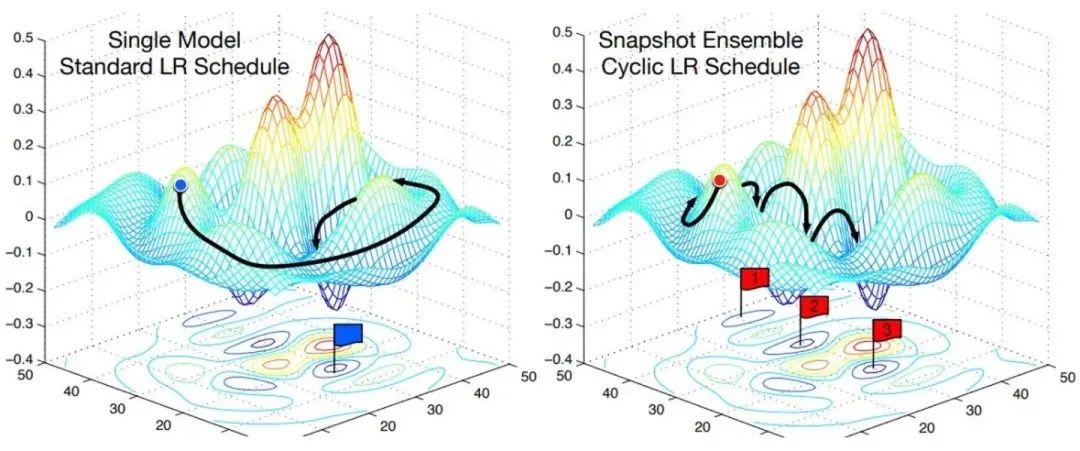
4. Exploitation minière dure-négative
1. Il est difficile pour le modèle d'analyse de prédire le bon échantillon, et une méthode ciblée est donnée.
2. mauvaise analyse des cas
5. L'angle du modèle
5.1 Fusion multi-modèle (Ensemble)
Ensemble est l'arme nucléaire ultime pour les résultats de thèse. Il existe généralement les méthodes suivantes dans l'apprentissage en profondeur
- Mêmes paramètres, différentes méthodes d'initialisation
- Différents paramètres, par validation croisée, sélectionnent les meilleurs groupes
- Les mêmes paramètres, différentes étapes de formation du modèle, c'est-à-dire des modèles avec différentes itérations.
- Différents modèles effectuent une fusion linéaire, par exemple RNN et les modèles traditionnels.
- Amélioration des performances et de la robustesse du modèle : fusion et vote des probs.
En supposant qu'il y ait le modèle 1, le modèle 2 et le modèle 3 ici, ils peuvent être intégrés comme ceci :
- probs model1 + probs model2 + probs model3 ==> étiquette finale
- étiquette modèle1 , étiquette modèle2 , étiquette modèle3 ==> vote ==> étiquette finale
- model1_1 probs + ... + model1_n probs ==> model1 label, model2 label et model3 obtiennent la même méthode de label que 1 ==> vote ==> label final
La troisième méthode s'inspire du fait que si la graine aléatoire d'un modèle n'est pas fixe, les résultats de plusieurs prédictions peuvent être différents. L'effet de la méthode ci-dessus doit être analysé en détail en fonction de problèmes spécifiques tels que le nombre d'étiquettes et la taille de l'ensemble de données, et les performances peuvent être différentes.La méthode n'est rien de plus que l'utilisation unique ou la combinaison de probs fusion et le mode de vote.
5.2 Distillation des connaissances
Ceci est en fait analysé du point de vue de la fonction de coût. Utilisez un modèle d'enseignant pour aider la formation du modèle actuel (modèle étudiant), le modèle étudiant utilisera une nouvelle fonction de coût, veuillez vous référer à la distillation des connaissances pour plus de détails
La prédiction à l'aide d'un ensemble de tous les modèles est lourde et peut nécessiter trop de calculs pour être déployée auprès d'un grand nombre d'utilisateurs. La méthode Knowledge Distillation (distillation des connaissances) est l'une des méthodes efficaces pour faire face à ce genre de problème.
