MySQLのパフォーマンス
するデータの最大量
はさておきデータの量やいじめのパフォーマンスについて同時、話の数を設定します。MySQLは、単一のテーブル内のレコードの最大数に制限はありません、それはファイルサイズのオペレーティング・システムの制限に依存します。
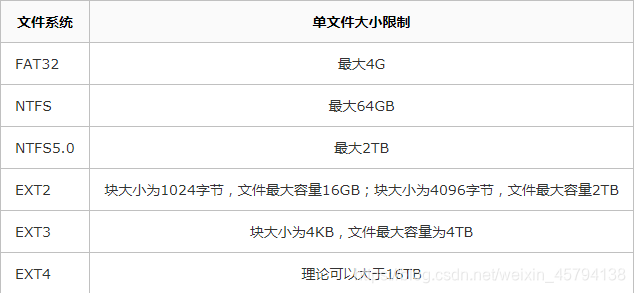
「アリ・ババのJava開発マニュアル」5万行または2GB以上の単一テーブルの容量を介して前方の単一テーブルの行を入れて、それが推奨されるサブライブラリーサブテーブル。パフォーマンスはさておき、ビジネスの複雑さを入れて、要因の組み合わせによって決定され、インパクトは、ハードウェア構成、MySQLの設定、データテーブルの設計、インデックスの最適化が続いています。5000000この値はない鉄法、参考値です。
最新の記録は0.6秒かかりタブ20のチェック、SQL文、一般FIELD_1を選択し、テーブルからfield_2場合のID DESC制限20によってID <#{prePageMinId}ため、prePageMinId ID最小前のデータレコード。
データが成長し続けている時には、クエリの速度は大丈夫、1日は圧倒されなければなりません。サブライブラリーサブテーブル長時間・大リスクの高い仕事である、あなたは、などのアップグレードのハードウェア、移行履歴データとして、現在の構造に最適化しようとする必要があり、それMeizhe細分化。興味のある学生のためのサブライブラリーサブテーブルサブライブラリーサブテーブルの基本的な考え方を読むことができます。
同時の最大数
の同時データベースが同じ時間に処理された要求の数を参照することができ、MAX_CONNECTIONSおよびMAX_USER_CONNECTIONSによって決定されます。MAX_USER_CONNECTIONSはユーザーごとのデータベース接続の最大数であり、上限値が16384であり、接続MAX_CONNECTIONS MySQLインスタンスの最大数を指します。
MySQLは、より多くのメモリを消費することを意味する、各接続のためのバッファを提供します。接続があまりにも高すぎるハードウェアを設定している場合は、低すぎるとハードウェアを最大限に活用することはできません。比の両方のための一般的な要件は、次のように計算され、10%を超えます。
max_used_connections / max_connections * 100% = 3/100 *100% ≈ 3%
接続および接続の応答の最大数の最大数を表示します。
show variables like '%max_connections%';
show variables like '%max_user_connections%';
コンフィギュレーション・ファイルのmy.cnfに接続の最大数を変更します。
[mysqld]
max_connections = 100
max_used_connections = 20
クエリは0.5秒かかり
、単一のクエリが0.5秒未満に制御を取ったことが推奨され、0.5秒のユーザーエクスペリエンスの原則から、経験値、3秒です。ユーザーの操作は、3秒以内に応答しない場合は、それも出て退屈になります。データベースクエリを消費するプロセスを消費する加工+ + +アプリケーション加工クライアントのネットワーク要求をレンダリング応答時間= UIは、処理時間は0.5秒1/6データベースを残しています。
原則の実装
と比較のNoSQLデータベースは、MySQLは繊細な脆弱な男です。それは、物理的な教育上の女子学生のようなものであるオッズや学生の紛争である(拡張が難しい)、(あまりにも多くのSQLの制約を)残すために、多くの場合、病気、(低容量の小さな同時)息を切らして2つのステップを実行しました。今日は、分散、アプリケーションの拡張を指摘されますので、以下の作業は原則、アプリケーション、およびより多くの仕事のデータベースの実装で、データベースよりもはるかに簡単です。
- しかし、虐待インデックスをフルに活用していない、インデックス・ノートは、ディスクとCPUを消費します。
- アプリケーションプロセスにデータをフォーマットするために、データベースの機能を使用することをお勧めしません。
- アプリケーションとデータの正確性を確保するために外部キー制約を使用することをお勧めしません。
- 読む多くの小規模なシーン追記は、一意性を保証するためにアプリケーションを使用して、一意のインデックスを使用することは推奨されません。
- 時間のためのアプリケーション、スペースと計算の中間結果、中間テーブルを作成しようと、冗長なフィールドを適切な。
- 小さなトランザクションにアプリケーション分割して、非常に時間のかかる業務を実行するために許可されていません。
- 推定された重要な(例えば、注文テーブルのような)データシートと負荷データ成長、最適化予め。
データテーブルデザイン
データタイプは、
単純またはより小さなフットプリント:原則のデータ型を選択します。
- 長さを満たすことができる場合は、int型ではないmedium_int、整数TINYINT、SMALLINTを利用することができます。
- 文字列の長さが決定された場合、char型を使用。
- varchar型満たしている場合は、テキストタイプを使用しません。
- 高精度の小数型の使用は、BIGINTはまた、例えば2つの小数精度を保存するために100を乗じ、使用されてもよいです。
