1. Visão geral da estrutura
Em primeiro lugar, analisamos o processamento de imagens por redes neurais tradicionais. Se você ainda usa imagens no CIFAR-10, há um total de 3072 recursos. Se a estrutura de rede normal for inserida, cada unidade neural na primeira camada terá 3072 pesos. Se for maior Depois de inserir a imagem do pixel, há mais parâmetros e a rede usada para o processamento da imagem geralmente tem uma profundidade de mais de 10 camadas. Juntos, a quantidade de parâmetros é muito grande e muitos parâmetros causarão sobreajuste, e a imagem também tem seu Recursos, precisamos usar esses recursos para reformar a rede tradicional para acelerar a velocidade de processamento e precisão.
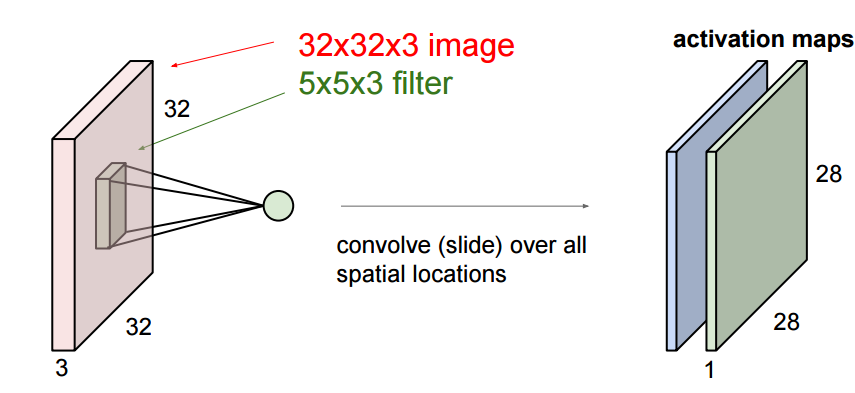
Notamos que os pixels da imagem são compostos por 3 canais, e aproveitamos esse recurso para colocar seus neurônios em um espaço tridimensional (largura, altura, profundidade), correspondendo aos 32x32x3 da imagem (tome o CIFAR como exemplo) conforme mostrado abaixo : 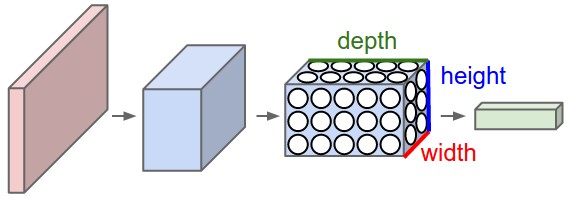
Vermelho é a camada de entrada onde a profundidade é 3, e a camada de saída é uma estrutura 1x1x10. O significado das outras camadas será apresentado mais tarde, e agora sabemos primeiro que cada camada tem uma estrutura de altura x largura x profundidade .
2. Camadas de rede neural convolucional
As redes neurais convolucionais têm três camadas: camada convolucional, camada pooling e camada totalmente conectada (camada convolucional, camada pooling e camada totalmente conectada).
Pegue a rede neural convolucional CIFAR-10 como exemplo. Uma rede simples deve conter estas camadas:
[INPUT-CONV-RELU-POOL-FC] que é [pontuação de classificação de entrada-convolução-ativação-agrupamento], As camadas são descritas a seguir:
- INPUT [32x32x3] Comprimento de entrada 32 largura 32 imagem com três canais
- CONV: Calcula a área local da imagem.Se quisermos usar 12 filtros, seu volume será [32x32x12].
- RELU: Ainda é uma camada de excitação max (0, x), e o tamanho ainda é ([32x32x12]).
- PISCINA: Amostragem ao longo da (largura, altura) da imagem, reduzindo as dimensões de comprimento e largura, por exemplo, o resultado é [16x16x12].
- FC (ou seja, totalmente conectado) calcula que o tamanho final da pontuação de classificação é [1x1x10], esta camada está totalmente conectada e cada unidade é conectada a cada unidade da camada anterior.