Dans la méthode de distillation des connaissances, nous utilisons un modèle d'enseignant pour aider la formation du modèle actuel (modèle étudiant). Le modèle de l'enseignant est un modèle pré-formé avec une plus grande précision, de sorte que le modèle de l'élève peut améliorer la précision tout en gardant la complexité du modèle inchangée. Par exemple, ResNet-152 peut être utilisé comme modèle d'enseignant pour aider l'étudiant à modéliser la formation ResNet-50. Lors de la formation, nous ajoutons une perte de distillation pour pénaliser la différence entre la sortie du modèle étudiant et le modèle enseignant.
Cette technologie a été créée par Hinton, qui guide la formation de réseau léger à travers un meilleur réseau, et obtient finalement de meilleurs résultats de formation.
5.3 Moyenne mobile exponentielle EMA
Le modèle de moyenne glissante calcule en continu la moyenne glissante des paramètres pendant le processus d'apprentissage, ce qui peut maintenir la stabilité plus efficacement et la rendre insensible aux mises à jour des paramètres actuels. Par exemple, la méthode de descente de gradient stochastique avec un terme de momentum consiste à appliquer un modèle de moyenne mobile au taux d'apprentissage.
Article de référence :
5.4、TTA (augmentation du temps de test)
Initialement, ce concept a été vu dans le cours fastai, ce processus ne sera pas impliqué dans la phase de formation, il se fait dans la phase de vérification et de test. Le processus spécifique consiste à effectuer plusieurs changements d'amélioration d'image aléatoires sur l'image à traiter, puis à prédire l'image après chaque amélioration d'image et à prendre la valeur moyenne des résultats de prédiction.
Le principe est similaire à la moyenne du modèle, qui sacrifie la vitesse d'inférence pour améliorer la précision de l'inférence. Bien entendu, cette technologie présente également des avantages et des inconvénients. Dans l'ensemble de données d'images satellite que j'ai géré moi-même, la précision de l'utilisation de TTA est inférieure de 0,03 point de pourcentage à celle de ne pas l'utiliser.
6. Taux d'apprentissage différentiel et apprentissage par transfert
Permettez-moi de parler d'abord de l'apprentissage de la migration. L'apprentissage de la migration est une technique d'apprentissage en profondeur très courante. Nous utilisons de nombreux modèles classiques pré-entraînés pour entraîner directement nos propres tâches. Bien que les domaines soient différents, il existe un lien entre les deux tâches en termes d'étendue des poids appris.
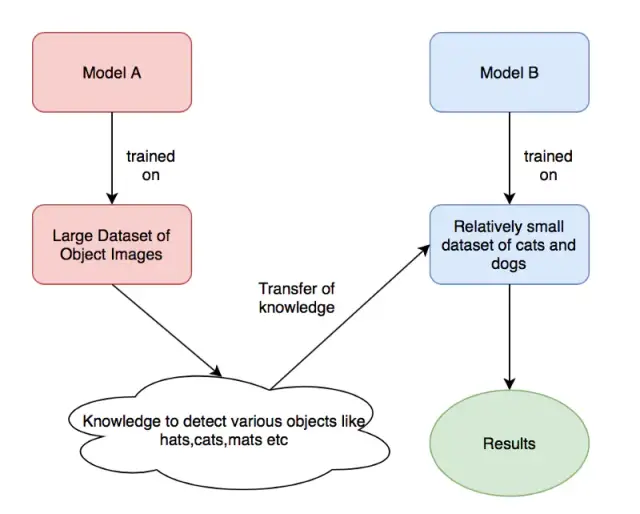
À partir de la figure ci-dessus, nous utilisons les poids de modèle formés par le "modèle A" pour former nos propres poids de modèle ("Modèle B"), où modelA peut être les poids pré-formés d'ImageNet, et ModelB est ce que nous voulons utiliser. pour identifier les poids pré-entraînés pour les chats et les chiens.