- 代わりに、日時のタイムスタンプを使用してみてください。

少ないスペースを取るタイムスタンプ、日付時刻比較すると、ストレージ・ゾーンは自動的にUTC時刻形式に変換されます。
避けヌル値
MySQLのフィールドにインデックス、索引統計をより複雑になり、まだNULLスペースです。NULL値は非NULLの更新に更新されたインデックスのパフォーマンスに影響を与える分割する傾向から、その場で行うことはできません。できるだけNULL値の代わりに、意味のある値として、だけでなく、判断がnullでなく、含まれている回避のSQLステートメントに。
text型の最適化
テキストフィールドは、大量のデータを格納するので、テーブル容量が非常に早く上がる、クエリのパフォーマンスの他のフィールド。私たちは、関連する自然キーで、子テーブルの上に引き出されてお勧めします。
索引チューニング
インデックスの分類
- 通常のインデックス:基本的な指標。
- 複合インデックス:複数のフィールドをインデックス、複合体は、検索クエリを加速することができます。
- 唯一のインデックス:通常のインデックスに似ていますが、索引列の値は一意でなければなりませんが、NULLを許可します。
- ユニークなインデックスの組み合わせ:列の値の組み合わせは一意でなければなりません。
- 主キーのインデックス:特別な一意のインデックス、テーブル内で一意の識別データの記録は、通常、主キー制約と、NULLを許可します。
- フルテキストインデックス:MySQL5.6をサポートフルテキストインデックス後の質量のテキストクエリ、InnoDBはMyISAMテーブルとのために。問合せ精度とスケーラビリティが悪いので、より多くの企業がElasticsearchを選択してください。
索引チューニング
- クエリデータの量が30%を超える場合は、クエリをページングすることは、非常に重要であり、MySQLはインデックスを使用しません。
- 単一のテーブルのインデックス数を超えない5、これ以上5以下、単一のインデックスフィールドの数。
- 文字列の接頭辞インデックスは、制御文字5-8のプレフィックス長を使用することができます。
- 専用フィールドが低すぎる、などの意味がありません率を高める:性別を削除するかどうか。
被覆指数の使用の合理化は、次の通り:
select login_name, nick_name from member where login_name = ?
login_nameに、NICK_NAME 2つのフィールドが複合インデックスを確立するために、単純なインデックスは速いのlogin_nameを超えています。
SQLの最適化
バッチ処理の
ブロガーは、子池は、漂流物のすべての種類があり、水を排水に小さな穴を掘っ参照してください。ウキクサ葉は常にコンセントを渡すことができ、および支店を通じて他のオブジェクトをブロックします、そして時には、手動クリーニングの必要性が立ち往生。MySQLは魚の池で、同時ネットワーク帯域幅の最大数は、アウトレット、SQLが浮いているユーザです。
ページングパラメータ、またはデータ更新および削除操作の大量の影響を持つクエリは、すべての枝が、我々はそれがバッチ処理を分割したい、例:
事業内容:更新ユーザーのすべての期限切れのクーポン利用できません。
SQL文:
update status=0 FROM `coupon` WHERE expire_date <= #{currentDate} and status=1;
クーポンの多数が利用できない状態を更新する必要がある場合、実行するSQLは、他のSQLをブロックすることができる次のように、擬似コードのバッチ処理です。
int pageNo = 1;
int PAGE_SIZE = 100;
while(true) {
List<Integer> batchIdList = queryList('select id FROM `coupon` WHERE expire_date <= #{currentDate} and status = 1 limit #{(pageNo-1) * PAGE_SIZE},#{PAGE_SIZE}');
if (CollectionUtils.isEmpty(batchIdList)) {
return;
}
update('update status = 0 FROM `coupon` where status = 1 and id in #{batchIdList}')
pageNo ++;
}
演算子<>最適化
以下のように一般的に<>演算子は、たとえば、インデックスを使用することはできません、クエリは$ 100の受注額ではありません。
select id from orders where amount != 100;
量はデータこのような状況のまれな、深刻な不均一な分布のために100の命令の下であれば、インデックスを使用することが可能です。この不確実性を考えると、検索結果には、次のように書き換えられた重合組合を、使用しました:
(select id from orders where amount > 100)
union all
(select id from orders where amount < 100 and amount > 0)
または最適化
InnoDBエンジンやなど、複合インデックスを使用することはできません。
