まず、検索
1.順次検索
コンフィギュレーション・データは、線形またはシーケンシャルな関係に格納され、シーケンシャルアクセスを見つけることができます

DEF :(のIList、項目)sequential_search POS = 0 ながら posが< (のIList)をlenは: 場合のIList [POS] == :項目 戻りPOS 他: POS = POS + 1 リターン -1
2.バイナリ検索
残りのアイテムの各半分が除外されてもよいように、バイナリ検索を使用して順序付けられた配列表の各項目は、中央から始まり
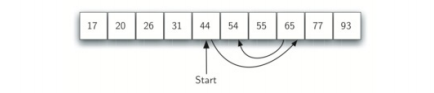
DEF :(のIList、項目)binary_search 最初 = 0 最後 = LEN(IListの) 一方、最初の<= :最後 mid_point =(最初+最後)// 2の 場合のIList [mid_point] == :項目 戻りmid_point 他: 場合アイテム< のIList [mid_point]: 最後 = mid_point - 1 他: 最初 = mid_point + 1 のリターン -1
再帰バージョン
DEF :(のIList、項目)binary_search 場合 LEN(IListの)== 0: 返す -1 他: 中点 = LEN(IListの)// 2の 場合のIList [中点] == 項目: 戻り中点 他: もしアイテム< のIList [中点]: 戻り binary_search(のIList [:中点-1 ]、項目) 他: 戻り binary_search(のIList [中点+ 1]、項目)
3.Hashを探します
ハッシュテーブルに格納されたデータは、各位置のハッシュテーブルは、一般的に溝と呼ばれ、溝は、一般に、順次1から番号付けすることができ、データと溝との間のマッピングと呼ばれるハッシュ関数。荷重係数

いくつかの一般的なハッシュ関数(次に等しいサイズのブロックにデータブロックのハッシュ値を取得するために一緒に追加された)残数(のみテーブルサイズでデータを必要とする)、パケットの合計、中間二乗法(正方形第一データ、及び、データ結果の部分を抽出します)
スロットの限られた数に起因するので、衝突、競合解決が存在するであろう:(空のスロットを見つけるまで、サイクルハッシュテーブルへ)OpenAddressed、リニアプローブ(例えば、空きスロットを見つけるために、:1,2,3,4、 、1,3,5,7,9)、例えば1,4のような一定のスキップ値を用いて第2のプローブ(:5(溝は、例えば、衝突の均一な分布をスキップし、欠点は)凝集しやすい溝を再ハッシング、9、16)、リストが(下記参照)

Pythonの使用することができ、特定の実装辞書
第二に、ソート
1.バブルソート
名前が示すように、泡のよう、フロートのようなまたは重い物のように底に沈むなど、すべての旅、最終的に到達するために1つの極端位置が発注されます。
DEF (NLIST)をbubble_sort: ため pass_num における範囲(LEN(NLIST)-1、0、-1 ): 交流 = Falseの ための I における範囲(pass_num): もし NLIST [I]> NLIST [I + 1 ]: 交流 = 真 NLIST [i]は、NLIST [I +1] = NLIST [I + 1 ]、NLIST [i]は なら ない交流: リターン
2. [ソート
最終極端な位置上のすべての選択肢。交換の回数を減らし、バブルソートを比較しました。
デフselection_sort(NLIST) のため fill_slot における範囲(LEN(NLIST)-1、0、-1 ): position_of_max = 0 のための場所での範囲(1、fill_slot + 1 ): もし NLIST [位置]> NLIST [position_of_max]: position_of_max = 位置 NLIST [fill_slot]、NLIST [position_of_max] = NLIST [position_of_max]、NLIST [fill_slot]
3.挿入ソート
カードドロー、注文リストの数で連続増加を挿入したときにトランプのように。
DEF :(NLIST)insertion_sort ためのインデックスで範囲(1 、LEN(NLIST)): 現在の値 = NLIST [インデックス] 位置 = インデックスを しながら位置> 0 と NLIST [位置-1]> :現在の値 NLIST [位置] NLIST [位置= -1 ] 位置 =位置- 1 NLIST [位置] =現在の値
4.シェルソート
シェルソート元のリストをソート各サブリストに使用挿入がソートされ、挿入ソートを改善するために、より小さなサブリストの複数に分解されます。
DEF (NLIST)shell_sort: sub_list_countを = LEN(NLIST)// 2 ながら sub_list_count> 0: 用 START_POSITION で:範囲(sub_list_count) gap_insertion_sort(NLIST、START_POSITION、sub_list_count) sub_list_count = sub_list_count // 2 デフgap_insertion_sort(NLIST、開始、ギャップ) のための I における範囲(+開始ギャップを、LEN(NLIST)、ギャップ): 現在の値 = NLIST [i]は 、位置 = I ながら位置> =ギャップと NLIST [位置-ギャップ]> 現在の値: NLIST [位置] = NLIST [位置- ギャップ】 位置 =位置- ギャップ NLIST [位置] =現在の値
5.マージソート
再帰的なアルゴリズムは、その後、マージ、その後、サブリストをソートし、半分にリストを維持します。分割統治戦略。
デフmerge_sort(NLIST): もし LEN(NLIST)> 1 : ミッド = LEN(NLIST)// 2 left_half = NLIST [:中間] right_half = NLIST [ミッド:] merge_sort(left_half) merge_sort(right_half) I、J、K = 0、0、0 ながら私がlen(left_half)< そして J < LEN(right_half): もし left_half [I] < right_half [J]: NLIST [K] = left_half [I] I + = 1 さもなければ: NLIST [K] = right_half [J] J + = 1 K + = 1 ながら、 iが< lenの(left_half): NLIST [K] = left_half [I] I + = 1 K + = 1 一方 J < LEN(right_half): NLIST [K] = right_half [J] J + = 1 K + = 1
6.クイックソート
二つの部分の割合は、ピボットの各決定された位置がトリップ値をソートしながら大型シリーズの比が小さくなるが、その後基準として、ピボット値として値を選択します。
DEF (NLIST)quick_sort: quick_sort_helperを(0、NLIST、LEN(NLIST) - 1 ) DEF quick_sort_helper(NLIST、最初、最後): もし最初の< 最後: split_point = パーティション(NLIST、最初、最後) quick_sort_helper(NLIST、第一、 split_point - 1 ) quick_sort_helper(NLIST、split_point + 1 、最後の) デフパーティション(NLIST、最初、最後): pivot_value = NLIST [第] left_mark =第一+ 1 right_mark = 最後 一方TRUE: しばらくleft_mark <= right_mark と NLIST [left_mark] <= pivot_value: left_mark = left_mark + 1 しばらく right_mark> = left_mark と NLIST [right_mark]> = pivot_value: right_mark = right_mark - 1 であれば right_mark < left_mark: 破る 他: NLIST [left_mark]を、 NLIST [right_mark] = NLIST [right_mark]、NLIST [left_mark] NLIST [最初]、NLIST [right_mark] = NLIST [right_mark]、NLIST [第] 戻り right_mark
最後に: