url Referência:
https://jakevdp.github.io/PythonDataScienceHandbook/05.13-kernel-density-estimation.html
avaliador de densidade usando um conjunto de dados D-dimensional para gerar um algoritmo de estimativa de distribuição de probabilidade D-dimensional, um algoritmo diferente GMM ponderação gaussiana estimativa da distribuição de probabilidade representada resumo. estimativa da densidade Kernel (estimativa de densidade de grãos, KDE) algoritmo para estender o conceito de um limite lógico Mistura de Gauss (extremo lógico), por mistura dos ingredientes que gera uma distribuição de Gauss para cada ponto, para obter essencialmente nenhuma avaliador parâmetro de densidade.
1, origem KDE: Histograma
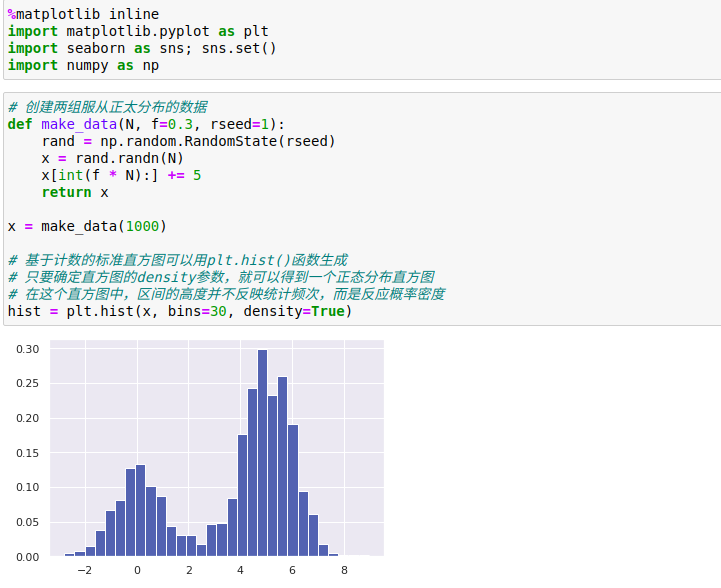
estimativas de densidade avaliador é um algoritmo de descoberta para gerar um conjunto de dados de um modelo de distribuição de probabilidade.
Unidimensional densidade de dados de estimativa - histograma é um avaliador de densidade simples, os dados de histograma é dividido em uma pluralidade de seções, o número de pontos estatísticos cair dentro de cada intervalo, em seguida, de uma forma intuitiva de visualizar os resultados.
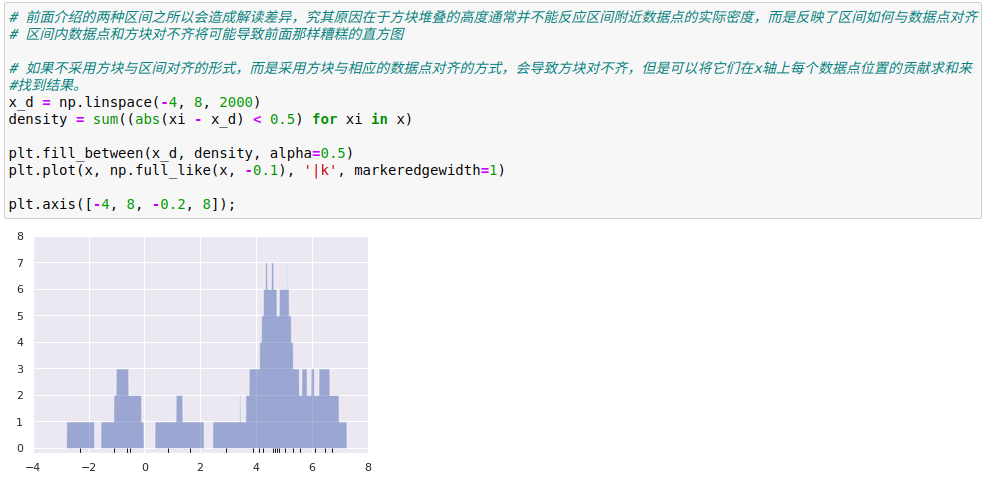

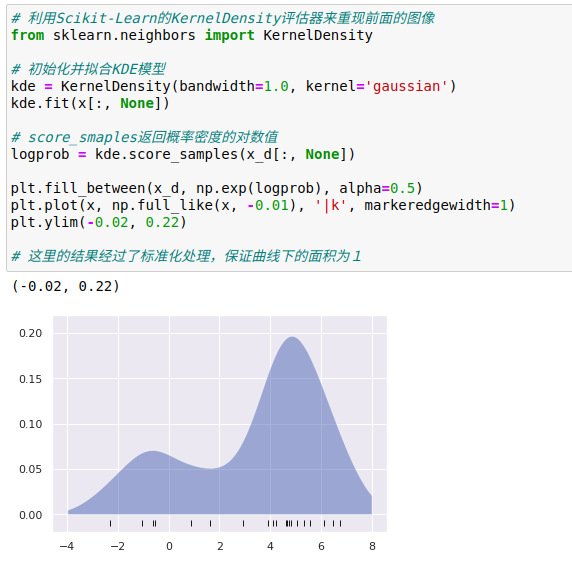
2, a estimativa de densidade de grãos de aplicação prática
parâmetro de estimativa de densidade de kernel livre é o tipo de núcleo (kernel) parâmetros, ele pode especificar a forma de cada ponto da distribuição da densidade nuclear.