select id,product_name from orders where mobile_no = '13421800407' or user_id = 100;
Mobile_no + user_idのヒットまたはインデックスの組み合わせではない、次のように連合は、採用:
(select id,product_name from orders where mobile_no = '13421800407')
union
(select id,product_name from orders where user_id = 100);
この時点で、IDとPRODUCT_NAMEフィールドがインデックスを持って、クエリが最も効率的です。
最適化における
小さなテーブルのためのIn LARGEメインテーブル、大きな子供のテーブルのためのメインテーブルに存在しています。クエリオプティマイザがエスカレートするので、多くのシーンの両方の性能はほぼ同じもの。
例えば、以下のようにクエリを結合する代わりに試してみてください。
select o.id from orders o left join user u on o.user_id = u.id where u.level = 'VIP';
JOINを、以下に示す使用:
select o.id from orders o left join user u on o.user_id = u.id where u.level = 'VIP';
列の操作がされていません
:以下のように通常のクエリインデックス列操作は、失敗につながる
問い合わせ注文の日付を
select id from order where date_format(create_time,'%Y-%m-%d') = '2019-07-01';
DATE_FORMAT関数は、クエリがリライトした後、インデックスを使用することはできません原因:
select id from order where create_time between '2019-07-01 00:00:00' and '2019-07-01 23:59:59';
すべてを回避することを選択し
、あなたがテーブルのすべての列を照会していない場合はSELECT *を使用して、回避し、それが効果的にインデックスを使用することはできません、全表スキャンになります。
最適化と同様に
、たとえば、ファジークエリのように(フィールドのインデックスを作成):
SELECT column FROM table WHERE field like '%keyword%';
このクエリは、インデックスをミスし、以下の文言に置き換え:
SELECT column FROM table WHERE field like 'keyword%';
前回のクエリ%に加えて、インデックスにヒットしますが、プロダクトマネージャーは、その前と後のあいまい一致でなければなりませんか?フルテキストインデックスのフルテキストを試すことができますが、Elasticsearchは究極の武器です。
参加最適化は、
ネストされたループアルゴリズムに参加採用する参加達成、結果は、基本データテーブルとして駆動により設定されたフィルタ条件テーブルクエリデータサイクルと次のノードを介してデータ、その結果を組み合わせています。複数参加した場合、結果の前に再クエリデータテーブルの後にサイクリックデータとして設定されています。
ON条件を満たし、より少ない場合には、小さな結果セットで大きな結果セットを駆動するテーブル駆動テーブルと駆動増加クエリ。
インデックス付けとドライブテーブルのフィールドに参加され、時間は、十分な参加バッファサイズの提供をインデックス化することはできません。
3つのテーブルよりも多くの接続を参加禁止、冗長フィールドを増やしてみてください。
制限最適化
の下に示すように、スキャン領域の削減:クエリ次のターンに悪いパフォーマンス、ソリューションをページングするための制限の原則:
select * from orders order by id desc limit 100000,10
これは、0.4秒かかります
select * from orders order by id desc limit 1000000,10
これは、5.2秒かかります
まず、次のように言葉遣い、IDは、検索結果を絞り込むスクリーニング:
select * from orders where id > (select id from orders order by id desc limit 1000000, 1) order by id desc limit 0,10
これは、0.5秒かかります
クエリ条件の場合のみマスターキーID、次のように言葉を選びました:
select id from orders where id between 1000000 and 1000010 order by id desc
これは、0.3秒かかります
上記のプログラムはまだ非常に遅いですか?私は、カーソルを実装ページングクエリを使用してJDBCを読み取るために、カーソルを使用していた、と興味を持って友人
他のデータベース
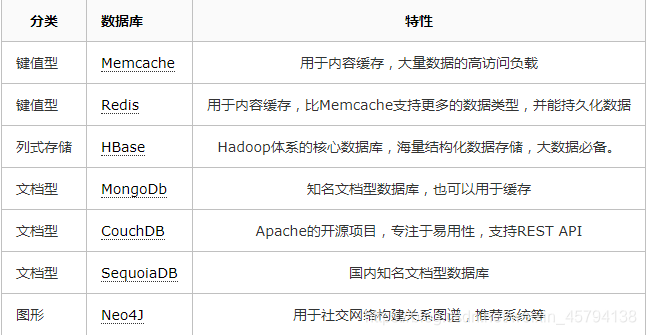
バックエンドの開発者として、ストレージコアとしてMySQLやSQL Serverで確認堪能するだけでなく、NoSQLのデータベースに積極的関心も、彼らは成熟していると広く、特定のシナリオでパフォーマンスのボトルネックを解決するために十分に使用されています。