Bonjour à tous, aujourd'hui, je vais partager avec vous comment utiliser TensorFlow pour personnaliser les méthodes de baisse du taux d'apprentissage exponentiel, de baisse du taux d'apprentissage par étapes et de baisse du taux d'apprentissage en cosinus , et utiliser l'ensemble de données Mnist pour vérifier la stratégie de baisse du taux d'apprentissage personnalisée .
La méthode de classe de taux d'apprentissage personnalisée créée doit hériter de tf.keras.optimizers.schedules.LearningRateSchedule
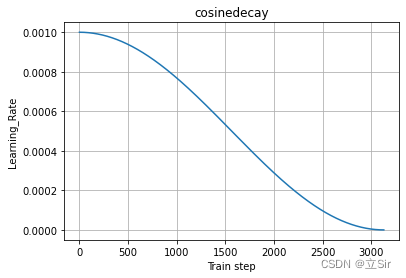
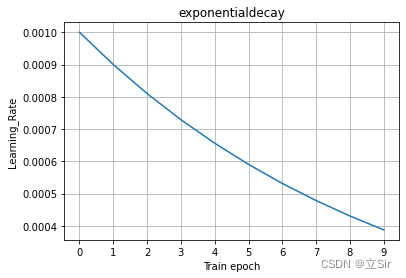
1. Chute exponentielle du taux d'apprentissage
La formule de descente exponentielle du taux d'apprentissage est la suivante :
où représente le taux d'apprentissage initial,
représente le coefficient de décroissance du taux d'apprentissage et
représente l'époque, c'est-à-dire que le taux d'apprentissage décroît une fois par itération
En prenant le taux d'apprentissage initial et le coefficient de décroissance du taux d'apprentissage
comme
exemple, la courbe de déclin exponentielle du taux d'apprentissage est illustrée dans la figure ci-dessous.
Si le pas est utilisé comme norme pour l'ajustement de l'indice, alors l'indice n est égal au pas actuel divisé par le nombre total de pas contenus dans une époque.
Ici, j'utilise l'époque comme norme pour l'ajustement de l'indice.
Créez d'abord une classe personnalisée de taux d'apprentissage qui hérite du planificateur de taux d'apprentissage personnalisé keras.optimizers.schedules.LearningRateSchedule .
Initialisez d'abord tous les attributs, où self.current renvoie le taux d'apprentissage de chaque étape pendant la formation , self.epoch représente le terme exponentiel n dans la formule de calcul du taux d'apprentissage exponentiel, et self.learning_rate_list est utilisé pour enregistrer l'apprentissage de chaque époque pendant la formation taux .
Dans la méthode __call__ , step % self.print_step , où step représente l'étape actuelle transmise pendant la formation , et print_step est le nombre d'étapes spécifié en externe pour ajuster le taux d'apprentissage et enregistre le taux d'apprentissage de l'époque actuelle, Renvoie la valeur ajustée taux d'apprentissage . Si la condition if n'est pas remplie, alors le taux d'apprentissage de ces étapes est le taux d'apprentissage après le dernier ajustement .
