
I.はじめに
ソフトウェア システムのパフォーマンス テストは、ビジネスの遂行能力と安定性を確保するための重要な手段です。ソフトウェア システムの機能構築を本筋として考えると、システム機能設計作業とパフォーマンス テスト作業には順序があり、相互に影響を及ぼします。上記の内容は、シナリオの意思決定、アーキテクチャ分析、トラフィック分析、ストレス テストの実装、分析と最適化などのパフォーマンス テストの主要な側面において、システム機能とシャーシの統合とテスト戦略の改善について多くの考えを引き起こすきっかけとなりました。
パフォーマンス テスト フェーズでは、システム機能の実装とソリューションの調整を分析し、より優れたソリューションとパフォーマンス テスト戦略の余地を探ります。
2. ホットデータストレージモデルの実戦とストレステストの感想
パフォーマンス テストを通じて、SKU 在庫の占有前のシナリオ、パフォーマンスのボトルネック、およびさまざまなストレージ モードでのリスクを推測できます。
データ アーキテクチャのアップグレード後、SKU 在庫予約効率 (TPS) は 2300%↑ 向上しました。
システム実装と組み合わせたテスト駆動により、キャッシュの予熱の必要性が実証され、ビッグデータ分析を使用して科学的なキャッシュの予熱と絶縁戦略が検討されます。
新しいビジネスモデルと組み合わせて、より科学的なテストデータ構築のアイデアやテストプロセスの効率改善計画を検討します。
1. ストレステストのシナリオ
在庫予約とは、注文受信プロセス中にドキュメントの SKU 在庫を短期間予約することを指します。物流倉庫の注文受信プロセスでは、SKU ディメンションでの在庫の先取り動作が開始されます。
在庫センターは、「在庫プリエンプション メイン アプリケーション」のプリエンプション インターフェイスを通じて、SKU 在庫プリエンプション標準機能を外部に提供します。主に、「在庫控除ロジック制御とデータベース層の相互作用」、「キャッシュ層の相互作用」、「タスクのスケジューリング」という 3 つの主要なアプリケーションを通じて、在庫ロジックの計算とストレージ層の相互作用機能を実現します。
データ モデルの観点から見ると、プリエンプション機能の実装には次の 2 種類があります。
▪事業部門のディメンション在庫のプリエンプションは、主に Redis キャッシュ レイヤーを通じて実行されます。
▪バッチ インベントリの事前占有はデータベースによって直接実行されます。
大規模な販売促進中の倉庫割り当ての量が爆発的な時期に入り、ホット SKU の先取りリクエストが急速に増加し、在庫の先取りリクエストがデータベースに直接送信されると、システムの TP99 が急上昇するか、さらには上昇し続け、注文が発生します。重大なケースではタイムアウトが発生します。
