Parte das notas de estudo de "Practice Deep Learning pytorch" é apenas para sua própria revisão.
Rede neural convolucional profunda (ALEXNET)
Quase 20 anos depois que o LeNet foi proposto, as redes neurais foram superadas por outros métodos de aprendizado de máquina, como máquinas de vetores de suporte. Embora o LeNet possa obter bons resultados em pequenos conjuntos de dados iniciais, seu desempenho em conjuntos de dados reais maiores não é tão bom quanto o esperado .
Por um lado, as redes neurais são computacionalmente complexas . Embora houvesse algum hardware de aceleração para redes neurais na década de 1990 do século 20, eles não eram tão populares quanto as GPUs depois. Portanto, o treinamento de uma rede neural multicanal, multicamada e convolucional com grandes parâmetros foi difícil de concluir durante o ano. Por outro lado, quando 年 os pesquisadores ainda não são grandes 量 o estudo aprofundado de inicialização de parâmetros e algoritmos de otimização não convexa e outros campos, o treinamento de redes neurais complexas geralmente é difícil.
A rede neural pode classificar diretamente com base nos pixels originais da imagem. Esse método, denominado ponta a ponta, salva 了 muitas etapas intermediárias. Porém, por muito tempo, o que fluiu foram os recursos manuais concebidos e produzidos por pesquisadores com trabalho e sabedoria. O principal processo deste tipo de pesquisa de classificação de imagens é:
- 1. Obtenha o conjunto de dados da imagem;
- 2. Use funções de extração de recursos existentes para gerar recursos de imagem;
- 3. Use modelos de aprendizado de máquina para classificar recursos de imagem.
O que realmente importa no processo de visão computacional são os dados e recursos . Em outras palavras, o uso de conjuntos de dados mais limpos e recursos mais eficazes tem um impacto maior nos resultados da classificação de imagens do que a escolha do modelo de aprendizado de máquina.
Representação de recursos de aprendizagem
Em um período de tempo considerável, os recursos são extraídos dos dados com base em várias funções projetadas manualmente . Na verdade, muitos pesquisadores continuam a melhorar os resultados da classificação de imagens, propondo novas funções de extração de recursos. Isso deu uma importante contribuição para o desenvolvimento da visão computacional.
Alguns pesquisadores discordam. Eles acreditam que as próprias características também devem ser aprendidas . Eles também acreditam que, para representar entradas suficientemente complexas, os próprios recursos devem ser representados hierarquicamente. Os pesquisadores que sustentam essa ideia acreditam que as redes neurais multicamadas podem ser capazes de aprender representações de dados em vários níveis e representar conceitos ou padrões cada vez mais abstratos, nível por nível . Tome a classificação de imagem como um exemplo 例, um exemplo de detecção de borda de objeto em uma camada convolucional bidimensional. Em uma rede neural de várias camadas, a representação de primeiro nível da imagem pode ser se há bordas em uma posição e comprimento específicos; e a representação de segundo nível pode ser capaz de combinar essas bordas em padrões interessantes, como padrões; No terceiro nível de representação, talvez os padrões do nível anterior possam ser posteriormente mesclados em padrões correspondentes a partes específicas do objeto. Desta forma, a representação continua nível a nível, no final, o modelo pode facilmente completar a tarefa de classificação com base na representação do último nível. Deve ser enfatizado que a representação nível a nível da entrada é determinada pelos parâmetros no modelo multicamadas, e esses parâmetros são todos aprendidos .
Embora exista um grupo de pesquisadores persistentes que estão constantemente estudando e tentando aprender a representação hierárquica dos dados visuais, mas por muito tempo, esses campos não foram realizados. Existem muitos fatores nisso que merecem nossa análise.
Elemento um em falta: dados
Um modelo profundo que contém muitos recursos requer muitos dados rotulados para ter um desempenho melhor do que outros métodos clássicos. Limitada ao armazenamento limitado dos primeiros computadores e ao orçamento limitado para pesquisa na década de 1990, a maior parte da pesquisa foi baseada apenas em pequenos conjuntos de dados públicos. Essa situação melhorou com a onda de big data que surgiu por volta de 2010. Em particular, o conjunto de dados ImageNet nascido em 2009 年 contém 1.000 tipos de objetos, cada um com até milhares de imagens. O conjunto de dados ImageNet promove simultaneamente a visão computacional e a pesquisa de aprendizado de máquina em um novo estágio, fazendo com que os métodos tradicionais anteriores não tenham mais vantagens.
Elemento dois em falta: hardware
O aprendizado profundo requer recursos de computação muito elevados. O poder de computação do hardware inicial era limitado, o que tornava difícil treinar redes neurais mais complexas. No entanto, a chegada de GPUs de uso geral mudou esse padrão. Por muito tempo, as GPUs foram projetadas para processamento de imagens e jogos de computador , especialmente para multiplicação de matrizes e vetores para alto rendimento para atender a transformações gráficas básicas. Felizmente, a expressão matemática é semelhante à expressão da camada convolucional na rede profunda. O conceito de GPU universal começou a surgir em 2001, e estruturas de programação como OpenCL e CUDA surgiram . Isso faz com que as GPUs também sejam usadas pela comunidade de aprendizado de máquina por volta de 2010 年.
ALEXNET
Em 2012 , nasceu AlexNet . O nome deste modelo vem do nome do primeiro autor do artigo, Alex Krizhevsky [1]. AlexNet usa rede neural convolucional de 8 camadas e venceu o ImageNet 2012 Image Recognition Challenge com uma grande vantagem. Prova pela primeira vez que os recursos aprendidos podem superar os recursos do projeto manual, quebrando assim o estado anterior da pesquisa de visão computacional.
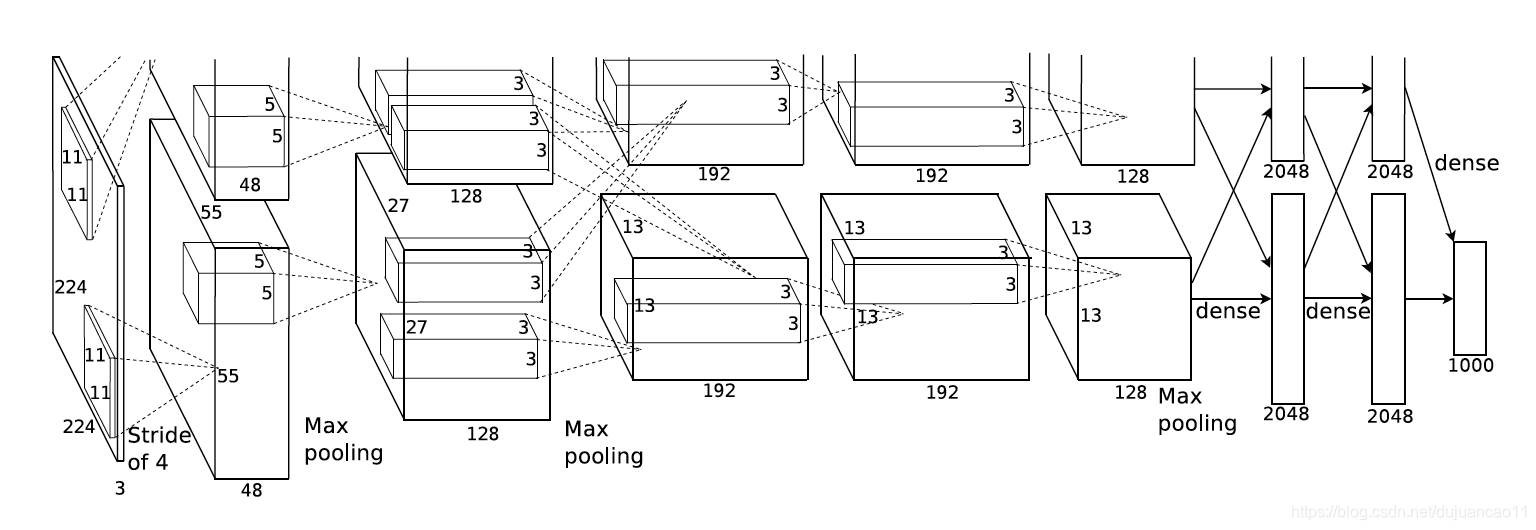
Os princípios de design do AlexNet e LeNet são muito semelhantes, mas também existem diferenças significativas.
Primeiro, em contraste com o LeNet relativamente pequeno, AlexNet contém 8 camadas de transformação, incluindo 5 camadas de convolução e 2 camadas de camadas ocultas totalmente conectadas e uma camada de saída totalmente conectada.
A forma da janela de convolução na primeira camada do AlexNet é 11 × 11. Como a altura e a largura da maioria das imagens no ImageNet são mais de 10 vezes maiores do que nas imagens MNIST, os objetos nas imagens ImageNet ocupam mais pixels, portanto, uma janela de convolução maior é necessária para capturar os objetos . A forma da janela de convolução na segunda camada é reduzida para 5 × 5 e, em seguida, 3 × 3 é usado. Além disso, após a primeira, segunda e quinta camadas convolucionais, a maior camada de agrupamento com uma forma de janela de 3 × 3 e uma passada de 2 é usada . Além disso, o número de canais de convolução usados pelo AlexNet é dezenas de vezes maior do que o número de canais de convolução no LeNet.
Seguindo a última camada convolucional estão duas camadas totalmente conectadas com 4096 saídas. Essas duas enormes camadas totalmente conectadas trazem quase 1 GB de parâmetros de modelo. Devido às limitações da memória de vídeo inicial , o primeiro AlexNet usava um design de fluxo de dados duplo, de modo que uma GPU só precisava processar metade do modelo. Felizmente, houve desenvolvimento suficiente nos últimos anos, então geralmente não precisamos mais de um design especial.
Em segundo lugar, AlexNet mudou a função de ativação sigmóide para uma função de ativação ReLU mais simples .
Por outro lado, o cálculo da função de ativação ReLU é mais simples , se não houver a operação de exponenciação na função de ativação sigmóide.