Le code qui utilise l'époque comme norme d'ajustement de l'indice est le suivant :
# ------------------------------------------------------------------ #
# 当前学习率 = 初始学习率 * 衰减系数 ^{迭代了多少次}
# ------------------------------------------------------------------ #
# eager模式防止graph报错
tf.config.experimental_run_functions_eagerly(True)
# ------------------------------------------------------------------ #
# 继承学习率的类
class ExponentialDecay(keras.optimizers.schedules.LearningRateSchedule):
'''
initial_lr: 初始的学习率
decay_rate: 学习率衰减系数
min_lr: 学习率下降的最小
print_step: 训练时多少个batch打印一次学习率
'''
# 初始化
def __init__(self, initial_lr, decay_rate, min_lr, print_step):
# 继承父类的初始化方法
super(ExponentialDecay, self).__init__()
# 属性分配
self.initial_lr = tf.cast(initial_lr, tf.float32)
self.decay_rate = tf.cast(decay_rate, tf.float32)
self.min_lr = tf.cast(min_lr, tf.float32)
self.print_step = print_step
# 记录记录每个epoch的学习率
self.learning_rate_list = []
# 最开始时,学习率为初始学习率
self.current = self.initial_lr
# 初始的迭代次数为0
self.epoch = 0
# 前向传播
def __call__(self, step):
# 每多少个batch调整一次学习率, 一个batch处理32张图
if step % self.print_step == 0:
# 学习率指数下降,设置为每个epoch调整一次
learning_rate = self.initial_lr * pow(self.decay_rate, self.epoch)
# 调整当前学习率, 每一轮的学习率不能低于最小学习率
self.current = tf.where(learning_rate>self.min_lr, learning_rate, self.min_lr)
# 迭代次数加一
self.epoch = self.epoch + 1
# 将当前学习率保存下来
self.learning_rate_list.append(learning_rate.numpy().item())
# 打印学习率变化
print('learning_rate:', learning_rate.numpy().item())
# 返回调整后的学习率
return self.current
# 否则就返回上一次调整的学习率
else:
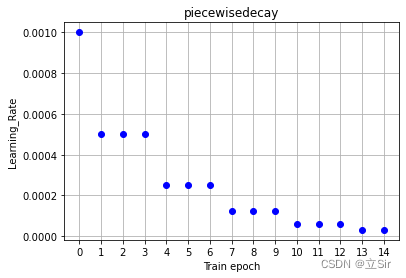
return self.current2. Baisse progressive du taux d'apprentissage
Idée : après chaque nombre d'étapes, le taux d'apprentissage chute aux temps de décroissance_rate précédents. Par exemple , le taux d'apprentissage initial est de 0,001 . Toutes les trois époques, le taux d'apprentissage est réduit à 0,5 fois l'original et la segmentation est réduite. Le diagramme schématique est le suivant :
Créez d'abord une classe personnalisée de taux d'apprentissage qui hérite du planificateur de taux d'apprentissage personnalisé keras.optimizers.schedules.LearningRateSchedule .
Terminez d'abord l'initialisation de tous les attributs, où self.change_step est défini en externe, représentant le nombre d'étapes pour ajuster le taux d'apprentissage . La méthode d'ajustement consiste à multiplier le taux d'apprentissage actuel self.current par le multiplicateur d'ajustement self.decay_rate pour obtenir le taux d'apprentissage ajusté et renvoyer le résultat. Si la condition if n'est pas remplie, c'est-à-dire que l'étape actuelle n'a pas besoin d'être ajustée, le taux d'apprentissage après le dernier ajustement sera renvoyé. Le taux d'apprentissage de chaque époque du processus de formation est enregistré dans la liste self.learning_rate_list , qui peut être lue et visualisée une fois la formation terminée.
# ------------------------------------------------------------------ #
# 自定义的分段常数下降方法
# ------------------------------------------------------------------ #
# eager模式防止graph报错
tf.config.experimental_run_functions_eagerly(True)
# ------------------------------------------------------------------ #
# 继承学习率的类
class PiecewiseConstantDecay(keras.optimizers.schedules.LearningRateSchedule):
'''
initial_lr: 初始的学习率
decay_rate: 学习率衰减系数
min_lr: 学习率下降的最小
change_step: 多少个epoch下降一次
print_step: 训练时多少个step打印一次学习率
'''
# 初始化
def __init__(self, initial_lr, decay_rate, min_lr, change_step, print_step):
# 继承父类的初始化方法
super(PiecewiseConstantDecay, self).__init__()
# 属性分配
self.initial_lr = tf.cast(initial_lr, tf.float32)
self.decay_rate = tf.cast(decay_rate, tf.float32)
self.min_lr = tf.cast(min_lr, tf.float32)
self.change_step = change_step
self.print_step = print_step
