説明するためのアプリケーションとアルゴリズムのKMP文字列
書き込みの1.目的
通常、彼らの理解深い印象を容易にするため、研究ノートをまとめて学びます。同時に、助けたいという願望は、この知識の学生がお互いから学ぶことができる学習されます。問題は、まだ私たちに知らせてください場合は、初心者、よろしくお願いします。
2.論理ストレージの文字列
リニアテーブルは、ストレージ構造の長所と短所を議論するために、単純なチェーン・ストレージを使用して順次記憶されている使用可能な文字を格納することができる特別な特殊であり、文字列の文字列を指します。
順次記憶
それがスプライシングの列が必要とするときに固定された空間的配列は、適用することであるため、ストレージアレイが、使用されているの順序、あるいは、アレイが膨張を有することができる場合、この操作は比較的時間がかかり、時にはスペース利用のアレイが低く、かつ空間の一部が無駄になっています。しかし、利点は明白、速い位置決め速度です。
チェーンストア
チェーン店はチェーン・ノードの数に必要とされているどのくらいのスペース、空間に結合されていません。各ノードは唯一の文字を続ければしかし、その後、間違いなく現在複数の文字は、あなたが見つけるために、文字の上に多くの時間を費やす必要がある場合は、スペースの無駄は、ですが、リスト自体が遅い検索速度。
私のポイントは
、すべての後に、文字列操作は、チェーン店に比べて、より頻繁に検索機能あり、店舗を注文速くクエリと引き換えに、小さなスペースを犠牲にするより傾斜しています。
アプリケーションの3文字列 - 暴力を探します
ここではアプリケーションの文字列について話をする:サブストリング検索。これは、非常に精通している必要があり、シナリオの多くはメインストリームで部分文字列を見つけることを期待しているがあります。あなたはまた、我々は、サブストリングを識別し、最も基本的な操作を完了する必要があるなど、すべて置換、があるかどうかを判断する、または交換する場合があり、ストリングの位置を検索したい場合があります。
次の例では、直接に、私たちのアルゴリズムを考えるのが最も可能性が高い2つの入れ子ループ、外側のループ(ⅰ)各文字列のメインキャラクターをステップ実行し、マッチが継続する場合は、最初の文字にマッチする部分文字列は、最初に決定するかどうかを判断しますハンドルが発見されるまで、2つの文字列を横断しました。キャラクターが道に一致しない場合は、私は、最初の場所に一致するように戻って、試合に次の文字の最初の文字を戻します。次のように基本的なプロセスは次のとおりです。
`public static int matchPattern(String origin,String aim) {
char[] origins = origin.toCharArray();
char[] aims = aim.toCharArray();
for(int i = 0; i < origins.length; i++) {
int j = 0,k = i;
for( ; j < aims.length;k++,j++ ) {
if(origins[k] != aims[j]) {
break;
}
}
