ソフトウェア・バージョン:
| ソフトウェア | 版 |
|---|---|
| JDK | jdk1.8.0_191 |
| 飼育係 | 飼育係-3.4.12 |
| Hadoopの | Hadoopの-2.8.5 |
| alluxio | alluxio-1.8.0-Hadoopの-2.8 |
設定JDK:
解凍してソフトリンクを作成します。
$ sudo ln -s /opt/Software/jdk1.8.0_191/ /jdk
設定の環境変数:
$ vi /etc/profile
次の行を追加します。
export JAVA_HOME=/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
環境変数ファイルを更新します。
$ source /etc/profile
キーレス設定:
ローカルまたはSSHプロトコルを組み込んでいないことを確認してください。
$ sudo rpm -qa|grep ssh
あなたが必要としない場合はyumのsshをインストール
.sshディレクトリにユーザーディレクトリでは、あなたがキーレスを設定する必要があるかどうかをチェックします
デフォルトでは、ディレクトリの.sshではありません
何も実行は、SSH鍵を生成しないだろう場合:
$ ssh-keygen -t rsa
連続した4を終え入力します
リモートホストに公開鍵をコピーし、自分自身をターゲット:
$ ssh-copy-id dpnice@cdh1
$ ssh-copy-id dpnice@cdh2
$ ssh-copy-id dpnice@cdh3
インストール設定のZooKeeper:
解凍飼育係:
解凍飼育係のディレクトリを入力したら、フォルダを作成します。
$ mkdir log
$ mkdir data
confディレクトリを入力します。
$ cp zoo_sample.cfg zoo.cfg
$ vi zoo.cfg
次を追加または変更します。
dataDir=/opt/Software/zookeeper-3.4.12/data
dataLogDir=/opt/Software/zookeeper-3.4.12/log
server.1=cdh1:2222:2225
server.2=cdh2:2222:2225
server.3=cdh3:2222:2225
データディレクトリで/opt/Software/zookeeper-3.4.12/dataの次の新しいファイルの名前MYID:
$ vi /opt/Software/zookeeper-3.4.12/data/myid
MYIDにファイルの内容をCDH1追加
1
異なる各ホストに対応するコンテンツは、コンテンツがCDH1 1であり、CDH2コンテンツが2である、CDH3コンテンツは、構成ファイルserver.x Xに対応し、3
設定ファイルは、他のノードに送信されます。
$ scp -r /opt/Software/zookeeper-3.4.12/conf/zoo.cfg dpnice@cdh2:/opt/Software/zookeeper-3.4.12/conf/
$ scp -r /opt/Software/zookeeper-3.4.12/conf/zoo.cfg dpnice@cdh3:/opt/Software/zookeeper-3.4.12/conf/
すべてのノードが起動を実行します。
$ /opt/Software/zookeeper-3.4.12/bin/zkServer.sh start
ノードステータスの身元を確認します。
$ /opt/Software/zookeeper-3.4.12/bin/zkServer.sh status
インストールHaoop構成HA HDFS、HA YARN:
解凍のHadoop:
ディレクトリへのHadoop
$cd /opt/Software/hadoop-2.8.5/
フォルダを作成します:
mkdir /opt/Software/hadoop-2.8.5/tmp
mkdir /opt/Software/hadoop-2.8.5/data
ディレクトリにHadoopの設定ファイル:
$ cd etc/hadoop/
設定ファイルを編集します。
$ Viのコア-site.xmlのは、次の設定を追加します。
<!-- 指定hdfs的nameservice-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://nns</value>
</property>
<!--指定hadoop数据临时存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/Software/hadoop-2.8.5/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>cdh1:2181,cdh2:2181,cdh3:2181</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
