O que é a regressão linear múltipla
Na análise de regressão, se houver duas ou mais variáveis independentes, é chamado de regressão múltipla. ** Na verdade, um fenómeno muitas vezes ligada a um número de factores, um mais variáveis independentes para prever a combinação óptima de comum ou estimar a variável dependente, variável independente para predizer ou estimativa é mais eficaz do que apenas utilizando, em linha com mais realidade. ** A regressão linear múltipla, portanto, maior do que o significado prático de regressão linear.
y = B0 + v1x1 v2x2 + + ... + + e # vpxp 公式
Um exemplo de falar hoje
Aqui está um arquivo de dados do Excel, vamos examinar os fatores que afetam as vendas no final é a mais óbvia, é TV ou rádio ou jornal, que está à procura de vendas no final é a casa causados pelos elementos, como aumentar as vendas?
Importação relativamente biblioteca
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot') #使用ggplot样式
from sklearn.linear_model import LinearRegression # 导入线性回归
from sklearn.model_selection import train_test_split # 训练数据
from sklearn.metrics import mean_squared_error #用来计算距离平方误差,评价模型
Abra o arquivo
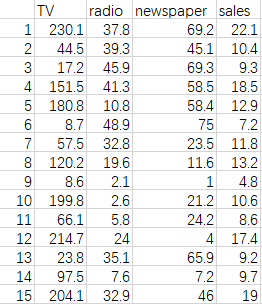
data = pd.read_csv('Advertising.csv')
data.head() #看下data
Primeiro pintura analisar
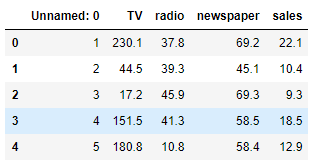
plt.scatter(data.TV, data.sales)
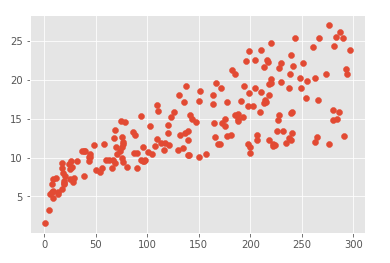
plt.scatter(data.radio, data.sales)
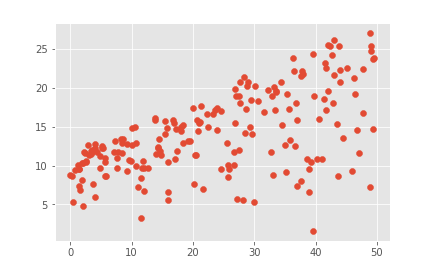
plt.scatter(data.newspaper, data.sales)
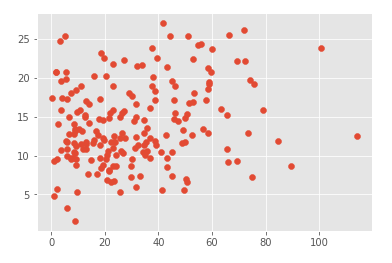
Análise visto a partir da figura o ponto de propagação jornal muito largo, previu nenhuma relação, deve ser removido
ligação códigos de acesso
x = data[['TV','radio','newspaper']]
y = data.sales
x_train,x_test,y_train,y_test = train_test_split(x, y) #得到训练和测试训练集
model = LinearRegression() #导入线性回归
model.fit(x_train, y_train) #
model.coef_ # 斜率 有三个
model.intercept_ # 截距
obter
array([ 0.04480311, 0.19277245, -0.00301245])
3.0258997429585506
for i in zip(x_train.columns, model.coef_):
print(i) #打印对应的参数
('TV', 0.04480311217789182)
('radio', 0.19277245418149513)
('newspaper', -0.003012450368706149)
mean_squared_error(model.predict(x_test), y_test) # 模型的好坏用距离的平方和计算
4.330748450267551
y = 0,04480311217789182 * + x1 x2 -0,003012450368706149 ,19277245418149513 * * x3 + 3,0258997429585506
Podemos ver o coeficiente jornal inferior a 0, indicando que a venda, mas então como melhorar o impacto do modelo de vendas, é para remover o valor do jornal
x = data[['TV','radio']]
y = data.sales
x_train,x_test,y_train,y_test = train_test_split(x, y)
model2 = LinearRegression()
model2.fit(x_train,y_train)
model2.coef_
model2.intercept_
mean_squared_error(model2.predict(x_test),y_test)
array([0.04666856, 0.17769367])
3.1183329992288478
2.984535789030915 # 比第一个model的小,说明更好
y = 0.04666856 * * x1 x2 + 3,1183329992288478 0,17769367
