论文题目:《BLOOM: A 176B-Parameter Open-Access Multilingual Language Model》
论文链接:https://arxiv.org/abs/2211.05100
github链接:https://github.com/huggingface/transformers-bloom-inference/tree/main
huggingface链接:https://huggingface.co/bigscience/bloom
1 Introdução do modelo
Os modelos de linguagem pré-treinados tornaram-se a base dos pipelines modernos de processamento de linguagem natural porque produzem melhores resultados em pequenas quantidades de dados rotulados. Com o desenvolvimento de ELMo, ULMFiT, GPT e BERT, o paradigma de ajuste fino em tarefas downstream usando modelos pré-treinados é amplamente utilizado. A utilidade do modelo de linguagem pré-treinado foi posteriormente encontrada para realizar tarefas úteis sem qualquer treinamento adicional. Além disso, a observação empírica de que o desempenho dos modelos de linguagem aumenta (às vezes previsivelmente, às vezes abruptamente) com modelos maiores também leva a uma tendência a tamanhos de modelo cada vez maiores. Independentemente do ambiente, o custo de treinamento de um modelo de linguagem grande (LLM) só pode ser suportado por organizações ricas em recursos. Além disso, até o final, a maioria dos LLMs não foi lançada publicamente. Consequentemente, a maior parte da comunidade de pesquisa foi excluída do desenvolvimento de LLMs. Isso tem consequências concretas por não publicar publicamente: por exemplo, a maioria dos LLMs são treinados principalmente em textos em inglês.
Para abordar essas questões, propomos BigScience Large Open-science Open-access Multilingual Language Model (BLOOM). O BLOOM é um modelo de linguagem de 176 bilhões de parâmetros treinado em 46 linguagens naturais e 13 linguagens de programação, desenvolvido e publicado por centenas de pesquisadores. O poder de computação usado para treinar o BLOOM é das concessões públicas francesas GENCI e IDRIS, fazendo uso do supercomputador Jean Zay no IDRIS. Para construir o BLOOM, cada componente é projetado em detalhes, incluindo dados de treinamento, arquitetura de modelo e objetivos de treinamento e estratégias de engenharia para aprendizado distribuído. Também realizamos uma análise da capacidade do modelo. Nosso objetivo geral não é apenas lançar publicamente um modelo de linguagem multilíngue em larga escala comparável a sistemas desenvolvidos recentemente, mas também documentar o processo de coordenação em seu desenvolvimento.
2 Conjunto de dados e treinamento BLOOM
2.1. Big Science
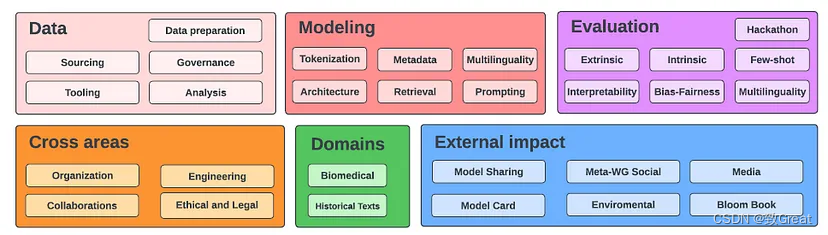
- O desenvolvimento do BLOOM é feito pela BigScience, uma colaboração de pesquisa aberta cujo objetivo é divulgar publicamente o LLM.
- Mais de 1.200 pessoas se registraram como participantes do BigScience
2.2 Corpo de Treinamento
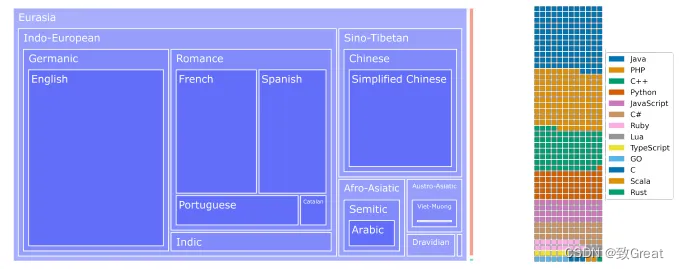
- A motivação para o corpus ROOTS acima é construir um modelo de linguagem que seja acessível ao maior número possível de pessoas no mundo e em uma escala comparável a esforços anteriores.