上記では、システムのピーク耐力と調整戦略の有効性を確認するために、対象を絞ったストレス テスト シナリオとデータ モデルを構築する予定です。
2. 最初の圧力と分析
◦ ストレステストのターゲット:「インベントリ プリエンプション メイン アプリケーション」の「プリエンプション インターフェイス」、ホットスポット SKU プリエンプション リクエスト モードを運ぶデータベースで、ターゲット TP99 (≤3000ms) が伝送できるピーク トラフィックを調査し、検証します。最適化されたピーク搬送能力 (目標 TP99≤500ms)。
◦ ストレステスト計画: 単一のホットスポット SKU が継続的に負荷をかけられ、事前占有されます。負荷は QPS=10 から始まり、QPS+10 ずつ増加して、リクエストを処理できるパフォーマンスの上限を調べます。
◦圧力試験のプロセスと結論
▪QPS=50の場合、システムは安定して在庫の先取り業務をサポートできます(TP99≒100ms)。
▪「インベントリの事前占有」メイン アプリケーション: CPU 使用率 ≤ 15%、メモリ使用率 ≤ 35%
▪「在庫控除ロジック制御とデータベース層の相互作用」アプリケーション: CPU 使用率 ≤ 18%、メモリ使用率 ≤ 65%
▪データベース: CPU 使用率 ≤ 7.8% (遅い SQL なし)
▪現在のシステム性能に基づき、連続加圧が可能な条件を備えています。
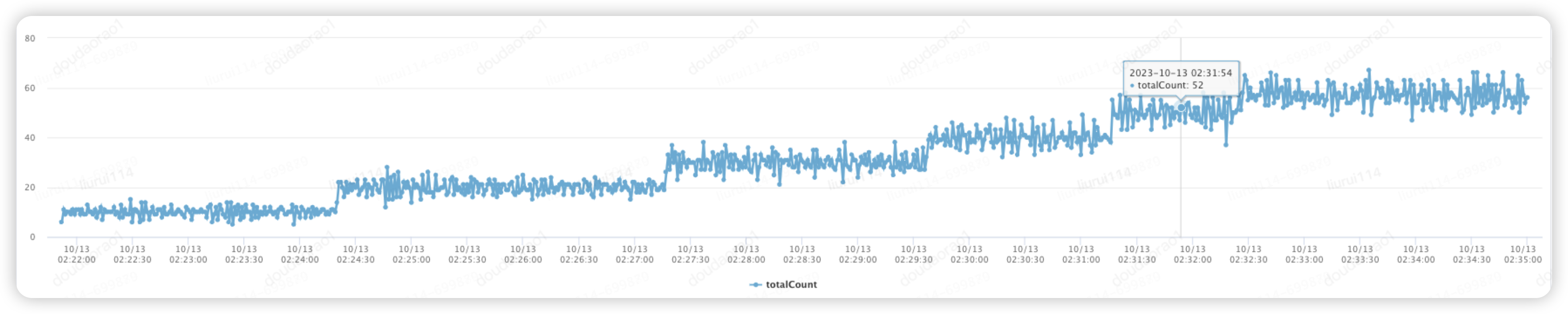
▪QPS+10 ずつ圧力を 60 まで増加させると、TP99 は約 2 分で 7000ms まで急速に増加します。「在庫先取り」の主な用途は TPS ≤ 60 です。システム容量がボトルネックに達し、圧力が停止されます。
「在庫先取り」メインアプリケーションTP99+TPS傾向

「インベントリの横取り」の主要なアプリケーション ハードウェア リソースの傾向


データベースの主要な指標 (CPU)
データベースの主要なインジケーター (遅い SQL)
データベースの主要な指標 (メモリ)
ボトルネック予測: ドキュメント次元での在庫のプリエンプションは、最初にチェック (利用可能な在庫) し、次に書き込み (在庫のプリエンプト) によって実行されます。ホット SKU の高頻度注文のプロセス中に、データベースにこれが記録されます。連続的な読み取りと書き込みの場合、データベース レベルでは、行ロック メカニズムを通じて単一トランザクションのアトミック性が保証されます。行レベルのロックによって引き起こされるロック競合により、システムの処理能力がボトルネックに達する可能性が高くなります。システムの実行効率を制限します。同時に、アプリケーション層からストレージ層までのハードウェアリソースのボトルネックがなく、ハードウェアリソース不足による影響も排除されます。
3. チューニングと再圧力
