続行前の仕事を家族広州中古住宅のデータの連鎖を分析し続けます。
正規性テスト
()は、3つの主な要因(面積、総平均は)結果は、これらの三つの変数が正規分布していないことを示し、正規分布ad.testのnortestパッケージでテスト、およびQQプロット上に発現していますより直感的に:
家のエリア
ad.test(house$area) #p-value < 2.2e-16 reject normality
qqnorm(house$area)
qqline(house$area, col = 2, lwd=2)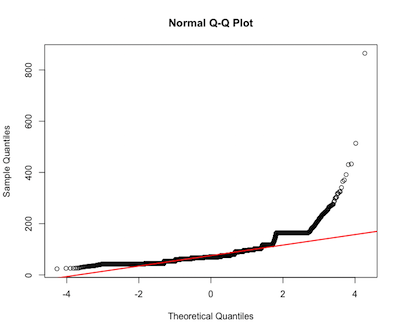
住宅の合計金額
ad.test(house$total_price) #p-value < 2.2e-16 reject normality
qqnorm(house$total_price)
qqline(house$total_price, col = 2, lwd=2)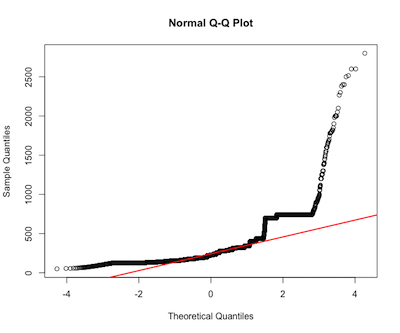
ハウス価格
ad.test(house$unit_price) #p-value < 2.2e-16 reject normality
qqnorm(house$unit_price)
qqline(house$unit_price, col = 2, lwd=2)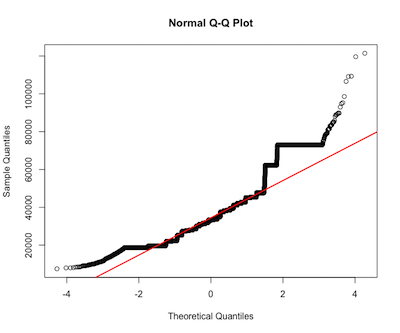
家の面積は、これら三つの変数の合計金額とユニット価格は正規分布していないので、それは、これらの3つの変数のANOVAと線形回帰分析することはできませんので。
クラスター分析
その後、我々は住宅部門分類することが分かります。あなたはバイヤーのために、より正確にターゲット顧客グループの分類を見つけることができるという点で、売り手と仲介のための家は家を知ってもらうより多くの時間を費やして避けることができるので、不適切な高速取引(結局、いつも家Cengceng人々に考える時間を与えない上がるためにこする - )私は、簡単で便利なK-平均アルゴリズムと家の分類を実現していきます。
あなたが数について分析心をクラスタ化するために開始する前に、最後にこれらの家は、いくつかのカテゴリーに分けされなければならない適切なのですか?クラスタリングは小さく、グループ間に大きなギャップになるようにグループ内の視差の原理です。私は唯一の地域と分析し、正方形の異なるグループの場合、グループ内の差から算出したこれら二つの最も重要な変数の単価を選択します。
tot.wssplot <- function(data, nc, seed=1){
tot.wss <- (nrow(data)-1)*sum(apply(data,2,var))
for (i in 2:nc){
set.seed(seed)
tot.wss[i] <- kmeans(data, centers=i, iter.max = 500)$tot.withinss
}
plot1 <- ggplot(data=data.frame(1:nc,tot.wss), aes(x=1:nc, y=tot.wss, group=1)) +
geom_line(color="#007CFF", linetype="solid", size=1.0)+
geom_point(color="#FF6666")+
scale_x_continuous(limits=c(0, 10),breaks = seq(0,10,2))+
scale_y_continuous(limits=c(10000, 45000),breaks = seq(10000, 45000,5000))+
xlab('Number of Cluster')+
ylab('Within groups sum of squares')
}
temp <- data.frame(scale(house[,c("area", "unit_price")]))
plot2 <- tot.wssplot(temp, nc = 10)
print(plot2)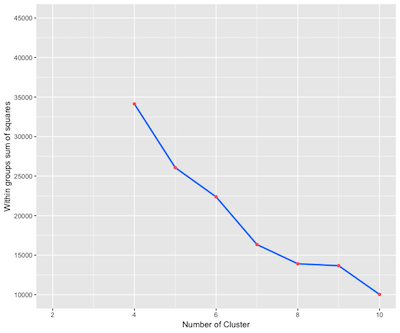
