O princípio básico do mestre-escravo do Mysql, a forma principal e o princípio de atraso da sincronização mestre-escravo (separação de leitura e gravação) levam ao problema e à solução
Primeiro, a diferença entre os bancos de dados mestre e escravo
O banco de dados escravo (escravo) é um backup do banco de dados mestre.Quando o banco de dados mestre (Mestre) é alterado, o banco de dados escravo deve ser atualizado.Este software de banco de dados pode projetar o ciclo de atualização. Este é um meio de melhorar a segurança da informação. O servidor de banco de dados mestre-escravo não está em um local geográfico e o banco de dados pode ser salvo quando ocorrer um acidente.
(1) Divisão de trabalho mestre-escravo
O mestre é responsável pela carga das operações de gravação, o que significa que todas as operações de gravação são executadas no mestre e as operações de leitura são alocadas ao escravo. Dessa maneira, a eficiência da leitura pode ser bastante aprimorada. Em aplicações gerais da Internet, após algumas pesquisas de dados, conclui-se que a proporção de leitura / gravação é de cerca de 10: 1, o que significa que um grande número de operações de dados está concentrado em operações de leitura, e é por isso que temos vários escravos. Razão. Mas por que separar leitura e escrita? Os desenvolvedores familiarizados com o DB sabem que as operações de gravação envolvem bloqueios, sejam bloqueios de linha, bloqueios de tabela ou bloqueios de bloco, que são relativamente coisas que reduzem a eficiência de execução do sistema. Nossa separação é concentrar a operação de gravação em um nó, enquanto a operação de leitura é executada nos outros nós N, o que melhora efetivamente a eficiência da leitura de outro aspecto e garante a alta disponibilidade do sistema.
(2) Processo básico
1) A sincronização mestre-escravo do Mysql significa que quando o mestre (banco de dados mestre) altera os dados, eles serão sincronizados com o escravo (banco de dados escravo) em tempo real.
2) A replicação mestre-escravo pode expandir horizontalmente a capacidade de carga do banco de dados, tolerância a falhas, alta disponibilidade e backup de dados.
3) Se é excluir, atualizar, inserir ou criar funções, procedimentos armazenados, estão no mestre, quando o mestre tiver operações, o escravo receberá rapidamente essas operações, para sincronizar.
(3) Usos e condições
1), finalidades de replicação mestre-escravo do MySQL
● Recuperação de desastre em tempo real, usada para failover
● Separação de leitura e gravação, fornece serviços de consulta
● Backup, para evitar afetar os negócios
2), condições necessárias da implantação do mestre-escravo:
● A biblioteca principal está aberta log binlog (definir parâmetro log-bin)
● O ID do servidor master-slave é diferente
● O servidor slave pode conectar-se ao banco de dados mestre
Segundo, a granularidade, princípio e forma da sincronização mestre-escravo:
(1), três principais granularidades de implementação
A sincronização mestre-escravo detalhada possui principalmente três formas: instrução, linha, mista
1), instrução: gravará a instrução SQL para operação de banco de dados no binlog
2), linha: cada As alterações de dados são gravadas no binlog.
3) Misto: declaração e linha são misturadas. O Mysql decide quando escrever o binlog no formato de instrução e quando escrever o binlog no formato de linha.
(2), o principal princípio de realização, operação específica, diagrama esquemático
1) Operação na máquina principal:
Quando os dados no mestre são alterados, a alteração do evento será gravada no log de posição em ordem. Quando o escravo estiver vinculado ao mestre, a máquina mestre iniciará o encadeamento de despejo de binlog para o escravo. Quando o log de bin do mestre for alterado, o encadeamento de despejo de log de bin notificará o escravo e enviará o conteúdo correspondente ao escravo.
2) Opere na máquina escrava:
Quando a sincronização mestre-escravo está ativada, dois encadeamentos são criados no escravo: encadeamentos de E / S. O encadeamento está conectado à máquina principal e o encadeamento de despejo de binlog na máquina principal envia o conteúdo do binlog para o encadeamento de E / S. Depois de receber o conteúdo do binlog, o encadeamento de E / S grava o conteúdo no log de retransmissão local, o encadeamento sql. Esse encadeamento lê o log de ralay gravado pelo encadeamento de E / S. E de acordo com o log de retransmissão. E de acordo com o conteúdo do log de retransmissão, faça a operação correspondente ao banco de dados escravo.
