最初の部分 を完全ケリ3つの質問:問題を解決するために、再帰的なルーチン
序文
私は多くの学生を信じている場合は、データ構造の完了は、アルゴリズムの問題を磨くようになった直後に私のように、再帰の問題は、常に頭痛である、との答えを見て、これにコードエレガントな再帰的なソリューションの大物数行を見つけました問題。私自身の学習経験の観点から、ちょうど再帰の考え方を理解し始めてすることは非常に困難であり、ましてや自分自身を書きます。
私はいつもそれがそこに存在しなければならないルーチン検査であることから、同様に、ブラシアルゴリズムと試験問題を感じています。質問を磨く、私は再帰の問題を解決するためのソリューションでテンプレートをまとめ、この第二の溶液との考え方は再帰たくさんのかもしれ思いました。
再帰的な問題解決のための三部作
再帰とは何ですか?それは繰り返し自分自身を再帰的に呼び出すプログラムです。
再帰の先頭に私自身はいつもそれが次の層の機能自体を呼び出し、何行われたこと...それは再帰的なソリューションを実現するために感じることが基本的な、非常に複雑であり、何を行うには、この層の機能をもつれに行く、問題を解決するために私たちは、起動することはできません。
私は、私のような多くの初心者が、それは誤解だと思っ、出て行かなければならないと考えています。これは再帰的な手順であるので、各レベルでの機能は同じである、ことを示しており、何度も何度も自分自身を呼び出すので、我々は単に再帰を解決するプロセスに焦点を当てる必要があります。
実際にソフトウェアを描く勉強したことがない何、それは手描きの波の魂である、ハッハッハスプレーしないでください。

上記のように、私たちは、主に以下の3点気にする必要があります。
-
再帰全体で終了条件。
-
どのような再帰を行う必要がありますか?
-
それはどのような値のレベルに戻るには、戻るべきですか?
したがって、我々はリングの問題の再帰的なソリューションを持っています。
-
全体再帰終了条件を探す:再帰はそれが終了する必要がありますか?
-
戻り値を検索:リターン時に与えられるべきであるどのような情報?
-
これは、再帰レベルを実行する必要があります。このレベルの再帰では、どのような作業を完了する必要がありますか?
未来と考えスパイク再帰アルゴリズムの問題のための基礎となるこれらの3つの手順を、理解してください。
しかし、それは非常に空のようだと言って、私たちは、テンプレートのこのセットは、私は3つの質問をダウン信じる方法を確認するために、例として話題に来て、あなたはゆっくりと、このテンプレートを理解することができるようになります。このルーチン再発問題が発生した後、その後ソリューションは、直接秒することができます。
実施例1:バイナリツリーの最大深さ
:シンプルLeetcodeトピックを見てください Leetcode最大深度104バイナリツリー
質問は非常にシンプルな、最大深度バイナリツリーた、そしてまっすぐな三部作のテンプレートを解決する再帰的な問題を設定します。
-
終了条件を探しています。 どのような状況下で、再帰終了?もちろん、木が空で、その後、木の深さは0である、再帰は以上です。
-
戻り値を検索します。 何を返すべき?トピックは、ツリーの最大の深さを求めている、私たちは、それぞれのレベルから情報を取得する必要があり、このレベルでは最大の天然の深さは、現在のツリーに対応しているので、私たちの戻り値は、現在のツリーの最大の深さである必要があり、このステップは、第三と組み合わせることができますステップ実行。
-
このレベルは、再帰的に行われるべきです。 まず、エラーを考える上や前に重点を出すために、再帰的なツリーの後に私たちの目には、このように見える姿を見なければなりません。このとき、3つのノードに:根、root.left、root.right、第二段階に記載、root.left root.rightが記録され、根の左と右の部分木の最大深度。そして、これを行う必要があります再帰レベルは、自然選択が周りにあるサブツリーのルートの大きい方が非常に明確であるが、プラス1の最大深さは、サブツリーのルートのルートで、その後で、この深さに戻りますことができます。

特定のJavaコードは次のとおりです。

{ソリューションクラス
パブリックINT MAXDEPTH(ツリーノードのルート){
//終了条件:再帰的ツリーの端部が空で、現在の深さ0を返す