Por outro lado, a função de ativação ReLU torna o modelo mais 易 treinamento sob diferentes métodos de inicialização de parâmetros. Isso ocorre porque quando a saída da função de ativação sigmóide está muito próxima de 0 ou 1, o gradiente dessas regiões é quase 0, o que impede que a retropropagação continue. Nova parte dos parâmetros do modelo; e o gradiente da função de ativação ReLU no intervalo positivo é sempre 1. . Portanto, se os parâmetros do modelo não forem inicializados corretamente, a função sigmóide pode obter um gradiente de quase 0 no intervalo positivo , o que impede que o modelo seja efetivamente treinado.
Terceiro, o AlexNet usa o método de descarte para controlar a complexidade do modelo da camada totalmente conectada. LeNet não usa o método de descarte.
Em quarto lugar, o AlexNet introduz grandes aprimoramentos de imagem, como inversão, corte e alterações de cor para expandir ainda mais o conjunto de dados para aliviar o sobreajuste.
Implemente um AlexNet ligeiramente simplificado.
import time
import torch
from torch import nn, optim
import torchvision
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(torch.__version__)
print(torchvision.__version__)
print(device)class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
# in_channels, out_channels, kernel_size, stride, padding
nn.Conv2d(1, 96, 11, 4),
nn.ReLU(),
# kernel_size, stride
nn.MaxPool2d(3, 2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return outputImprima para ver a estrutura da rede.
AlexNet (
(conv): Sequential (
(0): Conv2d (1, 96, kernel_size = (11, 11), stride = (4, 4))
(1): ReLU ()
(2): MaxPool2d (kernel_size = 3 , stride = 2, padding = 0, dilation = 1, ceil_mode = False)
(3): Conv2d (96, 256, kernel_size = (5, 5), stride = (1, 1), padding = (2, 2) )
(4): ReLU ()
(5): MaxPool2d (kernel_size = 3, stride = 2, preenchimento = 0, dilation = 1, ceil_mode = False)
(6): Conv2d (256, 384, kernel_size = (3, 3 ), passada = (1, 1), preenchimento = (1, 1))
(7): ReLU ()
(8): Conv2d (384, 384, tamanho do kernel = (3, 3), passada = (1, 1) , preenchimento = (1, 1))
(9): ReLU ()
(10): Conv2d (384, 256, tamanho do kernel = (3, 3), passo = (1, 1), preenchimento = (1, 1))
(11): ReLU ()
(12): MaxPool2d (kernel_size = 3, stride = 2, padding = 0, dilation = 1, ceil_mode = False)
)
(fc): Sequential (
(0): Linear (in_features = 6400, out_features = 4096, bias = True )
(1): ReLU ()
(2): Dropout (p = 0,5)
(3): Linear (in_features = 4096, out_features = 4096, bias = True)
(4): ReLU ()
(5): Dropout (p = 0,5)
(6): Linear (in_features = 4096, out_features = 10, bias = True)
)
)
Leia os dados
Embora AlexNet use o conjunto de dados ImageNet no papel, porque o conjunto de dados ImageNet leva muito tempo para treinar, ainda usamos o conjunto de dados Fashion-MNIST anterior para demonstrar o AlexNet. Ao ler os dados, damos um passo extra para aumentar a altura e largura da imagem para a altura e largura da imagem 224 usadas por AlexNet. Isso pode ser alcançado pela instância torchvision.transforms.Resize . Em outras palavras, usamos Resize antes da instância ToTensor e, em seguida, usamos a instância Compose para concatenar essas duas transformações para chamar.
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def load_data_fashion_mnist(batch_size, resize=None, root='~/Datasets/FashionMNIST'):
"""Download the fashion mnist dataset and then load into memory."""
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=4)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=4)
return train_iter, test_iterbatch_size = 128
# 如出现“out of memory”的报错信息,可减小batch_size或resize
train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=224)Treinamento
Comece a treinar AlexNet. Comparado com o LeNet, porque o tamanho da imagem muda e o modelo muda , ele requer uma grande memória de vídeo e um longo tempo de treinamento.
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)Resultado:
treinamento em cuda epoch 1, perda 0,0047, train acc 0,770, teste acc 0,865, tempo 128,3 seg. epoch 2, perda 0,0025, train acc 0,879, teste acc 0,889, tempo 128,8 seg, epoch 3, perda 0,0022, tre acc 0,898, teste acc 0,901 , tempo 130,4 seg, época 4, perda 0,0019, trem acc 0,908, teste acc 0,900, tempo 131,4 seg, época 5, perda 0,0018, trem acc 0,913, teste acc 0,902, tempo 129,9 seg
resumo
- AlexNet é semelhante ao LeNet em estrutura, mas usa mais camadas convolucionais e um espaço de parâmetro maior para caber em um conjunto de dados de grande escala ImageNet . É a linha divisória entre a rede neural rasa e a rede neural profunda.
- Embora pareça que a implementação do AlexNet envolve mais alguns códigos do que a implementação do LeNet, a mudança de conceito e a produção de resultados experimentais verdadeiramente excelentes custaram à comunidade acadêmica muitos anos.