
著者: ブルース
背景
本日共有されたケースは、Dewu 技術チームによる MSE-ZooKeeper アプリケーションのベスト プラクティスに基づいています。オリジナルのDewu ZooKeeper SLA は 99.99% | Dewu Technology にすることもできます。
ZooKeeper (ZK) は、2007 年に誕生した分散アプリケーション連携サービスです。ただし、歴史的に特別な理由があり、多くのビジネス シナリオでは依然としてそれに依存する必要があります。たとえば、Kafka、タスクのスケジューリングなど。特に Flink の混在展開と ETCD の分離の場合、ビジネス側は絶対的な安定性を必要とし、自作の ZooKeeper を使用しないことを強く推奨しました。安定性を考慮して、Alibaba の MSE-ZK が使用されます。 2022 年 9 月の使用以来、Dewu 技術チームは安定性の問題に遭遇しておらず、SLA の信頼性は実際に 99.99% に達しています。
2023 年に、一部の企業が自社構築の ZooKeeper (ZK) クラスターを使用しましたが、ZK では使用中にいくつかの変動が発生し、その後 Dewu SRE がいくつかの自社構築クラスターを引き継ぎ、安定性の強化を数回実施しました。引き継ぎプロセス中に、ZooKeeper が一定期間実行されるとメモリ使用量が増加し続け、メモリ不足 (OOM) 問題が容易に発生する可能性があることが判明しました。 Dewu 技術チームはこの現象に非常に興味を持っていたため、この問題を解決するための探査プロセスに参加しました。
探索と分析
方向を決める
問題のトラブルシューティングを行ったとき、幸運なことに、クラスター内の 2 つのノードがエッジ状態の OOM になっていたことがわかりました。