# 记录记录每个epoch的学习率
self.learning_rate_list = []
# 最开始时,学习率为初始学习率
self.current = self.initial_lr
# 前向传播
def __call__(self, step): # 这个step不是epoch
# 多少个step记录一次学习率,外部指定为一个epoch记录一次
if step % self.print_step == 0:
# 训练过程中打印每一个epoch的学习率
print('current learning_rate is ', self.current.numpy().item())
# 记录下当前epoch的学习率
self.learning_rate_list.append(self.current.numpy().item())
# 多少个step调整一次学习率
if step % self.change_step == 0:
# 计算调整后的学习率
learning_rate = self.current * self.decay_rate
# 更新当前学习率指标, 学习率不能小于指定的最小值
self.current = tf.where(learning_rate>self.min_lr, learning_rate, self.min_lr)
# 返回调整后的学习率
return self.current
# 如果为满足调整要求,就返回上一次调整的学习率
else:
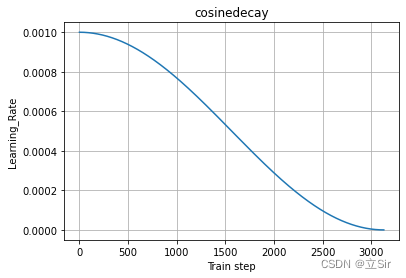
return self.current3. Baisse du taux d'apprentissage du cosinus
La formule de chute du taux d'apprentissage en cosinus est :
Parmi eux, représente le taux d'apprentissage initial,
qui fait référence au nombre actuel d'étapes, et
fait référence au nombre d'étapes après lesquelles le taux d'apprentissage décroît jusqu'à 0
En prenant le taux d'apprentissage initial de 0,001 et le taux d'apprentissage diminuant à 0 après toutes les époques, la courbe cosinus décroissante du taux d'apprentissage est la suivante :
Créez d'abord une classe personnalisée de taux d'apprentissage qui hérite du planificateur de taux d'apprentissage personnalisé keras.optimizers.schedules.LearningRateSchedule .
Terminez d'abord l'initialisation de tous les attributs, où self.current est utilisé pour enregistrer le taux d'apprentissage de l'étape actuelle , et self.learning_rate_list est utilisé pour enregistrer le taux d'apprentissage de toutes les étapes pendant la formation, qui peut être appelé pour afficher après la formation.
Pendant la formation, le modèle passera à l'étape en cours, ajustera le taux d'apprentissage learning_rate de chaque étape et exigera que le taux d'apprentissage ajusté ne puisse pas être inférieur au taux d'apprentissage minimum self.min_lr. Utilisez la fonction tf.where() pour comparer le taux d'apprentissage ajusté et le taux d'apprentissage minimum, sélectionnez le taux d'apprentissage le plus élevé comme résultat renvoyé.
# ------------------------------------------------------------------ #
# 余弦学习率下降
# ------------------------------------------------------------------ #
# eager模式防止graph报错
tf.config.experimental_run_functions_eagerly(True)
# ------------------------------------------------------------------ #
# 继承学习率的类
class CosineDecay(keras.optimizers.schedules.LearningRateSchedule):
'''
initial_lr: 初始的学习率
decay_rate: 学习率衰减到最低点的步长
min_lr: 学习率下降的最小
print_step: 训练时多少个step打印一次学习率
'''
# 初始化
def __init__(self, initial_lr, decay_step, min_lr, print_step):
# 继承父类初始化方法
super(CosineDecay, self).__init__()
# 属性分配
self.initial_lr = tf.cast(initial_lr, dtype=tf.float32)
self.decay_step = tf.cast(decay_step, dtype=tf.float32)
self.min_lr = tf.cast(min_lr, dtype=tf.float32)
self.print_step = print_step
# 最开始的当前学习率等于初始学习率
self.current = self.initial_lr
# 记录每个epoch的学习率值
self.learning_rate_list = []
# 前向传播
def __call__(self, step):
# 余弦衰减计算公式
learning_rate = 0.5 * self.initial_lr * (1 + tf.math.cos(step*math.pi / self.decay_step))
# 更新当前学习率指标, 学习率不能小于指定的最小值
self.current = tf.where(learning_rate>self.min_lr, learning_rate, self.min_lr)
# 记录每个step的学习率
self.learning_rate_list.append(self.current.numpy().item())
# 多少个step打印一次学习率,外部设置每个epoch打印一次学习率
if step % self.print_step == 0:
# 在训练时打印当前学习率
print('learning_rate has changed to: ', self.current.numpy().item())
return self.current4. Vérification expérimentale
Ici, nous prenons la stratégie de désintégration du cosinus du taux d'apprentissage comme exemple pour vérifier si la méthode du taux d'apprentissage définie ci-dessus peut être utilisée.