3) O diagrama de princípio da replicação mestre-escravo do MySQL é o seguinte:
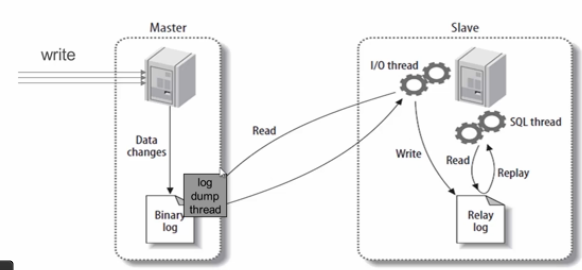
Gere dois encadeamentos da biblioteca, um encadeamento de E / S e um encadeamento SQL; o encadeamento de E / S
solicita o log de bin da biblioteca principal e grava o log de log de log obtido no arquivo de log de retransmissão (relay log); a
biblioteca principal gera Um encadeamento de despejo de log é usado para transferir o binlog para o encadeamento de E / S da biblioteca escrava; o encadeamento
SQL lê o log no arquivo de log de retransmissão e o analisa em operações específicas para obter operações consistentes de mestre-escravo e consistência final de dados;
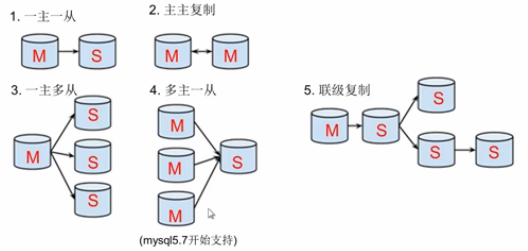
(2), forma mestre-escravo
a replicação mestre-escravo do mysql é flexível
● um mestre um escravo
● replicação mestre principal
● um escravo mestre --- expande o desempenho da leitura do sistema, porque a leitura é lida na biblioteca;
● multi-mestre um escravo --- 5.7
● replicação em cascata ---
3. Problemas, causas e soluções para o atraso da sincronização mestre-escravo:
(1) O atraso da sincronização do banco de dados mysql do banco de dados
1) parâmetros relacionados:
Primeiro, execute show slave satus no servidor; você pode ver muitos parâmetros sincronizados:
Master_Log_File: O nome do arquivo de log binário do servidor principal atualmente sendo lido pelo encadeamento de E / S no SLAVE Read_Master_Log_Pos: A posição do encadeamento de E / S no SLAVE que foi lido no log binário do servidor mestre atual Relay_Log_File: O encadeamento SQL está atualmente O nome do arquivo de log de retransmissão que é lido e executado Relay_Log_Pos: no atual log de retransmissão, o local em que o encadeamento SQL leu e executou Relay_Master_Log_File: O nome do arquivo de log binário do servidor mestre que contém os eventos mais recentes executados pelo encadeamento SQL Slave_IO_Running : Se o encadeamento de E / S foi iniciado e conectado com êxito ao servidor mestre Slave_SQL_Running: Se o encadeamento SQL foi iniciado Seconds_Behind_Master: O intervalo de tempo entre o encadeamento SQL do servidor escravo e o encadeamento de E / S do servidor escravo, em segundos.
Atraso de sincronização da biblioteca escravo ocorre ● show status do escravo mostra que o parâmetro Seconds_Behind_Master não é 0, esse valor pode ser grande ● show status do escravo mostra que os parâmetros Relay_Master_Log_File e Master_Log_File mostram que os números de log de bin são muito diferentes, indicando que o log de bin está na biblioteca de escravos Não há sincronização oportuna no computador, portanto, o log de bin recentemente executado é muito diferente do log de bin lido pelo thread de E / S atual. ● Existem muitos logs de mysql-relay-log no diretório de dados do banco de dados escravo do mysql. O sistema exclui automaticamente, existem muitos logs, indicando que o atraso da sincronização mestre-escravo é muito grave
(2) O atraso da sincronização do banco de dados MySql da biblioteca
1), princípio de atraso da sincronização mestre-escravo do banco de dados MySQL princípio da sincronização mestre-escravo do mysql: a biblioteca principal para operações de gravação, escreva binlog sequencialmente, da biblioteca de thread único para a leitura sequencial da biblioteca mestre "leitura operação binlog", obtenha o binlog da biblioteca, pois é localmente Execute (gravação aleatória) para garantir que os dados mestre e escravo sejam logicamente consistentes. A replicação master-slave do MySQL é uma operação de thread único. A biblioteca principal gera binlogs para todos os DDL e DML. Os binlogs são gravados seqüencialmente, portanto a eficiência é muito alta. O thread Slave_IO_Running do slave busca logs na biblioteca principal. Aí vem, o encadeamento Slave_SQL_Running do escravo implementa as operações DDL e DML da biblioteca principal no escravo. As operações de E / S do DML e DDL são aleatórias, não seqüenciais e o custo é muito mais alto. Também pode causar contenção de bloqueio para outras consultas no escravo.Como o Slave_SQL_Running também é de thread único, um mestre de cartão DDL precisa ser executado por 10 minutos. Em seguida, todo o DDL subsequente aguardará esse DDL concluir a execução antes de continuar, o que causa um atraso. Alguns amigos perguntam: "O mesmo DDL na biblioteca principal também precisa executar 10 pontos, por que o escravo está atrasado?" A resposta é que o mestre pode ser simultâneo, mas o encadeamento Slave_SQL_Running não é.