Nota:
1. Volumes e redes neurais contêm camadas diferentes (por exemplo, CONV / FC / RELU / POOL também são os mais populares)
2. Cada camada entra e produz dados de estrutura 3d, exceto para a última camada
3. Algumas camadas podem não Parâmetros, algumas camadas podem ter parâmetros (por exemplo, CONV / FC faz, RELU / POOL não)
4. Algumas camadas podem ter hiperparâmetros e algumas camadas podem não ter hiperparâmetros (por exemplo, CONV / FC / POOL tem, RELU não)
A figura abaixo é um exemplo, não pode ser representada em três dimensões e só pode ser expandida em uma coluna. 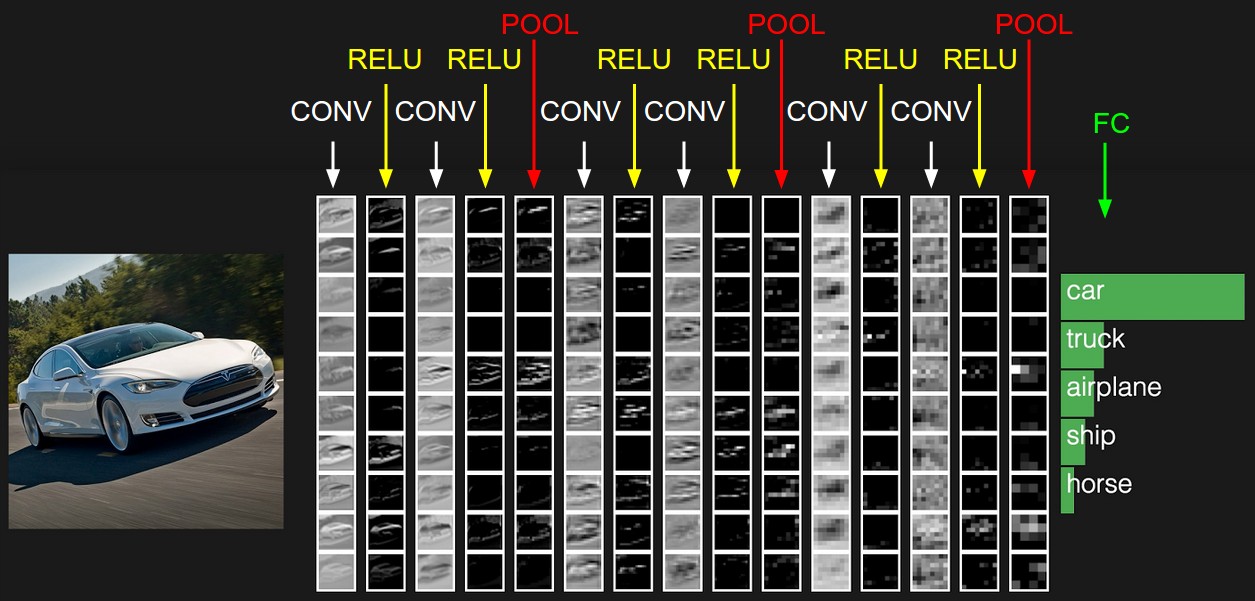
Os detalhes específicos de cada camada são discutidos abaixo:
2.1 Camada convolucional
A camada convolucional é a camada central da rede neural convolucional, o que melhora muito a eficiência computacional.
