プログラミングに加えて、正確にすべての可能な例でプログラムを動作させるだけでなく、プログラムの効率を考慮する必要があり、それはリーディング、ライティング、このセクションの操作を解析する最適化に関して最適化に焦点を当てています。読み取りと書き込みの最適化
効率的なプログラムを書くことは2つのことを行う必要があります:
- 適切なアルゴリズムとデータ構造のセットを選択します
- 実行可能コードの効果的かつ効率的なソースに変換するための書き込み最適化コンパイラ
あなたが書いたときに最初のポイントに適したアルゴリズムとデータ構造は、多くの場合、プログラムは最初に考慮に入れると、第二の点は、しばしば見過ごされています。ここでは、コードの最適化の面では、我々は、最適化コンパイラは、機能と制限が非常に重要であることを理解するところの書き込みに効果的に、コンパイラのソースコードを最適化する方法に焦点を当てます。
読み出し動作と書き込みの間の差に加えて、このセクションの最大の違いの一つである。この例の最適化は、読みやすさに影響を与えます。
しかし、それはまた、多くの場合、より良い最適化の手段が存在しない場合に遭遇しますが、性能要件の緊急プログラムがあり、時間のためのスペースを取って、またはコードの可読性の運転効率を低下させると引き換えに、望ましくないプログラミングの場合の方法であります。
あなたは一時的な情勢に対処するための(そしておそらく将来が再利用されていない)小さなツールを作成したり、あなたのアイデアの一つが実現可能であるとき、検証したい場合には(このようなアルゴリズムをテストとして正しいです)、良い可読性が、実行を書かれている場合非常にゆっくりとしたプロセスは、多くの場合、不必要な多くの時間を無駄に。この時点で、あなたは、コードの読みやすさについてはあまり気にするが、必要に応じ早く得るために、現在のプログラムの動作性能の結果にもっと注意を払う必要がないかもしれません。
以下は、私たちは、共通のコードの最適化の行列演算を説明します。
目的関数:イメージスムージング
操作をスムージングすることが必要です。
- 修正された画像行列の各画素の値が
9つの画素の平均値に隣接する画素上の中心点として新たな値= - 画像マトリックスの四隅の点が、唯一の四隅の画素の平均値を必要とします
- 画像マトリックスの四辺は、現在の平均点に隣接する唯一6画素を必要とします
概略:
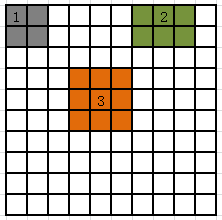
ATは1,2,3コーナー、エッジ点と内側点の隣接する画素を表します
我々は、以下の構造を有するピクセル画像を表します。
typedef struct {
unsigned short red; /* R value */
unsigned short green; /* G value */
unsigned short blue; /* B value */
} pixel;赤、緑、青のそれぞれのカラー画像の赤、緑および青チャネルを表します。
オリジナルの平滑化の機能は以下のとおりです。
static void accumulate_sum(pixel_sum *sum, pixel p)
{
sum->red += (int) p.red;
sum->green += (int) p.green;
sum->blue += (int) p.blue;
sum->num++;
return;
}
static void assign_sum_to_pixel(pixel *current_pixel, pixel_sum sum)
{
current_pixel->red = (unsigned short) (sum.red/sum.num);
current_pixel->green = (unsigned short) (sum.green/sum.num);
current_pixel->blue = (unsigned short) (sum.blue/sum.num);
return;
}
static pixel avg(int dim, int i, int j, pixel *src)
{
int ii, jj;
pixel_sum sum;
pixel current_pixel;
initialize_pixel_sum(&sum);
for(ii = max(i-1, 0); ii <= min(i+1, dim-1); ii++)
for(jj = max(j-1, 0); jj <= min(j+1, dim-1); jj++)
accumulate_sum(&sum, src[RIDX(ii, jj, dim)]);
assign_sum_to_pixel(¤t_pixel, sum);
return current_pixel;
}
void naive_smooth(int dim, pixel *src, pixel *dst)
{
int i, j;
for (i = 0; i < dim; i++)
for (j = 0; j < dim; j++)
dst[RIDX(i, j, dim)] = avg(dim, i, j, src);