ストレージレイヤーの変換( 「インベントリ センター - インベントリ プリエンプション シナリオのシステム アーキテクチャ図」を参照): ストレス テストと分析の最初のラウンドの後、既知のパフォーマンスのボトルネックをデータ アーキテクチャ レベルから解決するために、バッチ インベントリ プリエンプションが実行されます。プレッシャー、主にリクエストプレッシャーを運ぶ Redis キャッシュへのアップグレード。Redis の高性能スループット機能は、同時シナリオでのデータの読み取りと書き込みの効率の問題を解決するために使用され、Redis は人気製品の主要なトラフィックを前に運ぶために使用されます。
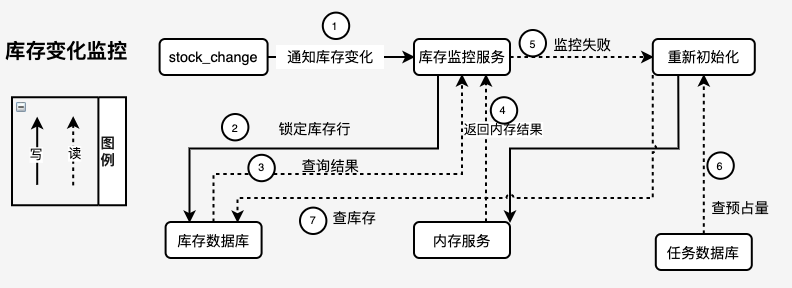
整合性の保証(在庫センター - 在庫変更監視メカニズムの簡略図を参照)
▪キャッシュ層とデータベース層の間のデータの一貫性を確保するため、キャッシュ ヒットの場合、スケジューリング タスクまたは MQ メソッドを確立することにより、データベースは非同期に書き戻されます。
▪キャッシュが故障した場合、最初に読み取り (データベース)、書き込み (Redis)、次にフィードバック (API) を行うことによって結果がプリエンプトされ、データの一貫性を確保するために非同期でデータベースに書き戻されます。
在庫センター - 在庫事前占有シナリオのシステム アーキテクチャ図

在庫センター - 在庫変更監視メカニズムの簡略図
◦再圧力の結論
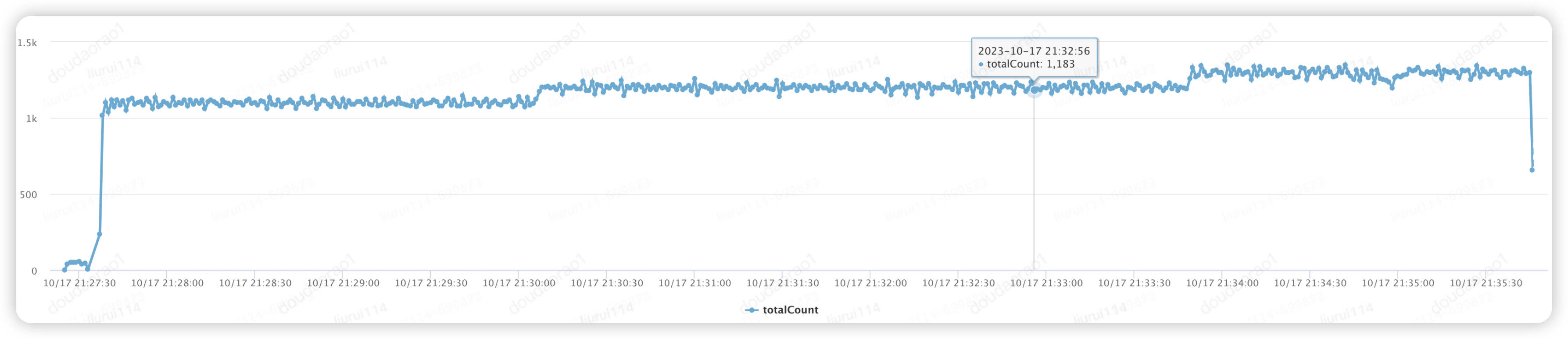
▪データ アーキテクチャのアップグレードとホットスポット SKU キャッシュのウォームアップが完了すると、初期 QPS = 1100 から 100 ずつ増加します。TPS が 1200 に達すると、TP99 ≈ 130ms となり、システムはバッチ インベントリの事前占有ビジネスを安定してサポートできます。
▪TPS が 1300 に達すると、TP99 が大きく変動し (グリッチ ≈ 420ms)、「キャッシュ レイヤー インタラクション」アプリケーションの CPU 使用率が 90% 以上に急上昇し、コア リンクの安定性が低下し、圧力が停止します。
▪データベース ベアリング モードと比較すると、キャッシュ アップグレード後、TP99 は期待値 (≤500ms) を満たし、TPS ベアリング容量は 2300%=(1200-50)/50 と大幅に増加しました。
「在庫先取り」メインアプリケーションTP99+TPS傾向

「インベントリの横取り」の主要なアプリケーション ハードウェア リソースの傾向


データベースの主要な指標 (CPU)
データベースの主要なインジケーター (遅い SQL)

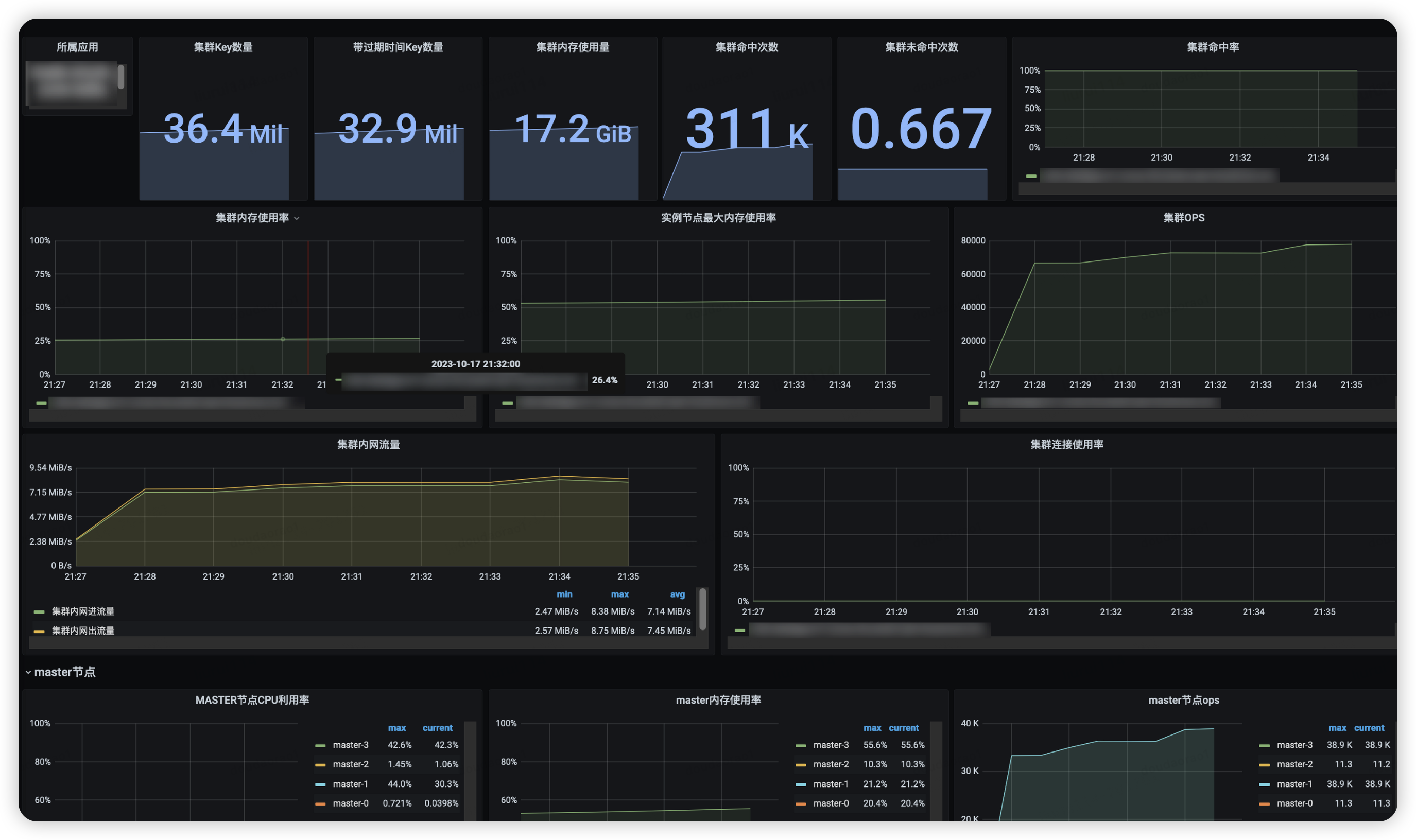
データベースの主要な指標 (メモリ)

Redis クラスターの主要なインジケーター
