Endereço do artigo: https://arxiv.org/pdf/2303.17568.pdf
Blogs relacionados
[Processamento de linguagem natural] [Modelo grande] CodeGen: um modelo de linguagem de código grande para síntese de programas multi-rodadas
[Processamento de linguagem natural] [Modelo grande] CodeGeeX: um modelo de pré-treinamento multilíngue para geração de código
[Processamento de linguagem natural] 【Modelo grande】LaMDA: Modelo de linguagem para aplicações de conversação
【Processamento de linguagem natural】 【Modelo grande】 Gopher de modelo grande da DeepMind
【Processamento de linguagem natural】 【Modelo grande】Chinchilla: Modelo de linguagem grande com treinamento e utilização computacional ideais
[Processamento de linguagem natural] [ Modelo grande] Modelo de linguagem grande Teste de ferramenta de raciocínio BLOOM
[Processamento de linguagem natural] [Modelo grande] GLM-130B: um modelo de linguagem pré-treinado bilíngue de código aberto
[Processamento de linguagem natural] [Modelo grande] para grandes transformadores Introdução à matriz de 8 bits multiplicação
[Processamento de linguagem natural] [Modelo grande] BLOOM: Um modelo multilíngue com parâmetros 176B e acesso aberto
[Processamento de linguagem natural] [Modelo grande] PaLM: Um modelo de linguagem grande baseado em Pathways
[Processamento de linguagem natural] [série chatGPT] Linguagem grande os modelos podem melhorar a si mesmos
[Processamento de linguagem natural] [Série ChatGPT] FLAN: Os modelos de linguagem de ajuste fino são um aluno Zero-Shot
[Processamento de linguagem natural] [Série ChatGPT] De onde vem a inteligência do ChatGPT?
1. Introdução
O objetivo da geração de código é: dada uma descrição da intenção humana (por exemplo: “escrever uma função fatorial”), o sistema gera automaticamente um programa executável. Essa tarefa já existe há muito tempo e as soluções para ela são infinitas. Recentemente, a qualidade da geração de código foi significativamente melhorada ao tratar programas como sequências de linguagem e modelá-los com arquiteturas de transformadores de aprendizagem profunda. Especialmente quando dados de código-fonte aberto em grande escala são combinados com grandes modelos de linguagem.
O modelo CodeX 12B da OpenAI demonstra o potencial de grandes modelos pré-treinados em bilhões de linhas de código público. Ao usar o pré-treinamento generativo, o CodeX pode resolver muito bem problemas de programação de nível básico em python. A pesquisa mostra que 88% dos usuários do GitHub Copilot relatam aumento na produtividade da programação. Posteriormente, um grande número de grandes modelos de linguagem de código foram desenvolvidos, incluindo: AlphaCode da DeepMind , CodeGen da Salesforce , InCoder da Meta e PaLM-Coder-540B do Google .
Este artigo propõe CodeGeeX, um modelo de geração de código multilíngue com 13B parâmetros , que é pré-treinado em 23 linguagens de programação. O modelo foi treinado por 2 meses em um cluster com 1.536 processadores Ascend 910 AI, treinando um total de 850 bilhões de tokens. CodeGeeX tem as seguintes características: (1) CodeGeeX é diferente do CodeX, seu próprio modelo e código de treinamento são de código aberto , o que é útil para entender e melhorar o modelo de código de pré-treinamento. CodeGeeX também suporta inferência em diferentes plataformas , como GPUs Ascend e NVIDIA . (2) Além da geração e conclusão de código, CodeGeeX também suporta interpretação e tradução de código . (3) Comparado com modelos de geração de código bem conhecidos (CodeGen-16B, GPT-NeoX-20B, InCode-6.7B e GPT-J-6B), CodeGeeX supera consistentemente outros modelos.
Este artigo também desenvolve o benchmark HumanEval-X para avaliar modelos de código multilíngue porque: (1) HumanEval e outros benchmarks contêm apenas problemas de programação em um único idioma ; (2) conjuntos de dados multilíngues existentes usam strings semelhantes, como métricas de avaliação BLEU, em vez de verificar a exatidão do código gerado . Especificamente, para cada problema Python no HumanEval, seus prompts, soluções padrão e casos de teste são reescritos manualmente em C++, Java, JavaScript e GO. No total, 820 “pares problema-solução” manuscritos estão incluídos no HumanEval-X. Além disso, HumanEval-X suporta geração de código e avaliação de tradução de código.