Alors, quelle est la relation entre le taux d'apprentissage différentiel et l'apprentissage par transfert ? Nous utilisons directement les poids d'entraînement d'autres tâches.Lors de l'optimisation, comment choisir un taux d'apprentissage approprié est une question très importante.
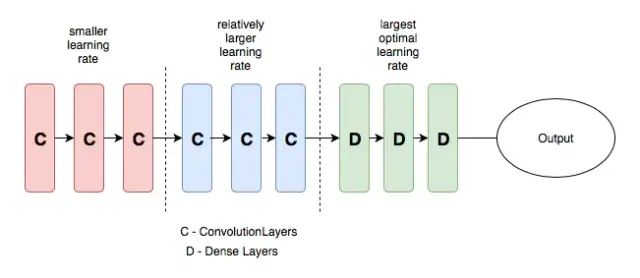
Généralement, le réseau de neurones que nous concevons (comme illustré dans la figure ci-dessous) est généralement divisé en trois parties, la couche d'entrée, la couche cachée et la couche de sortie. À mesure que le nombre de couches augmente, les fonctionnalités apprises par le réseau de neurones deviennent plus abstrait. Par conséquent, le taux d'apprentissage de la couche convolutive et de la couche entièrement connectée dans la figure ci-dessous doit également être défini différemment. D'une manière générale, le taux d'apprentissage défini pour la couche convolutive doit être inférieur, tandis que le taux d'apprentissage de la couche entièrement connectée peut être augmenté de manière appropriée.
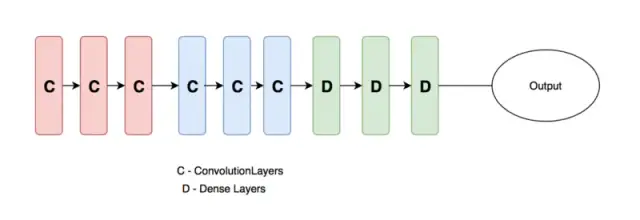
C'est la signification du taux d'apprentissage différentiel. La définition de différents taux d'apprentissage dans différentes couches peut améliorer l'effet d'entraînement du réseau de neurones. Pour plus de détails, veuillez vous référer à la connexion ci-dessous.
7. Formation multi-échelle
La formation multi-échelles est une méthode "directe et efficace". En saisissant des ensembles de données d'images à différentes échelles, en raison de la particularité de la mise en commun des convolutions du réseau de neurones, cela permet au réseau de neurones d'apprendre pleinement les caractéristiques des images à différentes résolutions, ce qui peut L'amélioration des performances de l'apprentissage automatique peut également être utilisée pour gérer l'effet de surajustement.Lorsque l'ensemble de données d'image n'est pas particulièrement suffisant, vous pouvez d'abord former une image de petite taille, puis augmenter la taille et former à nouveau le même modèle.Cette idée est dans Yolo- Il est également mentionné dans l'article v2.
Il convient de noter que la formation multi-échelles ne convient pas à toutes les applications d'apprentissage en profondeur.La formation multi-échelles peut être considérée comme une méthode spéciale d'amélioration des données et la taille de l'image a été ajustée. Si c'est possible, il est préférable d'utiliser le code visuel pour observer de près l'image multi-échelle, "voir si la multi-échelle affectera les informations globales de l'image", si cela affecte les informations de l'image, une telle formation directe induire en erreur l'algorithme conduit à ne pas obtenir les résultats souhaités.
8. Validation croisée
Dans la méthode statistique de Li Hang, la validation croisée est souvent utilisée pour les "données insuffisantes" dans les applications pratiques, et le but fondamental est de réutiliser les données. En temps normal, nous divisons toutes les données en ensemble d'apprentissage et ensemble de vérification, qui est déjà une simple validation croisée, qui peut être appelée validation croisée 1 fois. "Notez que la validation croisée n'a rien à voir avec l'ensemble de test. L'ensemble de test est utilisé pour mesurer nos normes d'algorithme et ne participe pas à la validation croisée."
La validation croisée ne fonctionne que sur les ensembles de formation et de validation.
