autor
Huang Lei, engenheiro sênior da Tencent Cloud, foi responsável pela construção de uma nova geração de sistema de monitoramento de negócios multidimensional para o Tencent Cloud Cloud Monitoring. Ele é bom em design de sistemas de monitoramento distribuído em larga escala e tem um profundo conhecimento da arquitetura do projeto de fundo golang Mais tarde, juntou-se à equipe da TKE e se dedicou ao estudo do Kubernetes. Relevante tecnologia de operação e manutenção, possui muitos anos de experiência na operação e gestão de manutenção da federação de cluster Kubernetes. Atualmente, a equipe é a principal responsável pela melhoria da observabilidade de federação de cluster em grande escala e liderou o desenvolvimento do sistema de monitoramento e alarme de cluster Kubernetes de nível 10.000 da Tencent Cloud, inspeção inteligente e sistema de detecção de risco.
Resumo
Se você perguntar ao autor quais componentes de código aberto são definitivamente usados ao gerenciar clusters do Kubernetes, o autor acha que o Prometheus será um deles. O Prometheus possui forte desempenho, ecologia ativa, métodos de implantação convenientes e PromQL flexível, que é especialmente adequado para monitorar a coleta e agregação de dados em todos os níveis, como mestre, nó e aplicativo em cenários do Kubernetes, combinado com o deslumbrante painel Grafana (como mostrado na figura abaixo), pode-se dizer que é a melhor solução para monitoramento nativo da nuvem.
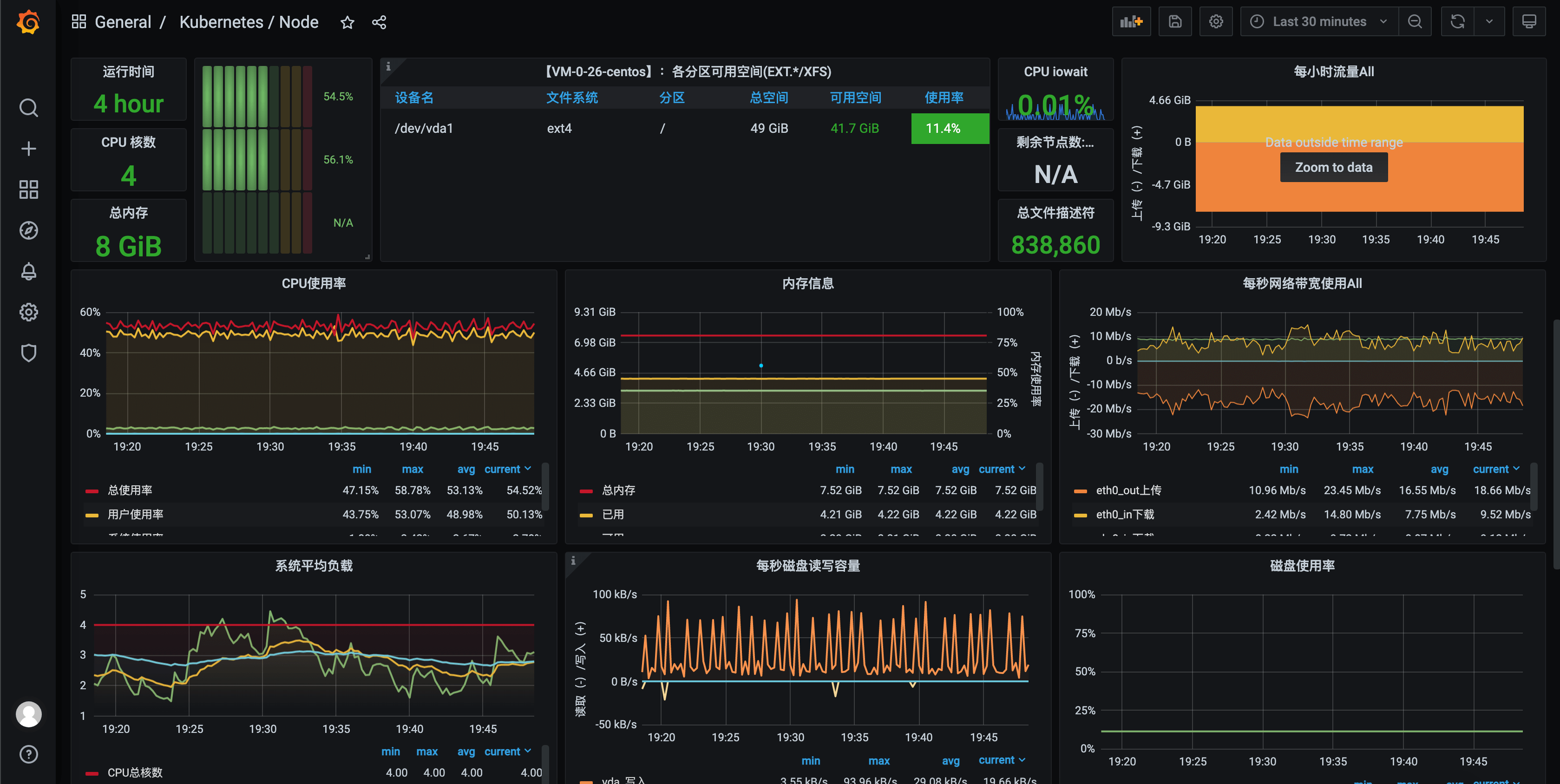
Embora Prometheus e Grafana sejam muito poderosos, quando entrei em contato com eles, ainda havia um certo custo de aprendizado e não foi fácil começar, o que é particularmente tocante para o autor. Lembro-me de alguns anos atrás, quando o autor não estava encarregado de melhorar a observabilidade nativa da nuvem da equipe, muitas vezes ouvi um amigo que era novo no Prometheus reclamando com o autor o dia todo: "Ei, por que a sintaxe do Prometheus tão complicado", "Essa coisa é muito nojenta, como escrever isso." Naquela época, o autor também ria dele por exagerar, mas quando também comecei a aprender Prometheus e comecei a combinar com o painel do Grafana, também fiz as mesmas reclamações, como a seguinte afirmação.
