conceito básico
visão geral
Rede Neural Convolucional (CNN) é um modelo de rede neural comumente usado em aprendizado profundo para processar dados com uma estrutura de grade. É amplamente utilizado na classificação de imagens, detecção de objetos, geração de imagens e outras tarefas no campo da visão computacional.
idéia principal
A ideia central da CNN é capturar as informações da estrutura espacial dos dados de entrada, utilizando a percepção local e o compartilhamento de parâmetros. Em comparação com a rede neural totalmente conectada tradicional, a CNN introduz camadas convolucionais e camadas de agrupamento na estrutura da rede, reduzindo assim o número de parâmetros e lidando melhor com dados de entrada de alta dimensão.
outros conceitos
Camada de entrada : Recebe imagens brutas ou outras formas de dados de entrada.
Camada Convolucional : Use operações de convolução para extrair recursos de entrada, deslize nos dados de entrada definindo filtros (kernels de convolução) e execute operações de convolução. Desta forma, características locais como arestas e texturas podem ser aprendidas.
Função de ativação : Cada camada convolucional é geralmente seguida por uma função de ativação não linear, como ReLU (Rectified Linear Unit), para aumentar a expressividade não linear da rede.
Camada de agrupamento : reduz a complexidade do modelo reduzindo o tamanho dos mapas de recursos. Uma operação de agrupamento comumente usada é o Max Pooling, que seleciona o maior autovalor dentro de cada janela de agrupamento como saída.
Camada totalmente conectada : conecte a saída da camada convolucional e da camada de pooling à camada totalmente conectada e use o modelo de rede neural tradicional para executar tarefas como classificação e regressão.
Camada de abandono : durante o processo de treinamento, a saída de alguns neurônios é definida aleatoriamente como 0 com uma certa probabilidade de reduzir o overfitting do modelo.
Camada Softmax : A camada de saída comumente usada em problemas de multiclassificação.A operação softmax é executada na última camada para converter a saída em uma distribuição de probabilidade na categoria.
Código e comentários detalhados
import os
# third-party library
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
# Hyper Parameters
# 轮次
EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
# 批大小为50
BATCH_SIZE = 50
# 学习率
LR = 0.001
# 是否下载mnist数据集
DOWNLOAD_MNIST = False
# 下载minist数据集
if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):
# not mnist dir or mnist is empyt dir
DOWNLOAD_MNIST = True
# torchvision本身就是一个数据库
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST,
)
# 输出训练数据尺寸
print(train_data.train_data.size()) # (60000, 28, 28)
# 输出标签数据尺寸
print(train_data.train_labels.size()) # (60000)
# 展示训练数据集中的第0个图片
plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
