O que é Ziya?
Ziya é um modelo de idioma pré-treinamento bilíngue chinês-inglês com 13 bilhões de parâmetros baseado em LLaMa. Ele é lançado pelo Centro de Pesquisa de Computação Cognitiva e Linguagem Natural (CCNL) do IDEA Research Institute e é membro do modelo geral de código aberto Series. Ziya tem os recursos de tradução, programação, classificação de texto, extração de informações, resumo, geração de cópias, resposta a perguntas de bom senso e cálculo matemático, e pode lidar com uma variedade de tarefas de linguagem natural.
- Endereço de código aberto do modelo Ziya-Visual: https://huggingface.co/IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1
- Endereço da experiência de demonstração: https://huggingface.co/spaces/IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1-Demo
- Modelo de código aberto Ziya: https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
- Página inicial do projeto Fengshenbang: https://github.com/IDEA-CCNL/Fe
O que é IDEA Instituto CCNL?
IDEA Research Institute (International Digital Economy Academy) é uma instituição internacional inovadora dedicada à pesquisa de ponta e implementação industrial no campo da inteligência artificial e economia digital. Foi fundada pelo Dr. Shen Xiangyang, ex-vice-presidente executivo da Microsoft Asia Research Instituto. O IDEA Research Institute se esforça para começar com a tecnologia, incubar empresas de alta qualidade, cultivar talentos excepcionais e construir uma ecologia cooperativa.
CCNL (Computação Cognitiva e Linguagem Natural) é um centro de pesquisa do IDEA Research Institute, liderado pelo Dr. Zhang Jiaxing. A CCNL está empenhada em construir a infraestrutura de inteligência cognitiva e promover o desenvolvimento da IA acadêmica e industrial na era do pré-treinamento de grandes modelos. O CCNL alcançou o nível de liderança nos campos técnicos de produção de modelos de pré-treinamento, aprendizado de poucos disparos/zero disparos, geração de texto controlado e aprendizado de máquina automatizado. A sede da CCNL está localizada no 6º andar, Edifício B2, Kexing Science Park, No. 9 Keyuan Road, North District, Science and Technology Park, Nanshan District, Shenzhen.
Qual é a diferença entre Ziya e outros grandes modelos de linguagem?
O modelo de linguagem grande (LLM) refere-se a modelos de linguagem pré-treinados com mais de 1 bilhão de parâmetros e geralmente podem lidar com uma variedade de tarefas de linguagem natural, como geração de texto, resposta a perguntas, resumo etc. Existem várias diferenças entre o Ziya e outros modelos de linguagem grandes:
- Ziya é um modelo autorregressivo, o que significa que só pode gerar texto da esquerda para a direita sem usar informações contextuais ao mesmo tempo. Isso é diferente de alguns modelos de codificação automática ou codificação-decodificação, como T5, mT5, UL2, etc.
- Ziya é um modelo bilíngue, o que significa que suporta chinês e inglês e tem alta precisão em ambos os idiomas. Isso é diferente de alguns modelos que suportam apenas monolíngues ou multilíngues, como GPT-3, GPT-4, mT0, etc.
- Ziya é um modelo de código aberto, o que significa que seus arquivos de peso e código são gratuitos para download e uso. Isso é diferente de alguns modelos que fornecem apenas API ou uso comercial, como GPT-3, GPT-4, PaLM, LaMDA, etc.
- O Ziya é um modelo multifuncional, o que significa que pode lidar com uma variedade de tarefas, como tradução, programação, classificação de texto, extração de informações, resumo, geração de cópias, resposta a perguntas de conhecimento geral e cálculos matemáticos. Isso é diferente de alguns modelos que focam apenas em um determinado campo ou tarefa, como ChatGLM, InstructGPT, Alpaca, etc.
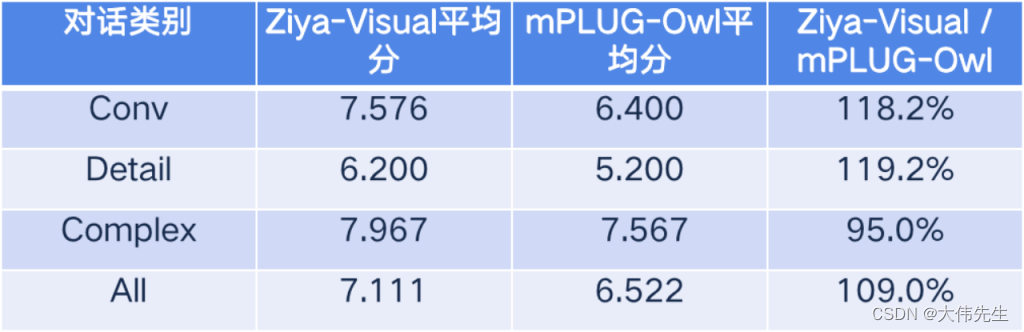
Como o Ziya é usado?