if(j == aims.length) {
return i - j;
}
}
return -1;
}`この方法では、期待することができるはずですが、この書き込みは問題があるでしょう。質問は次のとおりです。
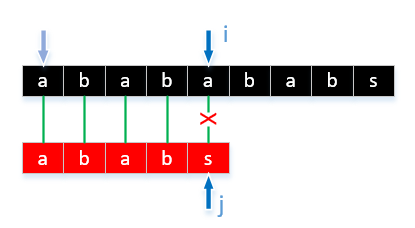
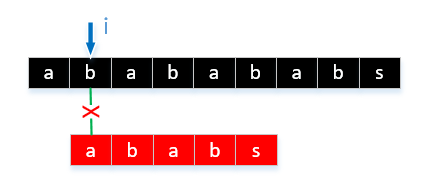
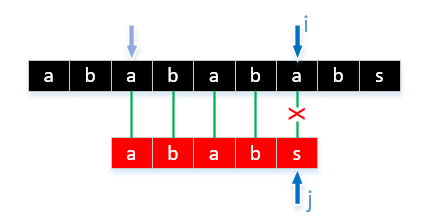
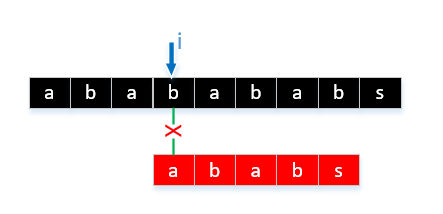
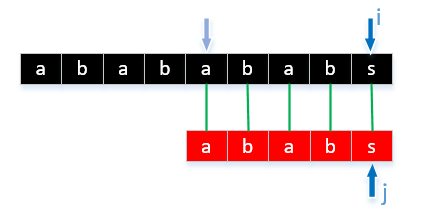
通常のを感じているようだが、あなたは成功した試合は時間についてですいつでも彼らは文字に一致しないため、文字列が非常に長い場合、私たちは、戻って来なければならないことがわかりますよく見てみると、対象の文字の類似性が高い場合は、繰り返されますこのような比較は、私たちが実際にアルゴリズムを最適化するため、比較の既知の結果に基づいて、比較回数を減らすことが重要です。
4. KMPアルゴリズム
このアルゴリズムの背景の起源について簡潔に説明すると、KMPの。
KMPアルゴリズムは、アルゴリズムに一致する改良された文字列であり、DEKnuth、JHMorrisとVRPrattも見出され、人はクヌースを呼び出すよう-モリス-プラット操作(以下KMPアルゴリズム)。
試合後の文字が失敗したので、私自身の言葉は、一致する文字列プロセスに概説されていると、既存の成功の一致に基づいて予測を部分文字列の文字列は、次の位置を移動する必要がある、速い試合不要な一致の数を低減するように、 。そして、移動するサブの位置を計算するためにどのような焦点は、来ましたの?どのように私はこのような動きの後に必ずしもその省略を保証しないことを知ることができます。ここでは、次いで、一緒に分析(または上記の例を使用し、説明の便宜上、我々はメインストリングO(原点)と呼ばれる、サブストリング)は、(AIMと呼ばれます)。
この試合の最初のステップ問題ありません。
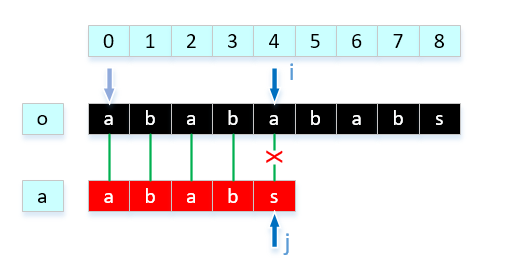
- 第二步这样匹配就出现问题了。 问题是上一步 i 已经移动到 4(数组下标),就因为o[4] != a[4],本次匹配失败,i 需要回溯到 1,j 需要回溯到 0 ,之前的匹配结果信息根本没有派上用场。
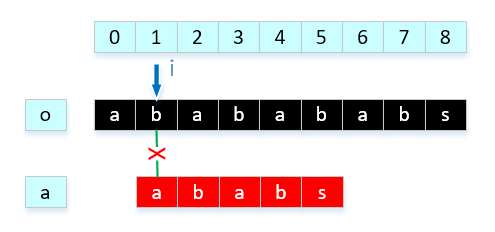
因为根据已经匹配信息,o[0] = a[0],o[1] = a[1],o[2] = a[2],o[3] = a[3],前4位是对应相等的,而且o[2] = a[0],o[3] = a[1],我们完全可以这样移动:
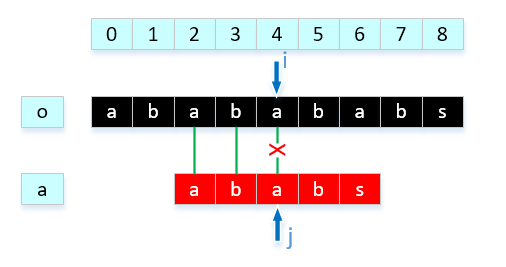
这样的话可以不用比较o[1]与a[0],o[2]与a[0],o[3]与a[1],直接比较o[4]与a[2],省去了不必要的步骤。那么我们继续往下分析,显然o[4] != a[2],因为o[2] = a[0],o[3] = a[1],而且a[0],a[1]不相等,我们可以推断出,o[3] != a[0],所以这一比较步骤也可以省略,直接比较a[4]与a[0]。最终得到结果