# 图片的标题是标签
plt.title('%i' % train_data.train_labels[0])
plt.show()
# Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
# 批大小为50,shuffle为True意思是设置为随机
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# pick 2000 samples to speed up testing
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
# 使用unsqueeze增加一个维度
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
test_y = test_data.test_labels[:2000]
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 快速搭建神经网络
self.conv1 = nn.Sequential( # input shape (1, 28, 28)
nn.Conv2d(
in_channels=1, # input height
out_channels=16, # n_filters
kernel_size=5, # filter size
stride=1, # filter movement/step
padding=2, # if want same width and length of this image after Conv2d, padding=(kernel_size-1)/2 if stride=1
), # output shape (16, 28, 28)
nn.ReLU(), # activation
nn.MaxPool2d(kernel_size=2), # choose max value in 2x2 area, output shape (16, 14, 14)
)
self.conv2 = nn.Sequential( # input shape (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
nn.ReLU(), # activation
nn.MaxPool2d(2), # output shape (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
# 前向传播
def forward(self, x):
# 第一层卷积
x = self.conv1(x)
# 第二层卷积
x = self.conv2(x)
x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)
output = self.out(x)
return output, x # return x for visualization
cnn = CNN()
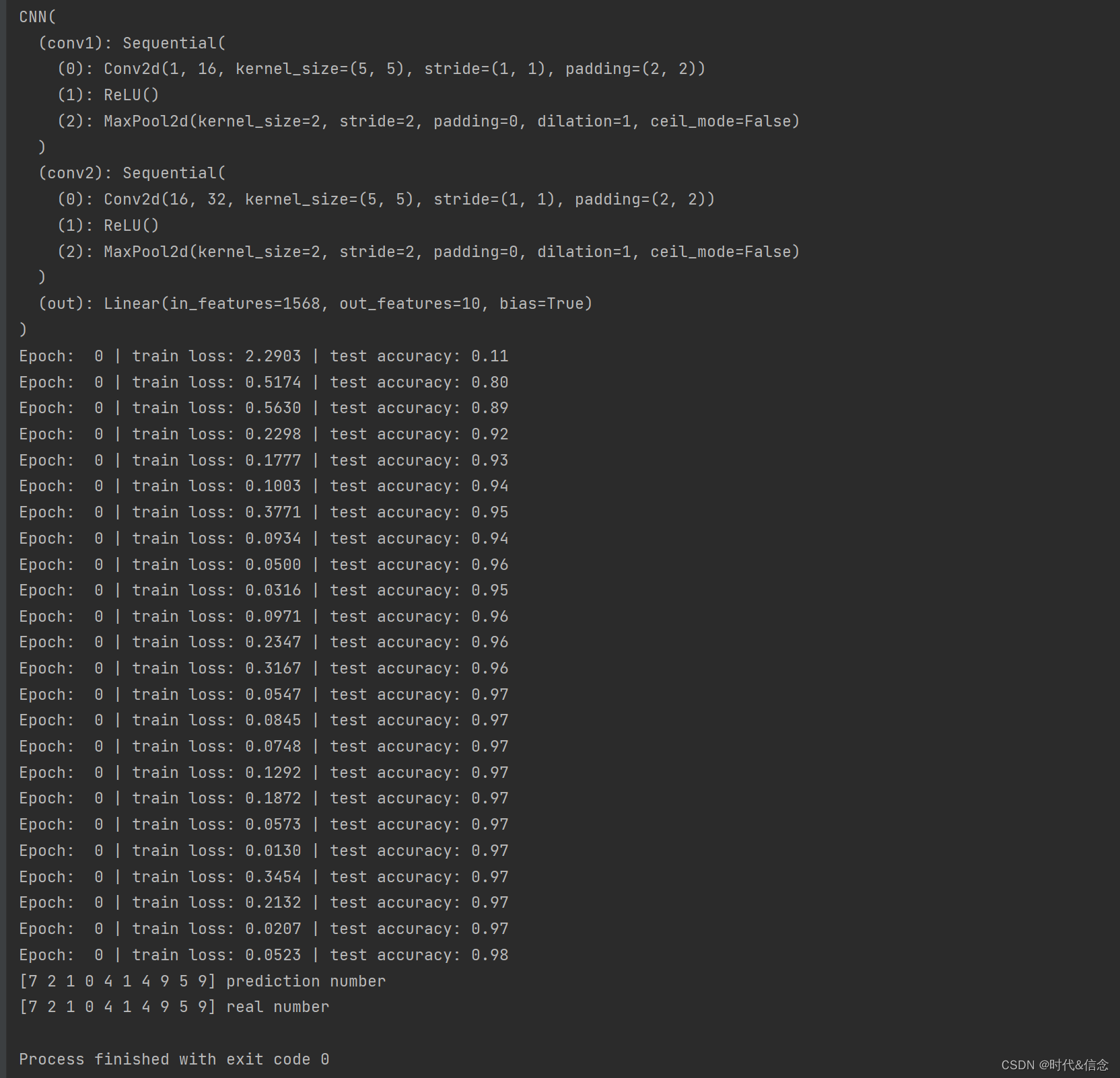
print(cnn) # net architecture
# 选择优化器
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
# 选择损失函数
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# following function (plot_with_labels) is for visualization, can be ignored if not interested
from matplotlib import cm
try: from sklearn.manifold import TSNE; HAS_SK = True
except: HAS_SK = False; print('Please install sklearn for layer visualization')
def plot_with_labels(lowDWeights, labels):
plt.cla()
X, Y = lowDWeights[:, 0], lowDWeights[:, 1]
for x, y, s in zip(X, Y, labels):
c = cm.rainbow(int(255 * s / 9)); plt.text(x, y, s, backgroundcolor=c, fontsize=9)
plt.xlim(X.min(), X.max()); plt.ylim(Y.min(), Y.max()); plt.title('Visualize last layer'); plt.show(); plt.pause(0.01)
plt.ion()
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
output = cnn(b_x)[0] # cnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 50 == 0:
test_output, last_layer = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
if HAS_SK:
# Visualization of trained flatten layer (T-SNE)
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_only = 500
low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])
labels = test_y.numpy()[:plot_only]
plot_with_labels(low_dim_embs, labels)
plt.ioff()
# print 10 predictions from test data
test_output, _ = cnn(test_x[:10])
pred_y = torch.max(test_output, 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10].numpy(), 'real number')
resultado da operação