障害シーンでは、通常、成功した終了点までに 50% しか残っていません。過去の経験によると、メモリがハイ側にあります。ヒープではないか、ヒープ内に問題があります。フレームグラフやjstatからヒープ内の問題であることが確認できます。

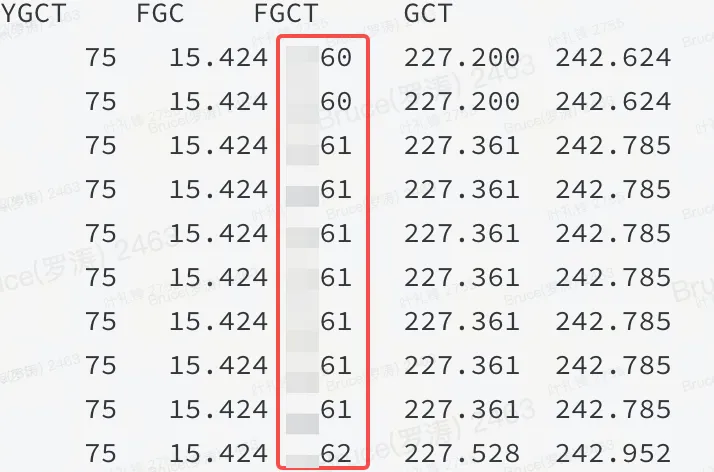
図に示すように、これは、JVM ヒープ内の特定のリソースが大量のメモリを占有しており、FGC がそれを解放できないことを意味します。
メモリ分析
JVM ヒープ内のメモリ使用量の分布を調査するために、Dewu 技術チームはすぐに JVM ヒープ ダンプを作成しました。分析の結果、JVM メモリは childWatch と dataWatch によって大きく占有されていることがわかりました。
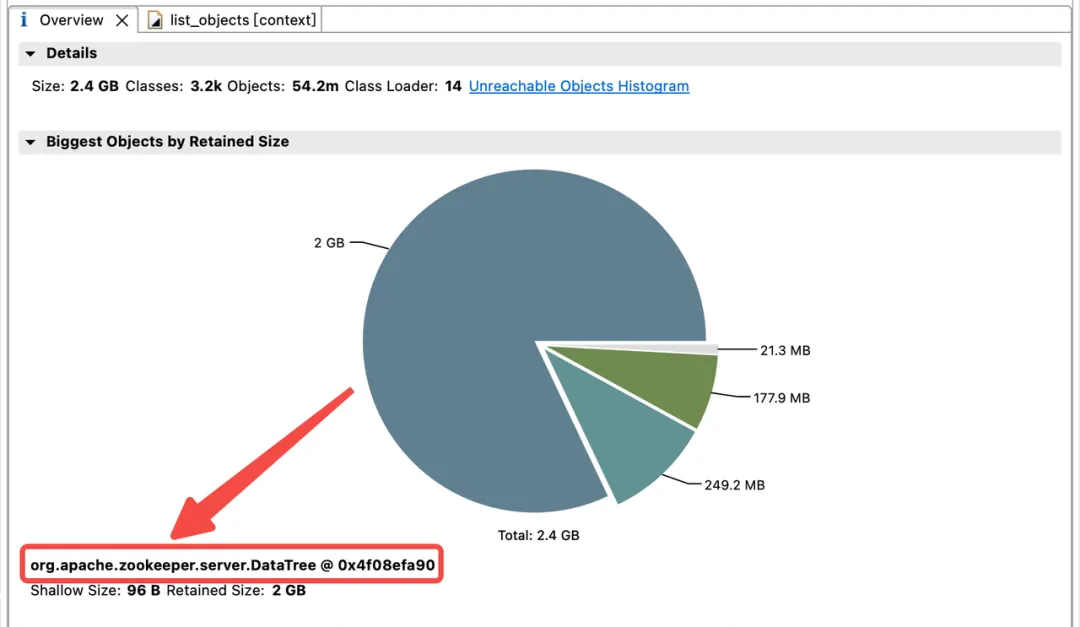
dataWatches: znode ノード データの変更を追跡します。
childWatches: znode ノード構造 (ツリー) の変更を追跡します。
childWatch と dataWatch は WatcherManager から生成されます。
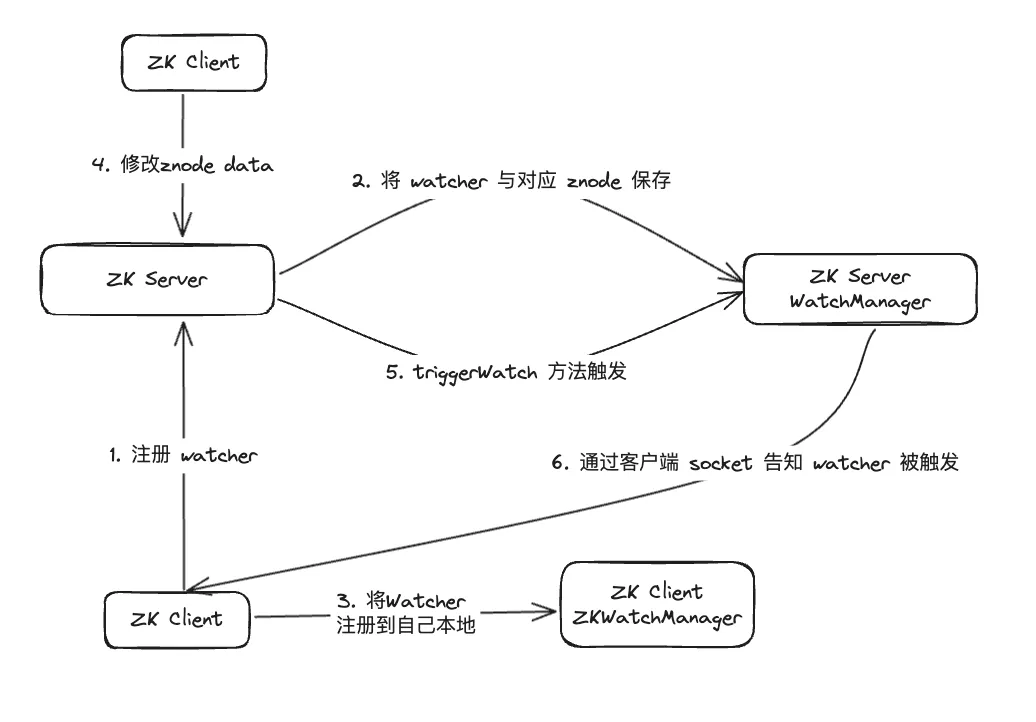
データ調査の結果、WatcherManager が主に Watcher の管理を担当していることが判明しました。 ZooKeeper (ZK) クライアントは、まず Watcher を ZooKeeper サーバーに登録し、次に ZooKeeper サーバーは WatcherManager を使用してすべての Watcher を管理します。 Znode のデータが変更されると、WatchManager は対応する Watcher をトリガーし、Znode にサブスクライブされている ZooKeeper クライアントのソケットと通信します。