Endereço do artigo: https://arxiv.org/pdf/2211.05100.pdf
Blog relacionado
[Processamento de linguagem natural] [Modelo grande] Estrutura do modelo BLOOM Análise de código-fonte (versão autônoma)
[Processamento de linguagem natural] [Modelo grande] Ajuste fino de recursos muito baixos Método de modelo grande LoRA e código de implementação BLOOM-LORA
[Processamento de linguagem natural ] [Big Model] Grande modelo da DeepMind Gopher
[Natural Language Processing] [Large Model] Chinchilla: um grande modelo de linguagem com treinamento e utilização de computação ideais
[Natural Language Processing] [Large Model] Grande modelo de linguagem BLOOM teste de ferramenta de raciocínio
[Natural Language Processing ] [Modelo grande] GLM-130B: um modelo de linguagem pré-treinada bilíngue de código aberto
[Processamento de linguagem natural] [Modelo grande] Introdução à multiplicação de matrizes de 8 bits para grandes transformadores
[Processamento de linguagem natural] [Modelo grande] BLOOM: um 176B parâmetro e pode Modelo multilíngue de acesso aberto
[Processamento de linguagem natural] [Modelo grande] PaLM: Um modelo de linguagem grande baseado em Pathways
[Processamento de linguagem natural] [série chatGPT] Modelos de linguagem grandes podem se aprimorar
[Processamento de linguagem natural] [série ChatGPT] WebGPT: baseado em perguntas e respostas assistidas por navegador com feedback humano
[Processamento de linguagem natural] [Série ChatGPT] FLAN: O ajuste fino do modelo de linguagem é um aprendizado zero-shot
[Processamento de linguagem natural] [Série ChatGPT] De onde vem a inteligência do ChatGPT de?
[Processamento de Linguagem Natural] [Série ChatGPT] Emergência de Grandes Modelos
1. Introdução
Os modelos de linguagem pré-treinados tornaram-se a base dos pipelines modernos de processamento de linguagem natural porque produzem melhores resultados em pequenas quantidades de dados rotulados. Com o desenvolvimento de ELMo, ULMFiT, GPT e BERT, o paradigma de ajuste fino em tarefas downstream usando modelos pré-treinados é amplamente utilizado. Posteriormente, descobriu-se a utilidade do modelo de linguagem pré-treinado para realizar tarefas úteis sem qualquer treinamento adicional. Além disso, a observação empírica de que o desempenho dos modelos de linguagem aumenta (às vezes de forma previsível, às vezes abruptamente) com modelos maiores também leva a uma tendência para tamanhos de modelo cada vez maiores. Independentemente do ambiente, o custo de formação de um modelo linguístico de grande dimensão (LLM) só pode ser suportado por organizações ricas em recursos. Além disso, até o final, a maioria dos LLMs não foram divulgados publicamente. Consequentemente, a maior parte da comunidade científica foi excluída do desenvolvimento de LLMs. Isto tem consequências concretas para a não publicação pública: por exemplo, a maioria dos LLMs são treinados principalmente em textos em inglês.
Para resolver esses problemas, propomos o BigScience Large Open-science Open-access Multilingual Language Model (BLOOM). BLOOM é um modelo de linguagem de 176 bilhões de parâmetros treinado em 46 linguagens naturais e 13 linguagens de programação, desenvolvido e publicado por centenas de pesquisadores. O poder computacional utilizado para treinar o BLOOM vem das bolsas públicas francesas GENCI e IDRIS, fazendo uso do supercomputador Jean Zay do IDRIS. Para construir o BLOOM, cada componente é projetado detalhadamente, incluindo dados de treinamento, arquitetura de modelo e objetivos de treinamento, além de estratégias de engenharia para aprendizagem distribuída. Também realizamos uma análise da capacidade do modelo. O nosso objectivo geral não é apenas divulgar publicamente um modelo linguístico multilingue em grande escala comparável aos sistemas recentemente desenvolvidos, mas também documentar o processo de coordenação no seu desenvolvimento.
2. FLOR
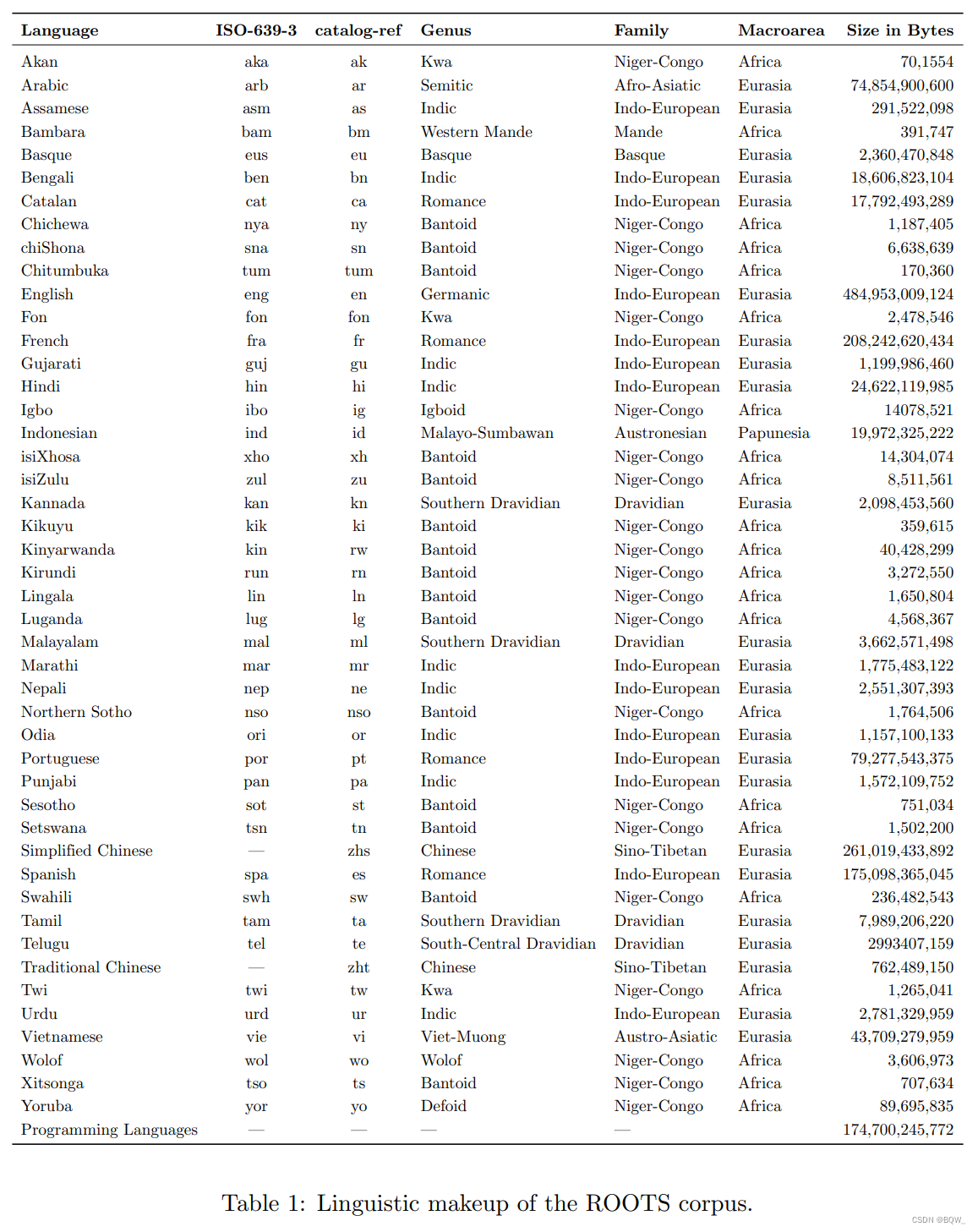
1. Dados de treinamento
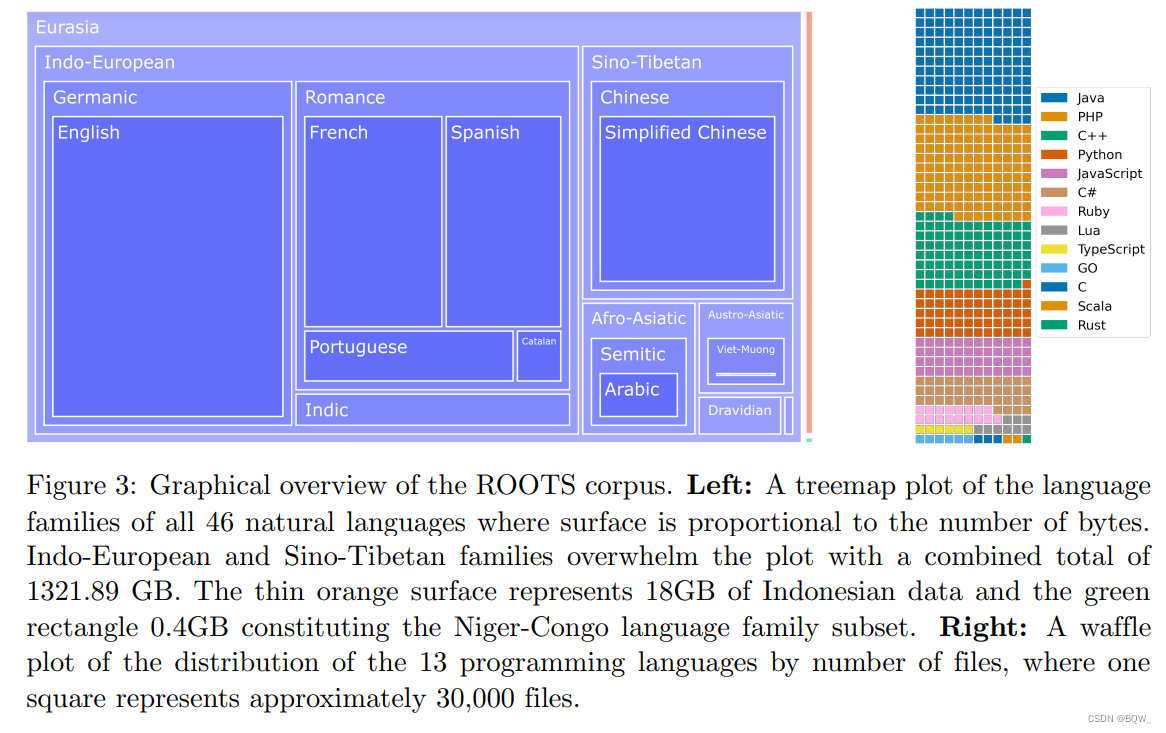
O BLOOM é treinado em um corpus chamado ROOTS, que é um corpus que consiste em 498 conjuntos de dados Hugging Face. Um total de 1,61 TB de texto, incluindo 46 linguagens naturais e 13 linguagens de programação. A Figura 3 acima mostra uma visão geral de alto nível do conjunto de dados, enquanto a Tabela 1 acima detalha cada língua e seu gênero, família linguística e macrorregião. Além da produção do corpus, o processo também resultou no desenvolvimento e divulgação de diversas ferramentas organizacionais e técnicas.
