1 Visão geral das redes neurais convolucionais profundas
1.1 Diagrama de estrutura do modelo de rede neural convolucional profunda
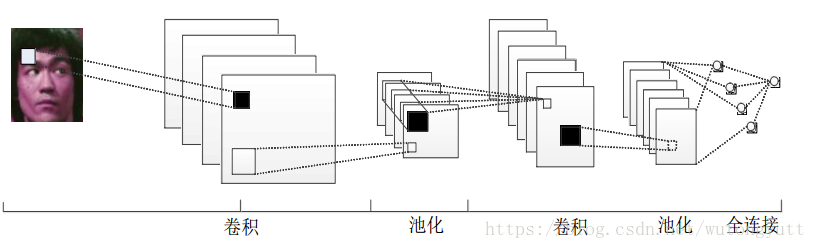
1.1.1 Análise da estrutura direta da rede neural convolucional profunda
- Na camada de entrada, cada pixel é alimentado na rede como um nó de recurso.
- Camada convolucional: composta por vários filtros.
- Camada de pooling: Reduza a dimensionalidade do resultado da convolução e execute o processamento de redução de dimensionalidade no mapa de recursos após a convolução para obter recursos mais significativos. Com base nos recursos originais do gráfico, a quantidade de operações subsequentes é reduzida.
- Camada de pool de média global: Pegue a média global dos mapas de recursos gerados, essa camada pode ser substituída por uma rede totalmente conectada.
- Camada de saída: A rede precisa dividir os dados em várias categorias, esta camada possui vários nós de saída, cada nó de saída representa a probabilidade de pertencer à amostra atual daquele tipo.
1.2 Etapas de retropropagação de redes neurais convolucionais
(1) Passe o erro para a camada anterior. Quando a derivação reversa da operação de convolução é realizada, o mapa de características gerado precisa ser preenchido uma vez, e então uma operação de convolução é executada com o kernel de convolução transposto para obter a beleza errada de a extremidade de entrada, e a transmissão reversa do erro é realizada.
(2) Calcule o valor da diferença que precisa ser atualizado de acordo com a expressão do parâmetro de aprendizado correspondente ao erro atual, que é o mesmo que a derivação reversa na rede totalmente conectada. A regra da cadeia ainda é usada para encontrar e minimizar o erro .O grau horizontal de , e depois com a taxa de aprendizado para calcular a diferença atualizada.
2 Operação de agrupamento
2.1 Visão geral da operação de agrupamento
2.1.1 O papel das operações de agrupamento
O principal objetivo da redução de dimensionalidade é minimizar o tamanho da matriz, mantendo as características originais.
2.1.2 Comparação de Agrupamento e Convolução
Pooling: só se preocupe com o tamanho do filtro, principalmente pegue o valor médio ou máximo dos pixels na área de mapeamento do filtro.
Convolução: O produto de pixels nas posições correspondentes.
2.2 Classificação das operações de pooling
2.2.1 Agrupamento Médio
Na área correspondente ao tamanho do filtro na imagem, é obtido o valor médio de todos os seus pixels, que é mais sensível às informações de fundo.
2.2.2 Agrupamento Máximo
A área correspondente ao tamanho do filtro na imagem assume o valor máximo para todos os seus pixels, que é mais sensível às características de textura.
2.2 Interface de função de agrupamento
2.2.1 Função de pooling médio
nn.AvgPool2d - operação de pooling médio bidimensional  https://blog.csdn.net/qq_50001789/article/details/120537858
https://blog.csdn.net/qq_50001789/article/details/120537858
torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None)- kernel_size: o tamanho do kernel de pool
- stride: o passo em movimento da janela, o padrão é o mesmo tamanho que kernel_size
- preenchimento: tamanho de largura de preenchimento zero em ambos os lados
- ceil_mode: Quando definido como True, a operação de arredondamento é usada no processo de cálculo da forma de saída, caso contrário, a operação de arredondamento é usada
- count_include_pad: boolean, quando True, zero padding será incluído no cálculo de pool médio, caso contrário, zero padding não será incluído
- divisor_override: Se especificado, o divisor será substituído por divisor_override. Em outras palavras, se esta variável não for especificada, o processo de cálculo do pooling médio está na verdade em um kernel pooling, somando os elementos e dividindo pelo tamanho do kernel pooling, ou seja, divisor_override assume como padrão a altura do kernel pooling × wide; se esta variável for especificada, o processo de agrupamento será a soma dos elementos no kernel agrupado e dividido por divisor_override.
