Nous avons terminé le déploiement et la formation à grande échelle du modèle de suppression de la pluie, de la neige et du brouillard basé sur la distillation des connaissances. Ensuite, nous apprendrons le code.
Utilisez debugla méthode pour apprendre le code.
Le premier est l'affichage de la structure du réseau : ne l'ouvrez pas facilement, ce modèle est trop compliqué. En dernière analyse, ce n’est pas que c’est compliqué, c’est juste qu’il y a trop de couches.
Net(
(conv_input): ConvLayer(
(reflection_pad): ReflectionPad2d((5, 5, 5, 5))
(conv2d): Conv2d(3, 16, kernel_size=(11, 11), stride=(1, 1))
)
(dense0): Sequential(
(0): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(1): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(2): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
)
(conv2x): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2))
)
(conv1): RDB(
(dense_layers): Sequential(
(0): make_dense(
(conv): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): make_dense(
(conv): Conv2d(32, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): make_dense(
(conv): Conv2d(48, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(3): make_dense(
(conv): Conv2d(64, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(conv_1x1): Conv2d(80, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(fusion1): Encoder_MDCBlock1(
(up_convs): ModuleList(
(0): DeconvBlock(
(deconv): ConvTranspose2d(16, 8, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
(down_convs): ModuleList(
(0): ConvBlock(
(conv): Conv2d(8, 16, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
)
(dense1): Sequential(
(0): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(1): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(2): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
)
(conv4x): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2))
)
(conv2): RDB(
(dense_layers): Sequential(
(0): make_dense(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): make_dense(
(conv): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): make_dense(
(conv): Conv2d(96, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(3): make_dense(
(conv): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(conv_1x1): Conv2d(160, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(fusion2): Encoder_MDCBlock1(
(up_convs): ModuleList(
(0): DeconvBlock(
(deconv): ConvTranspose2d(32, 16, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(1): DeconvBlock(
(deconv): ConvTranspose2d(16, 8, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
(down_convs): ModuleList(
(0): ConvBlock(
(conv): Conv2d(16, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(1): ConvBlock(
(conv): Conv2d(8, 16, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
)
(dense2): Sequential(
(0): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(1): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(2): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
)
(conv8x): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2))
)
(conv3): RDB(
(dense_layers): Sequential(
(0): make_dense(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): make_dense(
(conv): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): make_dense(
(conv): Conv2d(192, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(3): make_dense(
(conv): Conv2d(256, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(conv_1x1): Conv2d(320, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(fusion3): Encoder_MDCBlock1(
(up_convs): ModuleList(
(0): DeconvBlock(
(deconv): ConvTranspose2d(64, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(1): DeconvBlock(
(deconv): ConvTranspose2d(32, 16, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(2): DeconvBlock(
(deconv): ConvTranspose2d(16, 8, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
(down_convs): ModuleList(
(0): ConvBlock(
(conv): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(1): ConvBlock(
(conv): Conv2d(16, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(2): ConvBlock(
(conv): Conv2d(8, 16, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
)
(dense3): Sequential(
(0): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(1): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(2): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
)
(conv16x): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2))
)
(conv4): RDB(
(dense_layers): Sequential(
(0): make_dense(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): make_dense(
(conv): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): make_dense(
(conv): Conv2d(384, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(3): make_dense(
(conv): Conv2d(512, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(conv_1x1): Conv2d(640, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(fusion4): Encoder_MDCBlock1(
(up_convs): ModuleList(
(0): DeconvBlock(
(deconv): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(1): DeconvBlock(
(deconv): ConvTranspose2d(64, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(2): DeconvBlock(
(deconv): ConvTranspose2d(32, 16, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(3): DeconvBlock(
(deconv): ConvTranspose2d(16, 8, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
(down_convs): ModuleList(
(0): ConvBlock(
(conv): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(1): ConvBlock(
(conv): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(2): ConvBlock(
(conv): Conv2d(16, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(3): ConvBlock(