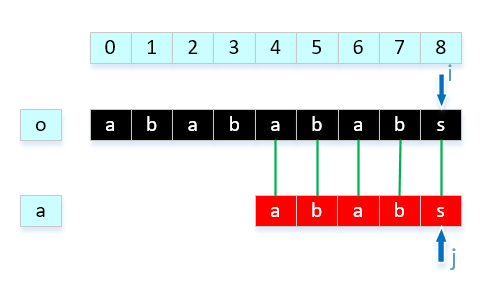
这样的比较方式,是我们可以接受的,根据已知匹配信息省略了许多比较操作,提高效率。 - 那可能有人就要问了,你是怎么知道确切的移动位置,可以让 j 定位到合适的位置,这也就引出了KMP算法的核心的部分,求next[]。next[]有什么作用,next[0],next[1]....next[n]的含义是什么?next是存放对应子串字符冲突后,需要移动 j 的位置。举个例子:next[4] = 2,意思是在 j = 4的位置上子串和主串不匹配,那么主串 i 不需要回溯,直接把 j 回溯到 2,进行比较,也就是把next[]的每个值都求出来,我们就可以轻松准确的更改 j 的位置。了解了next[]的用途,下面我们来学习next[]是如何求出来的。
拿之前的例子作为说明:
o[4]与a[4]冲突,前4位对应相等(首要条件),我们要是想根据前4位相等来推算位置,应该会出现2中情况。一:子串前4位互不相等(a[0],a[1],a[2],a[3]没有一个相同的),根据以上2个条件(o,a对应相等),直接可以推算,a[0]下次应该直接和o[4]比,原因就是a[0]不会和o前4位任意字符相等。 二:子串前4位有字符相等,而且是前后缀对应相等,也是可以推算位置。 插播一下前后缀知识。
例如一串字符 "abadaba"
前缀:{"a","ab","aba","abad","abada","abadab"}
后缀:{"a","ba","aba","daba","adaba","badaba"}
那么前后缀最长匹配相等串"adaba"。
回到刚才的问题,对于串"abab",最长匹配相等串为"ab"。那么我们是可以这样理解的:
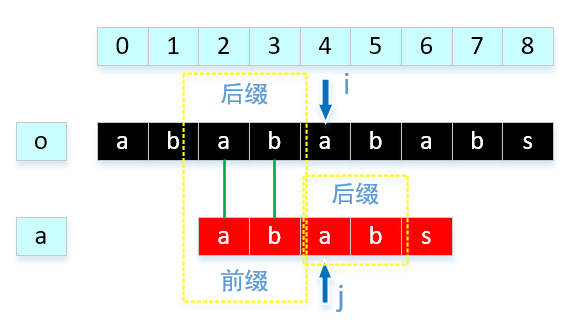
我们分析的是a的前后缀关系,但前提提交是o,a对应位置相等,所以a的前缀就对应了o的后缀,这样我们可以直接移动 j 2的位置。理论基本就这些,我们通过代码来实现一下:public static int[] getNext(String aim,int length) { char[] chars = aim.toCharArray(); int i = 0,j = -1; //next数组长度和aim长度是相等的,因为每一个字符比较出冲突都需要有对应j的位置 int[] next = new int[length]; //第0个位置前是没有前后缀的,所以next[0]我们规定为 -1. next[0] = -1; //第1个位置不匹配,前面只有一个字符,我们只能把j移动到0. next[1] = 0; //注意:这里 i < length -1,而非是 i < length。原因就是 i在循环内部先++,再赋值,如果是 < length会数组越界。 while(i < length-1) { //判断如果对应字符相等,就累加前后缀相同字符长度 if( j == -1 || chars[i] == chars[j] ) { next[++i] = ++j; }else { //注意:就这一句话,困扰我了2天,也许2是比较菜,不过我在文章中,重点解释一下,见文章。 j = next[j]; } } return next; }