4. システムの堅牢性について考える
◦**フル キャッシュの欠点: **サプライ チェーン モデルの業界が異なると、SKU カテゴリのライフ サイクルに大きな違いがあります (アパレル業界では約 3 か月など)。フル キャッシュ モードでは、多数の無効な SKU が発生します。 Redis のカテゴリとリソース消費。拡張は制御不能であり、リソース コストが増加します。より効果的なキャッシュ ソリューションを設計する必要があります。
◦**キャッシュの予熱と保温の必要性:**キャッシュのヒット率は、予熱のメカニズムと保温戦略に密接に関係しています。
▪必要性: 定期的な大規模なプロモーションのリズムと販売期間の開始により、一次キャッシュの初期化がトリガーされ、プロモーション カテゴリと日次販売カテゴリの重複により、一次キャッシュが破壊される確率が決まります。現在のキーの有効期間 = 7 日、販売期間→順調なスタート→ピーク期間の間隔は 7 日を超えています。必要な隔離戦略が欠如していると、次のプロモーション ノードの前にキャッシュが失敗する可能性が高くなります。
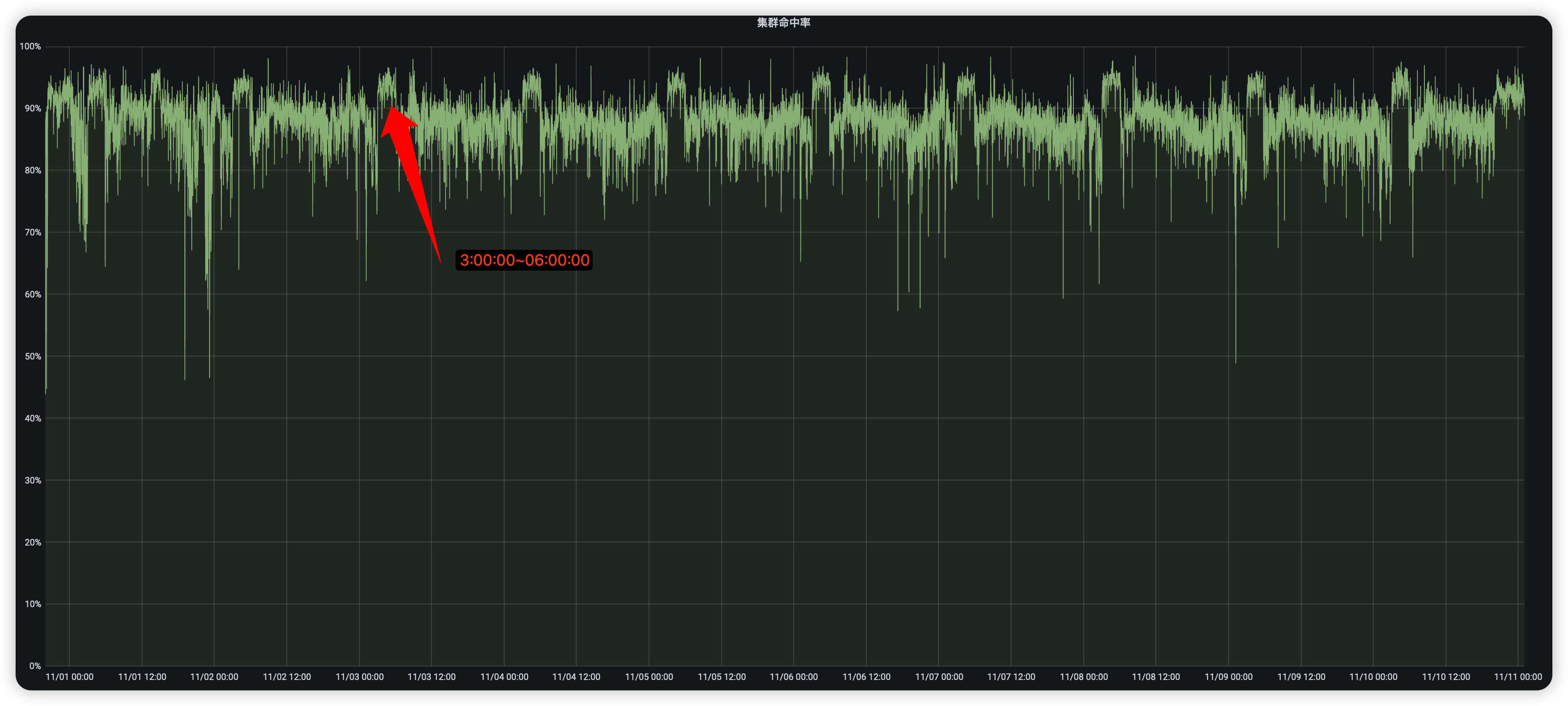
11.11 キャッシュ ヒット率のトレンドへの素晴らしいスタート
システム全体としては、トラフィックをスムーズに伝送し、同時にヒット率曲線をキャッシュできるため、改善の余地があります。
▪プレヒートアイデア:ビッグセールなどの特定期間において、キャッシュの有効性をできるだけ維持し、キャッシュのヒット率を向上させる(故障確率を下げる)方法を、事前に処理した多次元解析により実現します。ビッグデータベースの分析を含むがこれらに限定されない、技術的手段と組み合わせた、プロモーション前の集中購買カテゴリー分布分析、過去の主要プロモーションおよびキーノードプロモーションカテゴリーの密度と分布分析、主要顧客プロモーション計画の調査など。 、事前判定、予熱、断熱。
◦** キャッシュの予熱方法: ** 顧客の大規模なプロモーション前の集中購入期間と、大規模なプロモーション ノードの SKU カテゴリの重複を分析することにより、次のルールが見つかりました。
集中購入の観点: 大規模なプロモーション期間中の SKU カテゴリの重複は、オープナー カテゴリと比較して約 69%、11.11 カテゴリと比較して約 75% です。
▪販売の観点: 初期販売期間中の SKU カテゴリの一致度は、オープナーと比較して約 94%、11.11 カテゴリに対するオープナーの重複は約 75% です。
▪上記のデータは、グッド スタートや 11.11 プロモーションなどの主要なプロモーション ノードの前に、集中調達期間と前のプロモーション期間の SKU 利用可能な在庫データのキャッシュを予熱することで、事前のキャッシュ ヒット率の向上に役立つことを証明しています。リクエストを空にする。