La validation croisée est une technique particulièrement recommandée dans les compétitions Kaggle. Nous utilisons souvent la validation croisée 5 fois (5 fois), divisons l'ensemble d'entraînement en 5 parties, en choisissons une au hasard comme ensemble de vérification et le reste comme entraînement. ensemble, cycle 5 Deuxièmement, ce type de comparaison n'est pas très gourmand en calculs. Il existe également une méthode appelée validation croisée sans omission. Ce type de validation croisée est une validation croisée n fois, où n représente la capacité de l'ensemble de données. Cette méthode ne convient que dans les cas où la quantité de données est relativement faible. , et la quantité de calcul est très importante. Cette méthode est rarement utilisée.
9. Choisissez le bon algorithme d'optimisation
Il va de soi que différents algorithmes d'optimisation conviennent à différentes tâches, mais la plupart des algorithmes d'optimisation que nous utilisons sont adam et SGD+monmentum. Adam peut résoudre un tas de problèmes étranges (parfois la perte ne peut pas diminuer, il suffit de changer Adam instantanément), et cela peut également apporter un tas de problèmes étranges (comme la différence de fréquence des mots est très grande, le lot actuel ne le fait pas avoir des mots Le vecteur de mots est également mis à jour ; un autre exemple est l'effet complexe de la combinaison d'Adam et de la régularisation L2). Soyez audacieux et prudent lorsque vous l'utilisez. En cas de problème, trouvez diverses modifications magiques Adams (telles que MaskedAdam [14], AdamW, etc.) pour le sauvetage.
Mais j'ai lu des blogs disant que par rapport à SGD, la convergence d'Adam est plus rapide, mais sa capacité de généralisation est médiocre, et de meilleurs résultats semblent nécessiter un réglage fin de SGD. adam, adadelta, etc., sur de petites données, l'effet de mon expérience ici n'est pas aussi bon que sgd, et la vitesse de convergence de sgd sera plus lente, mais les résultats convergents finaux sont généralement meilleurs. Si vous utilisez sgd, vous pouvez choisir de commencer avec un taux d'apprentissage de 1,0 ou 0,1, et de le vérifier sur le jeu de vérification après un certain temps. Si le coût ne baisse pas, vous pouvez réduire de moitié le taux d'apprentissage. J'ai lu beaucoup papiers qui font cela, moi-même Les résultats de l'expérience sont également très bons. Bien sûr, vous pouvez également utiliser la série ada pour exécuter en premier, et lorsque la convergence finale est rapide, remplacez-la par sgd pour continuer la formation. Cela améliorera également On dit qu'adadelta a généralement un meilleur effet sur les problèmes de classification, et adam génère L'effet est meilleur sur le problème.
Bien qu'adam converge rapidement, la solution obtenue n'est souvent pas aussi bonne que la solution obtenue par sgd+momentum.Si vous ne considérez pas le coût en temps, utilisez sgd. Adam n'a pas besoin d'ajuster spécialement lr, et sgd doit passer plus de temps à ajuster lr et les poids initiaux.
10. J'ai essayé d'adapter un petit ensemble de données
C'est une astuce classique, mais beaucoup de gens ne le font pas, vous pouvez l'essayer. Désactivez la régularisation/l'abandon/l'augmentation des données, laissez le réseau de neurones s'entraîner pendant quelques époques en utilisant une petite partie de l'ensemble d'apprentissage. Assurez-vous que vous pouvez atteindre zéro perte, sinon, alors quelque chose ne va probablement pas.
