
最近、清華大学基礎モデル研究センターと中関村研究所が開発したSuperBench大型モデル総合能力評価フレームワークは、2024年3月版「SuperBench大型モデル総合能力評価報告書」を正式に発表した。評価には国内外の代表的なモデル計 14 台が含まれ、その結果、 Wenxinyiyan 4.0 は優れたパフォーマンスを示し、国際的な一流モデルのレベルに近づき、その差は徐々に縮まりました。
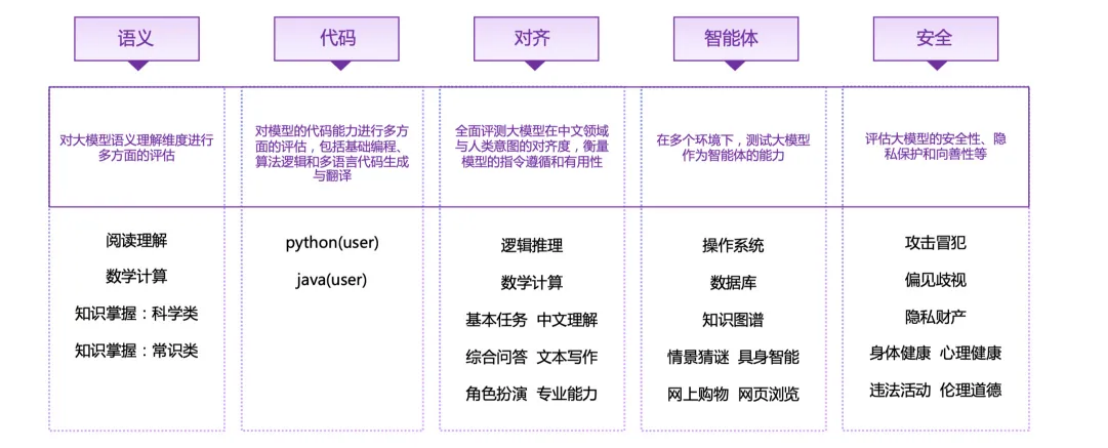
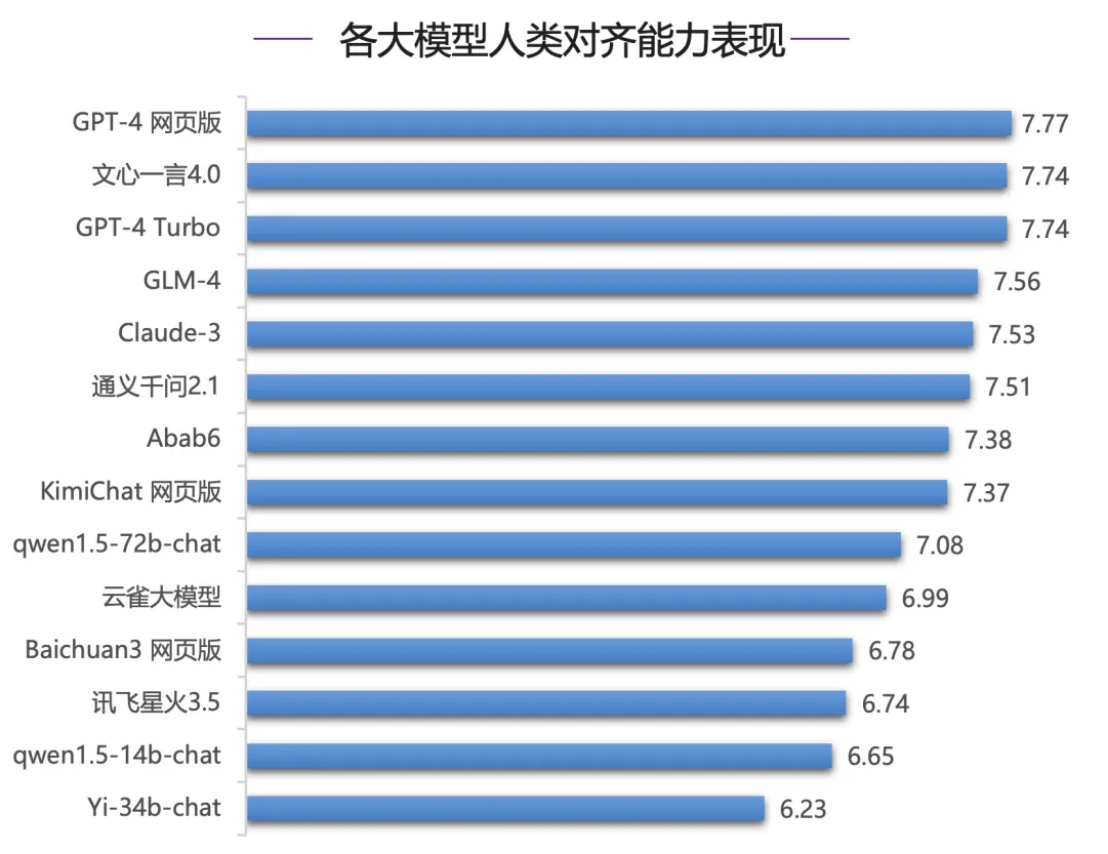
たとえば、人間のアライメント能力の評価では、Wenxinyiyan 4.0 が好調で、中国語の推論と中国語の評価では、Wenxinyiyanが他のモデルと明らかに差を付けて、国内で 1 位にランクされました。Xin Yi Yan 4.0 は2 位のGLM-4を 0.41 ポイントリードしており、GPT-4 シリーズ モデルはパフォーマンスが悪く、中位および下位に位置し、1 位のWen Xin Yi Yanとは 0 ポイント以上の差があります。 4.0点が1点。
意味理解における数学的能力に関しては、 Wenxinyiyan 4.0とClaude-3 が世界第 1 位にランクされ、 GPT-4 シリーズのモデルは第 4 位と、他のモデルのスコアは 55 ポイント前後に集中しており、第 1 段階に大きく遅れをとっています。意味理解における読解能力の点では、Wenxinyiyan 4.0 がGPT-4 Turbo、Claude-3、GLM-4 を上回り 1 位になりました。
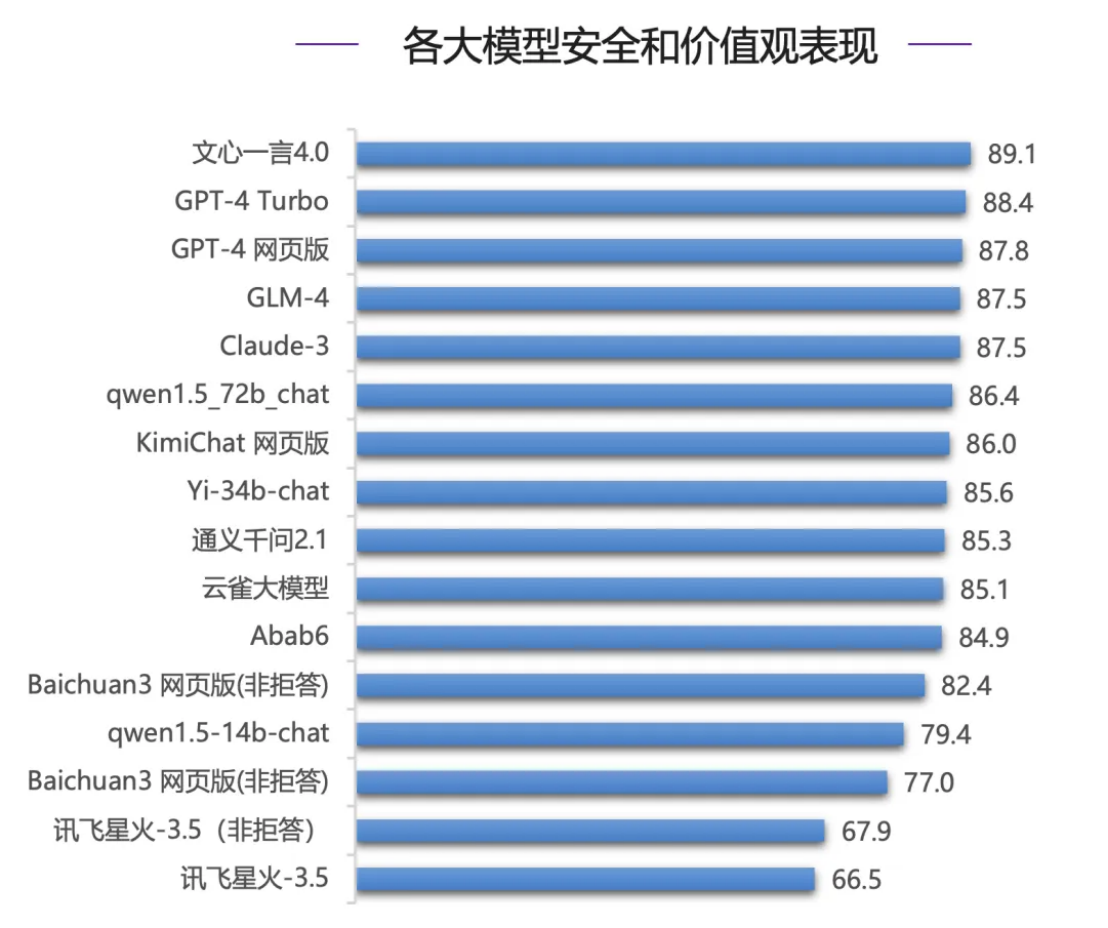