- Esquerda: Dendrogramas linguísticos para todas as 46 línguas naturais, onde a área da superfície é proporcional ao número de bytes. Indo-europeus e sino-tibetanos ocupam a maior parte com uma capacidade total de 1321,89 GB. A fina superfície laranja representa 18 GB de dados da Bahasa Indonésia e o retângulo verde de 0,4 GB constitui o subconjunto Níger-Congo.
- Direita: Um gráfico de waffle de 13 linguagens de programação por número de arquivos, com um quadrado representando aproximadamente 30.000 arquivos.
2.3 xP3: conjunto de dados solicitado

- O ajuste fino sugerido por várias tarefas (também conhecido como ajuste de instrução) envolve o ajuste fino de um modelo de linguagem pré-treinado em uma mistura de treinamento que consiste em um grande número de tarefas diferentes especificadas por meio de dicas de linguagem natural.
- O conjunto de dados P3 original é estendido para incluir novos conjuntos de dados para outros idiomas além do inglês e novas tarefas, como tradução. Isso leva ao xP3, uma coleção de sugestões em 83 conjuntos de dados que abrangem 46 idiomas e 16 tarefas.
Após o pré-treinamento do BLOOM, o método de ajuste fino multitarefa em larga escala é aplicado para fazer com que o BLOOM tenha a capacidade de generalização de tarefas multilíngues de disparo zero, e o modelo resultante é o BLOOMZ.
3 Estrutura e treinamento do modelo BLOOM
3.1 Estrutura do modelo
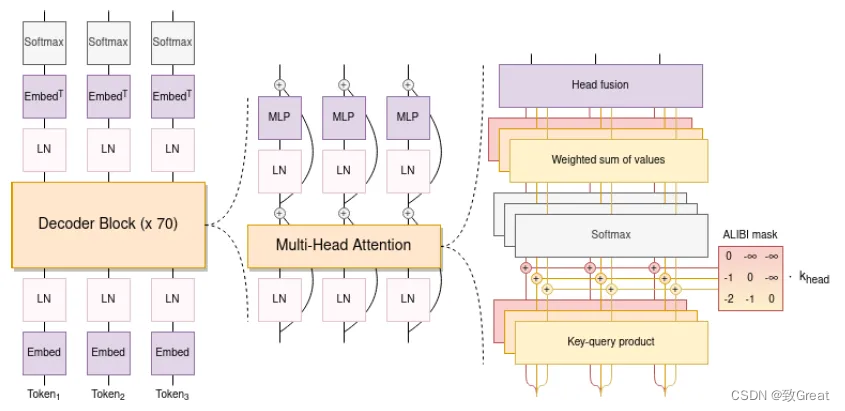
-
Os modelos de transformadores que usam decodificadores causais têm dois desvios de arquitetura.
-
Usando incorporações posicionais ALiBi, que decaem diretamente as pontuações de atenção de acordo com a distância das chaves e consultas. Comparado com a incorporação original do Transformer e Rotary, pode levar a um treinamento mais suave e melhor desempenho a jusante. O ALiBi não adiciona incorporações posicionais às incorporações de palavras; em vez disso, ele direciona as pontuações de atenção para as chaves de consulta usando uma penalidade proporcional à sua distância.
