PLA:前回は、私たちは、線形分類問題を解決するための簡単な方法をご紹介します。PLAは、データが完全に正しく分類された試料の平面に沿って選択することができます。直線的に不可分の場合には、ポケットアルゴリズムを処理するために使用することができます。このレッスンでは、マシンの種類、および要約についての学習に焦点を当てます。
(分割された入力空間の変化に応じて)異なる出力容量Yと学習
銀行の例には、個人的な事情に応じて、彼に発行されたクレジットカードは、これは典型的なバイナリ分類(バイナリ分類)の問題であるかどうかを判断します。すなわち、2つの一般的なYの出力のみである= { - 1、+ 1}、 - クレジットカードの1つの代表(ネガ型)を送信しない、クレジットカード+ 1(正のクラス)の代表。
バイナリ分類問題は、クレジットカード決済、スパムの識別、患者の診断、推定の精度、およびその答えを含め、非常に一般的です。バイナリ分類は、機械学習では非常に中心的かつ根本的な問題です。リニアバイナリ分類モデルは、別のモデルを選択し、実際の状況の問題に応じて、また、非線形モデルです。
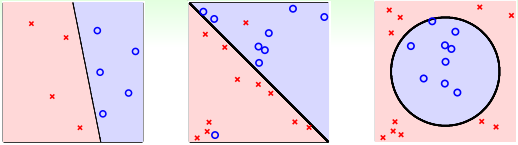
バイナリ分類に加えて、多変量分類(多クラス分類)という問題があります。名前が示すように、二つ以上の多変量分類の出力、Y = {1、2、...、K}、K> 2.一般多変量分類アプリケーションは、識別番号、画像認識などのコンテンツです。

バイナリ分類と多変量分類は分類に属し、その出力は離散的な値です。
そのようなトレーニングモデルとして別のケースについては、住宅価格を予測、株式リターンどのように他の多くのそのような問題の出力y = R、つまりは、現実空間の全範囲で、連続しています。この種の問題は、我々はそれ回帰(回帰)を呼び出します。
最も単純な線形回帰は、一般的な回帰モデルです。
これは、機械学習の問題で使用されます(構造化学習)を学べる構造。出力空間の構造化学習が内部にいくつかの構造を含む、その解決策のいくつかは、通常フィールドの、多言語拡張マルチ分類問題から来ています。
簡潔に述べるとを含む、出力に応じて分割され、次いで、機械学習空間を要約バイナリ分類、多変量分類、回帰、構造化された学習ような異なるタイプのような、。これは、バイナリ分類と回帰2種類のコア、最も基本的なものです。
異なるデータラベルYN(マークに応じてデータを分割)で学ぶ二、
D入力機能の両方のトレーニングサンプル我々は、Xが、また、出力YNを取得する場合、我々は学習のこのタイプは、(教師付き学習)学習指導と呼ばれる呼び出します。
教師付き学習が進分類、多変量分類または回帰することができ、最も重要なことは、出力ラベルYNを知ることです。
非教師あり学習(教師なし学習)の別のタイプとは対照的に、そして教師付き学習。
教師なし学習は、一般的に教師なし学習には、何も出力YNラベルではありません:そのようなニュース上のWebページの自動分類としてクラスタリング(クラスタリング)問題、;密度推定は、そのような交通状況の分析など、異常検出、このようなユーザのネットワークトラフィックなどモニタリング。一般的に、教師なし学習は、より複雑で、かつ教師なし多くの問題は、多くのアルゴリズムを用いて実現することができる教師付き学習を考えています。

これは、教師と教師なし学習(半教師付き学習)との間に介在する半教師付き学習と呼ばれます。
タグデータの別の部分は、出力YNないが名前として、示唆出力データタグYNの一部であり、半教師あり学習。実用的なアプリケーションでは、半教師付き学習は、このようなテストのための特定の薬剤のための製薬企業として、必要がある場合もあり、考慮に他の実験人口問題のコストと限界を取って、データ出力ラベルYNの一部のみがあります。