Autres astuces
En plus des nombreuses astuces très avancées ci-dessus, il existe de nombreuses petites astuces pour améliorer les performances, dont certaines sont particulièrement utilisées et courantes.Voici un résumé :
2. Résumé des compétences de formation
- Dans le cas d'un ensemble de données volumineux, n'exécutez pas la totalité de la quantité de données dès qu'elle apparaît. Tout d'abord, entraînez-vous et testez sur un ensemble d'entraînement plus petit (il est recommandé d'utiliser 1/100, 1/10) pour avoir une idée des performances du modèle et du temps d'entraînement, et extrapolez le temps nécessaire pour exécuter la totalité des données. Ne menez pas d'expériences à grande échelle sans une confiance suffisante. Voyez s'il peut surajuster ou prédire de meilleurs résultats sur un petit ensemble de données. Si ce n'est pas le cas, le taux d'apprentissage est peut-être trop élevé ou le code est mal écrit. Essayez d'abord de réduire le taux d'apprentissage, et si cela ne fonctionne toujours pas, vérifiez le code pour voir si les données sorties par le chargeur de données sont correctes, puis vérifiez si la taille de chaque étape du modèle répond à vos attentes. Par exemple : vous n'avez pas besoin d'un grand ensemble de données au début, mais ajustez d'abord les paramètres sur un petit ensemble de données d'environ 2 semaines d'apprentissage et 2 000 ensembles de test.
- En regardant la courbe de perte de train/eval, la situation normale devrait être que la perte de train continue de diminuer en forme de journal et finalement se stabilise. La perte d'eval commence à diminuer jusqu'à une certaine époque, puis se stabilise ou commence à augmenter. À ce moment , un arrêt précoce peut être utilisé Enregistrez le modèle avec la perte d'évaluation la plus faible. a. Si la courbe de perte est très anormale, il est probable qu'il y ait un problème avec le traitement des données, comme une mauvaise étiquette, revenez en arrière et vérifiez le code. b. Si le réseau que nous avons conçu ne fonctionne pas et que le taux correct dans l'ensemble d'apprentissage est également très faible, nous pouvons réduire le nombre d'échantillons et supprimer l'élément de régularisation, puis ajuster les paramètres. Si le taux correct n'est toujours pas élevé , cela signifie que nous avons conçu Les résultats Web pour peuvent être problématiques.
- L'optimiseur utilise d'abord adam, le taux d'apprentissage est défini sur 1e-3 ou 1e-4, puis essaie Radam (LiyuanLucasLiu/RAdam). sgd n'est pas recommandé car il est très lent. La vitesse de convergence de sgd sera plus lente, mais les résultats convergés finaux sont généralement meilleurs. Si vous utilisez sgd, vous pouvez choisir de commencer avec un taux d'apprentissage de 1,0 ou 0,1, et de le vérifier sur le jeu de vérification après un certain temps. Si le coût ne baisse pas, vous pouvez réduire de moitié le taux d'apprentissage. J'ai lu beaucoup papiers qui font cela, moi-même Les résultats de l'expérience sont également très bons. Bien sûr, vous pouvez également utiliser la série ada pour exécuter en premier, et lorsque la convergence finale est rapide, remplacez-la par sgd pour continuer la formation. Cela améliorera également On dit qu'adadelta a généralement un meilleur effet sur les problèmes de classification, et adam génère L'effet est meilleur sur le problème.
- Pendant le réglage fin, le taux d'apprentissage de la couche nouvellement ajoutée peut être augmenté et le taux d'apprentissage de la couche réutilisée peut être réglé relativement bas.
- Il suffit généralement d'utiliser relu pour la fonction d'activation, et vous pouvez également essayer relu qui fuit. Lorsque la fonction d'activation est RELU, lorsque l'on initialise l'item de biais, afin d'éviter trop de nœuds morts (la valeur d'activation est 0), on peut généralement l'initialiser à une petite valeur positive.
- Pendant le processus de formation, il est nécessaire non seulement d'observer si la perte de l'ensemble d'apprentissage et de l'ensemble de test est réduite et si le taux de précision est augmenté, mais également d'observer la distribution des paramètres et des valeurs d'activation dans le temps, et il doit y avoir certaines fluctuations. Une bonne mesure consiste à utiliser une bibliothèque de visualisation pour générer des histogrammes de poids après quelques exemples d'entraînement, ou entre les époques. Cela peut nous aider à détecter certains problèmes courants dans les modèles d'apprentissage en profondeur, tels que la disparition du gradient et l'explosion du gradient (Exploding Gradient)
- Pour effectuer la normalisation du gradient, c'est-à-dire diviser le gradient calculé par la taille du mini-lot
- Test de gradient : lorsque notre algorithme rencontre des problèmes d'apprentissage et de débogage, nous pouvons envisager d'utiliser le gradient numérique approximatif et le gradient calculé pour comparer et vérifier si le gradient est calculé correctement.