(conv): Conv2d(8, 16, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
)
(dehaze): Sequential(
(res0): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res1): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res2): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res3): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res4): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res5): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res6): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res7): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res8): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res9): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res10): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res11): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res12): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res13): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res14): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res15): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res16): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(res17): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
)
(convd16x): UpsampleConvLayer(
(conv2d): ConvTranspose2d(256, 128, kernel_size=(3, 3), stride=(2, 2))
)
(dense_4): Sequential(
(0): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(1): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(2): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
)
(conv_4): RDB(
(dense_layers): Sequential(
(0): make_dense(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): make_dense(
(conv): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): make_dense(
(conv): Conv2d(192, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(3): make_dense(
(conv): Conv2d(256, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(conv_1x1): Conv2d(320, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(fusion_4): Decoder_MDCBlock1(
(down_convs): ModuleList(
(0): ConvBlock(
(conv): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
(up_convs): ModuleList(
(0): DeconvBlock(
(deconv): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
)
(convd8x): UpsampleConvLayer(
(conv2d): ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(2, 2))
)
(dense_3): Sequential(
(0): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(1): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(2): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
)
(conv_3): RDB(
(dense_layers): Sequential(
(0): make_dense(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): make_dense(
(conv): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): make_dense(
(conv): Conv2d(96, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(3): make_dense(
(conv): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(conv_1x1): Conv2d(160, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(fusion_3): Decoder_MDCBlock1(
(down_convs): ModuleList(
(0): ConvBlock(
(conv): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(1): ConvBlock(
(conv): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
(up_convs): ModuleList(
(0): DeconvBlock(
(deconv): ConvTranspose2d(64, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(1): DeconvBlock(
(deconv): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
)
(convd4x): UpsampleConvLayer(
(conv2d): ConvTranspose2d(64, 32, kernel_size=(3, 3), stride=(2, 2))
)
(dense_2): Sequential(
(0): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(1): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(2): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
)
(conv_2): RDB(
(dense_layers): Sequential(
(0): make_dense(
(conv): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): make_dense(
(conv): Conv2d(32, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): make_dense(
(conv): Conv2d(48, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(3): make_dense(
(conv): Conv2d(64, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(conv_1x1): Conv2d(80, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(fusion_2): Decoder_MDCBlock1(
(down_convs): ModuleList(
(0): ConvBlock(
(conv): Conv2d(16, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(1): ConvBlock(
(conv): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(2): ConvBlock(
(conv): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
(up_convs): ModuleList(
(0): DeconvBlock(
(deconv): ConvTranspose2d(32, 16, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(1): DeconvBlock(
(deconv): ConvTranspose2d(64, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(2): DeconvBlock(
(deconv): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
)
(convd2x): UpsampleConvLayer(
(conv2d): ConvTranspose2d(32, 16, kernel_size=(3, 3), stride=(2, 2))
)
(dense_1): Sequential(
(0): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(1): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
(2): ResidualBlock(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1))
)
(relu): PReLU(num_parameters=1)
)
)
(conv_1): RDB(
(dense_layers): Sequential(
(0): make_dense(
(conv): Conv2d(8, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): make_dense(
(conv): Conv2d(16, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): make_dense(
(conv): Conv2d(24, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(3): make_dense(
(conv): Conv2d(32, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(conv_1x1): Conv2d(40, 8, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(fusion_1): Decoder_MDCBlock1(
(down_convs): ModuleList(
(0): ConvBlock(
(conv): Conv2d(8, 16, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(1): ConvBlock(