強化学習(強化学習):また、非常に重要な種類があります。
增强学习中,我们给模型或系统一些输入,但是给不了我们希望的真实的输出y,根据模型的输出反馈,如果反馈结果良好,更接近真实输出,就给其正向激励,如果反馈结果不好,偏离真实输出,就给其反向激励。不断通过“反馈-修正”这种形式,一步一步让模型学习的更好,这就是增强学习的核心所在。增强学习可以类比成训练宠物的过程,比如我们要训练狗狗坐下,但是狗狗无法直接听懂我们的指令“sit down”。在训练过程中,我们给狗狗示意,如果它表现得好,我们就给他奖励,如果它做跟sit down完全无关的动作,我们就给它小小的惩罚。这样不断修正狗狗的动作,最终能让它按照我们的指令来行动。实际生活中,增强学习的例子也很多,比如根据用户点击、选择而不断改进的广告系统。
简单总结一下,机器学习按照数据输出标签yn划分的话,包括监督式学习、非监督式学习、半监督式学习和增强学习等。其中,监督式学习应用最为广泛。
三、Learning with Different Protocol f(xn,yn)(根据获取数据的方式不同)
按照不同的协议,机器学习可以分为三种类型:
- Batch Learning
-
Online
-
Active Learning
batch learning是一种常见的类型。batch learning获得的训练数据D是一批的,即一次性拿到整个D,对其进行学习建模,得到我们最终的机器学习模型。batch learning在实际应用中最为广泛。
online是一种在线学习模型,数据是实时更新的,根据数据一个个进来,同步更新我们的算法。比如在线邮件过滤系统,根据一封一封邮件的内容,根据当前算法判断是否为垃圾邮件,再根据用户反馈,及时更新当前算法。这是一个动态的过程。之前我们介绍的PLA和增强学习都可以使用online模型。
active learning是近些年来新出现的一种机器学习类型,即让机器具备主动问问题的能力,例如手写数字识别,机器自己生成一个数字或者对它不确定的手写字主动提问。active learning优势之一是在获取样本label比较困难的时候,可以节约时间和成本,只对一些重要的label提出需求。
简单总结一下,按照不同的协议,机器学习可以分为batch, online, active。这三种学习类型分别可以类比为:填鸭式,老师教学以及主动问问题。
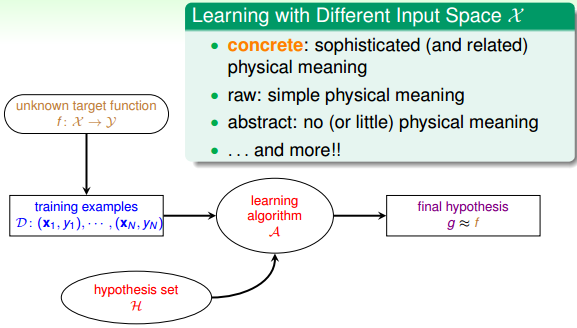
四、Learning with Different Input Space X(根据输入的数据不同划分)
输入X的第一种类型就是concrete features。比如说硬币分类问题中硬币的尺寸、重量等;比如疾病诊断中的病人信息等具体特征。concrete features对机器学习来说最容易理解和使用。
第二种类型是raw features。比如说手写数字识别中每个数字所在图片的mxn维像素值;比如语音信号的频谱等。raw features一般比较抽象,经常需要人或者机器来转换为其对应的concrete features,这个转换的过程就是Feature Transform。
第三种类型是abstract features。比如某购物网站做购买预测时,提供给参赛者的是抽象加密过的资料编号或者ID,这些特征X完全是抽象的,没有实际的物理含义。所以对于机器学习来说是比较困难的,需要对特征进行更多的转换和提取。
简单总结一下,根据输入X类型不同,可以分为concetet, raw, abstract。将一些抽象的特征转换为具体的特征,是机器学习过程中非常重要的一个环节。在《机器学习技法》课程中,我们再详细介绍。
五、总结:
本节课主要介绍了机器学习的类型,包括Out Space、Data Label、Protocol、Input Space四种类型。