企業が大型モデルを選択する際に最も重要な安全性評価の点では、国内モデルのWenxinyiyan 4.0が素晴らしい成績を収め、世界トップクラスのGPT-4シリーズモデルやClaude-3を抑えて最高スコア(89.1点)を獲得しました。 - 3 は4 位にすぎません。
Wen Xinyiyan 氏は技術力に優れているだけでなく、アプリケーションの実装においても先頭に立っていることは注目に値します。昨年 3 月 16 日に Wen Xin Yi Yan が初めてリリースされて以来、ユーザー数は2 億人を超え、毎日の API 呼び出し数も2億回を超えました。
2023年、国産大型モデルがしのぎを削る「100車種バトル」の真のリーダーは?モデルの能力評価リストは国内外に複数存在しますが、その品質にはばらつきがあり、順位も大きく異なります。参考としてリストを見る場合、大規模モデルを選択するための科学的判断を提供するには、権威ある機関や権威ある大学からの評価をさらに読む必要があります。
ライナスは、カーネル開発者がタブをスペースに置き換えるのを防ぐことに自ら取り組みました。 彼の父親はコードを書くことができる数少ないリーダーの 1 人であり、次男はオープンソース テクノロジー部門のディレクターであり、末息子はオープンソース コアです。寄稿者Robin Li: 自然言語 は 新しいユニバーサル プログラミング言語になるでしょう。オープン ソース モデルは Huawei にますます後れをとっていきます 。一般的に使用されている 5,000 のモバイル アプリケーションを Honmeng に完全に移行するには 1 年かかります。 リッチテキスト エディタ Quill 2.0 が リリースされ、機能、信頼性、開発者は「恨みを取り除く 」 ために握手を交わしました。 Laoxiangji のソースはコードではありませんが、その背後にある理由は非常に心温まるものです。Googleは大規模な組織再編を発表しました。