2.2.2 Função de Agrupamento Máximo
class torch.nn.MaxPool1d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)- kernel_size (int ou tuple) – tamanho da janela para pool máximo
- stride(int ou tupla, opcional) – O passo do movimento da janela para o agrupamento máximo. O valor padrão é kernel_size
- padding(int ou tupla, opcional) - o número de camadas para adicionar 0 a cada borda da entrada
- dilatação (int ou tupla, opcional) – um parâmetro que controla o passo dos elementos na janela
- return_indices - se igual a True, retornará o índice do valor máximo de saída, o que é útil para operações de upsampling
- ceil_mode - se for igual a True, ao calcular o tamanho do sinal de saída, ele usará arredondamento para cima em vez da operação padrão de arredondamento para baixo
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)- kernel_size (int ou tuple) – tamanho da janela para pool máximo
- stride(int ou tupla, opcional) – O passo do movimento da janela para o agrupamento máximo. O valor padrão é kernel_size
- padding(int ou tupla, opcional) - o número de camadas para adicionar 0 a cada borda da entrada
- dilatação (int ou tupla, opcional) – um parâmetro que controla o passo dos elementos na janela
- return_indices - se igual a True, retornará o índice do valor máximo de saída, o que é útil para operações de upsampling
- ceil_mode - se for igual a True, ao calcular o tamanho do sinal de saída, ele usará arredondamento para cima em vez da operação padrão de arredondamento para baixo
2.3 O combate real da função de pooling
2.3.1 Definindo variáveis de entrada --- pool2d.py (Parte 1)
import torch
### 1.1 定义输入变量
img = torch.tensor([
[[0.0,0.0,0.0,0.0],[1.0,1.0,1.0,1.0],[2.0,2.0,2.0,2.0],[3.0,3.0,3.0,3.0]],
[[4.0,4.0,4.0,4.0],[5.0,5.0,5.0,5.0],[6.0,6.0,6.0,6.0],[7.0,7.0,7.0,7.0]]
]).reshape([1,2,4,4]) # 定义张量,模拟输入图像
print(img) # 输出结果
print(img[0][0]) # 输出第1通道的内容# Saída:
# tensor([[0, 0, 0, 0],
# [1, 1, 1, 1],
# [2, 2, 2, 2],
# [3, 3, 3, 3]] )
print(img[0][1]) # saída do conteúdo do canal 2
# saída:
# tensor([[4, 4, 4, 4],
# [5, 5, 5, 5],
# [6, 6, 6, 6],
# [7, 7, 7, 7]])
2.3.2 Definindo operações de pool e computação --- pool2d.py (Parte 2)
### 定义池化操作
pooling = torch.nn.functional.max_pool2d(img,kernel_size=2)
print("pooling :",pooling) # 输出最大池化结果(池化区域为2,步长为2),
pooling1 = torch.nn.functional.max_pool2d(img,kernel_size=2,stride=1) # 不补0
print("pooling1 :",pooling1) # 不补0,输出最大池化结果(池化区域为2X2,步长为1),生成3X3的矩阵
pooling2 = torch.nn.functional.avg_pool2d(img,kernel_size=2,stride=1,padding=1)# 先执行补0,再进行池化
print("pooling2 :",pooling2) # 先执行补0,输出平均池化结果(池化区域为4X4,步长为1),生成3X3的矩阵
# 全局池化操作,使用一个与原来输入相同尺寸的池化区域来进行池化操作,一般在最后一层用于图像表达
pooling3 = torch.nn.functional.avg_pool2d(img,kernel_size=4)
print("pooling3 :",pooling3) # 输出平均池化结果(池化区域为4,步长为4)
# 对于输入的张量计算两次均值,可得平均池化结果
m1 = img.mean(3)
print("第1次均值结果",m1)
print("第2次均值结果",m1.mean(2))
### 对于输入数据进行两次平均值操作时,可以看到在输入数据进行两次平均值计算的结果与pooling3的数值是一直的,即为等价pooling : tensor([[[[1., 1.],
[3., 3.]],[[5., 5.],
[7., 7.]]]])