2. Modelo CodeGeeX
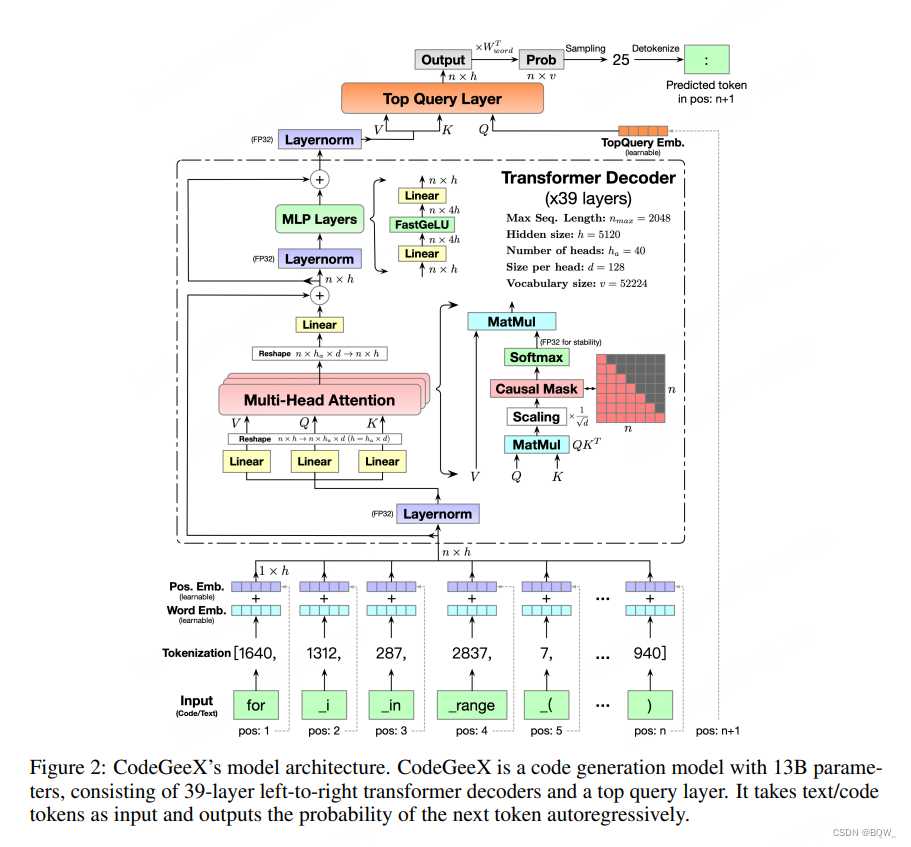
1. Arquitetura do modelo
Backbone do transformador . CodeGeeX usa uma arquitetura GPT somente decodificador e usa modelagem de linguagem autorregressiva. A arquitetura central do CodeGeeX é um decodificador transformador de 39 camadas. Cada camada do transformador inclui: mecanismo de autoatenção de múltiplas cabeças, camada MLP, normalização de camada e conexão residual. Use ativações FaastGELU do tipo GELU, que são mais eficientes no processador Ascend 910 AI.
FastGELU ( X i ) = X i 1 + exp ( − 1,702 × ∣ X i ∣ ) × exp ( 0,851 × ( X i − ∣ X i ∣ ) ) (1) \text{FastGELU}(X_i)=\ frac{X_i}{1+\exp(-1,702\vezes|X_i|)\vezes\exp(0,851\vezes(X_i-|X_i|))} \tag{1}RápidoGELU ( Xeu)=1+exp ( - 1,702×∣ Xeu∣ )×exp ( 0,851×( Xeu-∣ Xeu∣ ))Xeu( 1 ) Objetivo
generativo. Adote o paradigma GPT para treinar o modelo em dados de código não supervisionados em grande escala. Em geral, iterativamente toma o token do código como entrada, prevê o próximo token e o compara com o token real. Especificamente, para comprimentonnQualquer sequência de entrada de n { x 1 , x 2 , … , xn } \{x_1,x_2,\dots,x_n\}{
x1,x2,…,xnão} , a saída do CodeGeeX é a distribuição de probabilidade do próximo token
P ( xn + 1 ∣ x 1 , x 2 , … , xn , Θ ) = pn + 1 ∈ [ 0 , 1 ] 1 × v (2) \mathbb { P}(x_{n+1}|x_1,x_2,\dots,x_n,\Theta)=p_{n+1}\in[0,1]^{1\times v} \tag{2}P ( xn + 1∣x _1,x2,…,xnão,eu )=pn + 1∈[ 0 ,1 ]1 × v( 2 )
Entre eles,Θ \ThetaΘ denota todos os parâmetros,vvv é o tamanho do vocabulário. Ao comparar o token previsto com a distribuição verdadeira, a função de perda de entropia cruzada pode ser otimizada:
L = − ∑ n = 1 N − 1 yn + 1 log P ( xn + 1 ∣ x 1 , ) (3) \mathcal {L} =-\sum_{n=1}^{N-1}y_{n+1}\log \mathbb{P}(x_{n+1}|x_1,) \tag{3}eu=-n = 1∑N − 1simn + 1ei _P ( xn + 1∣x _1,)( 3 ) Camada de consulta
superior. O GPT original usa a função pooler para obter o resultado final. Adicionamos uma camada de consulta adicional (também usada pela Huawei "Pangu") em todas as camadas do transformador para obter a incorporação final. Conforme mostrado na figura acima, a entrada da camada de consulta superior é substituída pela posiçãon + 1 n+1n+1 incorporação de consulta. A saída final é multiplicada pela transposta da matriz de incorporação de palavras para obter a distribuição de probabilidade de saída. Para estratégias de resolução, CodeGeeX suporta amostragem gananciosa, amostragem de temperatura, amostragem top-k, amostragem top-p e pesquisa de feixe.