Largura de banda Nuclear controles de parâmetros (kernel largura de banda) o tamanho de cada ponto central
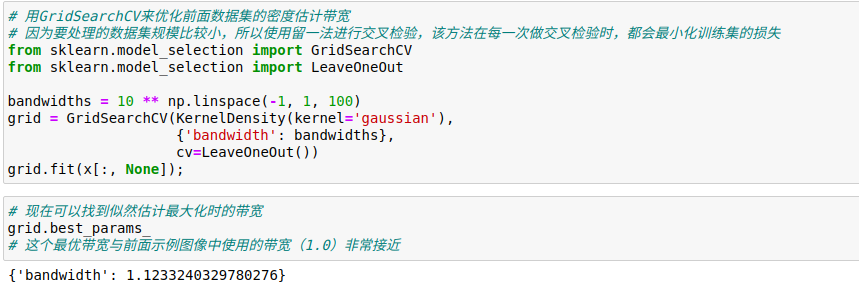
Kernel Densidade algoritmo de estimativa em sklearn.neighbors.KernelDensity avaliador, as seis núcleos por meio de qualquer um núcleo, métrica de distância vinte ou trinta KDE pode ser processado com uma pluralidade de dimensões.
Uma vez que uma quantidade muito grande de cálculo KDE, então scikit-learn avaliador inferior utiliza um algoritmo baseado em árvore, atol podem ser utilizados (tolerância a falhas absoluta) e RTOL (tolerância a falhas relativa) parâmetro para que o saldo da computação e precisão pode ser usado scikit-learn a ferramenta de verificação cruzada padrão para determinar os parâmetros livres de largura de banda nuclear.
Por comparação da seleção da largura de banda
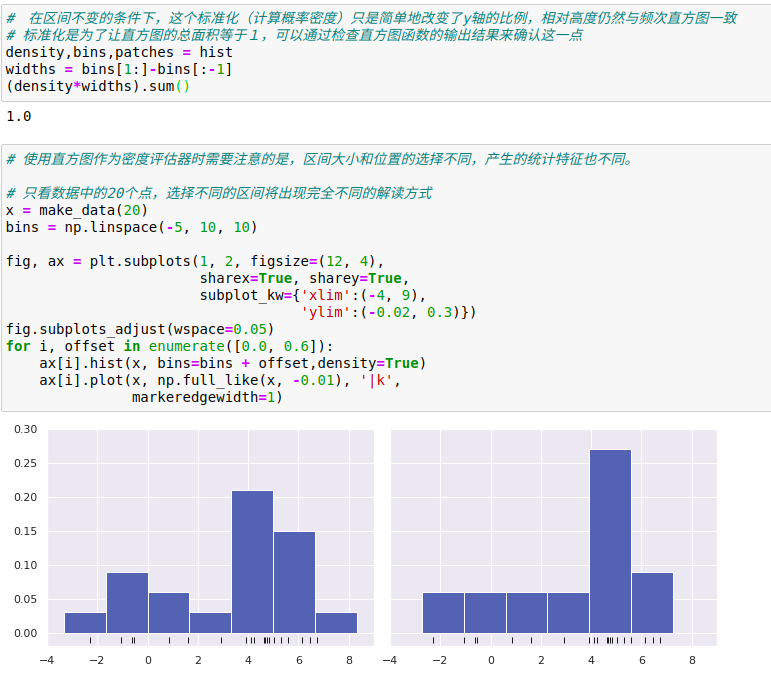
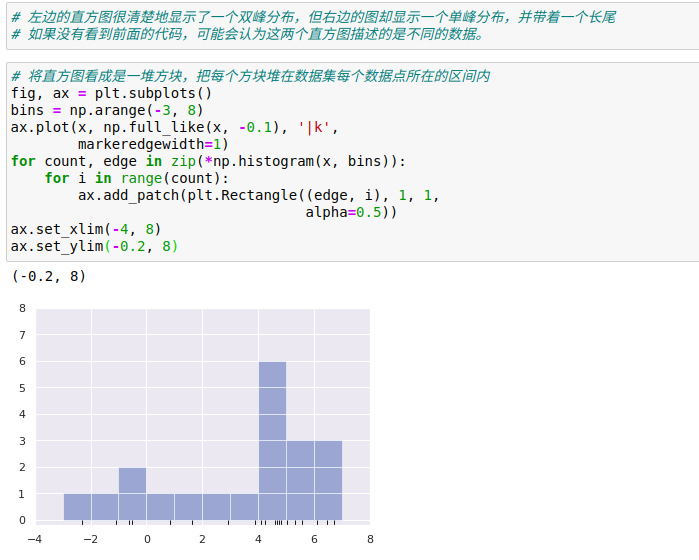
No KDE, a largura de banda de escolha não só para encontrar a estimativa densidade certa é muito importante, mas também o desvio de controle na estimativa de densidade - chave equilíbrio variância:
(1) a largura de banda estreita irá levar a uma elevada variância estimada exposição (isto é, o excesso de montagem), mas não há qualquer ponto ou eliminação vai causar um grande diferença
(2) a largura de banda é muito grande vai resultar num elevado desvio exposição estimada (isto é, menos do ajuste), mas também afectam a estrutura de dados de largura de banda mais larga nuclear
Sintonia super-máquina de parâmetros de aprendizagem são geralmente realizado por cruzamento de dados.