(ルート== NULL){IF
戻り0;
}
左および右の部分木の//ルート最大深さ
INTは= leftDepth MAXDEPTH(root.left);
INT = rightDepth MAXDEPTH(root.rightは);
//左と右の部分木の最大深度を返す+ +1
Math.max(leftDepth、rightDepth)+を返す1;
}
}
場合は十分に熟練し、あなたはまた、初心者が無知な力を見た後のは、見てみましょう、問題を取得するには、コメントとコードのショー非常に数行としてLeetcodeエリアができます(この質問はLeetcodeの質問を取得するためのコードの私の最初の行です):
クラスのソリューション{
公共のint MAXDEPTH(TreeNodeのルート){
リターンルート== nullの?0:Math.max(MAXDEPTH(root.left)、MAXDEPTH(root.right))+ 1。
}
}
実施例2:リンクされたリスト内のスイッチングノード二十から二
問題を解決するために、バイナリツリーの再帰ルーチンを読んだ後、少し再帰的なルーチンはそれの気持ちを取得しますか?我々はメディア難易度のリストをLeetcode問題を見てみましょう、ルーチンのこの媒質難しさの問題は、実際に把握するために、第2次のとおりです。Leetcode 24二十から二のExchangeノードのリストを
三部作のテンプレートを指示:
-
終了条件を探しています。 どのような状況下で、再帰終了?再帰が聖歌を終了し、時間を交換する必要はありませんでした。リストには、ノードまたはノードだけではないときに、再帰的な性質が終了しました。
-
戻り値を検索します。 私たちは、どのような情報再帰次に高いレベルに戻ることを望みますか?隣接ノードペアごとの私たちの目的は、リストを交換しているので、とても自然に完成された再帰的な交換プロセスに交換することを希望し、そのリストがうまく処理されています。
-
このレベルは、再帰的に行われるべきです。 第二のステップに関連して、図を参照してください!これだけレベルの再帰的なので、私たちの目には、このリストは、実際には、また、3つのノードを検討しているので:頭、head.nextを、リストの処理部を終えました。そして、再帰タスクのこのレベルでは、これら3つのノード、非常に簡単なの最初の二つのノードを交換することです。

Javaコードを接続します。
{ソリューションクラス
のパブリックListNodeのswapPairs(ListNodeヘッド){
//終了条件:リストまたは複数のノードだけでなく、と交換しませんでした。これは、リストが良い処理された戻り
{IF(ヘッド== NULL || head.next == NULL)
;戻りヘッド
}
ヘッド、次に、swapPairs(next.next):// 3つのノードの合計
//次のタスクこのスイッチングノードは、三個の前の二つの内のノードである
。ListNode次に= head.next
head.next = swapPairs(next.next);
next.next =ヘッド;
//第二段階:前へ戻ります現在の交換が完了した後、すなわち、チェーンのハンドル部分は、
Next(次へ)を返します;
}
}
実施例3:バランスの取れた二分木
私は、二つ以上の質問の後、あなたはおそらくすでにこのテンプレートの問題解決のプロセスを理解していることを信じています。
:そして、あなたはそれをLeetcode問題を解決しようとすると、一部を見ていない、それは簡単な難易度(個人的にこの質問は上記培地難しさよりも硬いと感じる)であったLeetcode 110平衡二分木
私はこの質問が本当にテンプレートセットの三部作以下、テンプレートのコレクションの本質だと思います。
-
終了条件を探しています。 再帰はどのような状況下で終了すべきですか?自然は、サブツリーが空である空の木は、自然平衡二分木です。
-
どのような情報が返されます。
なぜ私はこのトピックには、テンプレートの本質の集まりであることを言うのですか?これは、理由は、戻り値のこの質問です。我々は非常に多くの添えものを行うことを知っているために、それが正しい再帰関数を書くことができるようにすることですので、この問題の解決策は、私たちが考える必要があるとき、最後に私たちはどのような値を返すようにしたいですか?