A camada convolucional é composta por vários filtros, cada filtro possui apenas uma pequena parte, cada vez que é conectado apenas a uma pequena parte da imagem original, a imagem em UFLDL:
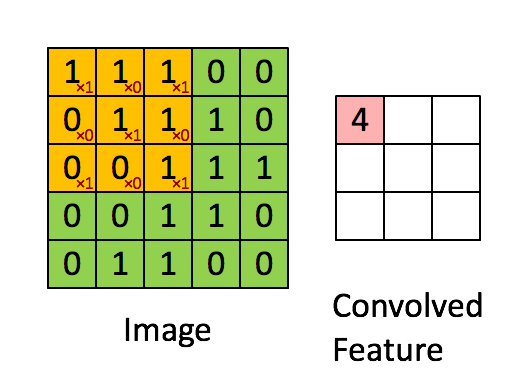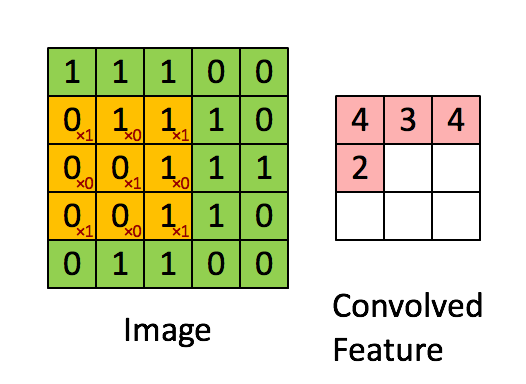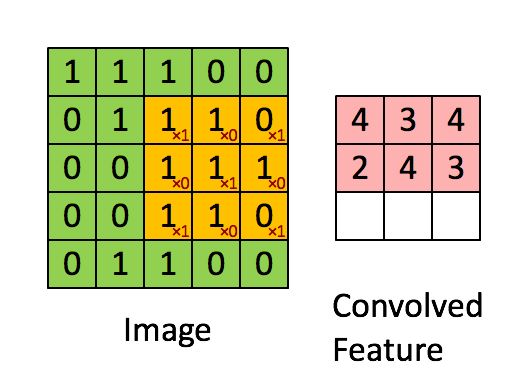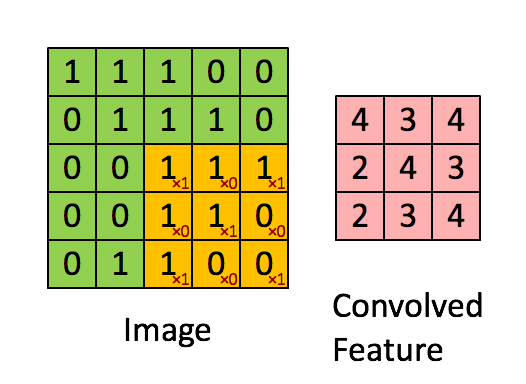
isso é o resultado de um filtro que fica deslizando,
aqui estamos Para ir mais fundo, a imagem que inserimos é tridimensional, então cada filtro também tem três dimensões. Supondo que nosso filtro seja 5x5x3, também obteremos um mapeamento semelhante ao valor de ativação na imagem acima, que é convolvido característica é chamada de mapa de ativação na figura abaixo, e seu método de cálculo é wT × x + bwT × x + b, onde w é 5x5x3 = 75 dados, que é o peso, que pode ser ajustado.
Podemos ter vários filtros:
Vá mais fundo, há três hiperparâmetros quando deslizamos:
1. Profundidade, profundidade, que é determinada pelo número de filtros.
2. Passada, passada, o intervalo de cada deslizamento, a animação acima desliza apenas 1 número por vez, ou seja, o comprimento do passo é 1.
3. O número de preenchimento de zero, preenchimento de zero, às vezes conforme necessário, usará zero Expanda a área da imagem. Se o número de zeros for 1, o comprimento torna-se +2. A parte cinza na figura
abaixo é o zero do complemento. Abaixo está um exemplo unidimensional: 
a fórmula de cálculo da dimensão do espaço de saída é
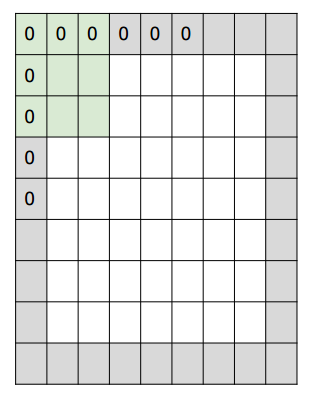
(W − F + 2P) / S + 1 (W − F + 2P) / S + 1
Onde w é o tamanho da entrada, f é o tamanho do filtro, p é o tamanho do preenchimento de zero e s é o tamanho do passo. Na figura, se o preenchimento de zero for 1, a saída é 5 números e o tamanho do passo é 2 e a saída é 3 números. Até
agora, parece que não envolvemos o conceito de nervo uau, agora entendemos isso de uma perspectiva neurológica:
cada valor de ativação mencionado acima é: wT × x + bwT × x + b, essa fórmula é familiar para nós uau, isso É a fórmula de pontuação dos neurônios, então podemos considerar cada mapa de ativação como uma obra-prima de um filtro.Se houver 5 filtros, haverá 5 filtros diferentes conectados a uma parte ao mesmo tempo.