1.1 Gerenciamento de dados
Grandes corpora de texto são criados por e sobre pessoas. Diferentes pessoas ou instituições podem possuir “legalmente” os dados, o que é chamado de propriedade dos dados. À medida que os desenvolvedores de aprendizagem automática coletam e organizam esses dados em conjuntos de dados cada vez maiores, é cada vez mais importante considerar as partes interessadas envolvidas no desenvolvimento de dados, incluindo: desenvolvedores, titulares de dados e titulares de direitos.
BigScience visa resolver esses problemas combinando conhecimentos multidisciplinares, como tecnologia, direito e sociologia. A organização concentra-se em dois objetivos principais em dois prazos diferentes: projetar uma estrutura internacional de governança de dados de longo prazo que priorize os detentores de direitos de dados e fornecer recomendações específicas para dados usados diretamente por projetos BigScience. O progresso em direção ao primeiro objetivo Jernite et al.é mostrado no trabalho, que motiva ainda mais a necessidade de governança de dados e descreve uma rede de custodiantes de dados, titulares de direitos e outros atores. As interações desses atores são projetadas para considerar dados e privacidade algorítmica, propriedade intelectual e direitos do usuário. Em particular, esta abordagem baseia-se num acordo estruturado entre o fornecedor de dados e o anfitrião dos dados, especificando a finalidade dos dados.
Embora tenha sido impossível estabelecer uma organização internacional completa no período relativamente curto de tempo desde o início do projeto até o treinamento do modelo, também trabalhamos duro para aprender lições deste processo: (1) BigScience tentará obter uma utilização clara dos dados a partir da licença dos fornecedores de dados; (2) manter a independência de fonte única e manter a rastreabilidade até à fase final de pré-processamento. (3) Adotar um método de publicação combinado para cada fonte de dados que constitui todo o corpus, promovendo assim a reutilização e posterior investigação. O recurso do corpus ROOTS pode ser acessado e visualizado na organização "BigScience Data" da Hugging Face.
1.2 Fontes de dados
Após determinar a estratégia de gerenciamento de dados, o próximo passo é determinar a composição da linguagem de treinamento. Esta fase é impulsionada por vários objetivos, que estão inerentemente em conflito. Esses conflitos de memória incluem: construir um modelo de linguagem que seja acessível ao maior número possível de pessoas no mundo, ao mesmo tempo que requer conhecimento suficiente da linguagem para gerenciar conjuntos de dados comparáveis em tamanho aos anteriores para melhorar a documentação padrão, e seguir o corpo de dados e algoritmos corretos.
-
escolha do idioma
Com base nessas considerações, adotamos uma abordagem incremental para selecionar as línguas incluídas no corpus. Comece listando os 8 idiomas mais falados no mundo, promovendo ativamente esses idiomas no início do projeto e convidando falantes fluentes desse idioma para se juntarem ao projeto. Em seguida, o suaíli na seleção original foi estendido à categoria de línguas Níger-Congo, e o hindi e o urdu foram estendidos às línguas indianas, conforme sugerido pela comunidade. Em última análise, propomos que se um idioma tiver mais de 3 falantes fluentes participantes, ele possa ser adicionado à lista de apoio.
-
seleção de fonte
A maior parte do corpus foi curada por participantes do workshop e equipes de pesquisa, que escreveram em conjunto o "Catálogo BigScience": uma lista que abrange várias linguagens processadas e não processadas. Isso assume a forma de hackathons organizados por comunidades como Machine Learning Tokyo, Masakhane e LatinX in AI. Além destas fontes, outros participantes do grupo de trabalho compilaram recursos específicos de idiomas, como o repositório Masader, com foco em árabe. Esta abordagem ascendente identificou um total de 252 fontes, com pelo menos 21 fontes por língua. Além disso, para aumentar a cobertura geográfica dos recursos em espanhol, chinês, francês e inglês, os participantes identificaram URLs localmente relevantes para os idiomas que foram adicionados ao corpus por meio de pseudocrawl.
-
Código GitHub
Os conjuntos de dados da linguagem de programação neste diretório são complementados pelos conjuntos de dados do GitHub no BigQuer do Google e, em seguida, desduplicados usando correspondência exata.
-
OSCAR
Para não nos desviarmos da pesquisa padrão usando páginas da web como fonte de dados de pré-treinamento e para atender aos requisitos de volume de dados dos custos de cálculo do tamanho do BLOOM, usamos ainda o OSCAR versão 21.09 como fonte de dados, correspondendo ao instantâneo do Common Crawl em fevereiro de 2021, que ocupa 38% do corpus final.
1.3 Pré-processamento de dados
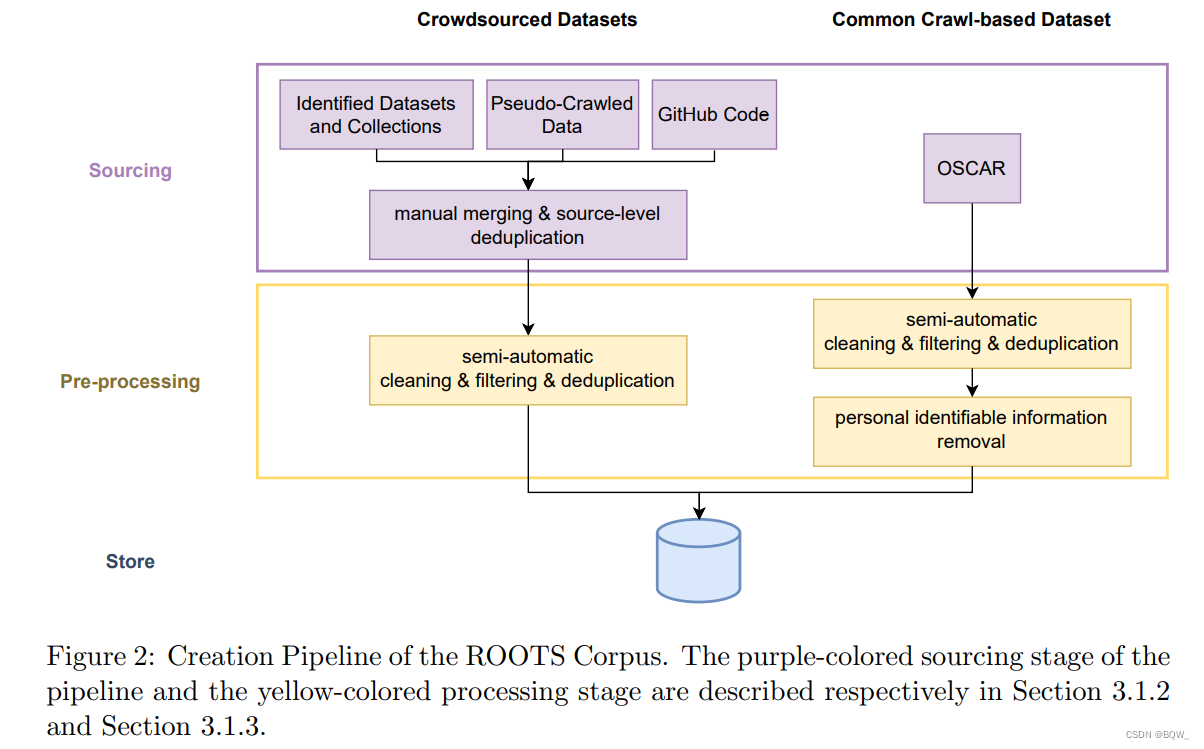
Depois de identificar a fonte de dados, o processamento de dados envolve várias etapas de gerenciamento de dados. Na Figura 2 acima você pode ver a visão geral do pipeline para construção do ROOTS. Todas as ferramentas desenvolvidas durante este processo estão disponíveis no GitHub.