- Écrêtage de dégradé (écrêtage de dégradé) : il existe certaines tâches (en particulier celles avec RNN) pour effectuer un écrêtage de dégradé (torch.nn.utils.clip_grad_norm), limiter le gradient maximum peut empêcher l'explosion du gradient, en fait, valeur = sqrt(w1^2 +w2 ^2….) , si la valeur dépasse le seuil, elle est considérée comme un coefficient d'atténuation, et la valeur de valeur est égale au seuil : 5, 10, 15. Entraînement RNN, si l'écrêtage du gradient n'est pas ajouté, la perte deviendra soudainement Nan après une période d'entraînement.
- Batchnorm et dropout peuvent être essayés, et l'emplacement est très important. Essayez de le placer avant la couche de sortie finale et après la couche d'intégration. RNN peut essayer layer_norm. Cependant, l'ajout de ces couches à certaines tâches peut avoir des effets négatifs. L'abandon a un bon effet sur la prévention du surajustement pour les petites données, et la valeur est généralement définie sur 0, 5. L'abandon + sgd sur les petites données a un effet très évident dans la plupart de mes expériences. Par conséquent, si possible, il est recommandé de l'essayer. La position du dropout est plus particulière, pour RNN, il est recommandé de le mettre dans la position entrée->RNN et RNN->sortie
- lrscheduler utilise torch.optim.lr_scheduler.CosineAnnealingLR, T_max est défini sur 32 ou 64 et les résultats des tests de plusieurs tâches sont bons. (L'utilisation de ce lr_scheduler plus l'optimiseur du département Adam n'a fondamentalement pas besoin d'ajuster le taux d'apprentissage)
- En termes de super paramètres, le taux d'apprentissage est le plus important. Il est recommandé de comprendre le taux d'apprentissage cosinus et le taux d'apprentissage cyclique
, suivis de la taille du lot et de la décroissance du poids. Lorsque votre modèle n'est pas mauvais, vous pouvez essayer d'augmenter les données et de modifier la fonction de perte pour le rendre encore meilleur. Vous pouvez essayer la perte de poids, j'utilise habituellement 1e-4. - Lors de la détermination du taux d'apprentissage initial, commencez par une petite valeur (par exemple, 1e-7), puis augmentez le taux d'apprentissage de manière exponentielle (par exemple, d'un facteur de 1,05) pour l'entraînement à chaque étape. Après un entraînement sur des centaines d'étapes, vous devriez pouvoir observer que la fonction de perte a la forme d'une coche avec le nombre d'étapes d'entraînement. Il vous suffit de choisir le taux d'apprentissage auquel la perte diminue le plus rapidement.
- En plus de la porte et autres, vous devez limiter la sortie à 0-1, essayez de ne pas utiliser sigmoïde, vous pouvez utiliser des fonctions d'activation telles que tanh ou relu. La fonction sigmoïde est dans l'intervalle [-4, 4] , ce qui est plus efficace.de gros gradients. En dehors de l'intervalle, le gradient est proche de 0, ce qui peut facilement poser le problème de disparition du gradient. Entrée 0 moyenne, la sortie de la fonction sigmoïde n'est pas 0 moyenne.
- Essayez de mélanger les données
- Si votre modèle contient une couche entièrement connectée (MLP) et que les tailles d'entrée et de sortie sont identiques, vous pouvez envisager de remplacer MLP par Highway Network. J'essaie d'améliorer un peu le résultat. Il est recommandé d'améliorer le modèle. Le principe est très simple, c'est-à-dire qu'à la sortie s'ajoute une porte pour contrôler le flux d'informations.
- Un cycle d'ajout de régularisation, un cycle de non-ajout de régularisation et de répétition.
- Là où il y a CNN, utilisez un raccourci. Une fois le nombre de couches CNN ajouté à une certaine valeur, l'effet sur le résultat n'est pas important et cette valeur peut être ajustée en tant que paramètre.