<description>默认0,表示不开启垃圾箱功能,大于0时,表示删除的文件在垃圾箱中存留的分钟数,</description>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1440</value>
<description>垃圾回收检查的时间间隔,值应该小于等于 fs.trash.interval。默认0,此时按fs.trash.interval的值大小执行</description>
</property>
$ ViのHDFS-site.xmlの
名前ノード名は「_」アンダースコアをすることはできません
<!-- 指定hdfs的nameservice为nns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>nns</value>
</property>
<!-- nns下面有两个NameNode,分别是 nn0 ,nn1 -->
<property>
<name>dfs.ha.namenodes.nns</name>
<value>nn0,nn1</value>
</property>
<!-- nn0 的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.nns.nn0</name>
<value>cdh1:9000</value>
</property>
<!-- nn0 的http通信地址 -->
<property>
<name>dfs.namenode.http-address.nns.nn0</name>
<value>cdh1:50070</value>
</property>
<!-- nn1 的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.nns.nn1</name>
<value>cdh2:9000</value>
</property>
<!-- nn1 的http通信地址 -->
<property>
<name>dfs.namenode.http-address.nns.nn1</name>
<value>cdh2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://cdh1:8485;cdh2:8485;cdh3:8485/nns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/Software/hadoop-2.8.5/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.nns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/dpnice/.ssh/id_rsa</value>
</property>
<!-- 当前节点为name节点时的元信息存储路径.这个参数设置为多个目录,那么这些目录下都保存着元信息的多个备份 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/Software/hadoop-2.8.5/data/namenode</value>
</property>
<!-- 当前节点为data节点时的元信息存储路径.这个参数设置为多个目录,那么这些目录下都保存着数据信息的多个备份 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/Software/hadoop-2.8.5/data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.web.ugi</name>
<value>dpnice,supergroup</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>supergroup</value>
</property>
$ cpはmapred-site.xml.template mapred-site.xmlに
$ Viのmapred-site.xmlに
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>cdh2:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cdh2:19888</value>
</property>
$ Viの糸-site.xmlに
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序</description>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>是否启用 ResourceManager 高可用,默认 false</description>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