2. Configurações pré-treino
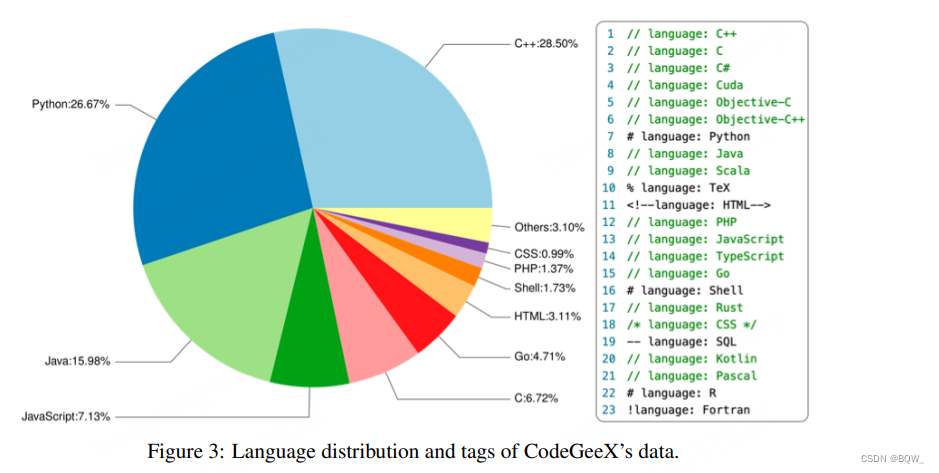
Corpus de código . O corpus de formação é composto por duas partes. A primeira parte são conjuntos de dados de código-fonte aberto: Pile e CodeParrot. A segunda parte é o código Python, Java e C++ rastreado diretamente do GitHub para complementar a primeira parte. Selecione o armazém de código com pelo menos uma estrela e menos de 10 MB e, em seguida, filtre os arquivos: (1) cada linha excede 100 caracteres; (2) gerado automaticamente; (3) a proporção de letras é inferior a 40%; (4) maior que 100 KB ou menor que 1 KB. A figura acima mostra a proporção de 23 linguagens de programação nos dados de treinamento. Os dados de treinamento são divididos em segmentos de igual comprimento . Para ajudar o modelo a distinguir entre vários idiomas, tags relacionadas ao idioma são adicionadas antes de cada fragmento, por exemplo: idioma: Python.
Tokenização . Considerando que há um grande número de anotações de linguagem natural nos dados do código e os nomes das variáveis, funções e categorias são geralmente palavras significativas, os dados do código também são usados como dados de texto e o tokenizer GPT-2 é usado . O tamanho inicial do vocabulário é 50.000 e vários espaços são codificados como tokens extras para aumentar a eficiência da codificação. Especificamente, L tokens em branco são representados como <|extratoken_X|>, onde X=8+L. Como o vocabulário contém tokens em vários idiomas , isso permite que o CodeGeeX lide com tokens em vários idiomas, como chinês, francês, etc. O tamanho final do vocabulário é v = 52224 v=52224v=52224 .