-
obter dados de origem
A primeira etapa envolveu a obtenção de dados de texto de fontes de dados identificadas, o que incluiu o download e a extração de campos de texto de conjuntos de dados de PNL em vários formatos, a extração e o processamento de um grande número de arquivos PDF de arquivos, 192 sites de um catálogo O texto foi extraído e pré-processado de um adicionais 456 locais geograficamente diversos selecionados por membros do Grupo de Trabalho de Itens e Dados. Este último exigiu o desenvolvimento de novas ferramentas para extrair texto de HTML em arquivos Common Crawl WARC. Conseguimos localizar e extrair dados utilizáveis de todos os URLs em 539 redes.
-
filtro de qualidade
Depois de obter o texto, descobrimos que a maioria das fontes continha uma grande quantidade de linguagem não natural, como erros de pré-processamento, páginas de SEO ou lixo. Para filtrar a linguagem não natural, definimos um conjunto de métricas de qualidade, onde texto de alta qualidade é definido como “escrito por humanos para humanos”, sem distinguir julgamentos a priori sobre conteúdo ou gramática. É importante ressaltar que essas métricas são adaptadas às necessidades de cada fonte de duas maneiras principais. Primeiro, seus parâmetros, como limites e listas de itens suportados, são escolhidos individualmente por falantes fluentes de cada idioma. Em segundo lugar, primeiro examinamos cada fonte individual para determinar quais métricas têm maior probabilidade de identificar linguagem não natural. Ambos os processos são apoiados por ferramentas para visualizar o impacto.
-
Desduplicação e privacidade
Por fim, usamos duas etapas de iteração para remover documentos quase duplicados e redigir informações de identificação pessoal identificadas no corpus OSCAR. Por ser considerada a fonte de maior risco à privacidade, isso nos motiva a usar a edição baseada em expressões regulares, mesmo que as expressões apresentem alguns problemas com falsos positivos.
1.4 Conjunto de dados solicitado
O ajuste fino de prompt multitarefa (também conhecido como ajuste de instrução) envolve o ajuste fino de um modelo de linguagem pré-treinado em um conjunto de dados ajustado que consiste em um grande número de tarefas diferentes por meio de prompts de linguagem natural. T0 demonstra a forte generalização zero-shot de modelos ajustados em conjuntos de dados solicitados mistos multitarefa. Além disso, T0 supera modelos de linguagem que são muito maiores sem esse ajuste fino. Inspirados por esses resultados, exploramos o uso de conjuntos de dados de linguagem natural existentes para ajuste fino solicitado por múltiplas tarefas.
T0 é treinado no subconjunto Public Pool of Prompt (P3), que é uma coleção de prompts para vários conjuntos de dados de linguagem natural aplicados de código aberto existentes. Esta coleção de prompts foi criada por meio de uma série de hackathons dos quais participaram colaboradores do BigScience, nos quais os participantes do hackathon escreveram mais de 2.000 prompts para mais de 170 conjuntos de dados. Os conjuntos de dados no P3 cobrem várias tarefas de linguagem natural, incluindo análise de sentimentos, resposta a perguntas, raciocínio em linguagem natural e exclusão de conteúdo prejudicial ou linguagem não natural. PromptSource, um kit de ferramentas de código aberto que facilita a criação, o compartilhamento e o consumo de prompts em linguagem natural.
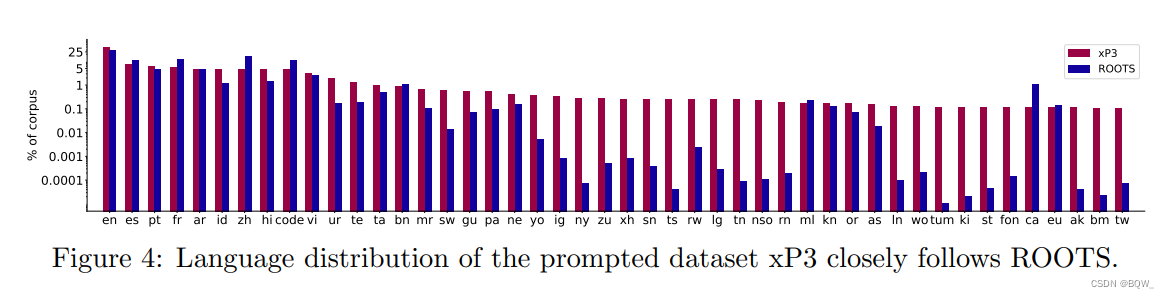
Após o pré-treinamento do BLOOM, aplicamos o mesmo ajuste fino multitarefa em grande escala para fazer o BLOOM generalizar para tarefas multilíngues de disparo zero. Chamamos o modelo resultante de BLOOMZ. Para treinar o BLOOMZ, estendemos o P3 para incluir novos conjuntos de dados e novas tarefas em idiomas diferentes do inglês, como tradução. Isso rendeu o xP3, uma coleção ampliada de 83 conjuntos de dados cobrindo 46 idiomas e 16 tarefas. Conforme mencionado na Figura 4 acima, xP3 reflete a distribuição de idiomas do ROOTS. As tarefas no xP3 incluem multilíngues e monolíngues. Usamos o PromptSource para coletar esses prompts, adicionando metadados adicionais aos prompts, como entrada e idioma de destino. Para investigar a importância dos prompts multilíngues, também traduzimos automaticamente os prompts em inglês no xP3 para o idioma do conjunto de dados correspondente para gerar um conjunto chamado xP3mt.
2. Arquitetura do modelo
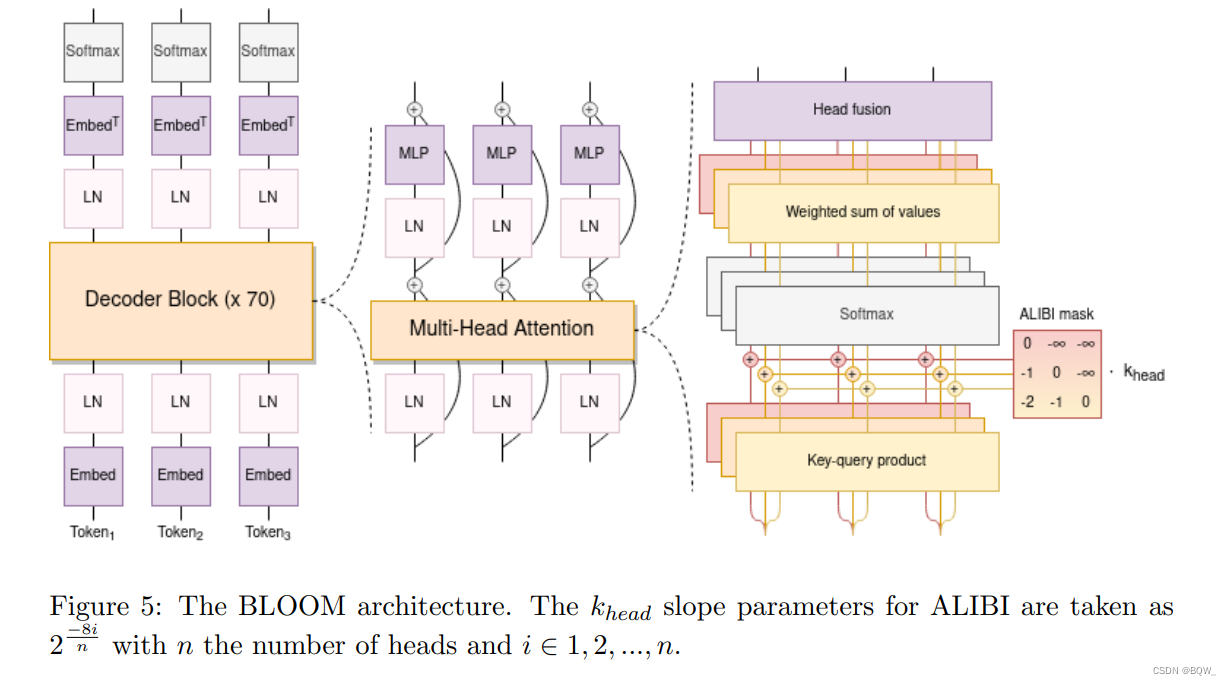
2.1 Método de projeto
A escolha do projeto de arquitetura é muito grande e é impossível explorá-la completamente. Uma opção é replicar completamente a arquitetura de um grande modelo existente. Por outro lado, muito trabalho para melhorar as arquiteturas existentes raramente foi adotado, e a adoção de algumas práticas recomendadas pode levar a um modelo melhor. Tomamos um meio-termo, escolhendo famílias de modelos que demonstraram ter bom dimensionamento e que são razoavelmente suportadas em ferramentas e bases de código disponíveis publicamente. Realizamos experimentos de ablação nos componentes e hiperparâmetros do modelo, buscando maximizar nosso orçamento computacional final.