Como usar o Ziya pode consultar sua documentação e código de exemplo no GitHub. Simplificando, os usuários precisam baixar os arquivos de peso de LLaMa-13B e Ziya-LLaMA-13B-v1 primeiro e usar o script de conversão para mesclá-los em um arquivo de modelo completo. O usuário pode então usar as classes LlamaTokenizer e LlamaForCausalLM na biblioteca de transformadores para carregar o modelo e usar o método generate para gerar texto. Os usuários também podem ajustar ou implantar o modelo de acordo com suas necessidades
Quais são os pontos fortes e as limitações do Ziya?
A vantagem do Ziya é que ele usa uma grande quantidade de dados bilíngues chinês-inglês para pré-treinamento e treina dados de tokens 110B de forma incremental com base no modelo LLaMa-13B nativo. Ele também usa tecnologias como ajuste fino supervisionado, auto-ajuda de feedback e aprendizado de reforço de feedback humano, para que o modelo tenha a capacidade de entender a intenção das instruções humanas. Ele também oferece suporte à quantização INT4, permitindo que os usuários implantem localmente em placas gráficas de consumo.
A limitação do Ziya é que sua escala de parâmetros é pequena e não pode lidar com problemas lógicos complexos; seu vocabulário é pequeno e não pode cobrir todos os caracteres chineses e ingleses; seu comprimento de sequência é curto e não pode gerar textos muito longos etc. .
Quais são os cenários de aplicação e casos de Ziya?
O Ziya pode ser aplicado em vários cenários, como:
- Tradução: Ziya pode realizar tradução mútua entre chinês e inglês e oferece suporte à tradução em diferentes campos e estilos, como literatura, tecnologia, linguagem falada, etc.
- Programação: Ziya pode gerar código de acordo com as necessidades do usuário, e suporta diferentes linguagens e frameworks, como Python, Java, C++, etc.
- Classificação de texto: Ziya pode classificar textos com base em tags de usuário, suportando diferentes tópicos e tipos, como notícias, comentários, emoções, etc.
- Extração de informações: Ziya pode extrair informações importantes de texto, suportando diferentes formatos e estruturas, como tabelas, listas, gráficos, etc.
- Abstract: Ziya pode resumir o texto, suportando diferentes comprimentos e granularidades, como título, resumo, resumo, etc.
- Geração de copywriting: Ziya pode gerar copywriting de acordo com a finalidade do usuário, suportando diferentes cenários e estilos, como publicidade, marketing, stories, etc.
- Perguntas e respostas de conhecimentos gerais: Ziya pode responder a perguntas de conhecimentos gerais dos usuários, apoiando diferentes campos e dificuldades, como história, geografia, ciências, etc.
- Cálculos matemáticos: Ziya pode realizar cálculos matemáticos, suportando diferentes operações e expressões, como adição, subtração, multiplicação, divisão, frações, equações, etc.
Resumir
O Ziya é um grande modelo de linguagem com recursos autorregressivos, bilíngües, de código aberto e multifuncionais, funciona bem em chinês e inglês e pode ser aplicado a vários cenários. Se você estiver interessado em Ziya, visite seu site oficial https://fengshenbang.cc/ ou faça o download e use-o na plataforma Hugging Face https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B- v1. Você também pode deixar suas dúvidas ou sugestões na área de comentários. Obrigado por ler!
Fonte de informação
(1) Instituto de Pesquisa em Economia Digital da Grande Baía de Guangdong-Hong Kong-Macau (Instituto de Pesquisa IDEA). https://www.idea.edu.cn/. (2
) Centro de Pesquisa em Computação Cognitiva e Linguagem Natural-Instituto de Pesquisa IDEA. https:/ /www.idea.edu.cn/research/ccnl.html.
(3) IDEA-CCNL (Fengshenbang-LM) – Rosto Abraços. https://huggingface.co/IDEA-CCNL.