その後、クライアントのウォッチ マネージャーが関連するウォッチャー コールバックをトリガーして、対応する処理ロジックを実行し、データのパブリッシュ/サブスクライブ プロセス全体を完了します。
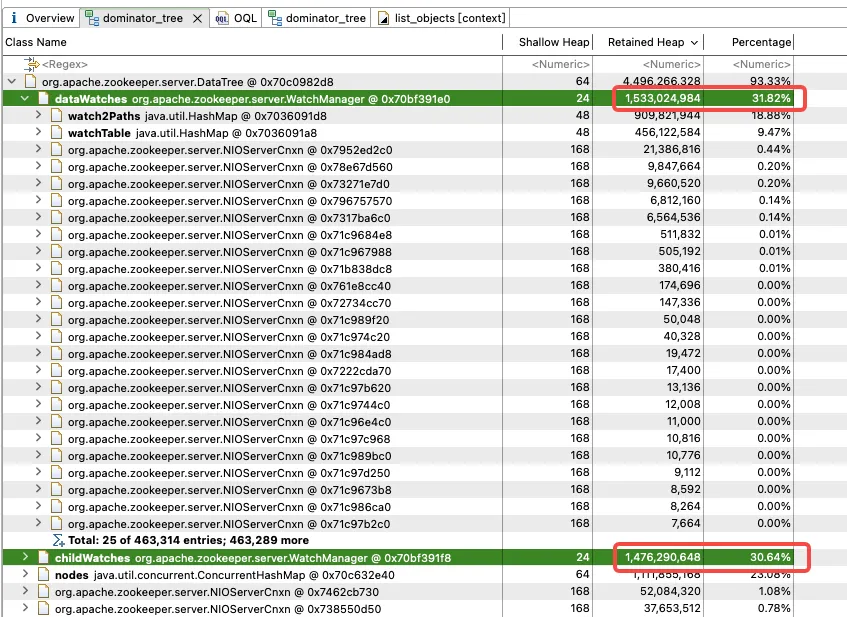
WatchManager をさらに分析すると、メンバー変数 Watch2Path および WatchTables のメモリ率が (18.88+9.47)/31.82 = 90% と高いことがわかります。
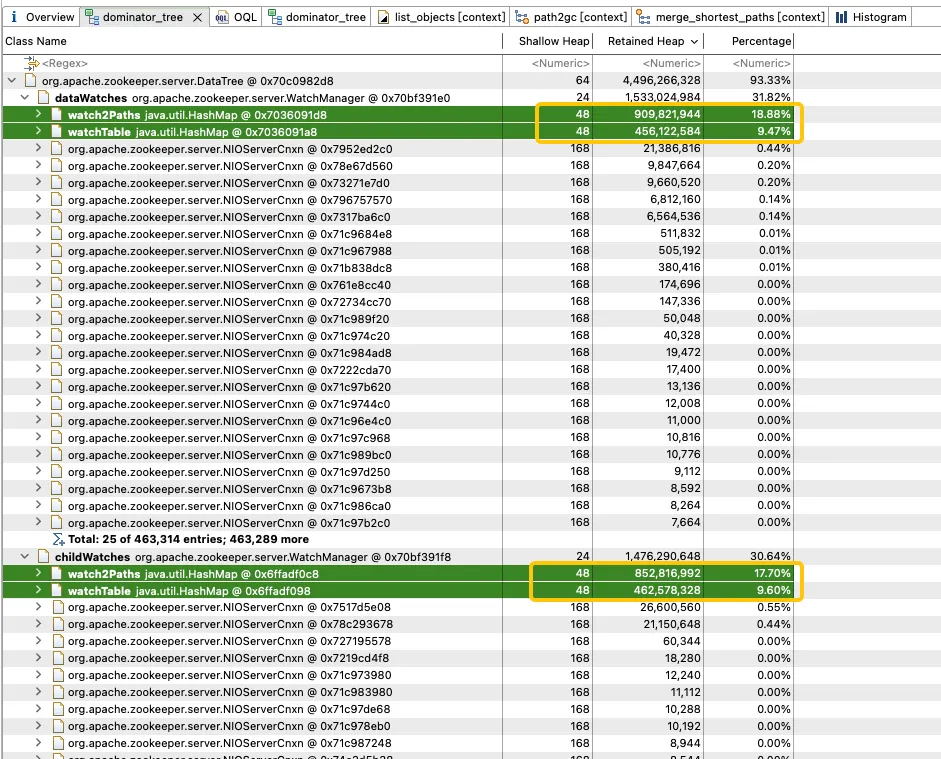
WatchTables と Watch2Path は、ストレージ構造図に示すように、ZNode と Watcher の間の正確なマッピング関係を保存します。
WatchTables [前方参照テーブル]
HashMap<ZNode、HashSet<Watcher>>
シナリオ: ZNode が変更されると、ZNode にサブスクライブしている Watcher が通知を受け取ります。
ロジック: この ZNode を使用して、WatchTable を通じて対応するすべての Watcher リストを検索し、通知を 1 つずつ送信します。
Watch2Paths [逆引きテーブル]
HashMap<ウォッチャー、ハッシュセット>
シナリオ: 特定の Watcher がサブスクライブしている ZNode をカウントします。
ロジック: この Watcher を使用して、Watch2Paths を通じて対応するすべての ZNode リストを検索します。
Watcher は本質的に NIOServerCnxn であり、接続セッションとして理解できます。