-
Projeto Experimental de Ablação
O principal apelo dos LLMs é sua capacidade de executar tarefas de maneira "zero/poucos disparos": modelos suficientemente grandes podem simplesmente executar novas tarefas a partir de instruções e exemplos no contexto, sem treinamento em amostras supervisionadas. Como o ajuste fino de um modelo 100B+ é complicado, avaliamos as decisões arquitetônicas com foco nas capacidades de generalização zero-shot e não consideramos a aprendizagem por transferência. Especificamente, medimos o desempenho zero-shot de diferentes conjuntos de tarefas: 29 tarefas do EleutherAI Language Model Evaluation Harness (EAI-Eval) e 9 tarefas do conjunto de validação de T0 (T0-Eval). Há uma grande sobreposição entre os dois: apenas uma tarefa no T0-Eval não está no EAI-Eval, embora todos os prompts dos dois sejam diferentes.
Além disso, experimentos de ablação também são realizados utilizando modelos menores. Use o modelo 6.7B para conduzir experimentos de ablação em alvos pré-treinados e use o modelo 1.3B para conduzir experimentos de ablação em incorporação de posição, funções de ativação e normalização de camada. Recentemente, Dettmers descobriu uma transição de fase em um modelo maior que 6,7B e observou o aparecimento de "características de anomalia". Então é possível extrapolar o tamanho do modelo final na escala de 1,3B?
-
Esquema fora do escopo
Não consideramos a mistura de especialistas (MoE) devido à falta de bases de código baseadas em GPU amplamente utilizadas, adequadas para treiná-lo em escala. Da mesma forma, não consideramos modelos de espaço de estados. Quando o BLOOM foi projetado, eles tiveram um desempenho ruim em tarefas de linguagem natural. Ambas as abordagens são promissoras e agora demonstram resultados competitivos em MoE em grande escala e em escalas menores usando modelos de espaço de estados com H3.
2.2 Arquitetura e objetivos pré-treinamento
Embora a maioria dos modelos de linguagem modernos sejam baseados na arquitetura Transformer, existem diferenças significativas entre as implementações arquitetônicas. Obviamente, o Transformer original é baseado na arquitetura codificador-decodificador, e muitos modelos populares escolhem apenas métodos somente codificador ou somente decodificador. Atualmente, todos os modelos de última geração com mais de 100B de parâmetros são modelos somente decodificadores. Isto é contrário às descobertas de Raffel et al., onde o modelo codificador-decodificador supera significativamente o modelo somente decodificador em termos de aprendizagem por transferência.
Antes do nosso trabalho, faltava na literatura uma avaliação sistemática da generalização zero-shot para diferentes arquiteturas e objetivos de pré-treinamento. Exploramos Wang et al.(2022a)essa questão no trabalho de et al., que explora arquiteturas codificador-decodificador e somente decodificador e interações com modelos pré-treinados de modelagem de linguagem causal, prefixada e mascarada. Nossos resultados mostram que o modelo somente decodificador causal tem melhor desempenho após o pré-treinamento, validando a escolha do LLM de última geração.
2.3 Detalhes de modelagem
Além da escolha da arquitetura e do alvo de pré-treinamento, muitas mudanças são propostas na arquitetura original do Transformer. Por exemplo, esquemas alternativos de incorporação de localização ou novas funções de ativação. Realizamos uma série de experimentos para avaliar cada modificação, no Le Scao et al.modelo somente decodificador causal. Empregamos duas variações no BLOOM:
-
Incorporação de posição ALiBi
Comparado com a adição de informações de localização na camada de incorporação, o ALiBi atenua diretamente a pontuação de atenção com base na distância entre as chaves e as consultas. Embora a motivação original do ALiBi fosse sua capacidade de extrapolar para sequências mais longas, descobrimos que ele também leva a um treinamento mais equilibrado e a um melhor desempenho downstream em relação ao comprimento da sequência original, além de incorporações aprendíveis e rotacionadas.
-
Incorporando LayerNorm
Em um teste inicial de treinamento de um modelo de parâmetro 104B, tentamos a normalização da camada imediatamente após a camada de incorporação, conforme recomendado pela biblioteca bitsandbytes e sua camada StableEmbedding. Descobrimos que isso pode melhorar significativamente a estabilidade do treinamento. Embora
Le Scao et al.tenhamos descoberto em nosso trabalho que há uma penalidade para generalização zero-shot, adicionamos uma camada adicional de normalização de camada após a primeira camada de incorporação do BLOOM para evitar instabilidade de treinamento. Observe que float16 é usado no experimento preliminar 104B e bfloat16 é usado no treinamento final. Porque float16 foi identificado como a causa de muitas instabilidades observadas durante o treinamento de LLMs. bfloat16 tem o potencial de aliviar a necessidade de incorporação do LayerNorm.Toda a arquitetura do BLOOM é mostrada na Figura 5 acima.
3. Tokenização
As opções de design para tokenizadores são frequentemente ignoradas em favor da configuração “padrão”. Por exemplo, tanto o OPT quanto o GPT-3 usam o tokenizer do GPT-2, treinado para inglês. Devido à natureza diversificada dos dados de treinamento do BLOOM, são necessárias escolhas cuidadosas de design para garantir que o tokenizer codifique frases sem perdas.
3.1 Verificação
Comparamos o tokenizer (Acs, 2019) usado neste artigo com os tokenizers monolíngues existentes como uma métrica para detecção de integridade. A fertilidade é definida como o número de subpalavras criadas pelo tokenizer por palavra ou por conjunto de dados, que medimos usando as Dependências Universais 2.9 e o subconjunto OSCAR da linguagem de interesse. Ter uma fertilidade muito alta em um idioma em comparação com um tokenizer monolíngue pode indicar degradação de desempenho em vários idiomas downstream. Nosso objetivo é garantir que a capacidade de fertilidade de cada idioma não seja inferior a 10 pontos percentuais ao comparar nosso tokenizador multilíngue com seu equivalente linguístico. Em todos os experimentos, a biblioteca Hugging Face Tokenizers foi usada para projetar e treinar tokenizers de teste.
3.2 dados de treinamento do tokenizador
Inicialmente usamos um subconjunto não repetitivo de ROOTS. No entanto, um estudo qualitativo sobre vocabulários de tokenizadores revelou problemas com os dados de treinamento. Por exemplo, em versões anteriores do tokenizer, descobrimos que URLs completos eram armazenados como tokens, o que era causado por vários documentos que continham muita duplicação. Esse problema nos motiva a remover linhas duplicadas nos dados de treinamento do tokenizer.
3.3 Tamanho do vocabulário
Um vocabulário grande reduz o risco de segmentação excessiva de certas frases, especialmente para idiomas com poucos recursos. Realizamos experimentos de validação usando tamanhos de vocabulário de 150k e 250k para comparação com a literatura de modelagem multilíngue existente. Comparado com o tokenizer monolíngue, finalmente determinamos o tamanho do vocabulário em 250 mil tokens para atingir a meta inicial de fertilidade. Como o tamanho do vocabulário determina o tamanho da matriz de incorporação, o tamanho da incorporação deve ser divisível por 128 para eficiência da GPU e deve ser divisível por 4 para usar o paralelismo tensorial. Acabamos usando um tamanho de vocabulário de 250.680, com 200 tokens reservados para aplicações futuras, como o uso de tokens de espaço reservado para selecionar informações privadas.
3.4 BPE em nível de byte
O tokenizer é um tokenzier de subpalavra que pode ser aprendido e treinado usando o algoritmo Byte Pair Encoding (BPE). Para não perder informações durante o processo de tokenização, o tokenizer cria mesclagens de bytes em vez de caracteres como a menor unidade. Dessa forma, a tokenização nunca poderá gerar tokens desconhecidos, pois todos os 256 bytes podem ser incluídos no vocabulário do tokenizer. Além disso, o BPE em nível de byte maximiza o compartilhamento de vocabulário entre idiomas.