(conv): Conv2d(16, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(2): ConvBlock(
(conv): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(3): ConvBlock(
(conv): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
(up_convs): ModuleList(
(0): DeconvBlock(
(deconv): ConvTranspose2d(16, 8, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(1): DeconvBlock(
(deconv): ConvTranspose2d(32, 16, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(2): DeconvBlock(
(deconv): ConvTranspose2d(64, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
(3): DeconvBlock(
(deconv): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(act): PReLU(num_parameters=1)
)
)
)
(conv_output): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(16, 3, kernel_size=(3, 3), stride=(1, 1))
)
)
Entrez d’abord dans le mode formation, également connu sous le nom d’étape de formation à la collecte de connaissances :
def train_kc_stage(model, teacher_networks, ckt_modules, train_loader, optimizer, scheduler, epoch, criterions):
print(Fore.CYAN + "==> Training Stage 1")
print("==> Epoch {}/{}".format(epoch, args.max_epoch))
print("==> Learning Rate = {:.6f}".format(optimizer.param_groups[0]['lr']))
meters = get_meter(num_meters=5)
criterion_l1, criterion_scr, _ = criterions
model.train()
ckt_modules.train()
for teacher_network in teacher_networks:
teacher_network.eval()
En déclarant la fonction de perte requise, la structure détaillée du ckt_modelsmode de formation (modèle de transfert de connaissances collaboratif) est la suivante :
ckt_models
ModuleList(
(0): CKTModule(
(teacher_projectors): TeacherProjectors(
(PFPs): ModuleList(
(0): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(IPFPs): ModuleList(
(0): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
(student_projector): StudentProjector(
(PFP): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
(1): CKTModule(
(teacher_projectors): TeacherProjectors(
(PFPs): ModuleList(
(0): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(IPFPs): ModuleList(
(0): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
(student_projector): StudentProjector(
(PFP): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
(2): CKTModule(
(teacher_projectors): TeacherProjectors(
(PFPs): ModuleList(
(0): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(IPFPs): ModuleList(
(0): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
(student_projector): StudentProjector(
(PFP): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
(3): CKTModule(
(teacher_projectors): TeacherProjectors(
(PFPs): ModuleList(
(0): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(IPFPs): ModuleList(
(0): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
(student_projector): StudentProjector(
(PFP): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
)
La structure des critères définit la fonction de perte, qui sont L1perte, SCRperte et HCRperte.
ModuleList(
(0): L1Loss()
(1): SCRLoss(
(vgg): Vgg19(
(slice1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
)
(slice2): Sequential(
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
)
(slice3): Sequential(
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
)
(slice4): Sequential(
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): ReLU(inplace=True)
(18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
)
(slice5): Sequential(
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): ReLU(inplace=True)
(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(26): ReLU(inplace=True)
(27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
)
)
(l1): L1Loss()
)
(2): HCRLoss(
(vgg): Vgg19(
(slice1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
)
(slice2): Sequential(
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
)
(slice3): Sequential(
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
)
(slice4): Sequential(
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): ReLU(inplace=True)
(18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
)
(slice5): Sequential(
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): ReLU(inplace=True)
(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(26): ReLU(inplace=True)
(27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
)
)
(l1): L1Loss()
)
)
On peut voir que le réseau des enseignants n'est que trois copies du réseau Net précédent, juste chargé de poids différents. Cela fait trois modèles.


continuer la formation
start = time.time()
pBar = tqdm(train_loader, desc='Training')
for target_images, input_images in pBar:
# Check whether the batch contains all types of degraded data
if target_images is None: continue
# move to GPU
target_images = target_images.cuda()
input_images = [images.cuda() for images in input_images]
# Fix all teachers and collect reconstruction results and features from cooresponding teacher
preds_from_teachers = []
features_from_each_teachers = []
with torch.no_grad():
for i in range(len(teacher_networks)):
preds, features = teacher_networks[i](input_images[i], return_feat=True)
preds_from_teachers.append(preds)
features_from_each_teachers.append(features)
preds_from_teachers = torch.cat(preds_from_teachers)
features_from_teachers = []
for layer in range(len(features_from_each_teachers[0])):
features_from_teachers.append([features_from_each_teachers[i][layer] for i in range(len(teacher_networks))])
preds_from_student, features_from_student = model(torch.cat(input_images), return_feat=True)
# Project the features to common feature space and calculate the loss
PFE_loss, PFV_loss = 0., 0.