<description>ResourceManager 集群名</description>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>cdh1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>cdh2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>cdh1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>cdh2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>cdh1:2181,cdh2:2181,cdh3:2181</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>是否开启日志聚集功能,默认false。应用执行完成后,Log Aggregation 收集每个 Container 的日志到 HDFS 上</description>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>25200</value>
<description>聚集日志最长保留时间</description>
</property>
追加:hadoop-env.shファイル:
$ vi /opt/Software/hadoop-2.8.5/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/jdk
設定ファイルは、他のノードに送信されます。
$ scp -rp /opt/Software/hadoop-2.8.5/etc/hadoop/core-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/hdfs-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/yarn-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/mapred-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/hadoop-env.sh cdh2:/opt/Software/hadoop-2.8.5/etc/hadoop/
$ scp -rp /opt/Software/hadoop-2.8.5/etc/hadoop/core-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/hdfs-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/yarn-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/mapred-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/hadoop-env.sh cdh3:/opt/Software/hadoop-2.8.5/etc/hadoop/
znode飼育係内のストレージ名前ノードHA-関連データを作成します
$ /opt/Software/hadoop-2.8.5/bin/hdfs zkfc -formatZK
zkCliビューの飼育係を使用します。
$ /opt/Software/zookeeper-3.4.12/bin/zkCli.sh -server 192.168.137.130:2181
Hadoopの-haのカタログ場合zkCliは、以下を参照してください。
$ ls /
すべてJournalNodeプロセスを開始します。
$ /opt/Software/hadoop-2.8.5/sbin/hadoop-daemons.sh start journalnode
フォーマット:
$ /opt/Software/hadoop-2.8.5/bin/hdfs namenode -format
あなたが名前ノードを再フォーマットする必要がある場合は、元の名前ノードの最初のファイルに必要とデータノードはすべて、またはエラーになり、名前ノードデータノードのディレクトリdfs.namenode.name.dir、コア-site.xmlでhadoop.tmp.dirあるを削除、dfs.datanode.data.dirプロパティ設定。各フォーマットなので、デフォルトでは、クラスタのIDを作成することで、名前ノードとデータノードVERSIONファイルは、再フォーマットは、デフォルトではあなたが元のディレクトリを削除しない場合、それは名前ノードをリードする、新しいクラスタIDが生成されます書き込み、 VERSIONファイルは、新しいクラスタのIDで、古いクラスタIDでのデータノードは、エラーが一貫性がなくなります。
ここで開始ノードのActive名前ノード:
$ /opt/Software/hadoop-2.8.5/sbin/hadoop-daemon.sh start namenode
別のノード上のスタンバイ名前ノード同期:
$ /opt/Software/hadoop-2.8.5/bin/hdfs namenode -bootstrapStandby
スタンバイ名前ノードを起動します。
$ /opt/Software/hadoop-2.8.5/sbin/hadoop-daemon.sh start namenode
この時点で、すべてのコンポーネントをオフにして、HDFSを開始することができます
第1のスイッチがアクティブな状態にあります。
$ /opt/Software/hadoop-2.8.5/bin/hdfs haadmin -transitionToActive --forcemanual nn0
手動フェイルオーバーを使用するように強制-forcemanual
閉じる:journalnode
$ /opt/Software/hadoop-2.8.5/sbin/hadoop-daemons.sh stop journalnode
閉じる:名前ノード
$ /opt/Software/hadoop-2.8.5/sbin/hadoop-daemon.sh stop namenode
HDFSを起動します。
$ /opt/Software/hadoop-2.8.5/sbin/start-dfs.sh
[dpnice @ CDH1のHadoop-2.8.5] $ JPS
13985名前ノード
14737 DFSZKFailoverController
14881 JPS
14147データノード
14454 JournalNode
8847 QuorumPeerMain
[dpnice @ CDH2のHadoop-2.8.5] $ JPS
11760名前ノード
12145 JPS
11942 JournalNode
12056 DFSZKFailoverController
11834データノード
8219 QuorumPeerMain
インストール構成Alluxio 1.8
要約:
大きなデータ・エコシステムにおいて、Alluxio計算フレームワークとの間(例えば、Apacheのスパーク、アパッチのMapReduceは、ApacheのHBase、アパッチハイブ、アパッチFLINK)と既存のストレージ・システム(例えば、アマゾンS3、OpenStackのスイフト、GlusterFS、HDFS、MaprFS、セファロ間、NFS、OSS)。Alluxioは、ビッグデータのソフトウェアスタックのための大幅なパフォーマンス向上をもたらします。Alluxioは、Hadoopのと互換性があります。このようなスパークのMapReduceプログラムのような従来のデータ分析アプリケーション、直接Alluxio上で実行するコードを変更しなくてもよいです。
DESIGN:
Alluxioは、アーキテクチャのシングルとマルチワーカーのマスターを使用して設計しました。高レベルの概念的な理解から、Alluxioは、3つの部分、マスター、労働者及びクライアントに分けることができます。Alluxioは一緒に、彼らは部品を維持し、管理するためのシステム管理者は、サーバとマスターワーカーを形成します。クライアント・アプリケーションは通常、このようなスパークまたはMapReduceの、Alluxioまたはコマンド・ライン・ユーザなどの操作。Alluxioユーザーは、一般的にのみAlluxioとクライアントのコンポーネントを相互に作用します。
プロセス:
AlluxioProxyは:プロセスは、RESTインターフェースとAlluxioサーバ間の内部AlluxioのJavaクライアントプロキシ通信を使用しています。
AlluxioMaster:メタデータの管理を担当
AlluxioWorkerを:データの読み取りと書き込みの責任
前提条件:
- ジャワ(JDK 8以降)
- Telnetサービスを開きます。
- HDFSは、すでにインストールされ、実行され
- 飼育係は、すでにインストールされ、実行され
- sudo権限を持つユーザー
インストール:
開梱し、環境変数を設定し、ソフトリンクを作成
ln -s /opt/Software/alluxio-1.8.0-hadoop-2.8/ /alluxio
Alluxioは、構成を開始confディレクトリを入力します。
ソフトリンクを作成します。
$ ln -s /opt/Software/hadoop-2.8.5/etc/hadoop/core-site.xml ./core-site.xml
$ ln -s /opt/Software/hadoop-2.8.5/etc/hadoop/hdfs-site.xml ./hdfs-site.xml
HA HDFSはalluxio-site.properties / Hadoopの/コアsite.xml内などalluxio.underfs.hdfs.configuration = / OPT /ソフトウェア/ Hadoopの-2.8.5を保存/または構成するために使用します。/ opt /ソフトウェア/ hadoop- 2.8.5の/ etc / Hadoopの/ HDFS-site.xmlの
Alluxio-site.properties設定ファイル:
$ cp alluxio-site.properties.template alluxio-site.properties