平衡二分木は何ですか?約2サブバイナリツリーが1以下である高さのバランスの取れた二分木。三つの条件満たす必要が平衡二分木であり、ツリーの場合:その左サブツリーが平衡二分木であるが、その右側のサブツリーは、平衡二分木、その左右のサブツリーの高さの差1以下です。言い換えれば、それは左または右サブツリーサブツリーが平衡二分木ではない、またはその左右の部分木の高さの差が1より大きい場合、それはバランスの取れた二分木ではありません。
ルート、左、右:私たちの目には、バイナリツリー風雲3つのノードです。だから我々はそれを何を返すべき?ツリーは平衡二分木のboolean型の現在の値であるので、私は2本のだけの木を左と右の場合は左右の高さの違いを描画することができませんでし平衡二分木は、1よりも大きくないことを知っているかどうかを返しますが、自然に持つことができない場合どうか、このツリーのルートは、平衡二分木です。そして、私が戻るならば、私は2つのツリーの高さがあることを知って、int型の平衡二分木の高さの値ですが、2つのツリーを知ることができないが、平衡二分木ではない、自然ツリーのルートを判断することはできませんこれは、平衡二分木ではありません。
したがって、ここでの情報は、我々は、int型の深さの値の両方が含まれているサブツリーに戻り、サブツリーはブール値を含むかどうかと、平衡二分木の種類であるべきです。次のようにReturnNodeは、単一のクラスを定義できます。
クラスReturnNode { ブールISB。 int型の深さ。 //构造方法 パブリックReturnNode(ブールISB、INT深さ){ this.isB = ISB。 this.depth =深さ; } }
-
このレベルは、再帰的に行われるべきです。 戻り値の後に第2工程を知って、この手順は非常に簡単です。ルート、右から左:現在3つのツリーノードがあります。直接ではなくfalseを返す場合には、まず、左及び右サブツリーサブツリーが平衡二分木であるかどうかを決定します。複数の直接falseを返す場合、2点のツリーの高さの差を決定することは、1以下です。そうでなければサブツリーのルートノードは、平衡二分木であり、それは真を返し、その高さを説明。
特定のJavaコードは次のとおりです。
ソリューション{クラス
//これは私がステップ2を説明した再帰的なルーチンReturnNodeへの参照です:どのような戻り値があると思います
//ツリーBSTはその左右のサブツリーと同等のは、BSTと二つのサブツリーの高さの両方です差が1以上でない
//は、だから私は、戻り値は、現在のツリーは非常にBSTと現在のツリー2の情報であるかどうかを含めるべきだと思い
プライベートクラスReturnNode {
boolean型ISBがあり、
int型の深さ;
公共ReturnNode(int型の深さ、ブールISBがある){
this.isB ISBは=であり;
this.depth =深さ;
}
}
//メイン関数
パブリックブールisBalanced(ツリーノードルート){
isBST(ルート).isBを返す;
}
//再帰ルーチン第三基準:単一の実行手順は、何に記載されています
プロセスの//単一の実行は、以下の本明細書:
//終了するか否か- >終了し、その後、三つの条件が満たさ不均衡であるか否かが判断されない- >戻り値?