}一次元配列で表される標準正方形画像が、である、(i、j)は番目の画素が示されているようなI [RIDX(I、J、N)]、N像側の長さです。
パラメータ:
- 薄暗い:画像の辺の長さを
- SRC:原画像アレイアドレスへの最初の点
- DST:対象画像アレイの先頭アドレス
目的最適化:速くスムーズな操作処理を有効にするには
我々は現在、それはプログラムがCPE(サイクルあたりの要素の数)のパラメータのパフォーマンスを実行していることを示し、元の関数は、私たちが求める機能をテストし、最適化することができ、driver.cファイルを持っています。
私たちの仕事は、元のコードで最適化されたコードを達成することである状況を最適化するためのパラメータ、コードを見て比較するために実行されます。
最適化の主な方法
- ループの展開
- 並列コンピューティング
- 事前に計算されました
- 計算ブロック
- 複雑な操作は避けてください
- 関数呼び出しを削減
- キャッシュヒット率の増加
ステートメントが1つだけあり、ループ本体は、文は主に多くの計算、関数呼び出し、コールスタック複数の機能があるが、このような動作の複数の層を意味しています。
分析することで、よりこのセクションの最適化方法前のセクションでは、より直接的な行列を読み書きします。二つの側面の主要なパフォーマンスのボトルネック嘘の現在のプログラム:
- 多層関数呼び出し:関数スタックが不要な処理オーバーヘッドを追加します
- 繰り返し操作の多数:異なる画素平均演算を行うには、多くの操作を繰り返し、不要です
このセクションの最適化は、これら2つのポイントのために改善すべきです、
多層関数呼び出しを解決しやすく、呼び出された関数の必要性はライン(結合度を減らすために、ソースコードが、性能低下につながっ)の円滑な移行を実現するために機能します。
:に示されるように、以下は、繰り返し動作の問題を解析
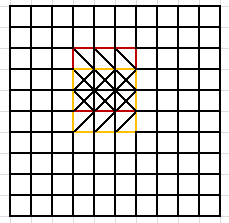
領域の平均値は、繰り返し動作の2つの行が存在する場合、赤色と黄色の領域の平均値を算出します。1×3部分行列は、各時間はわずか3平均および既知9の和で除算を計算するよう設定され、計算され、対応する最適化戦略は、計算の一定量が低減されます。
次のように最適化されたコードを対応する次のとおりです。
int rsum[4096][4096];
int gsum[4096][4096];
int bsum[4096][4096];
void smooth(int dim, pixel *src, pixel *dst)
{
int dim2 = dim * dim;
for(int i = 0; i < dim; i++){
for(int j = 0; j < dim-2; j++){
int z = i*dim;
rsum[i][j] = 0, gsum[i][j] = 0, bsum[i][j] = 0;
for(int k = j; k < j + 3; k++){
rsum[i][j] += src[z+k].red;
gsum[i][j] += src[z+k].green;
bsum[i][j] += src[z+k].blue;
}
}
}
// 四个角
dst[0].red = (src[0].red + src[1].red + src[dim].red + src[dim+1].red) / 4;
dst[0].green = (src[0].green + src[1].green + src[dim].green + src[dim+1].green) / 4;
dst[0].blue = (src[0].blue + src[1].blue + src[dim].blue + src[dim+1].blue) / 4;
dst[dim-1].red = (src[dim-2].red + src[dim-1].red + src[dim+dim-2].red + src[dim+dim-1].red) / 4;
dst[dim-1].green = (src[dim-2].green + src[dim-1].green + src[dim+dim-2].green + src[dim+dim-1].green) / 4;
dst[dim-1].blue = (src[dim-2].blue + src[dim-1].blue + src[dim+dim-2].blue + src[dim+dim-1].blue) / 4;
dst[dim2-dim].red = (src[dim2-dim-dim].red + src[dim2-dim-dim+1].red + src[dim2-dim].red + src[dim2-dim+1].red) / 4;
dst[dim2-dim].green = (src[dim2-dim-dim].green + src[dim2-dim-dim+1].green + src[dim2-dim].green + src[dim2-dim+1].green) / 4;
dst[dim2-dim].blue = (src[dim2-dim-dim].blue + src[dim2-dim-dim+1].blue + src[dim2-dim].blue + src[dim2-dim+1].blue) / 4;