$ vi alluxio-site.properties
添加或追加以下内容:
alluxio.master.hostname=cdh1
alluxio.underfs.address=hdfs://nns/
alluxio.zookeeper.enabled=true
alluxio.zookeeper.address=cdh1:2181,cdh2:2181,cdh3:2181
alluxio.master.journal.folder=hdfs://nns/alluxio/journal
NNSのdfs.nameservicesがさ
alluxio.master.hostnameのみ構成する必要がマスタノードに配置
設定する必要のみとalluxio.zookeeper.addressワーカーノードはalluxio.zookeeper.enabled
他のノードへの設定情報を送信するには:
$ /opt/Software/alluxio-1.8.0-hadoop-2.8/bin/alluxio copyDir /opt/Software/alluxio-1.8.0-hadoop-2.8/conf/
指定されたホストのすべてのalluxio / confに/労働者へのファイルとフォルダを同期します。あなただけAlluxioマスターノードでアーカイブAlluxioをダウンロードし、解凍した場合は、copyDirワーカーノード・クリップの下Alluxioファイル同期コマンドを使用することができます、また、変更はすべての労働者の会/ alluxio-site.propertiesを同期させるために、このコマンドを使用することができますノード。
HAの使用に注意してください:alluxio.master.hostname =のCDH2は、2つのマスターを持っていることを確認するように変更する必要がCDH2
あなたがあなたの初回起動時にフォーマットする必要があります。
$ /alluxio/bin/alluxio format
フォーマットされたHDFSの存在/ alluxioフォルダ:
[dpnice@cdh3 hadoop]$ /hadoop/bin/hdfs dfs -ls /
Found 4 items
drwxr-xr-x - dpnice supergroup 0 2018-11-29 02:06 /alluxio
sudoはキーレス
Linuxのファイルに現在のユーザー与えられたの/ etc / sudoersファイル、( "alluxio")を次の行を追加限らsudo権限ALL =(ALL)NOPASSWD alluxio: / binに/ *を/ mnt / RAMディスクをマウントし、/ binに/アンマウントを* / MNT / RAMディスク、/ binに / MKDIR * / MNT / RAMディスク、/ binに/ chmodの* / MNT / RAMディスク"alluxio"ユーザアプリケーション須藤許可コマンドを実行することを可能にする特定のパスにマウント/ MNT / RAMディスク、アンマウント、MKDIRそして、chmod(コマンドを想定して/ binに/)、およびパスワードなし。
ローカル環境ことを確認します。
$ /alluxio/bin/alluxio validateEnv local
CDH1では、CDH2はマスターを起動します。
$ /alluxio/bin/alluxio-start.sh master
CDH1、CDH2、CDH3スタート労働者には:
$ sudo /alluxio/bin/alluxio-start.sh worker Mount
あなたが設定ファイルにramfsパスを作成して設定する必要があり、このメソッドを使用して$ /Alluxio/bin/alluxio-start.sh労働者
簡単なプログラムを実行します。
$ /alluxio/bin/alluxio runTests
検証:
[dpnice@cdh3 hadoop]$ /hadoop/bin/hdfs dfs -ls /
Found 4 items
drwxr-xr-x - dpnice supergroup 0 2018-11-29 02:06 /alluxio
drwxr-xr-x - dpnice dpnice 0 2018-11-29 02:28 /default_tests_files
ビューのリーダーノード:
$ /alluxio/bin/alluxio fs leader
[dpnice@cdh3 hadoop]$ /alluxio/bin/alluxio fs leader
cdh2
リーダーがダウンしたり、他のマスターが短い初期化動作の後にサービスを提供しますハングアップすると、表示が完全に初期化できません:
[CDH1 confの@ dpnice] $ / alluxio / binに/ alluxio FSリーダー
CDH1
リーダー・レートで、このページでは、現在サービスを要求されていません。
アクセスリーダーノードのhttp:// CDH2:19999
このスタンバイノードでは使用できません。