2) Como é gerado o atraso da sincronização mestre-escravo no banco de dados MySQL? Quando a simultaneidade TPS da biblioteca principal é alta, o número de DDL gerado excede o intervalo que um encadeamento sql escravo pode suportar, então o atraso é gerado e, é claro, pode haver uma espera de bloqueio com a instrução de consulta grande do escravo. O principal motivo: o banco de dados tem muita pressão de leitura e gravação nos negócios, a carga de cálculo da CPU é grande, a carga da placa de rede é pesada e a E / S aleatória do disco rígido é muito alta. Motivos secundários: impacto no desempenho causado pela leitura e gravação de binlog, atraso na transmissão da rede.
(3), a solução de atraso da sincronização do banco de dados MySql da biblioteca
1) 、 Arquitetura
1. A implementação da camada de persistência de negócios adota uma arquitetura de sub-banco de dados e o serviço mysql pode ser estendido em paralelo para dispersar a pressão.
2. Leitura e escrita separadas de uma única biblioteca, um mestre e muitos escravos, a leitura mestre e escrava, dispersam a pressão. Dessa maneira, a pressão do armazenamento secundário é maior que a do armazenamento primário, protegendo o armazenamento primário.
3. A infraestrutura do serviço adiciona camada de cache memcache ou redis entre os negócios e o mysql. Reduza a pressão de leitura do mysql.
4. O MySQL de diferentes empresas é fisicamente colocado em diferentes máquinas para dispersar a pressão.
5. Use um dispositivo de hardware melhor que a biblioteca principal como um resumo do escravo, a pressão do mysql é pequena, o atraso naturalmente se tornará menor.
2), hardware
1. Use um bom servidor.Por exemplo, 4u é significativamente melhor que 2u e 2u é melhor que 1u.
2. O armazenamento usa SSD ou matriz de disco ou san para melhorar o desempenho da gravação aleatória.
3. A sala mestre-escravo é garantida para estar sob o mesmo comutador e em um ambiente de 10 Gigabit.
Em resumo, o hardware é forte e o atraso naturalmente se tornará menor. Em suma, a solução para reduzir a latência é gastar dinheiro e tempo.
3), aceleração de sincronização mysql master-slave
1. Sync_binlog está definido como 0 no lado do escravo
2. –logs-slave-updates As atualizações recebidas pelo servidor escravo do servidor mestre não são registradas em seu log binário.
3. Desative diretamente o binlog no lado escravo
4. No lado do escravo, se o mecanismo de armazenamento usado for innodb, innodb_flush_log_at_trx_commit = 2
4), otimização da perspectiva do próprio sistema de arquivos
O fim mestre modifica o atributo etime dos arquivos nos sistemas de arquivos Linux e Unix.Como o sistema operacional gravará novamente o tempo em que a operação de leitura ocorrer no disco ao ler o arquivo, isso não será necessário para arquivos de banco de dados com operações de leitura frequentes. Ele apenas aumenta a carga no sistema de disco e afeta o desempenho de E / S. Você pode organizar o sistema operacional para gravar informações atime configurando o atributo mount do sistema de arquivos.A operação no Linux é: open / etc / fstab, adicione o parâmetro noatime / dev / sdb1 / data reiserfs noatime 1 2 e remonte o sistema #mount -oremount / data
5) A biblioteca principal para o ajuste dos parâmetros de sincronização é gravada, com alta segurança de dados, como sync_binlog = 1, innodb_flush_log_at_trx_commit = 1, e outras configurações são necessárias, mas o escravo não precisa de alta segurança de dados, você pode dizer que sync_binlog está definido como 0 ou fechar o binlog, innodb_flushlog também pode ser definido como 0 para melhorar a eficiência da execução do sql
1. sync_binlog = 1 oMySQL fornece um parâmetro sync_binlog para controlar o binlog do banco de dados a piscar em disco. Por padrão, sync_binlog = 0, o que significa que o MySQL não controla a atualização do binlog e a atualização de seu cache é controlada pelo próprio sistema de arquivos. O desempenho neste momento é o melhor, mas o risco também é o maior. Quando o sistema travar, todas as informações do binlog em binlog_cache serão perdidas.