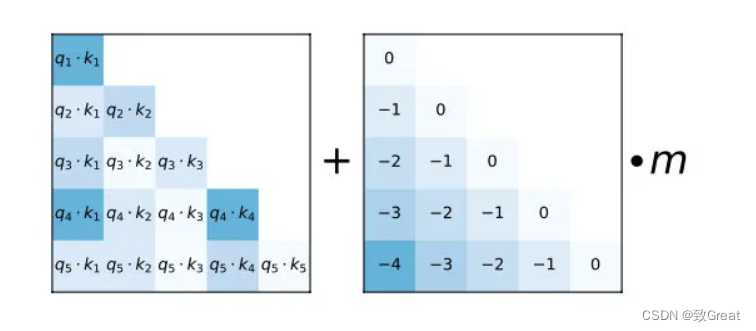
Conforme mostrado na figura, basta adicionar uma matriz de deslocamento predefinida à pontuação de atenção, o que equivale a adicionar um deslocamento de -1 quando a diferença de posição relativa entre q e k é 1. De fato, é equivalente a supor que quanto maior a distância entre dois tokens, menor será a contribuição mútua.
Claro, não basta apenas adicionar esta matriz diretamente, ou adicionar vários conjuntos de bias no T5 Bias. A matriz de bias principal é a mesma, a única diferença é o coeficiente m próximo a ela, que pode ser considerado como um declive (Slope).
O coeficiente m no artigo também é predefinido. O autor definirá um conjunto de coeficientes m de acordo com o número de caras, especificamente de acordo com a diferença de índice entre o número de caras n e n. Por exemplo, se houver 8 caras, então pode ser definido como treinamento M., mas os autores descobriram que o treinamento não trouxe consigo as melhores propriedades. Artigo: https://arxiv.org/pdf/2108.12409.pdf -
A norma de camada de incorporação é usada imediatamente após a primeira camada de incorporação para evitar treinamento instável.
-
Um vocabulário de 250.000 tokens é usado. Use BPE em nível de byte. Dessa forma, a tokenização nunca produz tokens desconhecidos
3.2 Realização do projeto
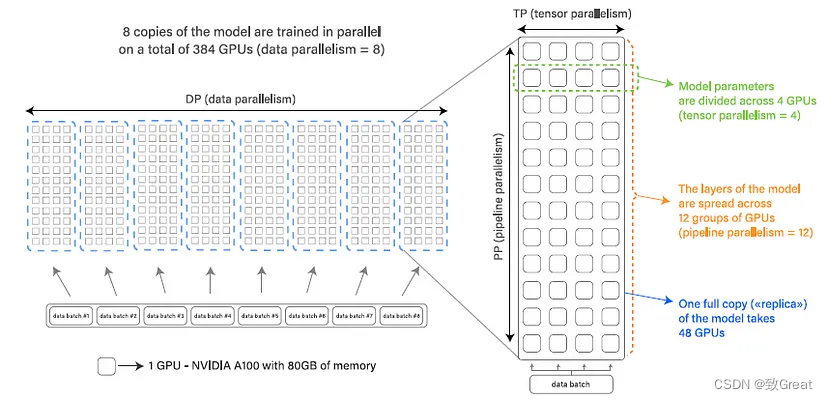
- O BLOOM usa Megatron-DeepSpeed para treinamento, que consiste em duas partes: Megatron-LM fornece implementação de Transformer, paralelismo de tensor e primitivas de carregamento de dados, enquanto DeepSpeed fornece otimizador ZeRO, pipeline de modelo e componentes gerais de treinamento distribuído.
- Data Parallelism (DP) Modelo de várias cópias, cada cópia colocada em um dispositivo diferente e servindo uma parte dos dados. O processamento é feito em paralelo e todas as cópias do modelo são sincronizadas ao final de cada etapa de treinamento.
- O paralelismo de tensor (TP) particiona as camadas de um modelo em vários dispositivos. Dessa forma, em vez de residir toda a ativação ou tensor de gradiente em uma única GPU, fragmentos desse tensor são colocados em GPUs separadas.
- O paralelismo de pipeline (PP) divide as camadas do modelo em várias GPUs, portanto, apenas uma fração das camadas do modelo é colocada em cada GPU.
Use a precisão mista bfloat16. Use kernels CUDA fundidos.
3.3 Variantes do modelo
- Variantes de modelo para seis quantidades de parâmetros

- O BLOOM consome um pouco mais de energia do que o OPT, mas o BLOOM emite cerca de 2/3 menos (25 toneladas vs. 70 toneladas). Isso se deve à baixa intensidade de carbono da matriz energética utilizada para treinar o BLOOM
, que emite 57 gCO2eq/kWh.