主要なプロモーション リンクにおける SKU カテゴリの重複の分析

◦**異常シナリオの特定:**インベントリシナリオでは、データの 3 つの特性 (精度、適時性、完全性) に対する高い要件があり、データベースとキャッシュ間の双方向の同期プロセス中に発生するビジネス例外を回避する必要があります。一貫性の問題により。
▪売れすぎ例外の識別: 販売のピーク時には、メイン データベースのセキュリティを保護するために、キャッシュ同期と電流制限を使用してメイン データベースへの負荷を軽減し、キャッシュとデータベース間の同期遅延を引き起こします。 SKU はデータベース層で期限内に差し引かれません。この場合、キャッシュが重ねられます。キーの有効期限が切れた場合、インターフェイスは MySQL データを直接返します。これにより、売られすぎたビジネス例外が発生する可能性があります。
▪システム最適化のアイデア
▪静的プラン: 単一ボリュームのピーク期間中、主要なプロモーションの主要な期間をカバーするためにキーの有効期間が延長されます。
▪動的ソリューション: ホットスポット SKU キャッシュの有効期間遅延戦略を追加します。キーの有効期限は T-1 日で、1 日の平均プリエンプション リクエスト量が 1 を超える SKU は、キーの有効期間を自動的に延長します。
5. テスト戦略の改善に関する考え方
◦シーン展開
▪ライブブロードキャスト電子商取引モデルの主流化の傾向は強い(2023年最初の3四半期、全国のライブブロードキャスト電子商取引売上高は60.6%増の1兆9,800億元に達し、オンライン小売売上高の18.3%を占め、ライブブロードキャスト電子商取引は、オンライン小売の成長率を7.7パーセントポイント押し上げました)、従来の電子商取引と比較して、その期間限定のプロモーションモデルにはソーシャルコミュニケーションと拡散属性が重畳されており、その結果、単一の製品に対する瞬間的なトラフィックが大量に発生します。異なるプロモーション セッション間の下位カテゴリの重複、およびプロモーション頻度の高さにより、システム パフォーマンスに対するさまざまな要件が提示されます。
▪バックワード パフォーマンス テスト戦略は、プラットフォームの観点から見ると、SKU の多様性を可能な限り高めながら、ストレス テストの 1 つのリクエストにおける SKU のカテゴリの重複を減らし、実際の複雑なシナリオにおける潜在的なパフォーマンス リスクを特定する必要があります。
◦効率の向上:複雑なシナリオでの倉庫物流オーダーのパフォーマンステストには、大量の基本データ(商品、在庫)の確保と、高度に複雑なインターフェース要求データの準備が必要です。製品や在庫などの基本データを迅速に準備するにはどうすればよいですか? 同時に、注文リクエストのメッセージ本文を自動的に構築し、SKU の密度と複雑さの要件に従って迅速に組み立てることはできますか? 基本データから複雑なドキュメントまでワンクリックで迅速な初期化構築をサポートし、複雑なシナリオ構築の難易度を軽減し、テスト作業の効率を向上させるためには、既存のストレステストフレームワークをベースにした拡張機能を開発する必要があります。
