オリジナルリンク:https://www.leiphone.com/news/201703/3qMp45aQtbxTdzmK.html
元はGoogleのエンジニアの神は、あなたが視覚的に深さを理解することができますし、重量が初期化モードの活性化関数モデルのトレーニングに影響を与えるように、非常に良い感じ見た後、記事を書いています。
この記事では、彼の理解とコードと一緒に、オリジナルの解釈です。
まず第一に、優れた重量の初期化方法は、最適解を見つけるために、ニューラルネットワーク高速化することができます。
重量重量1初期化するために必要な条件:各ネットワーク層の活性値は、活性化関数の飽和領域内に入りません。
重り2の重量を初期化するために必要な条件:各ネットワーク層の活性値は、ゼロに非常に近いものではなく、遠く0から0(0に分布の中心)の、好ましくは平均値ではありません
1は、0の実現可能性に初期化されます。
実現可能な全ての重みを0に初期化される場合、すべてのニューロンの出力値が同じである場合、逆拡散、勾配層の全てが同じであると、重み更新は非常に、同じです訓練は無意味です。
初期化する2、いくつかの可能な方法:
事前研修:
これは、訓練されたモデルパラメータの使用は初期化されており、その後、微調整を行います。
ランダム初期化:
ネットワーク層10、ランダム初期重み各出力データ配信
インポートのTFとしてtensorflow インポートのNPとしてnumpyの インポートPLTのようmatplotlib.pyplot データ = tf.constant(np.random.randn(2000、800)、DTYPE = tf.float32) layer_sizes = 800から50 *私のために私が中範囲( 0,10)] #10层网络、输入和 num_layers = LEN(layer_sizes) FCS = [] #は完全に接続されたレイヤの出力を格納する ための I 中範囲(0、num_layers-1 ): X =データであれば I == 0 他の FCS [I - 1 ] node_in =layer_sizes [I] node_out = layer_sizes [I + 1 ] #1 W = tf.Variable(np.random.randn(node_in、node_out))#* 0.01 W = tf.Variable(np.random.randn(node_in、node_out) DTYPE = tf.float32)* 0.01 FC = tf.matmul(X、W) FC = tf.nn.tanh(FC) fcs.append(FC) plt.figure() のSESとしてtf.Session()を持つ: のSES。ラン(tf.global_variables_initializer()) 用のI における範囲(0、num_layers-1): plt.subplot( 1、num_layers、I + 1 ) のx =のFCS [I] X = np.array(x.eval()) バツ= x.flatten() plt.hist(のx = xで、ビン= 20、範囲=( - 1,1 )) PLT。ショー()
層ニューラルネットワーク10を作成し、活性化関数がTANHで、各ランダム重みは、通常、0の平均値と0.01の標準偏差は、次のような出力分布を分布されます。
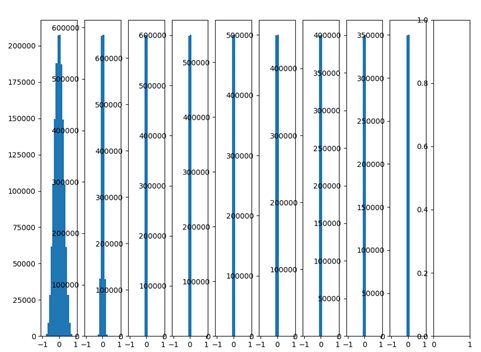
図から見ることができる層の数がネットワークとして増加し、出力値が徐々に0に近い分散、バック層の出力は、ゼロに非常に近いです。F = W.X + B偏導関数の逆伝播重みWは、X出力層の電流値を算出する際に見ることができる、すなわち勾配が生じるバック勾配伝播倍率は、そのようなパラメータを更新することは非常に小さいことが困難である場合。
大通常の初期化パラメータ転送の上、標準偏差が1となります。
W = tf.Variable(np.random.randn(node_in、node_out))
出力の分布を見てください:
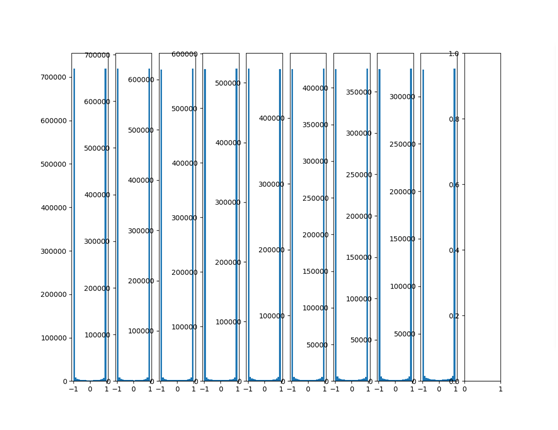
飽和領域内に入ると、出力値は1と-1の付近に集中している、活性化関数TANH関数が使用されていることがわかる機能を活性化することが見出されている、関数TANH -1とゼロに近い勾配更新すべきパラメータが困難です。
- ザビエルの初期化
ザビエルの初期化は、上記の問題を解決することができ、ザビエルの初期化値は0に傾向がすべての出力を回避するために、入力と出力の変動と一致しています。
-
W = tf.Variable(np.random.randn(node_in、node_out))/ np.sqrt(node_in)
下面就是采用Xavier初始化之后的每层的数据分布直方图: 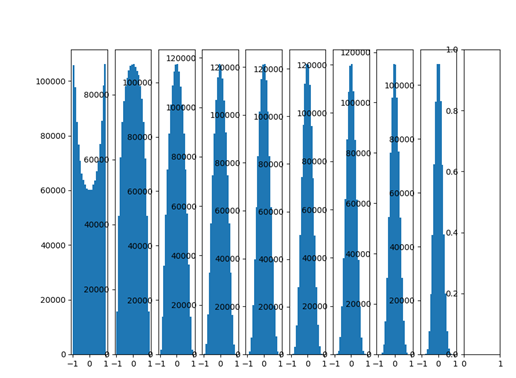
ディストリビューションの多くの層の出力は良いまま後うわー、私達にとって非常に有益なニューラルネットワークを最適化!
-
ザビエルの初期化が線形関数に由来し、それは普遍的な適用性を有していないことを示す非線形関数は、ここでしかTANH活性化機能、ReLu以下に説明起動機能テストを議論しました
-
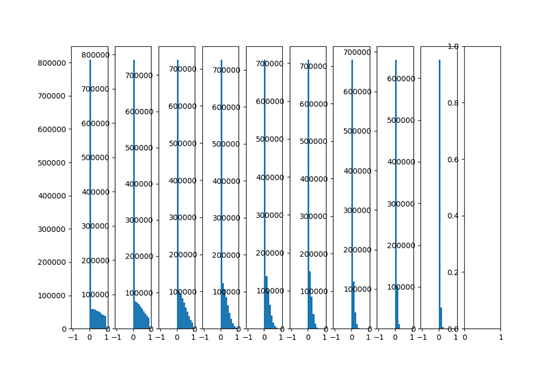
機能特性reluが層0-1は、ネットワークデータ出力に有利にバイアスされる原因となるので、それは、図から分かるように、出力分布はない 0データの近傍には、バック層にゼロを中心と。
それは非常に適用されていませんReluザビエル初期活性化機能に思えます。彼の初期化初期化の問題がrelu、解決することができるかどうか見てみましょう思考の彼の初期化を:reluネットワークでは、各層ニューロンの半分が活性化され、残りの半分がゼロであると仮定されるので、一定の分散を維持するために、ただザビエル2つの基礎で割った値。
-
W = tf.Variable(np.random.randn(node_in、node_out))/ np.sqrt(node_in / 2)
......FC = tf.nn.relu(FC)
ゼロ良い結果に近いようザビエルと以前のようにされなくなり、それが推奨され、ゼロを中心としていないが、分布の出力を見てみましょう(すなわち0平均の中心として〜0)が、少なくとも、出力値の分布は0-1の間で非常に安定していますreluネットワークインチ
バッチ正規化レイヤー:
バッチの正規化は、伝播勾配をバック計算するために、所望の非線形の活性、出力値は比較的良好な分布(例えばガウス分布)でなければならない前に持ち込ま粗悪い初期化の影響を弱めるための巧妙な方法であります更新の重み。バッチ正規化出力値は強制的にガウス正規化し、線形変換を行いました。