As redes neurais convolucionais têm outra característica importante: compartilhamento de peso : os pesos de diferentes unidades neurais (janelas deslizantes) no mesmo filtro são os mesmos. Isso reduz muito o número de pesos.
Desta forma, o peso de cada camada é o mesmo, e o resultado de cada cálculo do filtro é uma convolução (um bias b será adicionado posteriormente):
esta também é a fonte do nome da rede neural convolucional.
A imagem abaixo está errada, consulte o site oficial http://cs231n.github.io/convolutional-networks/#conv , descubra o erro e entenda o princípio de funcionamento da convolução.
Embora o peso w de cada filtro seja alterado em três partes aqui, a forma de wx + b ainda é usada no neurônio.
-Backpropagation: A retropropagação deste tipo de convolução ainda é convolução, e o processo de cálculo é relativamente simples
convolução -1x1: Alguns artigos usam convolução 1 * 1, como a primeira Rede na RedeIsso pode fazer vários produtos internos com eficácia. A entrada tem três camadas, então cada camada deve ter pelo menos três ws, ou seja, o filtro do gráfico dinâmico acima é alterado para 1x1x3.
- Convoluções dilatadas. Recentemente, há pesquisas ( por exemplo, consulte o artigo de Fisher Yu e Vladlen Koltun ) adicionaram um hiperparâmetro à camada convolucional: dilatação. Este é mais um controle do filtro. Vamos ativar o efeito: quando a dilatação for igual a 0, calcule a convolução w [0] x [0] + w [1] x [1] + w [2] x [2]; dilatação Quando = 1, fica assim: w [0] x [0] + w [1] x [2] + w [2] x [4]; ou seja, cada imagem que queremos processar é separada por 1. Isso Isso permite o uso de menos camadas para fundir informações espaciais. Por exemplo, usamos duas camadas 3x3 CONV na camada superior, esta é a segunda camada que desempenha o papel de 5x5 (campo receptivo efetivo). Se você usar convoluções dilatadas, isso é eficaz O campo receptivo crescerá exponencialmente.

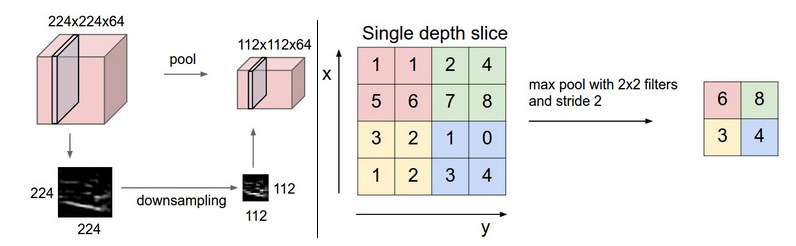
2.2 Camada de pooling
Pode ser visto do acima que ainda existem muitos resultados obtidos após a camada convolucional e, devido à existência da janela deslizante, muitas informações também são sobrepostas, portanto, há uma camada de agrupamento, que divide os resultados obtidos pela camada convolucional em vários pontos sem sobreposição. Parte e, em seguida, selecione o valor máximo de cada parte, ou média, ou 2 norma, ou outros valores que você gosta. Vamos pegar o pool máximo com o valor máximo como exemplo:
-Backpropagation: O gradiente do valor máximo era anteriormente Eu já aprendi durante a propagação, aqui geralmente rastreamos o valor máximo de ativação, para que a eficiência seja melhorada durante a retropropagação. -
Livrar-se do pooling. Algumas pessoas pensam que o pool é desnecessário, como The All Convolutional Net Muitas pessoas pensam que nenhuma camada de pool é importante para modelos generativos. Parece que a camada de pool pode diminuir gradualmente ou desaparecer no desenvolvimento futuro.
2.3 Outras camadas
- Camada de normalização, no passado, a camada de normalização era usada para simular o efeito inibitório do cérebro humano, mas gradualmente acho que não é muito útil, então eu a uso menos. Este artigo apresenta seu papel na biblioteca cuda-convnet API de Alex Krizhevsky.