3.5 Normalização
No upstream do algoritmo BPE, para obter o modelo mais geral possível, o texto não é normalizado. Adicionar normalização Unicode, como NFKC, não reduz a fertilidade em mais de 0,8% em todos os casos, mas ao custo de tornar o modelo menos geral. Por exemplo, resultando em 2 2 2^222 e 22 são codificados da mesma maneira.
3.6 Pré-tokenizador
Nossa pré-tokenização tem dois objetivos: produzir a primeira partição do texto e limitar o comprimento máximo das sequências de token produzidas pelo algoritmo BPE. A escala de pré-tokenização usa a seguinte expressão regular: ?[^(\S|[.,!?...。,、|_])]+, que separa palavras enquanto preserva todos os caracteres, especialmente espaços em branco e sequências de nova linha que são cruciais para linguagens de programação. Não usamos partições centradas em inglês que são comuns em outros tokenizadores. Também não usamos divisão em números, o que causou problemas com o árabe e o código.
4. Engenharia
4.1 Hardware
O modelo foi treinado em Jean Zay, um supercomputador financiado pelo governo francês, de propriedade da GENCI e administrado pelo IDRIS, o centro nacional de computação do Centro Nacional Francês de Pesquisa Científica (CNRS). O treinamento BLOOM levou 3,5 meses para ser concluído e consumiu 1.082.990 horas de computação. O treinamento foi realizado em 48 nós, cada um com 8 GPUs NVIDIA A100 de 80 GB (384 GPUs no total); também mantivemos 4 nós sobressalentes devido a possíveis danos de hardware durante o treinamento. Os nós são equipados com 2 CPUs AMD EPYC 7543 de 32 núcleos e 512 GB de RAM, enquanto o armazenamento é um sistema de arquivos paralelo SpectrumScale (GPFS) híbrido de unidades totalmente flash e de disco rígido.
4.2 Estrutura
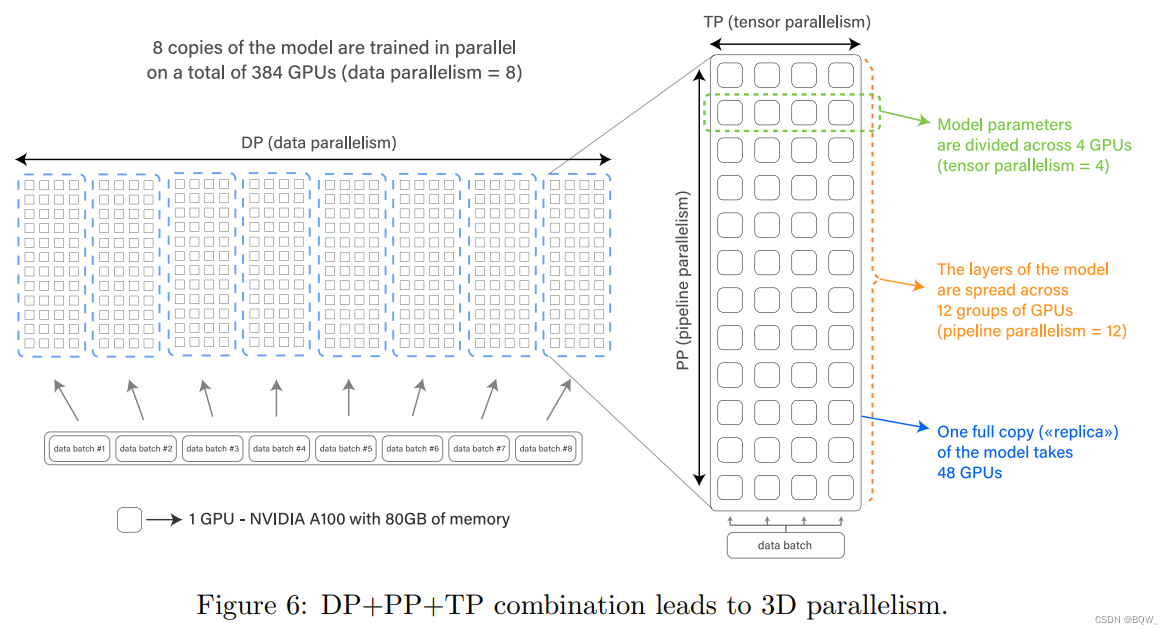
O BLOOM é treinado usando Megatron-DeepSpeed, uma estrutura para treinamento distribuído em larga escala. Ele consiste em duas partes: Megatron-LM fornece implementação de Transformer, paralelismo de tensor e primitivos de carregamento de dados, enquanto DeepSpeed fornece otimizador ZeRO, pipeline de modelo e componentes de treinamento distribuídos. Essa estrutura nos permite usar o paralelismo 3D para um treinamento eficiente – uma fusão de três métodos complementares de aprendizagem profunda distribuída. Esses métodos são descritos abaixo:
-
Paralelismo de dados (paralelismo de dados, DP)
Replique várias cópias do modelo, cada cópia é colocada em um dispositivo diferente e insira fragmentos de dados. Este processo é feito em paralelo, com todas as cópias do modelo sincronizadas ao final de cada etapa de treinamento.
-
Paralelismo tensorial (TP)
Divida camadas independentes do seu modelo em vários dispositivos. Dessa forma, em vez de colocar todo o tensor de ativação ou tensor de gradiente em uma única GPU, colocamos fragmentos desse tensor em uma única GPU. Essa técnica às vezes é chamada de paralelismo horizontal ou paralelismo intramodelo.
-
Paralelismo de pipeline (PP)
Divida as camadas do modelo em várias GPUs, cada GPU colocando apenas uma fração das camadas do modelo. Isso às vezes também é chamado de paralelismo vertical.
Em última análise, o Zero Redundancy Optimizer (ZeRO) executa diferentes processos contendo apenas parte dos dados (parâmetros, gradientes e estado do otimizador) e os dados necessários para uma etapa de treinamento. Usamos o estágio 1 do ZeRO, o que significa que apenas o estado do otimizador é fragmentado dessa forma.
A combinação dos quatro componentes descritos acima pode ser dimensionada para centenas de GPUs com utilização extremamente alta de GPU. Conseguimos atingir 156 TFLOPs na configuração mais rápida da GPU A100, metade do pico teórico de 312 TFLOPs.
4.3 Formato de ponto flutuante
Em experimentos preliminares com um modelo de parâmetro 104B em GPUs NVIDIA V100, observamos instabilidade numérica levando a divergência de treinamento irreversível. Nossa hipótese é que essas instabilidades surgem do uso original do IEEE float16, um formato numérico de ponto flutuante de 16 bits com uma faixa dinâmica muito limitada que pode levar ao overflow. Finalmente obtivemos permissão para suportar o formato bfloat16, que possui a mesma faixa dinâmica do float32. Por outro lado, a precisão do bfloat16 ainda é muito menor, o que nos motiva a utilizar o treinamento de precisão mista. A técnica realiza operações sensíveis à precisão, como acúmulo de gradiente e softmax na precisão float32, e utiliza baixa precisão para as demais operações, o que permite um equilíbrio entre alto desempenho e estabilidade do treinamento. Por fim, realizamos o treinamento final com precisão mista bfloat16, que provou resolver o problema de instabilidade do treinamento.
4.4 Fusão de núcleos CUDA
Em geral, as GPUs não podem realizar esses cálculos ao mesmo tempo que os dados estão sendo recuperados. Além disso, o desempenho computacional das GPUs modernas é muito superior à velocidade de transferência de memória necessária para cada operação (conhecida como núcleo na programação da GPU). A fusão de kernel é um método de otimização baseado na computação GPU, realizando múltiplas operações consecutivas em uma chamada de kernel. Este método fornece uma maneira de minimizar as transferências de dados: os resultados intermediários são deixados nos registros da GPU em vez de serem copiados para a VRAM, economizando sobrecarga.
Usamos Megatron-LM para fornecer vários núcleos CUDA fundidos personalizados. Primeiro, usamos um kernel otimizado para executar LayerNorm e usamos o kernel para fundir várias combinações de operações de escala, mascaramento e softmax. Adicione um termo de polarização às ativações GeLU usando a funcionalidade JIT do Pytorch. Como exemplo usando núcleos fundidos, adicionar um termo de polarização à operação GeLU não adiciona tempo extra porque a operação está vinculada à memória: a computação extra é insignificante em comparação com as transferências de dados entre GPU VRAM e registros. Assim, a fusão das duas operações reduz substancialmente o seu tempo de execução.
4.5 Desafios adicionais
O dimensionamento para 384 GPUs exigiu duas modificações: desabilitar inicializações assíncronas do kernel CUDA (para facilitar a depuração e evitar conflitos) e dividir grupos de parâmetros em subgrupos menores (para evitar alocação excessiva de memória da CPU).