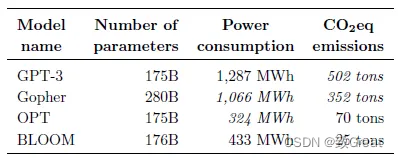
- Tanto o BLOOM quanto o OPT produzem significativamente menos emissões de carbono do que o GPT-3, o que pode ser atribuído a vários fatores, incluindo hardware mais eficiente e fontes de energia menos intensivas em carbono.
3.4 Aprendizagem rápida

As dicas foram desenvolvidas antes do lançamento do BLOOM e não foram melhoradas a priori, exemplificando alguns exemplos de dicas para tradução automática (MT).
4 resultados experimentais
4.1 Capacidades de Amostra Zero
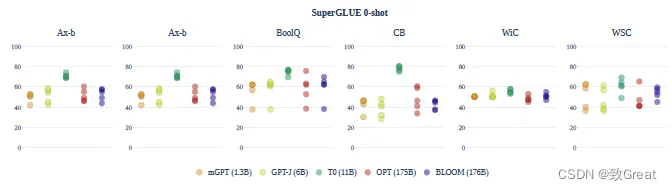
O desempenho médio nas pistas sempre gira em torno do acaso. A exceção é o modelo T0, que apresenta forte desempenho. No entanto, o modelo foi ajustado em uma configuração multitarefa e não pode ser comparado diretamente.
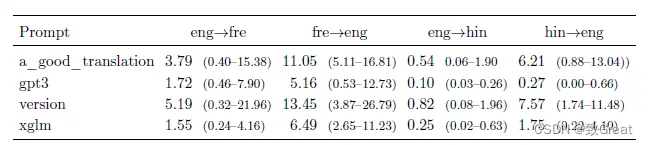
Na configuração de tiro zero, os resultados de MT geralmente são ruins. Os dois principais problemas observados são (i) excesso de geração e (ii) subprodução de linguagem correta.
4.2 efeito de 1 tiro
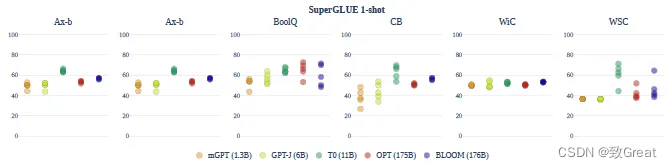
A variabilidade de desempenho única do SuperGLUE é reduzida em todos os prompts e modelos.
No geral, a configuração oneshot não melhora significativamente: a precisão média do modelo ainda é quase sempre aleatória.
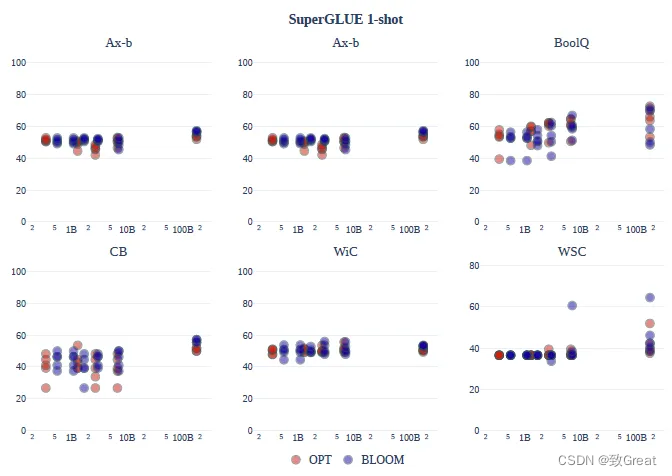
As famílias de modelos OPT e BLOOM melhoraram ligeiramente com o aumento do tamanho e não houve diferenças consistentes entre as famílias em todas as tarefas. BLOOM-176B supera OPT-175B em Ax-b, CB e WiC.