max(label_replace(
label_replace(
label_replace(
kube_deployment_status_replicas_unavailable,
"workload_kind","Deployment","","")
,"workload_name","$1","deployment","(.*)"),
"__name__", "k8s_workload_abnormal", "__name__","(.*)")
)
by (namespace, workload_name, workload_kind,__name__)
or on (namespace,workload_name,workload_kind, __name__) max(label_replace(
label_replace(
label_replace(
kube_daemonset_status_number_unavailable,
"workload_kind","DaemonSet","","")
,"workload_name","$1","daemonset","(.*)"),
"__name__", "k8s_workload_abnormal", "__name__","(.*)") ) by (namespace, workload_name, workload_kind,__name__)
or on (namespace,workload_name,workload_kind, __name__)
max(label_replace(
label_replace(
label_replace(
(kube_statefulset_replicas - kube_statefulset_status_replicas_ready),
"workload_kind","StatefulSet","","")
,"workload_name","$1","statefulset","(.*)"),
"__name__", "k8s_workload_abnormal", "__name__","(.*)") ) by (namespace, workload_name, workload_kind,__name__)
or on (namespace,workload_name,workload_kind, __name__)
max(label_replace(
label_replace(
label_replace(
(kube_job_status_failed),
"workload_kind","Job","","")
,"workload_name","$1","job_name","(.*)"),
"__name__", "k8s_workload_abnormal", "__name__","(.*)") ) by (namespace, workload_name, workload_kind,__name__)
or on (namespace,workload_name,workload_kind, __name__)
max(label_replace(
label_replace(
label_replace(
(kube_cronjob_info * 0),
"workload_kind","CronJob","","")
,"workload_name","","cronjob","(.*)"),
"__name__", "k8s_workload_abnormal", "__name__","(.*)") ) by (namespace, workload_name, workload_kind,__name__)
Nos últimos anos, o autor acumulou alguma experiência prática no processo de uso do Prometheus e também pisou em muitos buracos.
Para permitir que leitores e amigos que desejam aprender Prometheus comecem mais rapidamente, evitem desvios e melhorem as habilidades de monitoramento de negócios na era nativa da nuvem.
O autor organiza e resume uma versão do tutorial, incluindo alguns dos conceitos mais básicos e centrais, habilidades e melhores práticas para compartilhar com todos, para que todos possam dominar 80% das partes mais usadas em 20% do tempo.
Aprenda como expor indicadores de monitoramento para o seu negócio do zero, como configurar corretamente a descoberta de serviços e como configurar um painel Grafana prático, orientar os leitores a começar a usar o Prometheus+Grafana na velocidade da luz e dominar a postura correta da nuvem monitoramento nativo. foto
A conta oficial "Tencent Cloud Native" responde "Prometheus" ou "Light Speed Introduction" para obter o tutorial! Vamos aprender juntos!
Pequenas dicas: O livro didático atualmente possui uma versão do site (que precisa ser aberta em um navegador) e uma versão em PDF, e os calçados infantis podem visualizá-lo de acordo com suas próprias necessidades. A versão do site deste livro continuará sendo atualizada, você pode continuar prestando atenção~
Ao mesmo tempo, você pode enviar problemas para o tutorial. Este tutorial será atualizado, expandido e revisado de tempos em tempos com base em seus comentários!

(O endereço do GitHub do problema é mencionado)
A lista de livros é a seguinte


[Tencent Cloud Native] Novos produtos de Yunshuo, novas técnicas de Yunyan, novas atividades de Yunyou e informações de valorização da nuvem, digitalize o código para seguir a conta pública de mesmo nome e obtenha mais produtos secos a tempo! !