Se sync_binlog> 0, significa que toda transação sync_binlog é confirmada, o MySQL chama a operação de atualização do sistema de arquivos para liberar o cache. O mais seguro é sync_binlog = 1, o que significa que o MySQL reduz o binlog toda vez que uma transação é enviada, o que é mais seguro, mas tem a configuração de perda de desempenho mais alta. Nesse caso, o sistema pode perder os dados de uma transação somente quando o sistema operacional do host em que o banco de dados está localizado estiver danificado ou perder energia repentinamente. Embora o binlog seja IO sequencial, mas defina sync_binlog = 1, várias transações são enviadas ao mesmo tempo, o que também afeta muito o desempenho do MySQL e IO. Embora possa ser aliviado pelo patch de confirmação do grupo, o impacto da frequência excessiva de atualização nas E / S também é muito grande.
Para sistemas com transações simultâneas altas, a diferença entre o desempenho de gravação do sistema com "sync_binlog" definido como 0 e 1 pode chegar a 5 vezes ou mais. Portanto, o sync_binlog definido por muitos DBAs do MySQL não é o mais seguro, mas 2 ou 0. Isso sacrifica certa consistência para obter maior simultaneidade e desempenho. Por padrão, o binlog não é sincronizado com o disco rígido toda vez que é gravado. Portanto, se o sistema operacional ou a máquina (não apenas o servidor MySQL) travar, é possível que a última instrução no binlog seja perdida. Para evitar isso, você pode usar a variável global sync_binlog (1 é o valor mais seguro, mas também o mais lento) para sincronizar o log de bin com o disco rígido após a gravação de cada N binlog. Mesmo se sync_binlog estiver definido como 1, pode haver uma inconsistência entre o conteúdo da tabela e o conteúdo do binlog quando ocorrer uma falha.
2. Innodb_flush_log_at_trx_commit (isso funciona) reclama que o Innodb é 100 vezes mais lento que o MyISAM? Então você provavelmente esqueceu de ajustar esse valor. O valor padrão 1 significa que todas as instruções de confirmação ou fora de transação de transação exigem que o log seja liberado no disco rígido, o que consome tempo. Especialmente ao usar o cache de backup de bateria. Definido como 2 para muitos aplicativos, especialmente a transferência da tabela MyISAM, significa não gravado no disco rígido, mas gravado no cache do sistema. Os logs ainda serão liberados para o disco rígido a cada segundo, para que você normalmente não perca mais de um ou dois segundos de atualizações. Definir como 0 será mais rápido, mas a segurança é relativamente baixa, mesmo se o MySQL travar, ele poderá perder os dados da transação. O valor 2 somente perderá dados quando o sistema operacional inteiro travar.