3. 無効な通話の分析、特定、最適化
パフォーマンス テストのトラフィック分析フェーズでは、ビジネス シナリオの調査と組み合わせて、パフォーマンスのボトルネックの疑いがあるものを事前に特定します。
調査を推進し、コアリンクの呼び出しロジックを調整した結果、調整されたビジネスウィンドウ期間中に、コアインターフェイスの総呼び出し数が60%減少しました↓。
ビジネス シナリオを深くセグメント化し、潜在的な調整スペースを推定します。
1. 背景
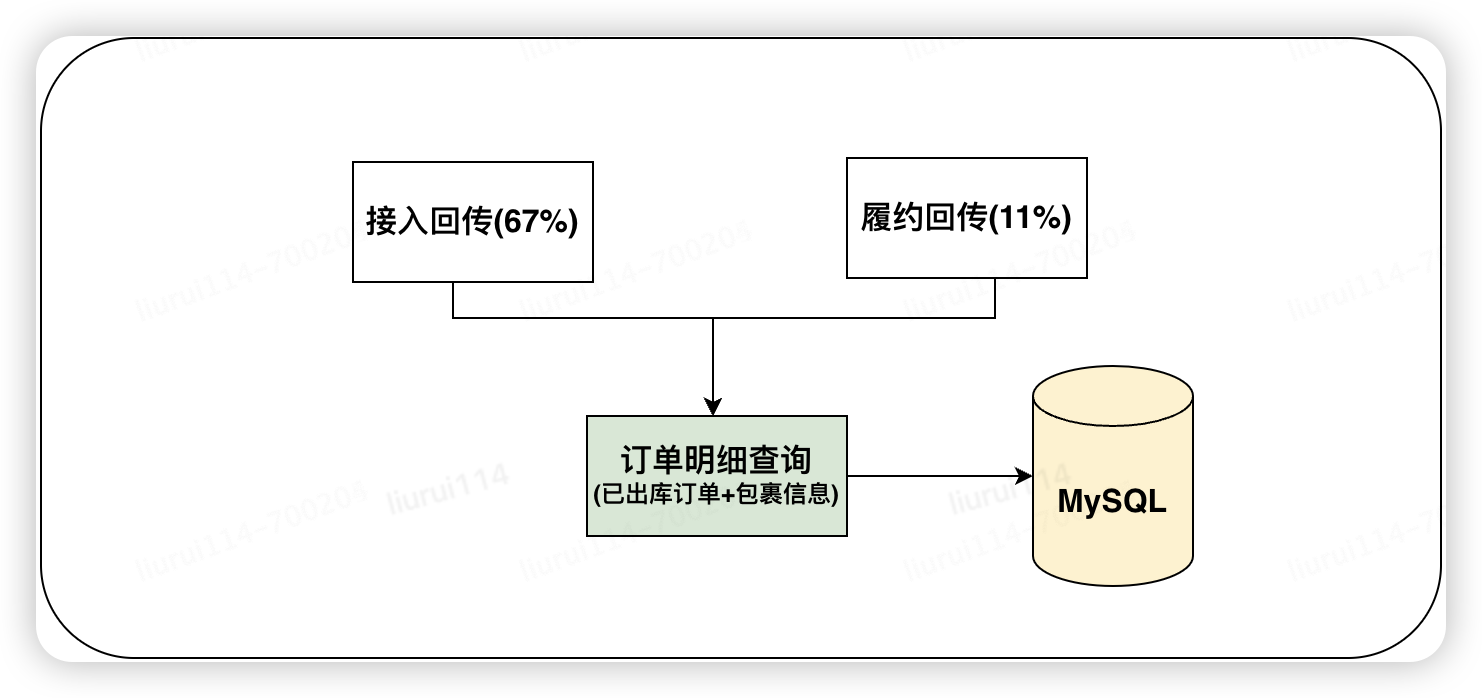
注文が倉庫から出荷されると、物流システムは注文詳細クエリ アプリケーションを使用して、注文とそれに関連する荷物の詳細に対する外部クエリ機能を提供します。主に外部システムから呼び出されます (上位 2 レベルの呼び出し元: アクセス収益 67%、フルフィルメント収益 11%) ドキュメントが倉庫から出荷された後、出荷商品の数量やパッケージの詳細などの基本的な注文情報が出力されます。
主要 (上位 2) 呼び出し元トポロジ
2. シナリオ調査と疑わしい点の特定
◦シナリオ調査とリスク予測(生産フロー分析)
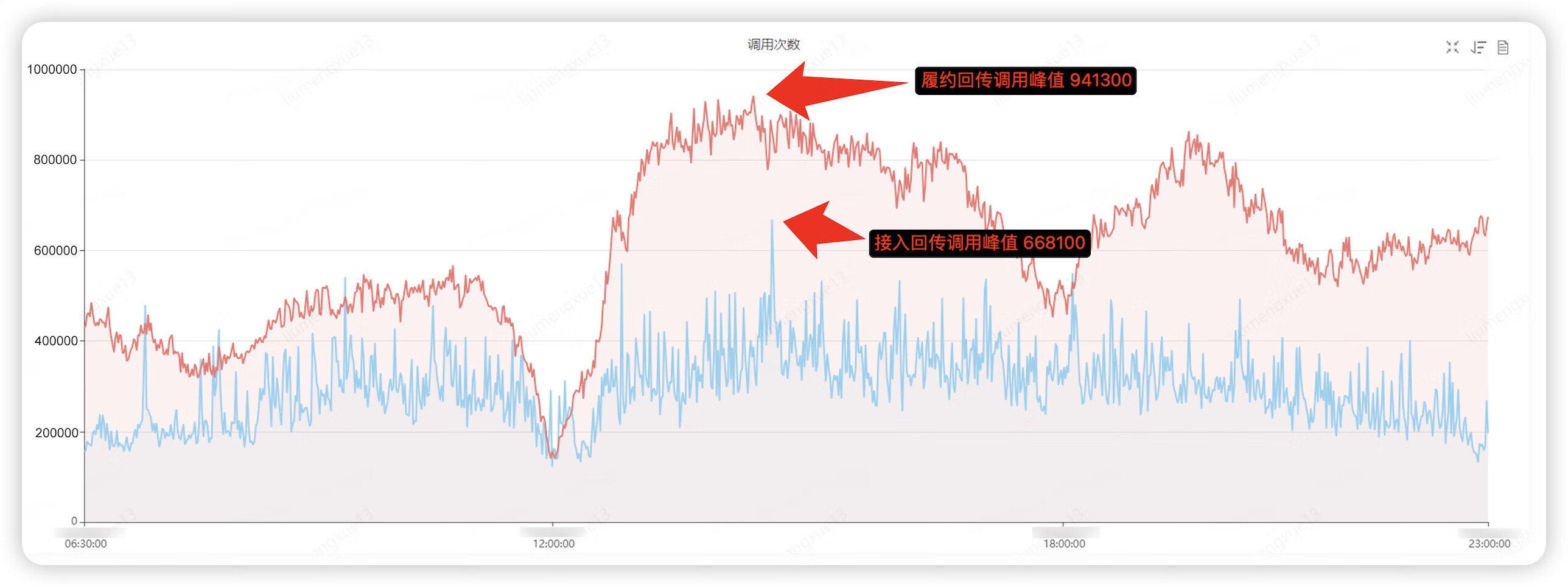
▪「注文・荷物詳細照会インターフェース」の通話量傾向分析を23年間(トラフィック分析期間)10.12 06:30~23:00をサンプリングし、最新プロモーションの同時期(最新プロモーションのピーク時)と比較して分析を実施。大規模なプロモーション リクエスト)、トップ 2 コール ピーク時のコールの総数は 305% 急増しました。
▪事前調査とコール量の観点から、通常の状況下での倉庫出荷の平均処理能力は約 400,000 注文/分であり、倉庫出荷のピーク時間帯は毎日 08:00 ~ 18:00 です。 : 「注文および荷物の詳細照会「インターフェース」のピーク通話量 ≈ 1:10 が「通常の比率」です。
▪10月12日のオンラインデータの観察によると、入庫件数:「注文・荷物詳細照会インターフェース」のピークコール額(400000/6532200)≈ 1:16で、「通常の出荷件数」よりも大きな乖離が見られた。比率"。
▪上記において、生産トラフィック分析作業を通じて、倉庫出荷のピーク時間帯における「注文・荷物詳細照会インターフェース」への呼び出し件数に疑問があることが判明し、さらに詳細な分析を行った。実施した。
最新のプロモーション期間中の主要なアプリケーションのコール数
2023 年 10 月 12 日の主要なアプリケーション コールの量