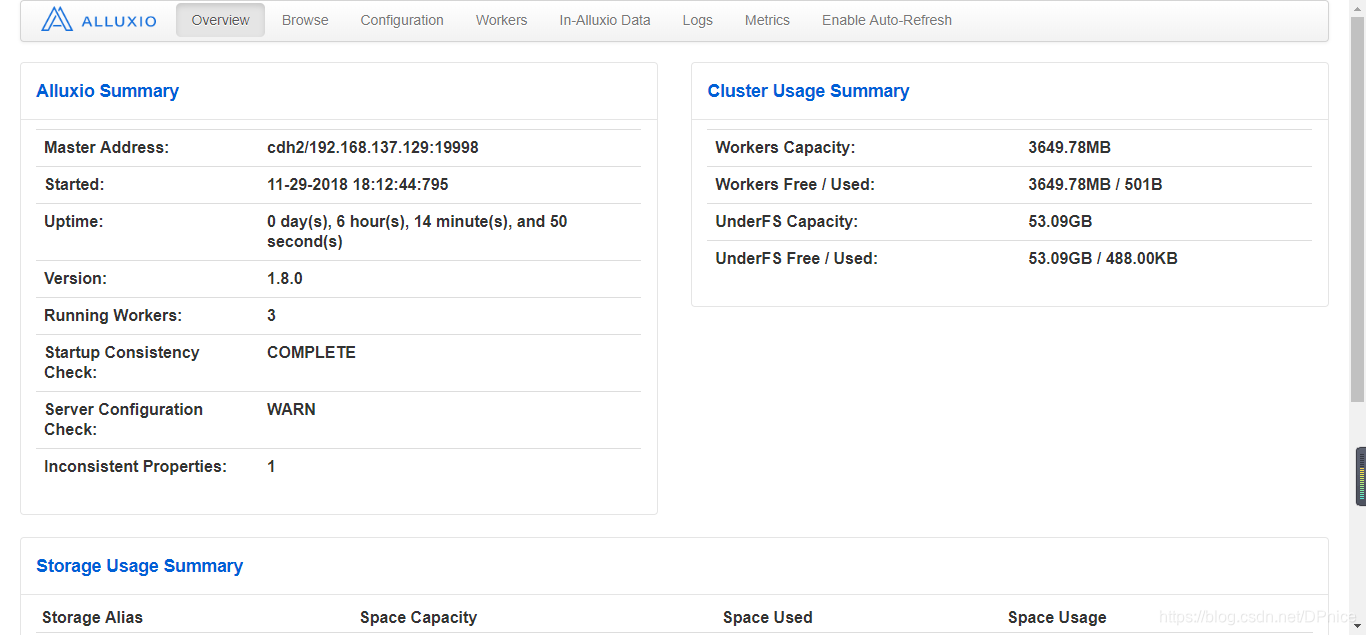
ルートディレクトリにファイルをアップロードalluxio
$ /alluxio/bin/alluxio fs copyFromLocal simple-start-app.sh /
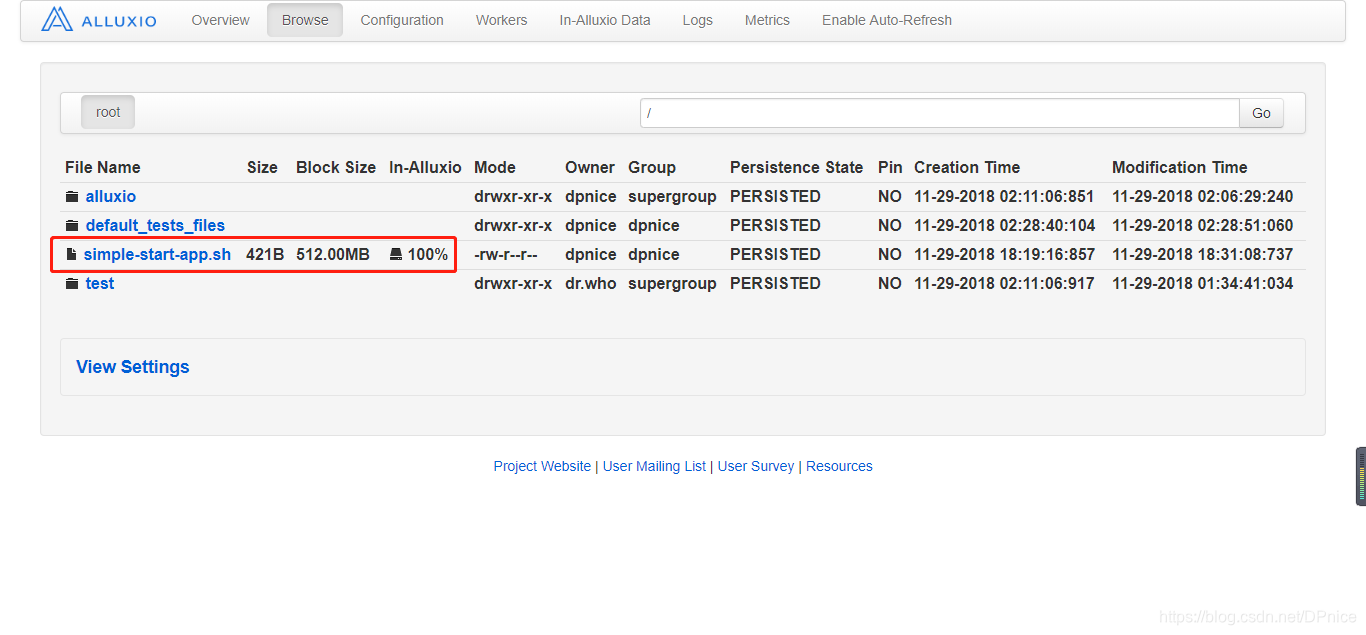
alluxioは、HDFSファイルに永続化
$ /alluxio/bin/alluxio fs persist /simple-start-app.sh
コマンドを閉じます。
$ /alluxio/bin/alluxio-stop.sh master
$ /alluxio/bin/alluxio-stop.sh worker
オペレーティングデモ:
ファイルの単語を作成します。
$ vi word.txt
内容为:
spark hadoop
spark hadoop alluxio dpnice
spark hadoop alluxio
spark hadoop alluxio
HDFSにアップロード:
[dpnice@cdh1 ~]$ /hadoop/bin/hdfs dfs -put ./word.txt /
ビューのファイル:
[dpnice@cdh1 ~]$ /alluxio/bin/alluxio fs ls /
drwxr-xr-x dpnice supergroup 1 PERSISTED 11-29-2018 02:06:29:240 DIR /alluxio
drwxr-xr-x dpnice dpnice 24 PERSISTED 11-29-2018 02:28:51:060 DIR /default_tests_files
drwxr-xr-x dpnice dpnice 0 PERSISTED 11-30-2018 01:14:47:538 DIR /efault_tests_files
drwxr-xr-x dpnice dpnice 0 NOT_PERSISTED 11-30-2018 01:18:21:146 DIR /mnt
-rw-r--r-- dpnice dpnice 421 PERSISTED 11-29-2018 18:31:08:737 100% /simple-start-app.sh
drwxr-xr-x dr.who supergroup 0 PERSISTED 11-29-2018 01:34:41:034 DIR /test
-rw-r--r-- dpnice supergroup 84 PERSISTED 11-30-2018 01:08:06:984 0% /word.txt
HDFS上のword.txtは自動的でalluxioにマップされますが、メモリ内で、メモリに格納されていないわけではありません。
統計はの火花の数をword.txt:
[dpnice@cdh1 ~]$ time /alluxio/bin/alluxio fs cat /word.txt | grep -c spark
4
real 0m11.023s
user 0m3.490s
sys 0m1.136s
再次查看文件word.txt:
[dpnice@cdh1 ~]$ /alluxio/bin/alluxio fs ls /word.txt
-rw-r--r-- dpnice supergroup 84 PERSISTED 11-30-2018 01:08:06:984 100% /word.txt
显示已经全部加载到内存中
再次统计hadoop的数量:
[dpnice@cdh1 ~]$ time /alluxio/bin/alluxio fs cat /word.txt | grep -c hadoop
4
real 0m3.649s
user 0m2.289s
sys 0m0.670s
会看到相比第一次明显快了很多(其实还是慢的因为虚拟机的缘故),因为数据已经存放到了Alluxio。
操作列表:
| 操作 | 语法 | 描述 |
|---|---|---|
| cat | cat “path” | 将Alluxio中的一个文件内容打印在控制台中 |
| checkConsistency | checkConsistency “path” | 检查Alluxio与底层存储系统的元数据一致性 |
| checksum | checksum “path” | 计算一个文件的md5校验码 |
| chgrp | chgrp “group” “path” | 修改Alluxio中的文件或文件夹的所属组 |
| chmod | chmod “permission” “path” | 修改Alluxio中文件或文件夹的访问权限 |
| chown | chown “owner” “path” | 修改Alluxio中文件或文件夹的所有者 |
| copyFromLocal | copyFromLocal “source path” “remote path” | 将“source path”指定的本地文件系统中的文件拷贝到Alluxio中"remote path"指定的路径 如果"remote path"已经存在该命令会失败 |