dst[dim2-1].red = (src[dim2-dim-2].red + src[dim2-dim-1].red + src[dim2-2].red + src[dim2-1].red) / 4;
dst[dim2-1].green = (src[dim2-dim-2].green + src[dim2-dim-1].green + src[dim2-2].green + src[dim2-1].green) / 4;
dst[dim2-1].blue = (src[dim2-dim-2].blue + src[dim2-dim-1].blue + src[dim2-2].blue + src[dim2-1].blue) / 4;
// 四条边
for(int j = 1; j < dim-1; j++){
dst[j].red = (rsum[0][j-1]+rsum[1][j-1]) / 6;
dst[j].green = (gsum[0][j-1]+gsum[1][j-1]) / 6;
dst[j].blue = (bsum[0][j-1]+bsum[1][j-1]) / 6;
}
for(int i = 1; i < dim-1; i++){
int a = (i-1)*dim, b = (i-1)*dim+1, c = i*dim, d = i*dim+1, e = (i+1)*dim, f = (i+1)*dim+1;
dst[c].red = (src[a].red + src[b].red + src[c].red + src[d].red + src[e].red + src[f].red) / 6;
dst[c].green = (src[a].green + src[b].green + src[c].green + src[d].green + src[e].green + src[f].green) / 6;
dst[c].blue = (src[a].blue + src[b].blue + src[c].blue + src[d].blue + src[e].blue + src[f].blue) / 6;
}
for(int i = 1; i < dim-1; i++){
int a = i*dim-2, b = i*dim-1, c = (i+1)*dim-2, d = (i+1)*dim-1, e = (i+2)*dim-2, f = (i+2)*dim-1;
dst[d].red = (src[a].red + src[b].red + src[c].red + src[d].red + src[e].red + src[f].red) / 6;
dst[d].green = (src[a].green + src[b].green + src[c].green + src[d].green + src[e].green + src[f].green) / 6;
dst[d].blue = (src[a].blue + src[b].blue + src[c].blue + src[d].blue + src[e].blue + src[f].blue) / 6;
}
for(int j = 1; j < dim-1; j++){
dst[dim2-dim+j].red = (rsum[dim-1][j-1]+rsum[dim-2][j-1]) / 6;
dst[dim2-dim+j].green = (gsum[dim-1][j-1]+gsum[dim-2][j-1]) / 6;
dst[dim2-dim+j].blue = (bsum[dim-1][j-1]+bsum[dim-2][j-1]) / 6;
}
// 中间部分
for(int i = 1; i < dim-1; i++){
int k = i*dim;
for(int j = 1; j < dim-1; j++){
dst[k+j].red = (rsum[i-1][j-1]+rsum[i][j-1]+rsum[i+1][j-1]) / 9;
dst[k+j].green = (gsum[i-1][j-1]+gsum[i][j-1]+gsum[i+1][j-1]) / 9;
dst[k+j].blue = (bsum[i-1][j-1]+bsum[i][j-1]+bsum[i+1][j-1]) / 9;
}
}
}次のように効率を操作します:
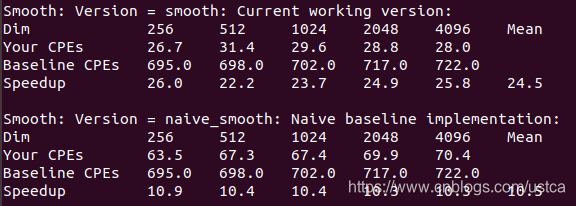
- 薄暗い:画像サイズ
- あなたのCPE:対応する機能CPE
- ベースラインのCPE:参照基準CPE
- スピードアップ:加速比=ベースラインのCPE /あなたのCPE
10.5の本来の機能を高速化した後、最適化のスピードアップはある程度いくつかのコードの可読性の損失が、24.5に上昇し、私たちが望む動作効率を高めるため。
ある程度の重複業務に低減するように最適化、より良い最適化手法は、シェアを喜ばがある場合は、完全に、重複した作業を排除しません。
:ソース記入してくださいhttps://www.cnblogs.com/ustca/p/11796896.htmlを