Durante o processo de treinamento, enfrentamos o problema de falha de hardware: em média, 1 a 2 falhas de GPU por semana. Como os nós de backup estão disponíveis e são usados automaticamente, e os pontos de verificação são salvos a cada três horas, isso não afeta significativamente o rendimento do treinamento. Bug de deadlock do Pytorch e falha de espaço em disco no carregador de dados podem causar tempo de inatividade de 5 a 10 horas. Dado que os problemas de engenharia eram relativamente escassos e o modelo se recuperou rapidamente devido a apenas um pico de perda, a intervenção humana foi menos necessária do que projetos semelhantes.
5. Treinamento
-
modelo pré-treinado
Treinamos as 6 variantes de tamanho do BLOOM usando os hiperparâmetros detalhados na Tabela 3 acima. A arquitetura e os hiperparâmetros são derivados de nossos resultados experimentais (Le Scao et al.) e treinamento prévio de grandes modelos de linguagem (Brown et al.). A profundidade e largura do modelo não-176B seguem aproximadamente a literatura anterior (Brown et al.), e o desvio de 3B e 7,1B é apenas para facilitar o ajuste ao nosso ambiente de treinamento. Devido ao maior vocabulário multilíngue, o tamanho do parâmetro de incorporação do BLOOM é maior. Durante o desenvolvimento do modelo de parâmetro 104B, usamos diferentes Adam β \betaParâmetros β , redução de peso e recorte de gradiente foram usados para experimentar a estabilidade objetiva, mas não foram considerados úteis. Para todos os modelos, usamos um cronograma de decaimento da taxa de aprendizado de cosseno em 410B tokens, que é usado como um limite superior na duração do treinamento se o cálculo permitir, e aquece 375M tokens. Usamos redução de peso, recorte de gradiente e sem abandono. O conjunto de dados ROOTS contém o texto de tokens 341B. No entanto, com base nas leis de escalonamento revisadas publicadas durante o treinamento, decidimos treinar modelos grandes com 25 bilhões de tokens adicionais em dados repetidos. Como os tokens de aquecimento + tokens de decaimento são maiores que o número total de tokens, o decaimento da taxa de aprendizagem nunca atingiu o fim.
-
Ajuste fino multitarefa
O modelo BLOOMZ ajustado mantém os mesmos hiperparâmetros arquitetônicos do modelo BLOOM. Os hiperparâmetros ajustados são baseados aproximadamente em T0 e FLAN. A taxa de aprendizagem é dobrar a taxa mínima de aprendizagem do modelo pré-treinado correspondente e depois arredondar. Para variantes menores, o tamanho global do lote é multiplicado por 4 para aumentar o rendimento. O modelo é ajustado em tokens de 13B e o ponto de verificação ideal é selecionado com base em um conjunto de validação independente. Após o ajuste fino dos tokens de 1 a 6B, o desempenho tende a ser estável.
-
ajuste fino de contraste
Também usamos o esquema SGPT Bi-Encoder para ajuste fino comparativo dos modelos BLOOM com parâmetros 1,3B e 7,1B para treinar modelos que produzem incorporações de texto de alta qualidade. Criamos o SGPT-BLOOM-1.7B-msmarco para recuperação de informações multilíngues e o SGPT-BLOOM-1.7B-nli para similaridade semântica multilíngue. No entanto, benchmarks recentes descobriram que tais modelos também podem ser generalizados para várias outras tarefas de incorporação, como mineração de bittexto, rearranjo ou extração de recursos para classificação downstream.
6. Publicar
A abertura está no centro do desenvolvimento do BLOOM e queremos garantir que seja fácil de usar pela comunidade.
6.1 Cartão Modelo
Seguindo as melhores práticas para o lançamento de modelos de aprendizado de máquina, os modelos BLOOM são lançados junto com um Cartão de Modelo detalhado, que descreve especificações técnicas, detalhes de treinamento, uso pretendido, usos fora do escopo e limitações do modelo. Os participantes dos grupos de trabalho trabalham juntos para gerar o Cartão Modelo final e cada cartão de ponto de verificação.
6.2 Licenciamento
Dados os casos de utilização potencialmente prejudiciais que o BLOOM poderia trazer, optei por encontrar um equilíbrio entre o acesso irrestrito ao desenvolvimento e a utilização responsável, incluindo um código de conduta para limitar a aplicação do modelo a casos de utilização potencialmente prejudiciais. Esses termos geralmente são incluídos em “Responsible AI Licenses (RAIL)”, as licenças adotadas pela comunidade ao lançar modelos. A diferença significativa da licença RAIL adotada inicialmente pelo BLOOM é que ela separa “código-fonte” e “modelo”. Também inclui definições detalhadas de “uso” do modelo e “trabalho derivado” para garantir a identificação clara dos usos posteriores por meio de solicitação, ajuste fino, destilação, uso de logits e distribuições de probabilidade. A licença contém 13 restrições de uso comportamental, que são determinadas de acordo com o uso pretendido e as restrições descritas pelo Cartão Modelo BLOOM e pelo Código de Ética da BigScience. A licença fornece o modelo gratuitamente e os usuários podem usá-lo livremente, desde que cumpram os termos. O código-fonte do BLOOM foi disponibilizado sob a licença de código aberto Apache 2.0.
3. Avaliação
A avaliação concentra-se nas configurações de disparo zero e de poucos disparos. Nosso objetivo é apresentar uma imagem precisa do BLOOM em comparação com os LLMs existentes. Devido ao tamanho desses modelos, abordagens baseadas em prompts e "aprendizado no contexto" de poucas tentativas são mais comuns do que o ajuste fino.
1. Projeto experimental
1.1 Solicitações

Com base em pesquisas recentes sobre o impacto do prompt no desempenho do modelo de linguagem, decidimos construir um conjunto de avaliação de modelo de linguagem que nos permita variar os dados da tarefa subjacente, bem como solicitar tarefas "contextualizadas". Nosso prompt foi desenvolvido antes do lançamento do BLOOM sem quaisquer melhorias anteriores no uso do modelo. Nosso objetivo ao projetar o prompt dessa forma é simular os resultados de disparo zero ou único que novos usuários esperam do BLOOM.
Usamos promptsource para gerar vários prompts para cada tarefa. Seguimos Sanh et al.(2022)o processo utilizado, os prompts foram gerados por crowdsourcing, então pudemos ver diferentes comprimentos e estilos de prompts. Para promover qualidade e clareza, realize diversas revisões por pares em cada solicitação.
A Tabela 5 acima mostra alguns prompts finais para tarefas do WMT'14. Devido a restrições de recursos, também geramos prompts para muitas tarefas não incluídas neste artigo. Todos os prompts para todas as tarefas são acessíveis publicamente.
1.2 Infraestrutura
Nossa estrutura estende o conjunto de avaliação de modelo de linguagem da EleutherAI integrando a biblioteca promptsource. Lançamos o Prompted Language Model Evaluation Harness como uma biblioteca de código aberto para uso das pessoas. Usamos essa estrutura para realizar experimentos e agregar resultados.
1.3 Conjunto de dados
-
SuperCOLA
Usamos um subconjunto do conjunto de avaliação de tarefas de classificação SuperGLUE, em particular: tarefas Ax-b, Ax-g, BoolQ, CB, WiC, WSC e RTE. Excluímos as tarefas restantes porque elas exigiam uma ordem de grandeza maior de computação do que todas as tarefas que consideramos combinadas. As tarefas estão em inglês simples, principalmente para facilitar a comparação com trabalhos anteriores. Observamos também que o desempenho usando configurações solicitadas de disparo zero e de disparo único nessas tarefas não é amplamente divulgado. A primeira exceção é T0, mas o modelo é ajustado por instrução, portanto não pode ser comparado diretamente com BLOOM e OPT. Para cada tarefa, escolhemos aleatoriamente 5 amostras da fonte de prompt e, em seguida, avaliamos todos os modelos no conjunto de prompt.
-
Tradução Automática (MT)
Avaliamos o BLOOM em três conjuntos de dados: WMT14 eng ↔ fre \text{eng}\leftrightarrow\text{fre}inglês↔fre和eng ↔ hin \text{eng}\leftrightarrow\text{hin}inglês↔hin , Flores-101 e DiaBLa. Usamos sacrebleu, uma implementação BLEU, para avaliação. Use decodificação gananciosa no processo de geração até o token EOS, adicione \n###\n para 1 disparo.
-
Resumo
Avaliamos o resumo no conjunto de dados WikiLingua. WikiLingua é um conjunto de dados de resumo multilíngue que consiste em artigos do WikiHow e pares de resumo passo a passo. Modelos comparáveis em tamanho ao BLOOM normalmente não relatam geração de linguagem natural condicional única. PaLM é a primeira exceção, relatando no WikiLingua; no entanto, apenas a capacidade de resumo em inglês do modelo é examinada. Como comparação, testamos as capacidades multilíngues do BLOOM avaliando resumos abstratos no idioma de origem. Estamos nos concentrando em 9 idiomas (árabe, inglês, espanhol, francês, hindi, português, vietnamita e chinês) que são os objetivos do BigScience.