Incorporações de palavras . A matriz de incorporação de palavras é expressa como W palavra ∈ R v × h W_{palavra}\in\mathbb{R}^{v\times h}Cw ou d∈Rv × h , a matriz de incorporação de posição é expressa comoW pos ∈ R nmax × h W_{pos}\in\mathbb{R}^{n_{max}\times h}Cpos _∈Rnma x× h , ondeh = 5120 h=5120h=5120 enmáx = 2048 n_{máx}=2048nma x=2048 . Cada token corresponde a uma palavra que pode ser aprendida incorporandoxword ∈ R h x_{palavra}\in\mathbb{R}^hxw ou d∈Rh e umaque pode ser aprendidaincorporandoxpos ∈ R h x_{pos}\in\mathbb{R}^{h}xpos _∈Rh . Os dois embeddings são adicionados para obter o vetor de incorporação de entradaxin = xword + xpos x_{in}=x_{word}+x_{pos}xdentro=xw ou d+xpos _. Finalmente, toda a sequência é transformada em uma matriz de incorporação X em ∈ R n × h X_{in}\in\mathbb{R}^{n\times h}Xdentro∈Rn × h ,nnn é o comprimento da sequência.
3. Treinamento CodeGeeX
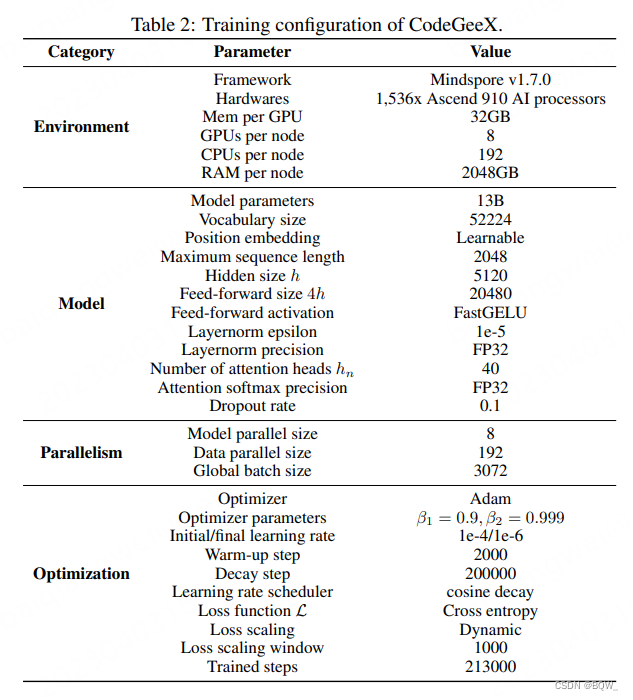
Treinamento paralelo Ascend . CodeGeeX usa Mindspore em um cluster de processadores Ascend 910 AI (32 GB) para treinamento. O treinamento ocorreu durante 2 meses em 1.526 processadores de IA em 192 nós. Um total de 850 bilhões de tokens foram consumidos, cerca de 5 épocas (213.000 passos). Para melhorar a eficiência do treinamento, são usados paralelismo de modelo de 8 vias e paralelismo de dados de 192 vias, e o otimizador ZeRO-2 é usado para reduzir ainda mais o consumo de memória. Finalmente, o tamanho do microlote em cada nó é 16 e o tamanho global do lote é 3.072.
Especificamente, use o otimizador Adam para otimizar a perda. Os pesos do modelo estão no formato FP16, e a norma de camada e o softmax usam FP32 para maior precisão e estabilidade. O modelo ocupa 27 GB de memória GPU. A taxa de aprendizagem inicial é 1e-4, e um cronograma de taxa de aprendizagem de cosseno é aplicado:
lrcurrent = lrmin + 0,5 ∗ ( lrmax − lrmin ) ∗ ( 1 + cos ( ncurrentndecay π ) ) (4) lr_{current}=lr_{ min}+ 0,5*(lr_{max}-lr_{min})*(1+\cos(\frac{n_{atual}}{n_{decaimento}}\pi)) \tag{4}eu ratual _ _ _ _=eu rmin+0,5∗( eu rma x-eu rmin)∗( 1+porque (nd ec a ynatual _ _ _ _p ))( 4 )
Os parâmetros de treinamento detalhados são mostrados abaixo.
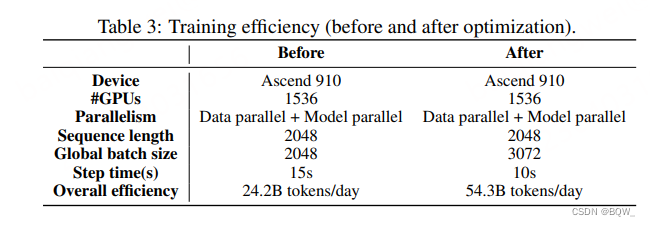
Eficiência de treinamento . Para otimizar a estrutura Mindspore para liberar o potencial do Ascend 910. Duas técnicas são empregadas para melhorar significativamente a eficiência do treinamento: (1) fusão do kernel; (2) otimização do Auto Tune. A tabela a seguir é uma comparação antes e depois da otimização.