重点来了
我们在求解next的时候并不需要o,只需要a就可以得出。我们只需要找出a中前后缀匹配长度,即可。那么我们的方法就是让a和a自己比较。比较的过程如下:
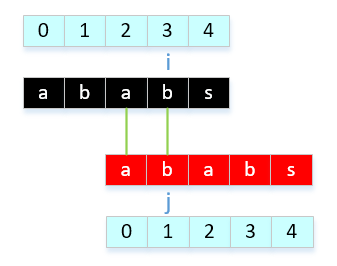
- a[0]与a[1]比较,不相等
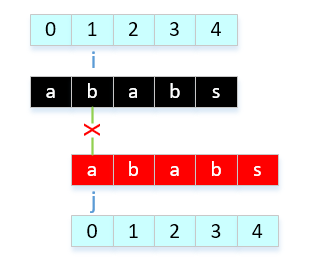
- a[0]与a[2]比较,相等,next[ ++i ] = ++j, next[3] = 1。 意思是什么呢? 可以这样理解,在第3个字符前面的字符中,前后缀最大公共长度为1,也就是有1个公共字符,"a"。那么我知道这个信息有什么用处呢?用处就是当j在3位置上匹配失败,直接改变j为1来继续比较。
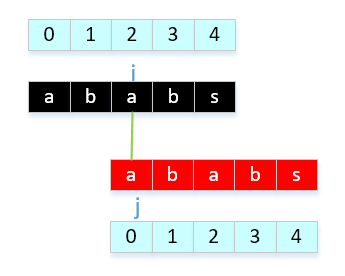
- a[1]与a[3]比较,相等
- a[2]与a[4]比较,不相等
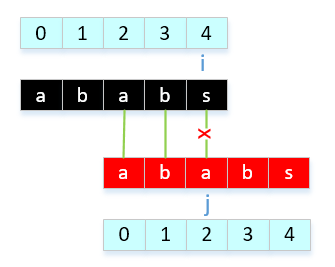
因为只是a[2]与a[4]不等,我们还不能确定具体的公共长度(next[4]的值),接下来我们需要回溯比较,a[4]与a[1],然后a[4]与a[0],如果这样比较多话,就又成了普通的暴力比较 ,我们可以根据已有的结果来推算。下面我来说一下困惑我2天的问题,j = next[ j ]
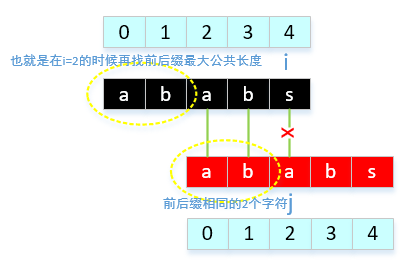
现有我们已经推算的结果:next[ 0 ] = -1, next[ 1 ] = 0, next[ 2 ] = 0, next[ 3 ] = 1,next[ 4 ] = 2。按照算法来说,就是, j = next[2],j = 0。
我之前一直认为 next[j] 的值代表的就是 j 需要移动的下标,所以很是不能理解把next[4]的值有放到next[]中(怎么能把下标放入到next[]中),也就是next[next[4]],next[4]很清晰的说明是当 j = 4 的位置有字符冲突时,把 j 移动到next[4],也就是2,那next[2]又是啥意思? 也就是实在搞不懂next[next[4]]。2天总是想着这个事,也继续在网上查阅资料,看有没有人和我同样有这个疑问。最后在不断的浏览中,感觉有可以说通的答案了,next[j] 也表示 0 ~ j-1 字符中前后缀最大长度,那么当next[4]失配后,next[4] = 2, 我们知道前面的4个字符,最大公共前后缀长度为2,那么next[2]就是在前2个字符当中再寻找最大前后缀公共的长度,因为是自身和自身比较,公共前后缀字符"ab"和 i=2 时前面的字符是一样的,所以在公共前后缀中再找相同前后缀即为在 i = 2之前找,也就是next[2]的值,相信到这里已经对这个疑问得到解答了。
next[ ]的求解我认为是kmp的核心,这个了解完之后,所剩内容不多。引用代码来使用next[ ]完成主串与模式串的查找吧。稍微改动了暴力求解的代码。
public static int kmp(String origin,String aim) {