多数の ZNode と Watcher があり、クライアントが多数の ZNode をサブスクライブしている場合は、完全にサブスクライブすることもできます。これら 2 つのハッシュ テーブルに記録された関係は指数関数的に増加し、最終的には膨大な量に達するでしょう。
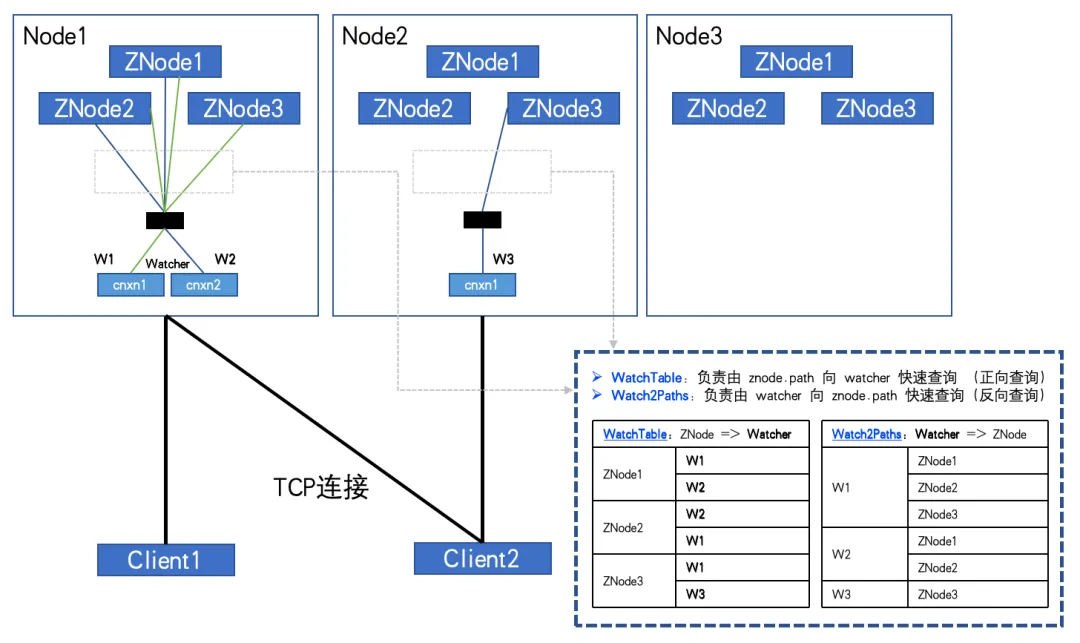
完全にサブスクライブされている場合、図に示すように:
ZNode数:3、Watcher数:2の場合、WatchTableとWatch2Pathはそれぞれ6つのリレーションシップを持つことになります。
ZNode の数: 4、Watcher の数: 3 の場合、WatchTable と Watch2Path にはそれぞれ 12 の関係があります。
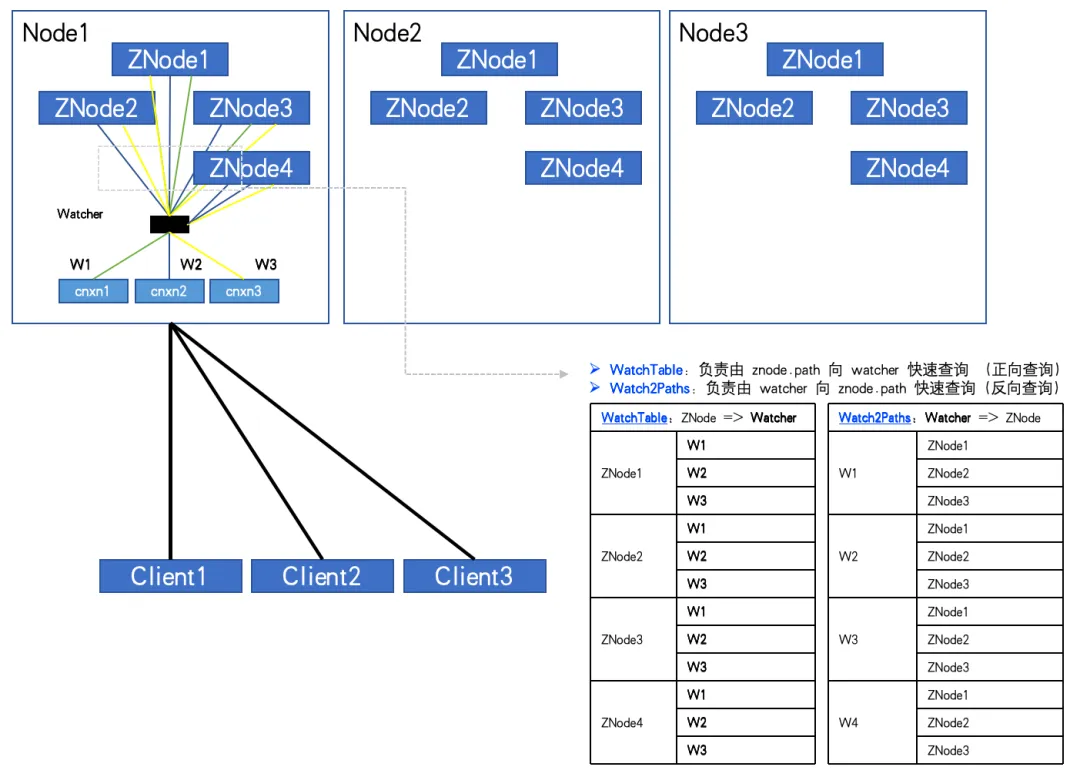
監視により異常なZK-Nodeが発見されました。 ZNode の数は約 20W、Watcher の数は 5,000 です。 Watcher と ZNode 間の関係の数は 1 億に達しました。
各リレーションシップを保存するために 1 つの HashMap&Node (32Byte) が必要な場合、リレーションシップ テーブルが 2 つあるため、それを 2 倍にします。次に、この「シェル」だけで 2 10000^2 32/1024^3 = 5.9GB の無効なメモリ オーバーヘッドが必要になります。
思いがけない発見
上記の分析から、クライアントがすべての ZNode に完全にサブスクライブすることを回避する必要があることがわかります。ただし、実際には、多くのビジネス コードには、ZTree のルート ノードから開始してすべての ZNode を走査し、それらを完全にサブスクライブするようなロジックが含まれています。