3. O comando ls (1) pode ser usado para listar atime, ctime e mtime de arquivos.
O horário de acesso do arquivo atime altera o horário de criação do arquivo ctime ao ler o arquivo ou o executa. Quando o arquivo é gravado, o proprietário, as permissões ou as configurações de link são alteradas quando o conteúdo do inode é alterado. O horário modificado do arquivo mtime é alterado quando o arquivo é gravado. Quando o conteúdo do arquivo é alterado, ls -lc nome do arquivo ctimels do arquivo -lu nome do arquivo lima atimels do arquivo -l nome do arquivo mtimestat nome do arquivo do arquivo lime atime, mtime, ctimeatime não são necessariamente modificados após acessar o arquivo porque : Ao usar o sistema de arquivos ext3, se o parâmetro noatime for usado durante a montagem, as informações do atime não serão atualizadas. Esses três carimbos de hora são todos colocados no inode. Se mtime e atime forem modificados, o inode será alterado. Como o inode é alterado, o ctime também será alterado. A razão pela qual o noatime é usado na opção de montagem é que eu não quero que o sistema de arquivos faça isso. Muitas modificações para melhorar o desempenho da leitura
(4), banco de dados MySql da biblioteca para sincronizar outros problemas e soluções
1) Problemas com a replicação master-slave do mysql: ● Os dados podem ser perdidos depois que o banco de dados mestre está inoperante ● Existe apenas um thread sql no banco de dados escravo, o banco de dados mestre tem uma grande pressão de gravação e é provável que a replicação seja adiada 2) Solução: ● Replicação semi-síncrona --- Solucionar o problema de perda de dados ● Replicação paralela ---- Solucionar o problema de replicação atrasada da biblioteca
3), replicação semi-síncrona mysql replicação semi-síncrona (replicação semi-síncrona): ● 5.5 está integrado ao mysql, existe na forma de um plug-in e precisa ser instalado separadamente. ● garantir que o binlog seja transferido para pelo menos uma biblioteca escrava após o envio da transação. O binlog depois que a biblioteca aplicou essa transação ● O desempenho será reduzido até certo ponto e o tempo de resposta será mais longo ● A rede está anormal ou a biblioteca escrava está inativa, a biblioteca principal do cartão, até o tempo limite ou a recuperação da biblioteca 4), princípio da replicação assíncrona do mestre escravo , Comparação de princípios de replicação semi-síncrona e paralela
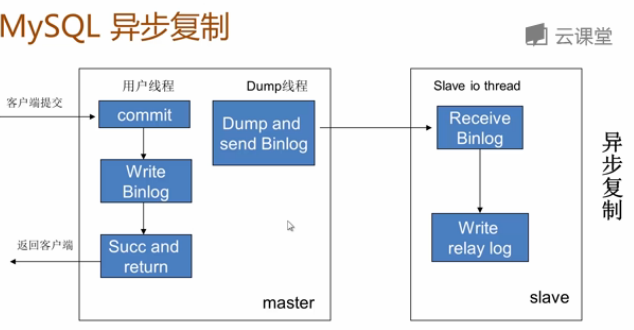
a) O princípio da replicação assíncrona:
b) O princípio da replicação semi-síncrona:
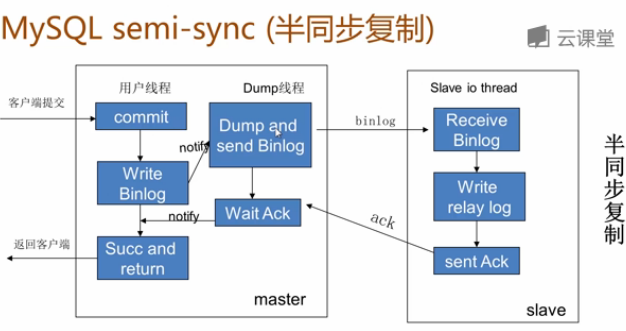
A transação precisa retornar um aceito da biblioteca depois de gravar o binlog na biblioteca principal e depois devolvê-lo ao cliente; 5.5 é integrado ao mysql e existe na forma de um plug-in. Ele precisa ser instalado separadamente para garantir que o binlog seja transferido para pelo menos uma biblioteca escrava após o envio da transação. O desempenho do binlog do aplicativo escravo para concluir esta transação tem uma certa redução nas anormalidades da rede ou no tempo de inatividade do escravo, na biblioteca principal do cartão, até o tempo limite ou a recuperação da biblioteca
Replicação paralela Replicação paralela do mysql ● Novo na comunidade versão 5.6 ● Parallel refere-se ao binlog de aplicação multithread da biblioteca ● Aplicação paralela no nível binário do binlog, as mesmas alterações de dados da biblioteca ou configuração serial (replicação paralela versão 5.7 baseada no grupo de transações) defina global slave_parallel_workers = 10; defina o número de threads sql para 10
Princípio: No binlog de aplicação multithread da biblioteca, um novo aplicativo paralelo de binlog no nível de biblioteca é adicionado na comunidade 5.6. Os mesmos dados da biblioteca são alterados ou replicação paralela da versão 5.7 serial com base no grupo de transações
Referência: https://blog.csdn.net/hao_yunfeng/article/details/82392261