◦ コールチェーンの粗いスクリーニング
▪倉庫割り当ての倉庫外ドキュメント ディメンション、フルフィルメント コールバック アプリケーション、倉庫外詳細を注文システムにプッシュすると、倉庫詳細クエリ インターフェイスが呼び出されます。
▪返品アプリケーションに接続します。注文情報が返されると、倉庫詳細クエリ インターフェイスが呼び出されます。
▪パフォーマンス ステータス コールバック コールのピーク値 / アクセス コールバック コールのピーク値 ≈ 1:9. アクセス コールバック コールのピーク値は明らかに大きく、疑わしいシステム (アクセス コールバック アプリケーション) は徐々にロックされます。
◦疑問点の徹底分析
▪綿密な調査の結果、異常なトラフィックと不審なシステムの初期判断が基本的に正確であったことが初めて確認されました。
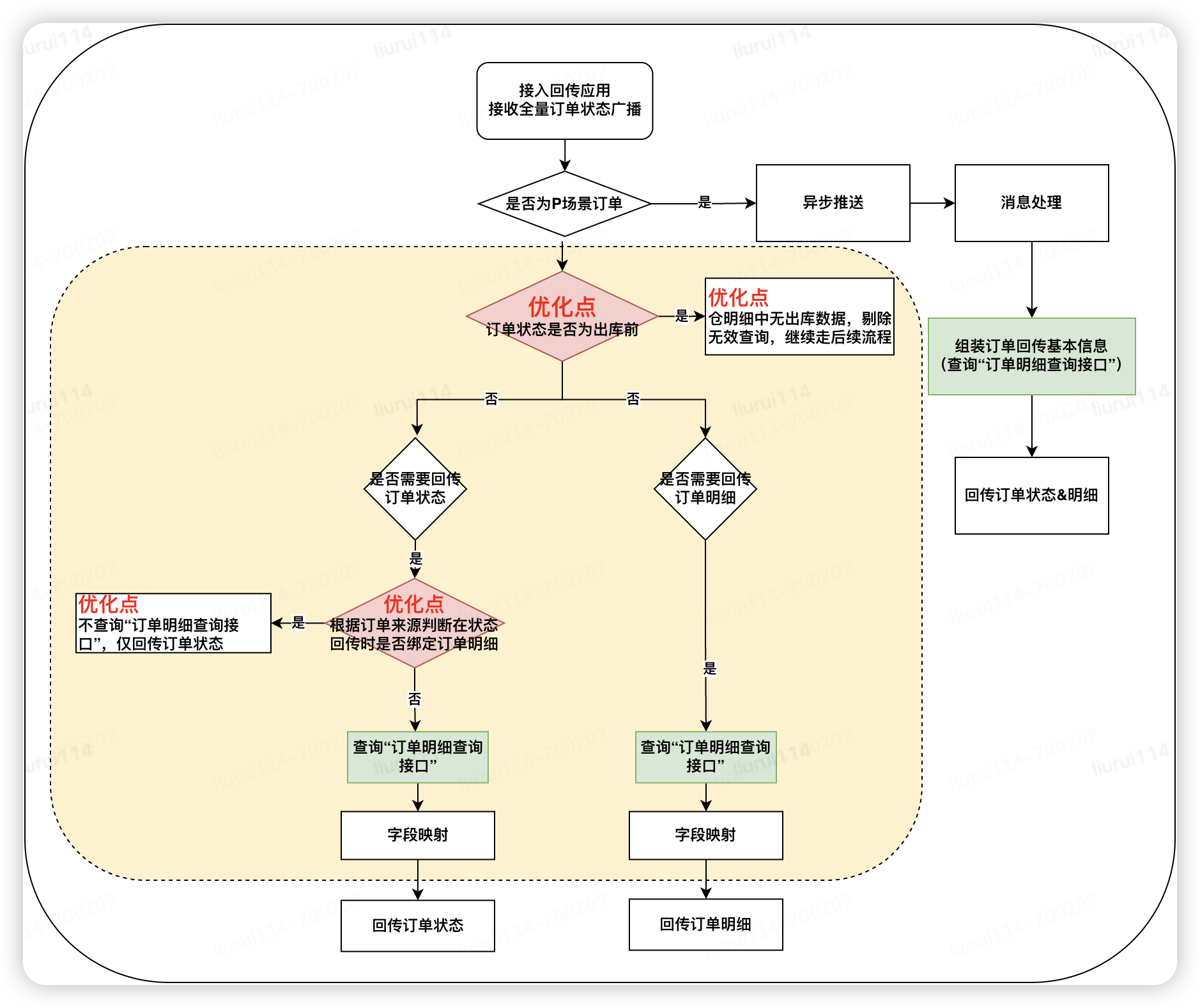
▪技術アーキテクチャ レベルでは、アクセス コールバック アプリケーションは注文ステータスを判断せずにターゲット インターフェイスを呼び出します。その結果、書類が倉庫から発送されず、発送の詳細がない場合に、無効なコールが多数発生しました。
▪同時に、ABテスト環境のエイリアス設定に誤りがあり、本番トラフィックが誤って重畳されてしまうことが判明しました。
3. チューニング戦略
◦コールロジックの調整
▪ "I" ビジネス シナリオの注文返品段階で、ドキュメントのステータスが出荷前の場合、「注文パッケージ詳細クエリ インターフェイス」呼び出しは開始されず、無効なクエリは削除されます。
▪最終的に返ってきた内容(詳細情報の要否)をもとに、通話の必要性を判断し、不要な問い合わせを排除します。
◦ AB テスト環境のエイリアス構成を調整して、テスト トラフィックが実稼働環境に不必要な圧力を与えないようにします。
最適化の前にポストバック アプリケーション ロジックにアクセスする

バックホールアプリケーションロジックへの最適化されたアクセス
4. チューニング効果
◦チューニング前(10.12)と比較して、 「バックホールアプリケーションへのアクセス」への総コール数が60%削減↓ (変更前:2397252500、変更後:925890100)、ピークコール数は64%削減↓(変更前) :5921500、以降:2121800)。
次の図は、調整前と調整後のコール量の分布を比較したものです。
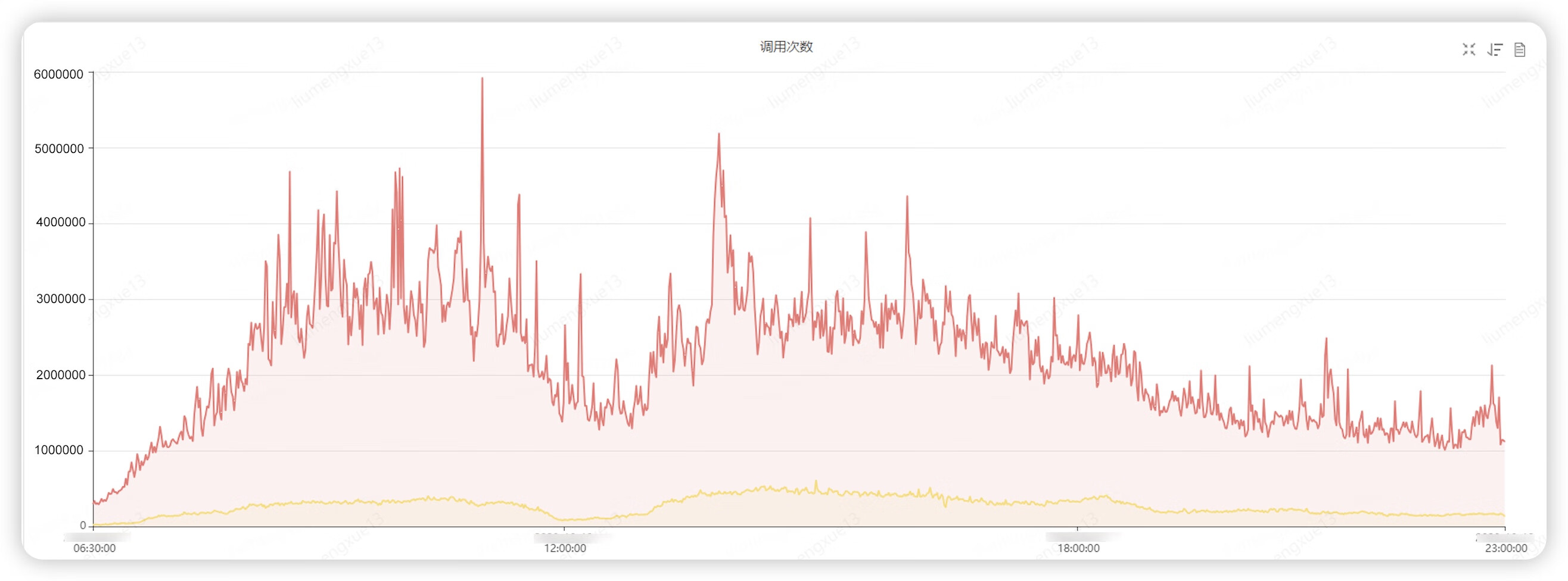

5. パフォーマンスリスクの事前特定
◦性能リスクを発見する段階はストレステスト実施段階だけではなく、トラフィック分析段階で性能リスクを特定し、実証を進める能力があれば、早期に問題を発見するほど、リスク管理コスト(リソース)は小さくなります。そして品質リスクも低くなります。
6. OpsReview を正規化する