1.4 Modelo de linha de base
- mGPT: modelos estilo GPT treinados em 60 idiomas;
- GPT-Neo, GPT-J-6B, GPT-NeoX: família de modelos estilo GPT treinada em Pile;
- T0: variante T5 ajustada por multitarefa promovida no conjunto de dados P3;
- OPT: um modelo estilo GPT, treinado em conjuntos de dados mistos;
- XGLM: modelo multilíngue estilo GPT treinado em variantes CC100;
- M2M: Modelo codificador-decodificador treinado com funções objetivo mascaradas e causais na Wikipedia e mC4;
- mTk-Instruct: variante T5 para ajuste fino solicitado por multitarefa no conjunto de dados Super-NaturalInstructions;
- Codex: modelo GPT ajustado no código do GitHub;
- GPT-fr: modelo de estilo GPT treinado em texto francês;
2. Efeito Tiro Zero
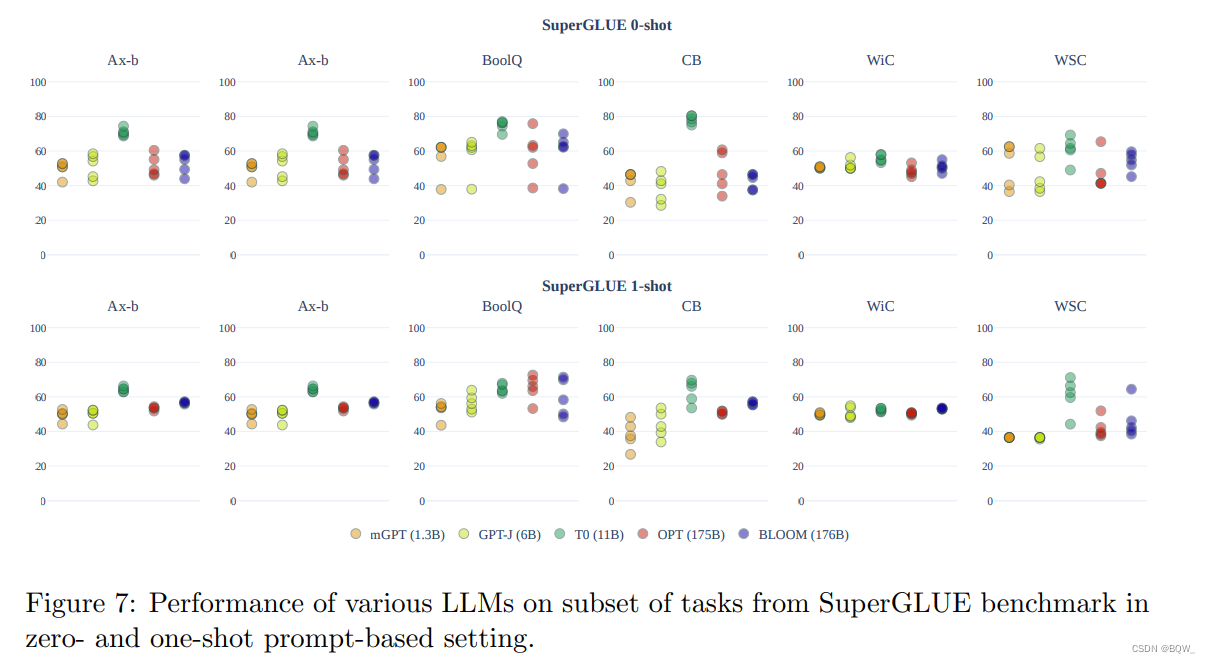
Em tarefas de compreensão e geração de linguagem natural, descobrimos que o desempenho zero-shot de modelos de linguagem pré-treinados é quase aleatório. A Figura 7 acima mostra o desempenho do disparo zero.
2.1 SuperCOLA
No SuperGLUE, embora alguns prompts independentes mostrem uma melhoria de desempenho de cerca de 10 pontos, a melhoria média dos prompts individuais é quase aleatória . Exceto o modelo T0, que apresenta forte efeito. No entanto, este modelo é ajustado na configuração multitarefa para melhorar o efeito da solicitação de disparo zero.
2.2 Tradução automática
Na configuração zero-shot, os resultados da tradução automática são muito ruins . Existem dois problemas principais com os resultados gerados: (1) geração excessiva; (2) incapacidade de gerar a linguagem correta.
3. Resultados únicos
3.1 SuperCOLA
A exibição na Figura 7 acima também mostra o efeito do one-shot. Comparado com o efeito zero-shot, a variabilidade do efeito one-shot de todos os prompts e modelos no SuperGLUE é reduzida. No geral, não há melhoria significativa na configuração one-shot: a precisão do modelo ainda está próxima da aleatória. Realizamos análises adicionais no BLOOM em diferentes tamanhos de modelo. Como linha de base, também medimos a precisão única de modelos OPT de tamanhos semelhantes. As famílias de modelos OPT e BLOOM melhoram ligeiramente com a escala. BLOOM-176B supera OPT-175B em Ax-B, CB e WiC.
3.2 Tradução automática
![[Falha na transferência da imagem do link externo, o site de origem pode ter um mecanismo anti-leeching, é recomendado salvar a imagem e carregá-la diretamente (img-BL4WvdO9-1675687454712)(.\图\BLOOM_T8.png)]](https://img-blog.csdnimg.cn/de67b5f8c67d49808f017ae4be8f5c06.png)
Na configuração 1-shot, usamos o prompt XGLM para testar as instruções de idioma central no conjunto de teste de desenvolvimento Flores-101. Selecionamos aleatoriamente amostras únicas do mesmo conjunto de dados, que podem diferir de trabalhos anteriores. Separamos diferentes resultados por pares de línguas com altos recursos, pares de línguas com recursos altos a médios, pares de línguas com poucos recursos e famílias de línguas românicas. De acordo com a proporção de idiomas no ROOTS, os idiomas são classificados em recursos baixos, médios e altos. Para pares de idiomas com recursos altos e recursos médios-altos, comparamos com os resultados supervisionados do modelo M2M-124 com parâmetros de 615M. Além disso, comparamos os resultados de 1 disparo do XGLM (7,5B) com os resultados do AlexaTM de 32 disparos. **Bons resultados para traduções de idiomas com muitos recursos e traduções de idiomas com muitos recursos para idiomas com recursos médios. **Isso mostra que o BLOOM tem boa capacidade multilíngue. Em comparação com os modelos M2M supervisionados, os resultados são frequentemente comparáveis ou até melhores na configuração 1-shot e, em muitos casos, os resultados são comparáveis aos do AlexaTM.
**A qualidade da tradução é boa para muitos idiomas com poucos recursos, comparável ou até melhor que os modelos M2M supervisionados. **No entanto, o desempenho entre suaíli e iorubá é bastante fraco, devido à falta de dados de treinamento do BLOOM.
3.3 Resumo
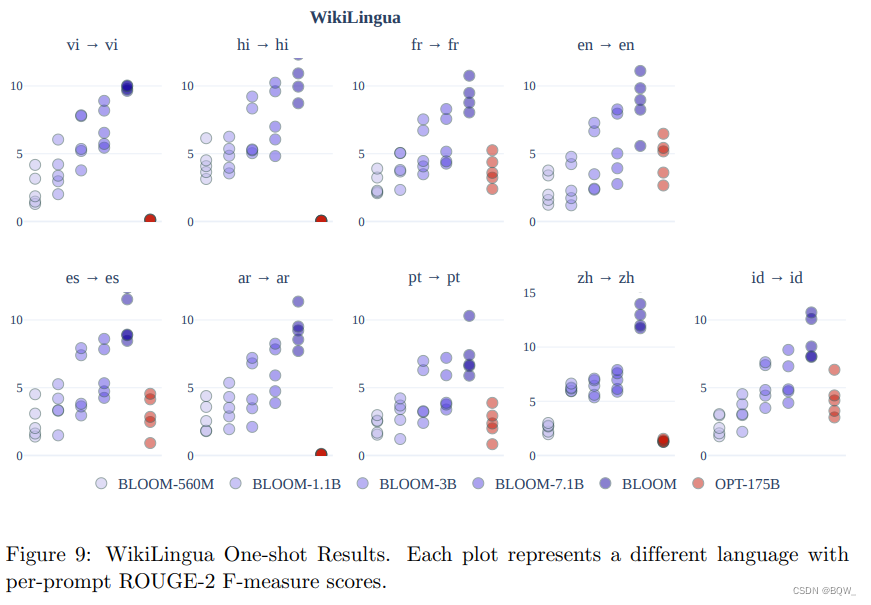
A Figura 9 acima mostra a comparação dos resultados únicos do BLOOM e do OPT-175B. Cada ponto representa uma pontuação pré-prompt. A principal conclusão é que o BLOOM alcança desempenho superior ao OPT na sumarização multilíngue, e o desempenho aumenta à medida que os parâmetros do modelo aumentam. Suspeitamos que isso se deva ao treinamento multilíngue do BLOOM.