- Faites attention à la reproductibilité et à la cohérence de l'expérience, et faites attention à développer de bonnes habitudes d'enregistrement expérimental ==> Sinon, comment analyser la conclusion expérimentale.
- Pour la plupart des tâches, les données sont plus importantes que le modèle. Lorsque vous faites face à une nouvelle tâche, analysez d'abord les données, puis concevez un modèle basé sur les données et déterminez chaque paramètre. Par exemple, la longueur de remplissage dans certaines tâches de nlp doit généralement atteindre plus de 90 % de l'ensemble de données, ce qui peut être analysé par la fonction describe de pandas.
compétences de réglage rnn
- Le biais de la porte d'oubli de LSTM, initialisé avec une valeur de 1,0 ou plus, peut obtenir de meilleurs résultats.Je l'ai défini sur 1,0 dans l'expérience ici, ce qui peut améliorer la vitesse de convergence.En utilisation réelle, différentes tâches peuvent devoir essayer valeurs différentes.
- Ajoutez une astuce rnn, toujours sans tenir compte du coût en temps, batch size=1 est un très bon régularisateur,
- L'initialisation Word2vec, sur de petites données, peut non seulement améliorer efficacement la vitesse de convergence, mais également améliorer les résultats.
- La taille dim et d'intégration de rnn est généralement ajustée à partir d'environ 128. La taille du lot est généralement ajustée à partir d'environ 128. Le plus important est que la taille du lot soit appropriée, pas plus elle est grande, mieux c'est.
- Lorsqu'une erreur est signalée sur le GPU, essayez de la réexécuter sur le CPU autant que possible, et le message d'erreur est plus convivial. Par exemple, le GPU signale "ERROR:tensorflow:Model diverged with loss = NaN". En fait, il est très probable que l'ID d'entrée dépasse le cadre du vocabulaire softmax.
3. Une certaine expérience, des essais rapides et des erreurs
Quelques grosses notes :
1. La formation aux données à petite échelle d'abord
Au début, téléchargez d'abord les données à petite échelle, puis agrandissez le modèle. Tant que la mémoire vidéo n'éclate pas, vous pouvez utiliser 256 filtres au lieu de 128. Passez directement au surajustement. C'est vrai, c'est le réseau de montage formé. Même l'ensemble de test et l'ensemble de vérification peuvent être utilisés.
1.
Vous devez vérifier que le processus de votre script de formation est correct. La quantité de données dans cette étape est petite et la vitesse de génération est rapide, mais tous les scripts sont cohérents avec la future formation à grande échelle (sauf pour les boucles moins courantes) 2. Si la
quantité de données est petite, votre approximation et grand réseau ira au surajustement Aucun n'a fonctionné. Donc, il faut commencer à réfléchir sur soi, y a-t-il un problème avec l'entrée et la sortie du modèle ? Voulez-vous vérifier votre code (ne doutez jamais de la bibliothèque d'outils, sauf si vous avez déplacé le code) ? Y a-t-il un problème avec la définition du problème résolu par le modèle ? La compréhension du scénario d'application est-elle erronée ? Ne doutez pas de la capacité de NN, ne doutez pas de la capacité de NN, ne doutez pas de la capacité de NN. En ce qui concerne les problèmes que nous pouvons rencontrer avec le chien d'ajustement des paramètres, NN ne peut pas correspondre, quelle est cette probabilité ? Vous n'êtes pas obligé de le faire, mais lorsque vous avez préparé les données pendant deux jours et constaté qu'il y a un problème à régénérer, tu es sous sauce soja cette semaine.
2. La conception des pertes doit être raisonnable
1. De manière générale, la classification est Softmax et la régression est la perte de L2. Mais faites attention à la plage d'erreur de la perte (principalement la régression). Si vous prédisez une étiquette avec une valeur de 10 000 et que le modèle génère 0, vous pouvez calculer l'ampleur de la perte. Il s'agit toujours d'un cas univarié. Le résultat général est nan. Ainsi, non seulement l'entrée doit être normalisée, mais la sortie doit également être normalisée.