- Camada totalmente conectada, esta camada totalmente conectada é a mesma que aprendemos antes. Conforme mencionado anteriormente, a camada de classificação final é uma camada totalmente conectada.
2.4 Conversão de camadas FC em camadas CONV
Exceto para os diferentes métodos de conexão, a camada totalmente conectada e a camada convolucional são calculadas em produtos internos, que podem ser convertidos entre si:
1. Se o FC faz o trabalho da camada CONV, é equivalente à maioria das posições de sua matriz são 0 (matriz esparsa).
2. Se a camada FC for convertida em uma camada CONV. É equivalente à conexão parcial de cada camada torna-se todos os links. Por exemplo, a entrada da camada FC com K = 4096 é 7 × 7 × 512, então a camada convolucional correspondente é F = 7, P = 0, S = 1, K = 4096 a saída é 1 × 1 × 4096.
Exemplo:
suponha que um cnn insira uma imagem de 224x224x3 e, após várias alterações, uma camada produza 7x7x512. Depois disso, duas camadas de 4096 FC e os últimos 1000 FC são usados para calcular a pontuação de classificação. Abaixo está o processo de conversão dessas três camadas de fc em Conv:
1 . Use a camada conv com F = 7 para a saída [1x1x4096];
2. Use o filtro com F = 1 para a saída [1x1x4096];
3. Use a camada conv com F = 1 para a saída [1x1x1000].
Cada conversão irá converter os parâmetros FC em parâmetros conv. Se uma imagem maior for passada no sistema convertido, ela também será calculada muito rapidamente. Por exemplo, se você inserir uma imagem 384x384 no sistema acima, obterá a saída de [12x12x512] antes das últimas três camadas, e a camada conv convertida acima terá [6x6x1000], ((12-7) / 1 + 1 = 6). Nós Um resultado de classificação 6x6 foi obtido em um clique.
Isso é mais rápido do que as 36 iterações originais. Esta é uma técnica em aplicação prática.
Além disso, podemos usar duas camadas convolucionais com um tamanho de etapa de 16 em vez de uma camada convolucional com um tamanho de etapa de 32 para inserir a imagem acima para melhorar a eficiência.
3 Construa uma rede neural convolucional
Abaixo, usaremos CONV, POOL, FC, RELU para construir uma rede neural convolucional:
3.1 Hierarquia
Construímos de acordo com a seguinte estrutura
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FCOnde N> = 0 (geralmente N <= 3), M> = 0, K> = 0 (geralmente K <3).
Observação aqui: preferimos usar CONV multicamadas e de tamanho pequeno.
porque?
Por exemplo, 3 3x3 e uma camada conv 7x7, todos eles podem obter campos receptivos 7x7. Mas 3x3 tem as seguintes vantagens:
1. A combinação não linear de
3 camadas tem capacidade expressiva mais forte do que a combinação linear de 1 camada ; 2. 3 camadas O número de parâmetros da camada convolucional de tamanho pequeno é menor, 3x3x3 <7x7;
3. Na retropropagação, precisamos usar mais memória para armazenar os resultados da camada intermediária.
É importante notar que as arquiteturas Inception do Google e Redes Residuais da Microsoft Research Asia. Ambas criaram uma estrutura de conexão mais complexa do que a estrutura acima.
3.2 Tamanho da camada
- Camada de entrada: A camada de entrada geralmente está na forma exponencial de 2, como 32 (por exemplo, CIFAR-10), 64, 96 (por exemplo, STL-10) ou 224 (por exemplo, ConvNets ImageNet comuns), 384, 512, etc.
- Camada convolucional: geralmente um filtro pequeno como 3x3 ou 5x5 máximo, o tamanho do passo é definido como 1, ao adicionar preenchimento de zero, a camada convolucional não pode alterar o tamanho da entrada, se você deve usar um filtro grande, muitas vezes está no primeiro A primeira camada usa o método de preenchimento de zero P = (F − 1) / 2.
- Camada de pooling: uma configuração comum é usar uma camada de pooling máxima de 2x2 e raramente há uma camada de pooling máxima excedendo 3x3.