それを可能にするすべての操作がスムーズに導出されているバッチ正規化は、効果的にΥβに対応したバックプロパゲーション学習パラメータは、バッハ正規化は、電車やテスト時の動作で異なるようにする場合。以下のためのトレーニング
マイクロベータ]と、σ β-計算現在のバッチに由来する、マイクロテストベータ]と、σ β-トレーニングを使用した場合の値が保存されるべき手段等がなく現在のバッチ計算よりも、処理され
バッチ正規化テスト:
Reluの活性化、ランダムな初期化、通常の無バッチ:

ランダムな初期化、そこbatchNormalization:
= tf.contrib.layers.batch_norm FC(FC、真の中心=、スケール=真、is_training = TRUE)
出力データは全てDTYPE =のfloat32、batchnormのfloat32必要なデータ型に変換される前に入力データが必要なことをここで#注意、ああ、データの矛盾が文句を言うだろう

図からわかるように、バッチノーマライゼーションを加えた後、ネットワークの深化と、出力データの分布は0、良い結果に傾向がない、井戸層の後ろに残っています。
推奨される初期化
・ReLU活性化機能における推奨ザビエル初期化変種、コール彼の初期化:

- 効果的にネットワークの重みの初期化依存性の深さを減らすことができますバッチ正規化層を使用します。

要約:良い重みの初期化と活性化関数は、学習の目的を達成するために、標準体重を更新する、ネットワーク内のデータの正常な流れを可能にする、上記の実験は、直感的重みの初期化と出力活性化関数の分布への影響を理解することができます。