Les parties de prétraitement des données et de construction du modèle ne sont pas couvertes, qui sont très basiques. Voir la section (6) directement sur la formation du modèle .
Tout d'abord, nous devons instancier la classe CosineDecay avec la baisse du taux d'apprentissage que nous avons définie, passer le taux d'apprentissage initial initial_lr requis dans la formule de calcul, la taille de pas decay_step requise pour que la valeur du cosinus tombe à 0 , et le recevoir avec la variable cosinedécroissance.
Transmettez la méthode de décroissance du taux d'apprentissage personnalisé à l'optimiseur Adam , afin que chaque étape transmise par le modèle puisse être reçue pendant la formation et utilisée pour calculer la décroissance.
Les méthodes personnalisées peuvent également faire référence à la documentation officielle : Custom Learning Rate Scheduling
En prenant comme exemple le problème de classification de l'image 10 de l'ensemble de données d'écriture manuscrite Mnist, le code complet est le suivant :
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
import math
# 调用GPU加速
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
# ------------------------------------------------------------------ #
# (1)读取手写数字数据集
# ------------------------------------------------------------------ #
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
print('x_train.shape:', x_train.shape, 'y_train.shape:', y_train.shape) # (60000, 28, 28) , (60000,)
print('x_test.shape:', x_test.shape) # (10000, 28, 28)
# 记录一共训练多少张图
total_train_num = x_train.shape[0]
# ------------------------------------------------------------------ #
# (2)余弦学习率下降
# ------------------------------------------------------------------ #
# eager模式防止graph报错
tf.config.experimental_run_functions_eagerly(True)
# ------------------------------------------------------------------ #
# 继承学习率的类
class CosineDecay(keras.optimizers.schedules.LearningRateSchedule):
'''
initial_lr: 初始的学习率
decay_rate: 学习率衰减到最低点的步长
min_lr: 学习率下降的最小
print_step: 训练时多少个step打印一次学习率
'''
# 初始化
def __init__(self, initial_lr, decay_step, min_lr, print_step):
# 继承父类初始化方法
super(CosineDecay, self).__init__()
# 属性分配
self.initial_lr = tf.cast(initial_lr, dtype=tf.float32)
self.decay_step = tf.cast(decay_step, dtype=tf.float32)
self.min_lr = tf.cast(min_lr, dtype=tf.float32)
self.print_step = print_step
# 最开始的当前学习率等于初始学习率
self.current = self.initial_lr
# 记录每个epoch的学习率值
self.learning_rate_list = []
# 前向传播
def __call__(self, step):
# 余弦衰减计算公式
learning_rate = 0.5 * self.initial_lr * (1 + tf.math.cos(step*math.pi / self.decay_step))
# 更新当前学习率指标, 学习率不能小于指定的最小值
self.current = tf.where(learning_rate>self.min_lr, learning_rate, self.min_lr)
# 记录每个step的学习率
self.learning_rate_list.append(self.current.numpy().item())
# 多少个step打印一次学习率,外部设置每个epoch打印一次学习率
if step % self.print_step == 0:
# 在训练时打印当前学习率
print('learning_rate has changed to: ', self.current.numpy().item())
return self.current
# ------------------------------------------------------------------ #
# (3)参数设置
# ------------------------------------------------------------------ #
# 每个step处理32张图
batch_size = 32
# 迭代次数
num_epochs = 10
# 初始学习率
initial_lr = 0.001
# 学习率衰减系数
decay_rate = 0.9
# 学习率下降的最小值
min_lr = 0
# 每个epoch打印一次学习率, 1个batch处理32张图
# 共60000张图,需要60000/32个batch,即1875个step
print_step = total_train_num / batch_size
# 余弦下降到0所需的步长
decay_step = total_train_num / batch_size * num_epochs