pooling1 : tensor([[[[1., 1., 1.],
[2., 2., 2.],
[ 3., 3., 3.]],[[5., 5., 5.],
[6., 6., 6.],
[7., 7., 7.]]]])
pooling2 : tensor([[[[0.0000, 0.0000, 0.0000 , 0,0000, 0,0000],
[0,2500, 0,5000, 0,5000, 0,5000, 0,2500],
[0,7500, 1.5000, 1.5000, 1.5000, 0,7500],
[
1.2500, 2.5000, 2.5000, 1.5000, 1.5000, 1.5000, 1.5000, 1.5000, 1.5000, 1.5000, 1.5000, 1.5000, 1.5000, 1.5000, 1.5000, 1.5000, 1.5000 , 0,7500]],[[1.0000, 2.0000, 2.0000],
[2.2500, 4.5000], [2.7500, 5.5000],
[2.7500, 5.7500],
[3.2500, 6.5000, 6.5000, 6,5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000,
3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 1.7500 ]]])
pooling3 : tensor([[[[1.5000]], [[5.5000]]]])
1º resultado médio tensor([[[0., 1., 2., 3.],
[4., 5 ., 6., 7.]]])
2º tensor de resultado médio([[1,5000, 5,5000]])
2.3.3 Visão geral do código --- pool2d.py
import torch
### 1.1 定义输入变量
img = torch.tensor([
[[0.0,0.0,0.0,0.0],[1.0,1.0,1.0,1.0],[2.0,2.0,2.0,2.0],[3.0,3.0,3.0,3.0]],
[[4.0,4.0,4.0,4.0],[5.0,5.0,5.0,5.0],[6.0,6.0,6.0,6.0],[7.0,7.0,7.0,7.0]]
]).reshape([1,2,4,4]) # 定义张量,模拟输入图像
print(img) # 输出结果
print(img[0][0]) # 输出第1通道的内容
# 输出:
# tensor([[0, 0, 0, 0],
# [1, 1, 1, 1],
# [2, 2, 2, 2],
# [3, 3, 3, 3]])
print(img[0][1]) # 输出第2通道的内容
# 输出:
# tensor([[4, 4, 4, 4],
# [5, 5, 5, 5],
# [6, 6, 6, 6],
# [7, 7, 7, 7]])
### 定义池化操作
pooling = torch.nn.functional.max_pool2d(img,kernel_size=2)
print("pooling :",pooling) # 输出最大池化结果(池化区域为2,步长为2),
pooling1 = torch.nn.functional.max_pool2d(img,kernel_size=2,stride=1) # 不补0
print("pooling1 :",pooling1) # 不补0,输出最大池化结果(池化区域为2X2,步长为1),生成3X3的矩阵
pooling2 = torch.nn.functional.avg_pool2d(img,kernel_size=2,stride=1,padding=1)# 先执行补0,再进行池化
print("pooling2 :",pooling2) # 先执行补0,输出平均池化结果(池化区域为4X4,步长为1),生成3X3的矩阵
# 全局池化操作,使用一个与原来输入相同尺寸的池化区域来进行池化操作,一般在最后一层用于图像表达
pooling3 = torch.nn.functional.avg_pool2d(img,kernel_size=4)
print("pooling3 :",pooling3) # 输出平均池化结果(池化区域为4,步长为4)
# 对于输入的张量计算两次均值,可得平均池化结果
m1 = img.mean(3)
print("第1次均值结果",m1)
print("第2次均值结果",m1.mean(2))
### 对于输入数据进行两次平均值操作时,可以看到在输入数据进行两次平均值计算的结果与pooling3的数值是一直的,即为等价