- Se o tamanho do nosso passo for maior que 1 ou não houver preenchimento zero, precisamos prestar muita atenção se o tamanho do passo e o filtro são suficientemente robustos e se nossa rede está conectada de maneira uniforme e simétrica.
- Um tamanho de etapa de 1 tem melhor desempenho e é mais compatível com agrupamento.
- A vantagem do preenchimento de zero: se você não preencher o zero, as informações de borda serão rapidamente descartadas
- Considere as limitações de memória do computador. Por exemplo, insira uma imagem de 224x224x3, o filtro é 3x3, um total de 64 filtros e o preenchimento é 1. Cada imagem requer 72 MB de memória, mas se for executado na GPU, a memória pode não ser suficiente, então você pode ajustar os parâmetros como filtro para 7x7 e avanço para 2 (rede ZF ). Ou filer11x11, passo de 4. (AlexNet)
3.3 Caso
- LeNet. A primeira aplicação bem-sucedida do cnn (Yann LeCun nos anos 1990). Seus pontos fortes são códigos postais, dígitos, etc.
- AlexNet. O primeiro amplamente utilizado em visão computacional (por Alex Krizhevsky, Ilya Sutskever e Geoff Hinton). O desafio ImageNet ILSVRC em 2012 brilha, semelhante à estrutura LeNet, mas mais profunda e maior, com camadas convolucionais multicamadas sobrepostas.
- ZF Net. Vencedor do ILSVRC 2013 (Matthew Zeiler e Rob Fergus). Tornou-se conhecido como ZFNet (abreviação de Zeiler & Fergus Net). Ajustou os parâmetros estruturais de Alexnet, expandiu a camada convolucional intermediária para fazer a primeira camada de filtros E o tamanho do passo é reduzido.
- GoogLeNet. O vencedor do ILSVRC 2014 (Szegedy et al. Do Google.) Reduziu muito o número de parâmetros (de 60M para 4M). Usando o Pooling médio em vez da primeira camada FC do ConvNet, eliminando muitos parâmetros, há muitos Variantes como: Inception-v4.
- VGGNet. O vice-campeão no ILSVRC 2014 (Karen Simonyan e Andrew Zisserman) provou os benefícios da profundidade. Pode ser usado no Caffe. Mas há muitos parâmetros, (140M) e muitos cálculos. Mas agora há muitos desnecessários Os parâmetros podem ser removidos.
- ResNet. (Kaiming He et al). Vencedor do ILSVRC 2015. Em 10 de maio de 2016, este é o modelo mais avançado. Há também uma versão aprimorada de Identity Mappings in Deep Residual Networks (publicado em março de 2016) .
Entre eles, o VGG O custo de cálculo é:
INPUT: [224x224x3] memory: 224*224*3=150K weights: 0
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parametersObserve que quando a memória é mais usada, nas primeiras camadas CONV, os parâmetros estão basicamente nas últimas camadas FC.O primeiro FC tem 100M!
3.4 Uso de memória
A memória é consumida principalmente nos seguintes aspectos:
1. Um grande número de valores de ativação e valores de gradiente. Ao testar, você só pode armazenar o valor de ativação atual e descartar os valores de ativação anteriores nas camadas inferiores, o que reduzirá muito a quantidade de armazenamento de valor de ativação.
2. O armazenamento de parâmetros, o gradiente durante a retropropagação e o cache quando momentum, Adagrad ou RMSProp são usados, irão ocupar o armazenamento, então a memória usada pelos parâmetros estimados geralmente deve ser multiplicada por pelo menos 3 vezes
3. Cada vez que a rede é executada Lembre-se de todos os tipos de informações, como lote de dados gráficos, etc.
Se for estimado que a memória exigida pela rede é muito grande, pode-se reduzir adequadamente o lote de imagens, afinal, o valor de ativação ocupa muito espaço na memória.
outra informação
- Benchmarks de Soumith para desempenho de CONV
- Demonstração em tempo real da ConvNets do navegador de demonstração ConvNetJS CIFAR-10 .
- Caffe , a ferramenta ConvNets popular
- ResNets de última geração em Torch7