# ------------------------------------------------------------------ #
# (4)构造数据集
# ------------------------------------------------------------------ #
def processing(x,y): # 预处理函数
x = 2 * tf.cast(x, dtype=tf.float32)/255.0 - 1 # 归一化
x = tf.expand_dims(x, axis=-1) # 增加通道维度
y = tf.cast(y, dtype=tf.int32)
return x,y
# 构造训练集
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_ds = train_ds.map(processing).batch(batch_size).shuffle(10000)
# 构造测试集
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_ds = test_ds.map(processing).batch(batch_size)
# 迭代器查看数据是否正确
sample = next(iter(train_ds))
print('x_batch:', sample[0].shape, 'y_batch:', sample[1].shape) # (32, 28, 28, 1), (32,)
# ------------------------------------------------------------------ #
# (5)构造模型
# ------------------------------------------------------------------ #
inputs = keras.Input(sample[0].shape[1:]) # 构造输入层
# [28,28,1]==>[28,28,32]
x = layers.Conv2D(32, kernel_size=3, padding='same', activation='relu')(inputs)
# [28,28,32]==>[14,14,32]
x = layers.MaxPool2D(pool_size=(2,2), strides=2, padding='same')(x)
# [14,14,32]==>[14,14,64]
x = layers.Conv2D(64, kernel_size=3, padding='same', activation='relu')(x)
# [14,14,64]==>[7,7,64]
x = layers.MaxPool2D(pool_size=(2,2), strides=2, padding='same')(x)
# [7,7,64]==>[None,7*7*64]
x = layers.Flatten()(x)
# [None,7*7*64]==>[None,128]
x = layers.Dense(128)(x)
# [None,128]==>[None,10]
outputs = layers.Dense(10, activation='softmax')(x)
# 构建模型
model = keras.Model(inputs, outputs)
# 查看模型结构
model.summary()
# ------------------------------------------------------------------ #
# (6)模型训练
# ------------------------------------------------------------------ #
# 接收学习率调整方法
cosinedecay = CosineDecay(initial_lr=initial_lr, # 初始学习率
decay_step=decay_step, # 学习率衰减系数
min_lr=min_lr, # 最小学习率值
print_step=print_step) # 每个epoch打印一次学习率值
# 设置adam优化器,指定学习率
opt = keras.optimizers.Adam(cosinedecay)
# 网络编译
model.compile(optimizer=opt, # 学习率
loss='sparse_categorical_crossentropy', # 损失
metrics=['accuracy']) # 监控指标
# 网络训练
model.fit(train_ds, epochs=num_epochs, validation_data=test_ds)
# 绘制学习率变化曲线
plt.plot(range(decay_step), cosinedecay.learning_rate_list)
plt.xlabel("Train step")
plt.ylabel("Learning_Rate")
plt.title('cosinedecay')
plt.grid()
plt.show()Imprimez le processus de formation, vous pouvez voir que chaque époque imprime le taux d'apprentissage actuel
Epoch 1/10
learning_rate has changed to: 0.0010000000474974513
313/313 [==============================] - 6s 19ms/step - loss: 0.6491 - accuracy: 0.7977 - val_loss: 0.0725 - val_accuracy: 0.9783
Epoch 2/10
learning_rate has changed to: 0.0009755282662808895
313/313 [==============================] - 6s 18ms/step - loss: 0.0673 - accuracy: 0.9793 - val_loss: 0.0278 - val_accuracy: 0.9911
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Epoch 9/10
learning_rate has changed to: 9.54914721660316e-05
313/313 [==============================] - 6s 18ms/step - loss: 8.1648e-04 - accuracy: 1.0000 - val_loss: 7.3570e-04 - val_accuracy: 1.0000
Epoch 10/10
learning_rate has changed to: 2.4471701181028038e-05
313/313 [==============================] - 6s 19ms/step - loss: 8.0403e-04 - accuracy: 1.0000 - val_loss: 7.2831e-04 - val_accuracy: 1.0000Dessinez la courbe du taux d'apprentissage, le taux d'apprentissage de chaque époque est stocké dans la liste self.learning_rate_list et la liste est appelée via cosinedecay.learning_rate_list