パブリックReturnNode isBST(ツリーノードルート){
IF(ルート== NULL){
(trueに、0)新しい新しいReturnNodeを返す;
}
ここで、//不平衡三種類:アンバランス木左右ツリーツリーは差の絶対値よりも大きい、左右アンバランスなツリー1
ReturnNode = isBSTは(root.left)を左;
ReturnNode右= isBST(root.right);
IF(falseにleft.isB偽へ== == || right.isB){
(falseに、0)新しい新しいReturnNodeを返す;
}
IF(数学.ABS(left.depth - right.depth)> 1)。{
falseに、0(新しい新しいReturnNodeを返す);
}
//バランスを上記の三つの条件を満たさない、ツリーの深さは約2サブツリー+1の最大深さ
新しい新しいReturnNodeリターン(Math.max(left.depth、right.depth)+ 1、真です。);
}
}
いくつかは、問題を解決するために、このルーチンを使用することができます
それは合格点の大学入試として、エンジニアリングの大学と学んだ男性は、表現能力が貧弱であるため、ラ・ラ・織りは、多くのことを書いて、私はあなたが日常的に非常によくこれを理解することを願って、一時的にそう書きます。
私は本当にあまりにも多く、このルーチン2番目の質問を使用しても、ブラシの過程で直面するいくつかの問題が一覧表示されます下に木や連結リストは、再帰のために本質的に適しているとして、質問再帰的なリストや木のほとんどは、そう秒かもしれません構造。
私はいつでも追加されます、あなただけのこれらの質問は、彼らがすぐに分離し、正確に再帰的なソリューションを書くことができるかどうかを確認するためにあなたの手を試みる取ることができ、上記の3つの質問を読むことができます。
Leetcode 226フリップバイナリツリー:これはほとんどの質問であるサン備考。当社のエンジニアの90%はあなたが書いたソフトウェア(自作)を使用する」が、あなたは面接することはできません:MacのGoogleはそれをこのパスアルゴリズムの問題をしませんでしたインタビューするOSのダウンロードアーティファクト自作首長作成者は、その後、Googleのインタビュアーを憎みますとき、ホワイトボード上のバイナリフリップに悪すぎるこの質問に、書き込みます。」
Leetcode 83.削除を繰り返し要素のリストを並べ替え
再帰の私の理解と問題解決のアイデアの第二部
あなたは、このルーチンを理解していない場合は、私はもはや少数のトピックで、それを解決しないであろう!
上記に基づき、私は再ソートされますアウトこのルーチン:
- 終了条件を決定します(実際には、初期条件と特殊な状況を考慮することです)
- 行うには、現在のものは(これは、被写体に応じて決定されます)
- 結果を返す(結果は現在の事を終えた後に返さ)
隣接ノードとのリストのペアごとの交換を考えると、交換にリストを返します。
あなたは、単に内部ノード値を変更しますが、実際のノード交換する必要がないことができます。
例:
考えると、あなたは返す必要があります。1->2->3->42->1->4->3
ListNode * swapPairs(ListNode *ヘッド)
1つの問題解決:
- 終了条件と判断しました。最初は空ノードの場合、プロセスは直接自体を返します。最初のケースは、ヘッドノードだけでなく、直接のリターン自体である場合。最初の2例場合は、第2工程を移動する必要があります。再帰的な方法でのみ、のような特別な事情がダウンを検討する必要はありません考慮に入れていることに注意してください!
- 現在、我々が行います。どのように行うには、現在のものを決定するには?現在の仮定は、空のノードまたはノードに続く2つだけのノードは、ソートされていることです。だから我々は、これら2つのノードの交換よりも何もしません。(あるいは理解、子として私たちの問題を解決するには、2つのノード以外のもの:子供は()関数の結果は、それを交換自分自身を呼び出す問題です!)
- (サブ問題)結果を返します。何かが復帰した後に行っていることが現在確認してください。特定のバーコードを示して参照してください
-
{ソリューションクラス パブリック: ListNodeのswapPairs *(* ListNodeヘッド){ IF((ヘッド== NULL)||(頭部>次に== NULL))#終了条件(特殊なケース):空の単一ノードおよびノードが 返さヘッド; ListNode次に* =頭部>次に、#の一般的な 頭部>次= swapPairs(ネクスト>次);.#の部分問題はswapPairs(ネクスト>次)は、2つのノードに時間とサブ問題です反転の問題。 ネクスト>次に=ヘッドと、 次へを返します; }
以下に示されており、コードが反転3つのノードのものになることはない、一緒:(一般的な図を参照して、簡単に)
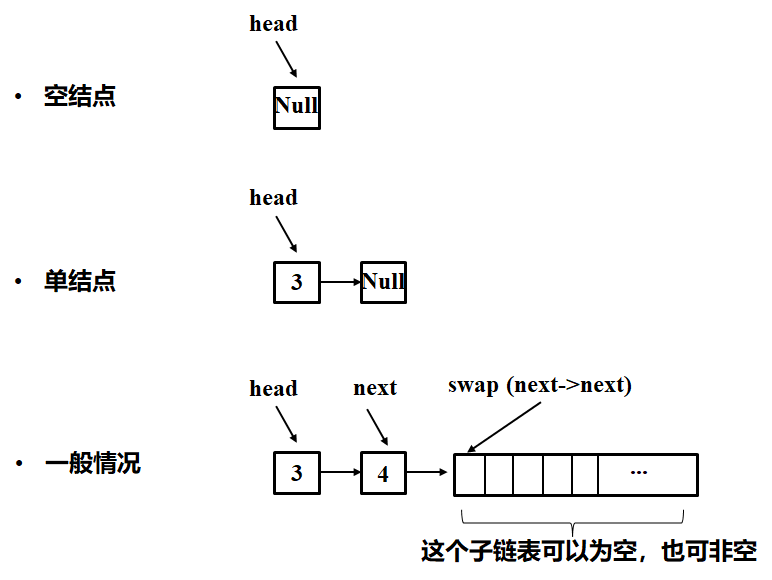
単独リンクリストを逆にします。
例:
输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL
解题2.