マップ上の結果から、私は結果が悪いわけではない、家は5つのカテゴリーに分割されます選択しました。
set.seed(1)
group <- kmeans(x = temp, centers = 5, iter.max = 500)
print(group)
#K-means clustering with 5 clusters of sizes 7336, 3448, 16948, 19842, 3906
#(between_SS / total_SS = 74.7 %)
解釈結果
新しい変数家$グループとして分類データの結果は、その後、パケットは、各グループの住宅エリア、合計金額および単価のために計算されます。
| グループ | エリア | 合計金額 | 単価 | カウント |
|---|---|---|---|---|
| 1 | 74.86566 | 154.5091 | 20766.57 | 7336 |
| 2 | 86.89919 | 595.8457 | 67492.40 | 3448 |
| 3 | 79.08328 | 310.8258 | 39814.88 | 16948 |
| 4 | 58.04336 | 179.4360 | 31160.86 | 19842 |
| 5 | 142.63028 | 460.6121 | 30534.02 | 3906 |
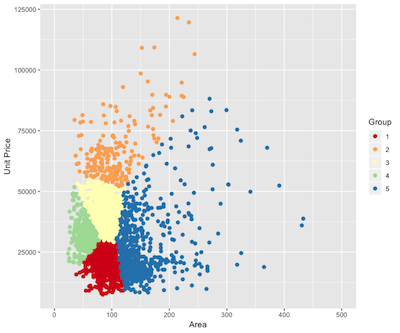
また、家屋の第一グループの地域の焦点はShiqiao、新しいTangnan、橋や他の場所であり、イーストパスに集中家屋の第二のグループ、金、天河公園、その他の場所、北京川、チャンに集中家の第三のグループ香港、ゴールデンなど;姜堰市の道、西、巨石、およびその他のクリフォードに集中家の四群;ように呂ジン、李成とに焦点を当てた家屋の第5群。
上記の情報は、私は広州で中古ハウジングは概ね以下の5つのカテゴリーに分けることができると信じています。
- 車のプレートタイプ:サイズと低価格で、ほとんどの媒体の郊外にあるこのグループの家。豊富なバイヤーに十分なお金のために、また、選択を取得することができます。
- 地域センターの種類(良い場所):主に一等地(トラフィックまたは学位やその他の要因のいずれか)で、広州市に位置して家のこのグループは、平均価格は広州で二手の住宅の平均価格よりもはるかに多く、また稀です家は確認することができます。これは、家の数はあまりないですし。
- ただ、入力する必要があります:主に広州市に位置して家のこのグループ、ではないが良い場所、しかし少なくとも、交通施設などの施設が家の郊外よりも良くなります。大きさ、手頃な価格、適切な住居内の媒体。
- 「オールド・壊れた小さな」タイプは:このグループの住宅面積は小さいですが、その価格は安くはありませんので、この家はのグループとして定義されているため、その焦点は、マルチ姜堰市の道の地域に西旧市街をオフ位置しています「古い小さな休憩」タイプ。その理由は、家は必ずしも古い、小さな、壊れた機能である11を満たしていない、このグループ内の引用符を打つことであるが、データの投機によって家のほとんどは、グループは、古い壊れた一つの小さな機能を満たしています。
- 大きな家:この家より大きなグループは、そうで、大家族の別荘、二重の家を含め、知っていることは容易です。
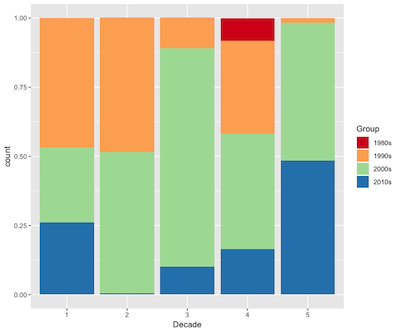
グループ化とグラフィックスが家を建てる家のをレンダリングすることで、あなたは第四グループは、古い家の過半数で決定することができ、家では、基本的な80年代の家グループ4に属しています。
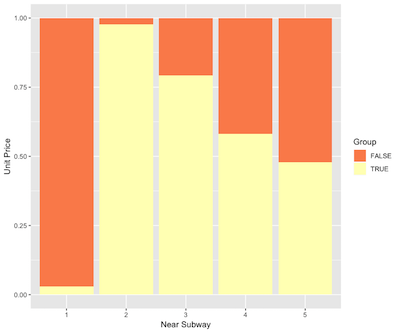
家を描画し、地下鉄グラフィック近くにグループ化された家かどうか、家の周辺を推測するより地下鉄からグループ1ながら期待に沿って、第2のグループはほとんど家の良い場所(よく発達輸送の代わりに)地下鉄の近くにあるかを決定することができ。
最後に、彼は家を買うか、銀行カードの残高を見て、そんなに言った......