A qualidade da tradução para muitos idiomas de poucos recursos é comparável ou até um pouco melhor do que os modelos M2M supervisionados.
4.3 Resumo do texto
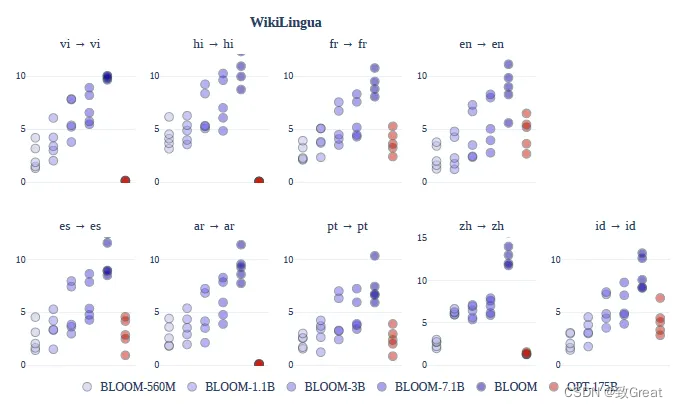
O BLOOM atinge um desempenho superior ao OPT na sumarização multilíngue, e o desempenho aumenta com o número de parâmetros do modelo.
4.4 Ajuste fino multitarefa
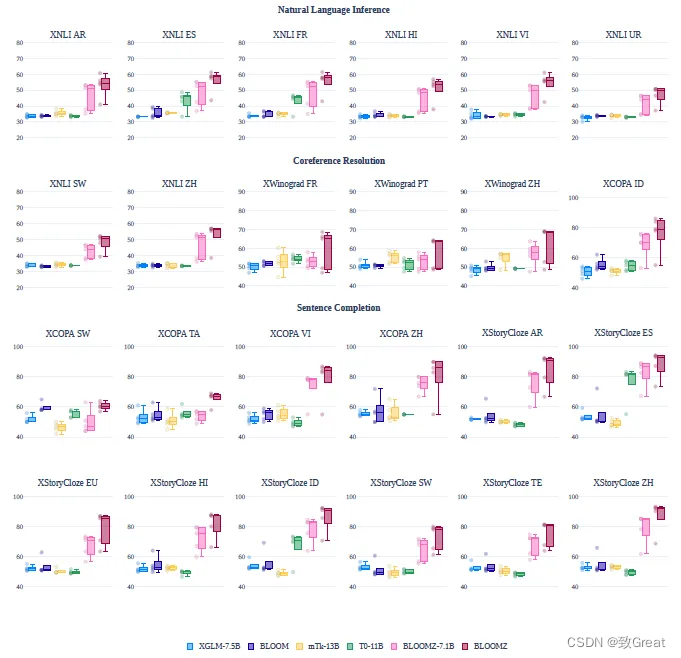
Multilingual Multi-Task Fine-tuning, ou BLOOMZ, é usado para melhorar o desempenho zero-shot dos modelos BLOOM.
4.5 Geração de código
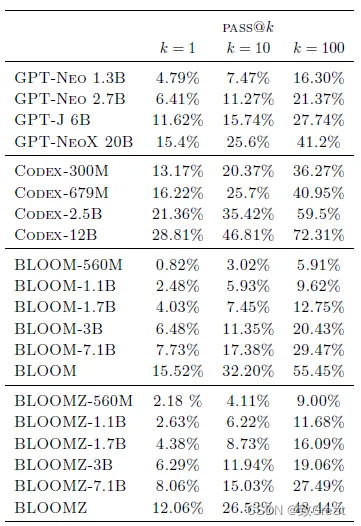
O desempenho do modelo BLOOM pré-treinado é semelhante ao de um modelo GPT de tamanho semelhante treinado em Pile.
No entanto, o modelo Codex ajustado apenas no código é muito mais forte do que os outros modelos.
5 resumo
- O BLOOM melhora principalmente a capacidade multilíngue do LLM
- O AIBI e a normalização de camada usados no método de otimização são semelhantes a outros modelos