4. Raciocínio rápido
Quantificar . Aplique tecnologia de quantização pós-treinamento para reduzir o consumo de memória da inferência CodeGeeX. Quantize todos os pesos da camada linear WW usando o máximo absolutoW é convertido de FP16 para INT8:
W q = Round ( W λ ) , λ = Max ( ∣ W ∣ ) 2 b − 1 − 1 (5) W_q=\text{Round}(\frac{W}{\lambda } ),\lambda=\frac{\text{Max}(|W|)}{2^{b-1}-1} \tag{5}Cq=Rodada (euE) ,eu=2b - 1-1Máx. ( ∣ W ∣ )( 5 )
ondebbb é a largura de bits,b = 8 b=8b=8λ \lambdaλ é o fator de escala.
acelerar . Após a quantização de 8 bits, uma versão mais rápida do CodeGeeX foi implementada usando o FasterTransformer da NVIDIA.
3. Referência HumanEval-X
O benchmark HumanEval, semelhante ao MBPP e APPS, contém apenas problemas de programação Python manuscritos e não pode ser aplicado diretamente à avaliação sistemática da geração de código multilíngue. Portanto, este artigo desenvolve uma variante multilíngue do HumanEval, HumanEval-X. Cada problema no HumanEval é definido em Python, e reescrevemos prompts, soluções padrão e casos de teste em C++, Java, JavaScript e Go. Há um total de 820 “pares problema-solução” no HumanEval-X.
tarefa . HumanEval-X avalia 2 tarefas: geração de código e tradução de código. A tarefa de geração de código recebe uma declaração de função e uma descrição textual como entrada e gera o código de implementação da função. A tarefa de tradução de código toma como entrada uma solução implementada na linguagem de origem e gera uma implementação correspondente na linguagem de destino.
Métrica . Use casos de teste para avaliar a exatidão do código gerado e medir seu pass@k. Especificamente, use um método imparcial para estimar pass@k:
pass@k : = E [ 1 − ( n − ck ) ( nk ) ] , n = 200 , k ∈ { 1 , 10 , 100 } (6) \ text{ pass@k}:=\mathbb{E}[1-\frac{\left(\begin{array}{l}nc \\ k\end{array}\right)}{\left(\begin{ array} {l}n \\ k\end{array}\right)}],\quad n=200,k\in\{1,10,100\} \tag{6}passar@k:=E [ 1-(nk)(n-ck)] ,n=200 ,k∈{
1 ,10 ,100 }( 6 )
ondennn é o número total gerado (200), k é o número de amostras,ccc é o número de amostras que passam em todos os casos de teste.
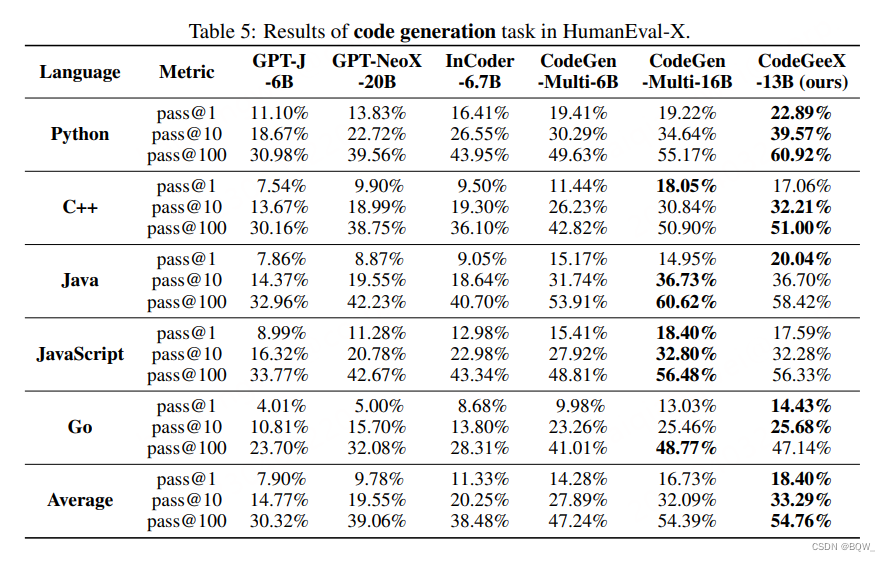
4. Avaliação CodeGeeX
- Geração de código multilíngue
- Tradução de código multilíngue