パンダnumpyのアレイは、アレイベースのデータ処理機能は、特に、構成され、ループベースのために使用されません。
最大の違いは、numpyのパンダとパンダが混在データテーブルとデザインを扱うように設計されており、統一numpyの数値配列のデータを処理するために、より適しているです。
パンダは、多くの場合、このような数値計算やscipyのダウンロードnumpyのツール、および分析ライブラリstatsmodels scikit学習、およびデータ可視化matplotlibのなどの他のツールと一緒に使用します。
データ構造のはじめに1頭のパンダ
二つの主要なデータ構造:シリーズ*とデータフレーム
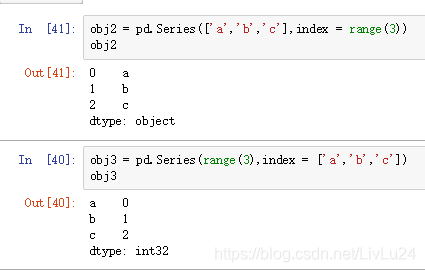
1.1シリーズ
一連のデータのセット(numpyの様々なデータタイプ)とタグ(すなわち、インデックス)組成物に関連するデータの集合で構成され
- シリーズを作成します。


データはPythonの辞書に格納されている場合、また、シリーズの辞書で直接作成することができます。
1.2データフレーム
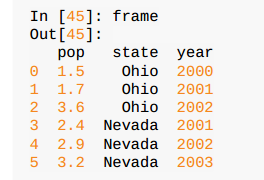
データフレームは、列の順序集合を含む、表形式のデータ構造であり、各列が異なる値型(数値、文字列、ブール値など)とすることができる、それがすることができる
辞書直列として見る(同一を共有しますインデックス)。
作成データフレーム
- 直接辞書など、またはからなるnumpyの配列の長いリストに:

- 列内の着信データが見つからない場合は、それが結果に欠損値を持つことになります。

- 新しい列を作成します。

- 列を削除

1.3インデックスオブジェクト
建物やシリーズDATAFRAME、または任意の他の配列タグの配列を使用することがインデックスに変換されます場合は:

注:別のPythonのセットは、例えば、重複タグのインデックスをパンダ:
索引オブジェクトは変更することができません。
2.基本機能
2.1再インデックス
インデックスを再作成()
インデックスの再作成には、いくつかの補間処理を行うことができます。達成可能な値を充填する前に、メソッドオプションffill / bfillを使用します:


2.2廃棄アイテム指定した軸
ドロップ方法
drop是从行标签删除值,通过传递axis=1或axis='columns'可以删除列的值:![]()
注意:drop方法得到的新对象是改变后的数据,但它不会修改原对象的数据,除非在使用drop方法时加上inplace = True
![]()
2.3 索引、选取和过滤
Series索引(obj[...]) 的工作方式类似于NumPy数组的索引,只不过Series的索引值不只是整数。
选取列:
data['w'] #选择表格中的'w'列,使用类字典属性,返回的是Series类型
data.w #选择表格中的'w'列,使用点属性,返回的是Series类型
data[['w']] #选择表格中的'w'列,返回的是DataFrame属性
选取行:和Numpy有不同
1)当用整数作为索引值时,直接采用 如data[1]会报错,应采用以下方式:
data[0:2] #返回第1行到第2行的所有行,前闭后开,包括前不包括后
data[1:2] #返回第2行,从0计,返回的是单行,通过有前后值的索引形式
2)用loc和iloc进行选取(直接用index值或者整数索引,返回的是Series,采用:形式选取返回的是DataFrame)
data['a':'b'] #利用index值选取行,返回的是前闭后闭的DataFrame
data.iloc[0] #取data的第一行,返回的是Series
data.loc['w'] #用列标签取data的第一行,返回的是Series
data.iloc[-1:] #选取DataFrame最后一行,返回的是DataFrame
data.loc['a', 'w'] #取data的a行w列的单一值
data.loc['a',['w']] #取data的a行w列,返回的是Series
data.loc[: , 'w'] #取data的w列,返回的是DataFrame
data.head() #返回data的前几行数据,默认为前五行,需要前十行则dta.head(10)
data.tail() #返回data的后几行数据,默认为后五行,需要后十行则data.tail(10)
2.4 算术运算和数据对齐
两个DataFrame相加或相减,得出的是原来两个DataFrame的并集,没有重合的地方以NaN显示。
如果不想显示NaN值,可以传入一个fill_value参数:
![]()
除法:1/dif 和dif.rdiv(1)相等

2.5 DataFrame和Series之间的运算
广播:当arr减去arr[0],每一行都会执行这个操作。这就叫做广播(broadcasting)
在行上广播:


在列上广播:
![]()
2.6 函数应用和映射
使用函数获取每列的最大值减去最小值

获取每行的最大值减去最小值
![]()

格式化浮点值字符串,使用applymap

2.7 排序和排名
排序:
可使用sort_index方法,它将返回一个已排序的新对象,对于DataFrame,可以根据任意一个轴排序。
升序:![]()
倒序:
![]()
![]() ,在排序时,任何缺失值默认都会被放到Series的末尾。
,在排序时,任何缺失值默认都会被放到Series的末尾。
根据一个或多个列中的值进行排序,将一个或多个列的名字传递给sort_values的by选项![]()
排名:
rank方法
rank会对重复重现的数值分配一个平均排名
根据值在原数据中出现的顺序给出排名: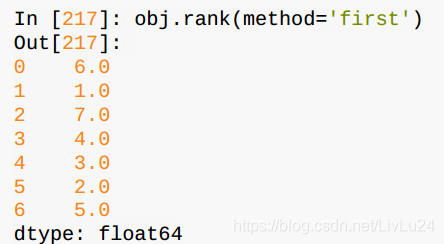 \
\
其他方法如下:

3 汇总和计算描述统计
3.1 汇总统计方法
sum()、mean()函数分别进行求和、求平均运算
sum()返回一个含有列的和的series
sum(axis=1)返回一个含有行的和的series
在进行运算时,NA值会自动被排除,除非整个切片(这里指的是行或列) 都是NA。通过skipna选项可以禁用该功能: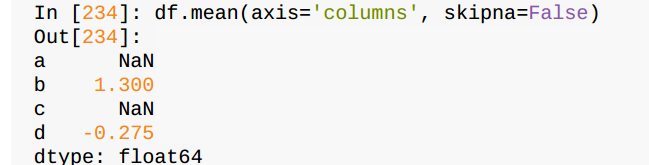

cumsum()累计求和
描述统计方法:describe()
数值型:

非数值型:



3.2 唯一值、值计数以及成员资格
unique()得到Series中的唯一值数组,uniques.sort()返回排序后的数组
value_counts()计算Series中各值出现的频率