4. Ajuste fino de multitarefa
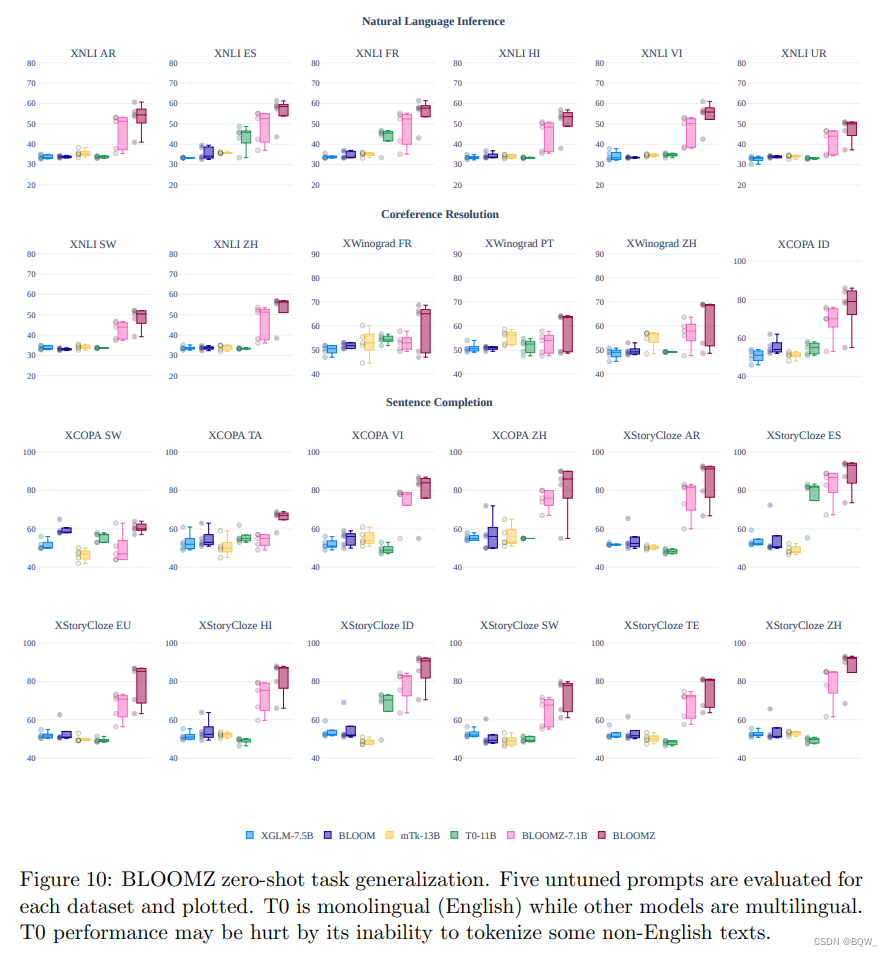
Com base em trabalhos recentes sobre ajuste fino multitarefa, exploramos o uso de ajuste fino multitarefa multilíngue para melhorar o desempenho zero-shot dos modelos BLOOM. Usamos o corpus xP3 para realizar o ajuste fino multitarefa multilíngue no BLOOM. Descobrimos que a capacidade de realizar um desempenho de tiro zero é significativamente aprimorada. Na Figura 10 acima, comparamos o efeito zero-shot dos modelos BLOOM e XLGM com o ajuste fino multitarefa BLOOMZ, T0 e mTk-Instruct. O desempenho do BLOOM e do XGLM é resolvido em linhas de base aleatórias. Após o ajuste fino multilíngue e multitarefa (BLOOMZ), o efeito do tiro zero é significativamente melhorado. Apesar de ser ajustado em múltiplas tarefas, como T0 é um modelo monolíngue em inglês, ele tem um desempenho ruim em conjuntos de dados multilíngues. No entanto, Muennighoff et al.resultados adicionais são apresentados para mostrar que o modelo ajustado no conjunto de dados xP3 em inglês ainda supera T0 ao controlar o tamanho e a arquitetura. Isso pode ser devido ao fato de que o conjunto de dados ajustado T0 (P3) contém uma diversidade menor de conjuntos de dados e prompts do que xP3.
5. Geração de código
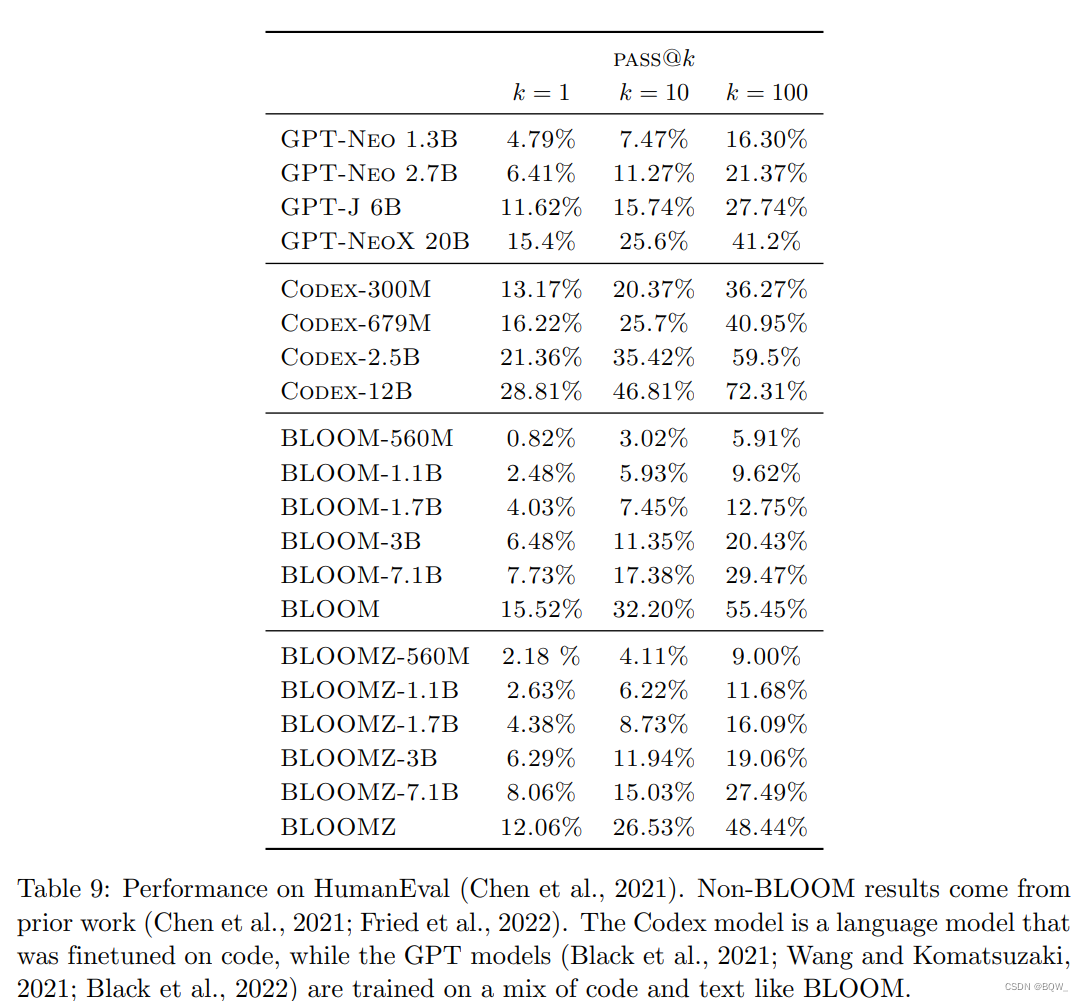
O corpus de pré-treinamento do BLOOM ROOTS contém cerca de 11% do código. A Tabela 9 acima mostra os resultados de benchmark do BLOOM no HumanEval. Descobrimos que o BLOOM pré-treinado tem um desempenho tão bom quanto um modelo GPT de tamanho semelhante treinado no Pile. A pilha contém dados em inglês e cerca de 13% de código, que é semelhante à fonte de dados do código e à proporção no ROOTS. O modelo Codex, que é ajustado apenas no código, é muito mais forte que outros modelos. Comparado ao modelo BLOOM, o modelo BLOOMZ multitarefa ajustado não melhora significativamente. Presumimos que isso ocorre porque o conjunto de dados de ajuste fino xP3 não contém uma grande quantidade de código puro.