- 确定终止条件。空结点或者单节点直接返回就行
- 当前要做的事情(结合子问题考虑)。等于大于两个节点的翻转问题可以转为单节点和其余节点的子问题。具体来说,子问题就是调用函数本身返回的结果。
- 返回结果。结合代码来看。
-
class Solution { public: ListNode* reverseList(ListNode* head) { if ((head==NULL) || (head->next==NULL)) return head; ListNode* next = head->next; ListNode*newhead = reverseList(next); # 子问题是reverse下一个节点 next->next = head; head->next=NULL; return newhead; } };
上图:

例题3 . *38. Count and Say (之前的博文)
例题4. 46. Permutations
给定一个没有重复数字的序列,返回其所有可能的全排列。
示例:
输入: [1,2,3] 输出: [ [1,2,3], [1,3,2], [2,1,3], [2,3,1], [3,1,2], [3,2,1] ]
对于这种排列问题,肯定也可以递归。
具体而言,空列表返回空,单元素返回只含该元素的列表(终止条件)。大于等于两个元素的需要额外考虑(当前要做的事情)。下面部分文字摘自:博客
如果只有 1 个数字 [ 1 ],那么很简单,直接返回 [ [ 1 ] ] 就 OK 了。
如果加了 1 个数字 2, [ 1 2 ] 该怎么办呢?我们只需要在上边的情况里,在 1 的空隙,也就是左边右边插入 2 就够了。变成 [ [ 2 1 ], [ 1 2 ] ]。
如果再加 1 个数字 3,[ 1 2 3 ] 该怎么办呢?同样的,我们只需要将 3 挨个插到上面的位置就行啦。例如对于 [ 2 1 ]而言,将3插到 左边,中间,右边 ,变成 3 2 1,2 3 1,2 1 3。同理,对于1 2 在左边,中间,右边插入 3,变成 3 1 2,1 3 2,1 2 3,所以最后的结果就是 [ [ 3 2 1],[ 2 3 1],[ 2 1 3 ], [ 3 1 2 ],[ 1 3 2 ],[ 1 2 3 ] ]。
所以规律很简单,直接看代码解释就ok。
class Solution:
def permute(self, nums): # 假设输入nums=[1,2,3],那上一级返回的结果应该是[[1,2],[2,1]]
if len(nums) == 0: return []
if len(nums) == 1: return [nums] # 终止条件
results = []
end = len(nums)-1
before = self.permute(nums[0:end]) # 上一级返回的结果[[1,2],[2,1]],下面要做的是将nums[end]=3这个元素挨个插到其中
len_before = len(before) # 上一级的结果
for i in range(len_before): # 在上一级每个列表的基础上
for j in range(len(nums)): # 在该列表的每个位置
temp = before[i].copy() # 提取上一级返回的结果中的每个子列表
temp.insert(j, nums[end]) # 插入到每个空隙里
results.append(temp) # 放到最终结果里
return results
对于 47. Permutations II , 一模一样,除了加一条语句判断是否重复即可。代码:
 View Code
View Code
例题5. 39. Combination Sum (较难理解)
组合总和:给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
说明:
- 所有数字(包括
target)都是正整数。 - 解集不能包含重复的组合。
示例 1:
输入: candidates = [2,3,6,7], target = 7,
所求解集为:
[
[7],
[2,2,3]
]
示例 2:
输入: candidates = [2,3,5], target = 8,
所求解集为:
[
[2,2,2,2],
[2,3,3],
[3,5]
]
此题一个不太好理解的地方:递归子函数是放在了一个循环里。前面的题目没有对递归子函数做循环处理。下面详细分析该题的解法:
变量定义:注意数组里的每个元素允许重复使用,先定义一个放临时解的列表temp=[] 和起点start=0。再定义一个存放最终结果的列表的列表results。
对于candidates=[2,3,6,7],target=8的任务,可以看成是总任务是:combinationDFS(candidates,target=8,start=0,temp,results), 则子任务是分别从不同位置开始,将满足target的列表存到results中。对于该总任务,当前要做的事(子任务)如下:
combinationDFS(candidates,6,start=0,temp,results); temp已经存放了start位置的元素2,candidates=[2,3,6,7],target=8-2=6的子任务。子任务完毕,弹出temp顶端的元素。
combinationDFS(candidates,5,start=1,temp,results); temp已经存放了start位置的元素3,candidates=[3,6,7],target=8-3=5的子任务。子任务完毕,弹出temp顶端的元素。
combinationDFS(candidates,2,start=2,temp,results); temp已经存放了start位置的元素6,candidates=[6,7],target=8-6=2的子任务。子任务完毕,弹出temp顶端的元素。
combinationDFS(candidates,1,start=3,temp,results); temp已经存放了start位置的元素7,candidates=[7],target=8-7=1的子任务。子任务完毕,弹出temp顶端的元素。
所以代码如下:
1 class Solution {
2 public:
3 vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
4 vector<vector<int>> results; # 存放最后结果
5 vector<int> temp;
6 combinationDFS(candidates,target,0,temp,results); # 主任务函数
7 return results;
8 }
9 void combinationDFS(vector<int>&candidates, int target, int pos,vector<int> &temp, vector<vector<int>> &results){
10 if (target<0){ # 题目中数组全为正数,不可能有目标<0,所以如果目标小于0,就返回空。
11 return;
12 }
13 if (target==0){ # 目标为0,两种情况:主任务要求target=0,不存在结果,将temp直接返回;子任务要求target=0,说明找到了一组解
14 results.push_back(temp);
15 return;} # 以上为终止条件,下面为当前要做的事。
16 for (int i=pos;i<candidates.size();i++){ # 对于主任务,要先将当前的元素放到临时解里,再执行后面的子任务
17 temp.push_back(candidates[i]); # 将当前位置的元素放到临时解temp里
18 combinationDFS(candidates,target-candidates[i],i,temp,results); # 执行子任务
19 temp.pop_back(); # 这句话最不好理解。可以这么想,上面那句话找到了一个解后,就将临时解的顶部元素弹出,考虑下一可能解
20 }
21
22 }
23 };
关于子任务循坏,还是要看当前总任务的需求。前面的题目中,当前总任务只与上一次子任务相关。而这道题当前总任务与一堆子任务相关,所以需要循环。
1 class Solution {
2 public:
3 vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
4 vector<vector<int>> results;
5 vector<int> temp;
6 sort(candidates.begin(), candidates.end());
7 combinationDFS(candidates,target,0,temp,results);
8 return results;
9 }
10 void combinationDFS(vector<int>&candidates, int target, int pos,vector<int> &temp, vector<vector<int>> &results){
11 if (target<0){
12 return;
13 }
14 if (target==0){
15 results.push_back(temp);
16 return;}
17のための(I = INT POS; Iに<(candidates.size)を、Iは++){
18 IF(Iある> POS && [-I 1]における[I] ==候補で候補)重複の#結果
19続行;
20は
21 TEMPあります。一back([I]における候補);
22 combinationDFSある(で候補が、[I] ,. 1 + I、TEMP、結果に、候補ターゲット);#+ I. 1、即ち、次の要素からの電流
23(temp.pop_backである);
24 }
25
26}である
27}。