トラフィック異常の観察: トラフィック分析とパフォーマンス リスクの特定では、実際の運用および運用の特性とインターフェイスのキー コール チェーンを組み合わせて、システム コール量の一般的なルールを定義する必要があります。着信側は、通話の発信元と通常の規模を継続的に特定し、外部通話戦略の棚卸しを行い、通話量が変化した場合のリスクを調査する必要があります。
◦ コーディング標準: チームの共同開発中に人によって異なるコーディングの違いを回避し、無効なクエリの可能性を減らすために、インターフェイス呼び出しロジックを標準メソッドに抽象化する必要があります。
◦ カスタマイズされたロジックのトラブルシューティング: システムには非標準サービス用のカスタマイズされたロジックが多数あり、特別なロジックに基づいて無効なクエリのリスクをトラブルシューティングする必要があります。
7. 潜在的な調整スペースの推定
◦テスト経験を踏まえ、業務シナリオを整理したところ、「Iシナリオ」の下に細分化された非標準のカスタマイズプロセスが存在し、「Iシナリオ」と並行して標準プロセスである「Pシナリオ」が存在することが判明しました。
◦連携R&Dでは、「Iシナリオ」の非標準カスタマイズプロセスと「Pシナリオ」の標準プロセスを詳細に分析し、更なる最適化の余地があることを確認し、最適化計画を明確にしました(以下に示すように)。
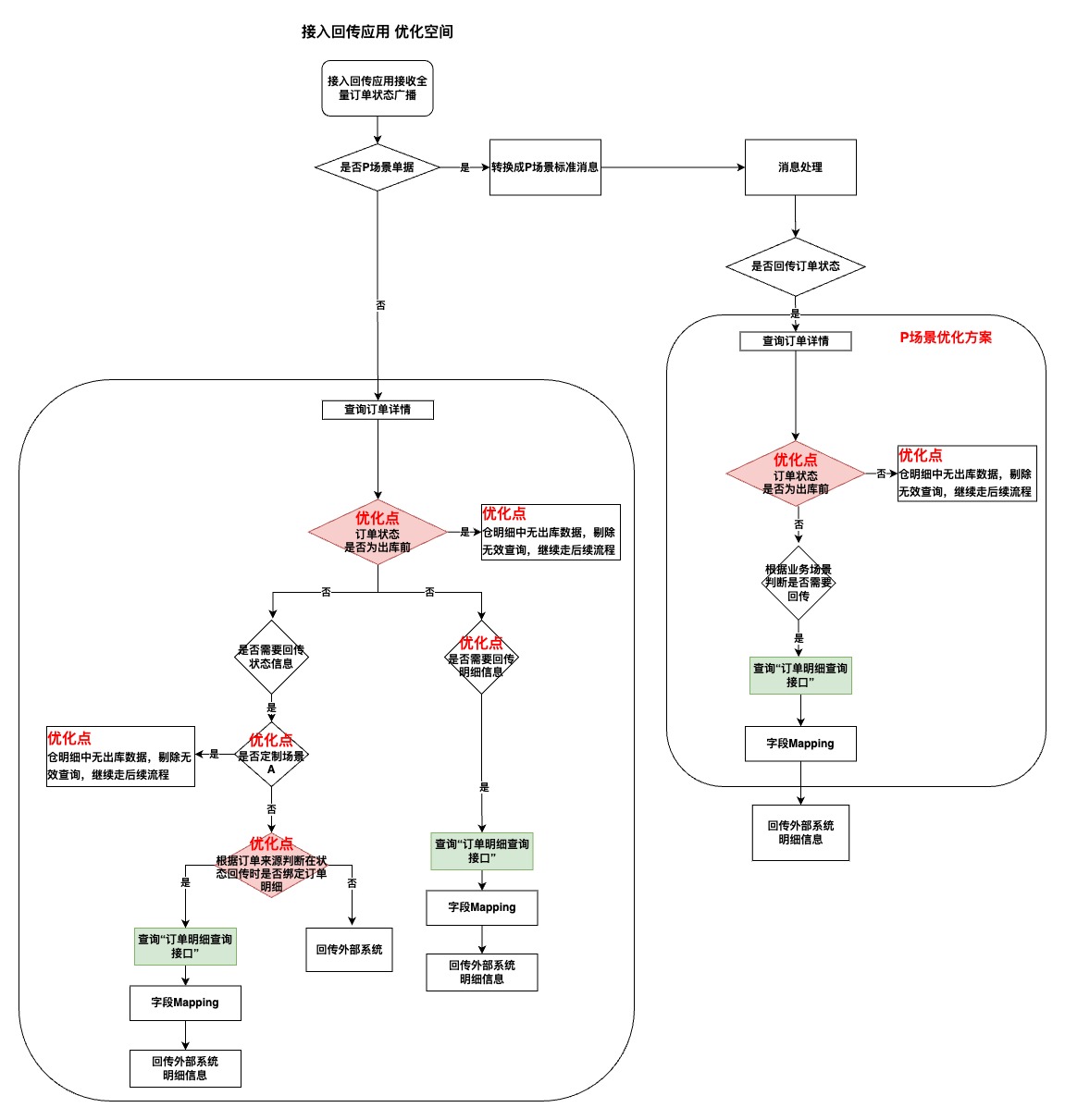
4. まとめ
パフォーマンス テストは、システム機能を統合およびアップグレードするための重要な手段であり、典型的なケースの提示と考察を通じて、システム機能とパフォーマンス テスト戦略の改善の余地を探ります。極端なシナリオを冷静に処理しながら、コア システム リンクがピークのビジネス トラフィックを安定的かつ効率的に伝送できるようにします。
著者: JD Logistics Liu Rui 他
出典:JD Cloud Developer Community Ziyuanqishuo Tech 転載の際は出典を明記してください
ブロードコム、既存のVMwareパートナープログラム終了を発表 . サイトBが2度クラッシュ、テンセントの「3.29」レベル1インシデント…2023年のダウンタイムインシデントトップ10を棚卸し、 Vue 3.4「スラムダンク」リリース、 ヤクルトが95Gデータ流出を確認 MySQL 5.7、Moqu、Li Tiaotiao... 2023 年に「停止」される (オープンソース) プロジェクトと Web サイトを棚卸す 「2023 中国オープンソース開発者レポート」が正式リリース 30 年前の IDE を振り返る: のみTUI、明るい背景色…… Julia 1.10が正式リリース Rust 1.75.0がリリース NVIDIAがGeForce RTX 4090 Dを中国で特別販売開始