| copyToLocal | copyToLocal “remote path” “local path” | 将"remote path"指定的Alluxio中的文件复制到本地文件系统中 |
| count | count “path” | 输出"path"中所有名称匹配一个给定前缀的文件及文件夹的总数 |
| cp | cp “src” “dst” | 在Alluxio文件系统中复制一个文件或目录 |
| du | du “path” | 输出一个指定的文件或文件夹的大小 |
| fileInfo | fileInfo “path” | 输出指定的文件的数据块信息 |
| free | free “path” | 将Alluxio中的文件或文件夹移除,如果该文件或文件夹存在于底层存储中,那么仍然可以在那访问 |
| getCapacityBytes | getCapacityBytes | 获取Alluxio文件系统的容量 |
| getfacl | getfacl “path” | |
| getUsedBytes | getUsedBytes | 获取Alluxio文件系统已使用的字节数 |
| help | help “cmd” | 打印给定命令的帮助信息,如果没有给定命令,打印所有支持的命令的帮助信息 |
| leader | leader | 打印当前Alluxio leader master节点主机名 |
| load | load “path” | 将底层文件系统的文件或者目录加载到Alluxio中 |
| loadMetadata | loadMetadata “path” | 将底层文件系统的文件或者目录的元数据加载到Alluxio中 |
| location | location “path” | 输出包含某个文件数据的主机 |
| ls | ls “path” | 列出给定路径下的所有直接文件和目录的信息,例如大小 |
| masterInfo | masterInfo | 打印Alluxio master容错相关的信息,例如leader的地址、所有master的地址列表以及配置的Zookeeper地址 |
| mkdir | mkdir “path1” … “pathn” | 在给定路径下创建文件夹,以及需要的父文件夹,多个路径用空格或者tab分隔,如果其中的任何一个路径已经存在,该命令失败 |
| mount | mount “path” “uri” | 将底层文件系统的"uri"路径挂载到Alluxio命名空间中的"path"路径下,"path"路径事先不能存在并由该命令生成。 没有任何数据或者元数据从底层文件系统加载。当挂载完成后,对该挂载路径下的操作会同时作用于底层文件系统的挂载点。 |
| mv | mv “source” “destination” | 将"source"指定的文件或文件夹移动到"destination"指定的新路径,如果"destination"已经存在该命令失败。 |
| persist | persist “path1” … “pathn” | 将仅存在于Alluxio中的文件或文件夹持久化到底层文件系统中 |
| pin | pin “path” | 将给定文件锁定到内容中以防止剔除。如果是目录,递归作用于其子文件以及里面新创建的文件 |
| report | report “path” | 向master报告一个文件已经丢失 |
| rm | rm “path” | 删除一个文件,如果输入路径是一个目录该命令失败 |
| setfacl | setfacl “newACL” “path” | |
| setTtl | setTtl “path” “time” | 设置一个文件的TTL时间,单位毫秒 |
| stat | stat “path” | 显示文件和目录指定路径的信息 |
| tail | tail “path” | 将指定文件的最后1KB内容输出到控制台 |
| test | test “path” | 测试路径的属性,如果属性正确,返回0,否则返回1 |
| touch | touch “path” | 在指定路径创建一个空文件 |
| unmount | unmount “path” | 卸载挂载在Alluxio中"path"指定路径上的底层文件路径,Alluxio中该挂载点的所有对象都会被删除,但底层文件系统会将其保留。 |
| unpin | unpin “path” | 将一个文件解除锁定从而可以对其剔除,如果是目录则递归作用 |
| unsetTtl | unsetTtl “path” | 删除文件的ttl值 |
ramfs和tmpfs的区别:https://www.cnblogs.com/dosrun/p/4057112.html
http://www.alluxio.org/docs/1.8/cn/deploy/Running-Alluxio-on-a-Cluster.html#設定alluxio
http://www.alluxio.org/docs/1.8/cn/ufs/ HDFS.html#基本的な構成
http://www.alluxio.org/docs/1.8/cn/basic/Command-Line-Interface.html#アクションリスト