2. Dans le cas du multitâche, chaque idée de perte est limitée à une ampleur, ou éventuellement limitée à une ampleur, et la phase initiale peut se concentrer sur la perte d'une tâche
3. L'observation de la perte est meilleure que l'observation de la précision
Bien que le taux de précision soit un indice d'évaluation, il faut tout de même faire attention à la perte lors du processus d'apprentissage. Vous constaterez que dans certains cas, le taux de précision change soudainement. Il était toujours de 0, et il peut rester pendant des milliers d'itérations, puis passe soudainement à 1. Si vous arrêtez de vous entraîner tôt à cause de cela, seul Dieu sera désolé pour vous. Et la perte n'aura pas une situation aussi étrange, après tout, l'objectif d'optimisation est la perte. Donnez un peu de temps à NN et laissez un certain espace à NN pour apprendre en fonction de la tâche. On ne peut pas dire qu'il ne s'est pas amélioré au cours de la dernière période et qu'il est ignoré. Dans certains cas, il n'y a pas d'amélioration pendant un certain temps, puis vous commencez à étudier régulièrement.
4. Confirmer que l'apprentissage du réseau classifié est suffisant
Un réseau de classification consiste à apprendre les frontières entre les catégories. Vous constaterez que le réseau passe lentement de catégories floues à des catégories claires. Comment le savoir Regardez la distribution de la sortie de probabilité par Softmax. S'il s'agit d'une classification binaire, vous constaterez que les prédictions initiales du réseau sont toutes autour de 0,5, ce qui est très vague. Avec le processus d'apprentissage, la prédiction du réseau se déplacera lentement vers les valeurs extrêmes de 0 et 1. Donc, si la distribution de prédiction de votre réseau se situe au milieu, alors apprenez à apprendre.
5. Le réglage du taux d'apprentissage est raisonnable
Trop grand : la perte explose, ou nan
est trop petit : la perte ne se répercute pas longtemps (cependant, il en est de même lorsqu'il faut réduire LR. Ici, ce sont les résultats intermédiaires du réseau qui sont visualisés, pas les poids, qui ont un effet. Les résultats visuels des deux sont différents. S'il est trop petit Le résultat intermédiaire ressemble à des ondulations d'eau ou à du bruit, car l'apprentissage du filtre est trop lent, vous saurez après l'avoir essayé (évidemment) qu'il doit être plus
approfondi réduit : la perte a été réduite jusqu'au bout sous le LR actuel, mais elle a cessé de baisser depuis une demi-journée.
S'il y a une tâche plus compliquée, au début, il faut de la chair humaine pour surveiller et ajuster LR. Après vous être familiarisé avec les caractéristiques de ce réseau de tâches en apprenant plus tard, vous pouvez le jeter de côté et vous enfuir.
Si la conception de perte ci-dessus est déraisonnable, il est facile d'exploser dans la situation initiale, installez d'abord un petit LR pour vous assurer qu'il n'explosera pas, attendez que la perte diminue, puis augmentez lentement le LR, et bien sûr il va lentement diminuez à nouveau le LR, bien que cela soit nul.
LR se ferme à la valeur maximale pouvant fonctionner, pour ne pas tuer les neurones par ReLU. Bien sûr, je suis une personne impatiente, et j'aime toujours en mettre en place une plus grande.
6. Comparez la perte de l'ensemble d'apprentissage et de l'ensemble de vérification
Juger le surentraînement, si la formation est suffisante et si un arrêt précoce est nécessaire sont tous des principes assez standard, donc je ne dirai pas grand-chose.
7. Connaître la taille du champ récepteur
Pour la tâche de CV, la fenêtre de contexte est très importante. Il faut donc connaître la taille du champ récepteur de votre modèle. Cet effet sur l'effet est encore très important. Surtout avec FCN, les grandes cibles nécessitent un grand champ récepteur. Contrairement au réseau avec une connexion complète, il y a au moins un fc pour couvrir le résultat net, et les informations globales sont disponibles.