char[] origins = origin.toCharArray();
char[] aims = aim.toCharArray();
int[] next = getNext(aim,aim.length());
for(int i = 0; i < origins.length; i++) {
int j=0;
for( ; j < aims.length; ) {
if(origins[i] != aims[j]) {
//改动
if(j == 0) {
break;
}
j = next[j];
}else {
i++;
j++;
}
}
if(j == aims.length) {
return i-j;
}
}
return -1;
}5. 聊一下kmp的改进方案:
举例说明,有一种情况,我们的next[ ]有待优化,是这样一种情况。模式串:"aaaaaaab",显然我们的结果是next[]{0,0,1,2,3,4,5,6}。当和我们的主串"aaaaaaacaa....",会导致以下情况:
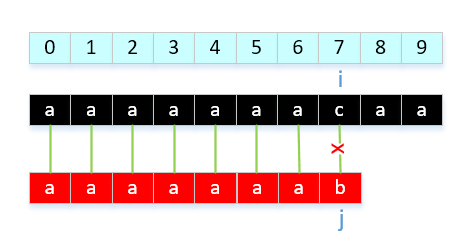

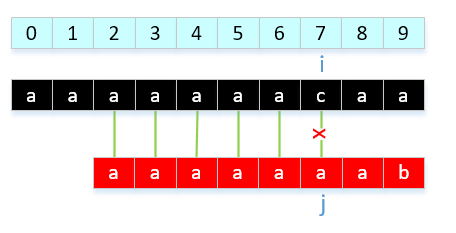
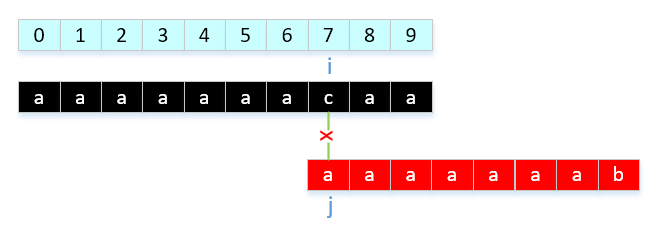
那我们如何改进呢?就是发现模式串中出现连续相等字符就让nextVal[ i ] = nextInt[ j ],解释一下就是: 回溯到上一个字符需要回溯的位置,因为2组前后缀对应想等,那就和上一个做相同处理。
public static int[] getNextVal(String aim,int length) {
char[] chars = aim.toCharArray();
int i = 0,j = -1;
//next数组长度和aim长度是相等的,因为每一个字符比较出冲突都需要有对应j的位置
int[] nextVal = new int[length];
//第0个位置前是没有前后缀的,所以next[0]我们规定为 -1.
nextVal[0] = 0;
//第1个位置不匹配,前面只有一个字符,我们只能把j移动到0.
nextVal[1] = 0;
//注意:这里 i < length -1,而非是 i < length。原因就是 i在循环内部先++,再赋值,如果是 < length会数组越界。
while(i < length-1) {
//判断如果对应字符相等,就累加前后缀相同字符长度
if( j == -1 || chars[i] == chars[j] ) {
i++;
j++;
//相较于getNext()改动的地方
if(chars[i] == chars[j]) { // i == j, i+1 == j+1
nextVal[i] = nextVal[j];
}else {
nextVal[i] = j;
}
}else {
//注意:就这一句话,困扰我了2天,也许是比较菜,不过我在文章中,重点解释一下,见文章。
j = nextVal[j];
}
}
return nextVal;
}参考文档:
《大话数据结构》