for i, (s_features, t_features) in enumerate(zip(features_from_student, features_from_teachers)):
t_proj_features, t_recons_features, s_proj_features = ckt_modules[i](t_features, s_features)
PFE_loss += criterion_l1(s_proj_features, torch.cat(t_proj_features))
PFV_loss += 0.05 * criterion_l1(torch.cat(t_recons_features), torch.cat(t_features))
T_loss = criterion_l1(preds_from_student, preds_from_teachers)
SCR_loss = 0.1 * criterion_scr(preds_from_student, target_images, torch.cat(input_images))
total_loss = T_loss + PFE_loss + PFV_loss + SCR_loss
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
Entrez dans le module d'évaluation : chargez le modèle, l'ensemble de vérification et enfin, sortez psnr et ssim.
if epoch % args.val_freq == 0:
psnr, ssim = evaluate(model, val_loader, epoch)
# Check whether the model is top-k model
top_k_state = save_top_k(model, optimizer, scheduler, top_k_state, args.top_k, epoch, args.save_dir, psnr=psnr, ssim=ssim)
evaluate(model, val_loader, epoch)Code détaillé de la fonction :

Affichez ensuite les résultats :
pred = model(image)
Autrement dit, sautez dans l'avant-plan du Net pour l'extraction de fonctionnalités.
valeur d'entrée :
Entrée x : La dimension de l'image est 640x480, à ce moment, la dimension initiale : torch.Size([1, 3, 480, 640])
Après une série de réduction de dimension de convolution, la carte de caractéristiques suivante est générée : Ce processus ne sera pas décrit en détail.
valeur de sortie :
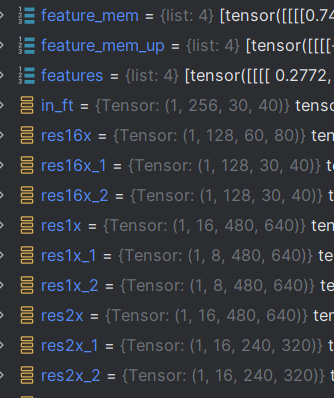
Sortie x et fonctionnalité : la dimension finale de x est toujourstorch.Size([1, 3, 480, 640])
Il existe 4 cartes de fonctionnalités dans la dimension de fonctionnalités, comme suit :
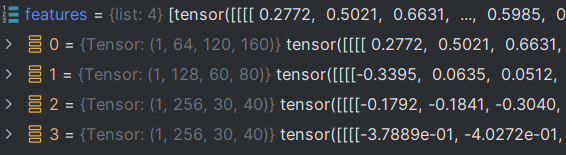
Le paramètre ici génère uniquement x, donc la valeur de pred est la valeur de x :

Après avoir obtenu la valeur de sortie, la perte peut être calculée :
psnr_list.append(torchPSNR(pred, target).item())
ssim_list.append(pytorch_ssim.ssim(pred, target).item())
Mise en œuvre:
@torch.no_grad()
def torchPSNR(prd_img, tar_img):
if not isinstance(prd_img, torch.Tensor):
prd_img = torch.from_numpy(prd_img)
tar_img = torch.from_numpy(tar_img)
imdff = torch.clamp(prd_img, 0, 1) - torch.clamp(tar_img, 0, 1)
rmse = (imdff**2).mean().sqrt()
ps = 20 * torch.log10(1/rmse)
return ps
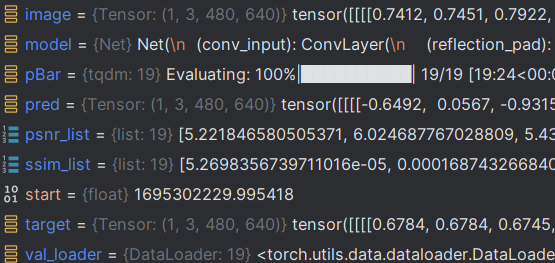
Finalement, les 19 photos ont été évaluées :

Obtenez la valeur psnr_list :

les 19 images doivent être évaluées, et seules deux sont évaluées ici.
Renvoyez enfin la valeur moyenne :
return np.mean(psnr_list), np.mean(ssim_list)
La valeur finale de cette méthode devient :