一部の取引先を説得して改善を促すことは可能かもしれないが、すべての取引先の利用を制限することを強制することはできない。したがって、この問題の解決策は監視と予防にあります。ただし、残念ながら ZK 自体はそのような機能をサポートしていないため、ZK のソース コードを変更する必要があります。
ソース コードの追跡と分析を通じて、問題の根本が WatchManager にあることが判明し、このクラスの論理的な詳細が注意深く調査されました。詳しく理解したところ、このコードの品質は新卒者によって書かれたものと思われ、スレッドやロックの不適切な使用が多かったことがわかりました。 Git の記録を調べたところ、この問題は 2007 年にまで遡ることがわかりました。しかし、興味深いのは、この時期に WatchManagerOptimized (2018) が登場し、ZK コミュニティの情報を検索したところ、[ZOOKEEPER-1177] が発見されたということです。時計はメモリ使用量の問題を引き起こしましたが、2018 年に最終的に解決策を提供しました。このWatchManagerOptimizedがあるからこそ、 ZK コミュニティはすでに最適化しているようです。
興味深いことに、ZK はデフォルトではこのクラスを有効にしません。最新の 3.9.X バージョンでも、WatchManager は依然としてデフォルトで使用されます。おそらくZKはあまりにも古いので、人々は徐々にZKに注目しなくなりました。 Alibaba の同僚に尋ねたところ、MSE-ZK でも WatchManagerOptimized が有効になっていることが確認され、Dewu 技術チームの焦点が正しい方向に向いていることがさらに確認されました。
探索を最適化する
ロックの最適化
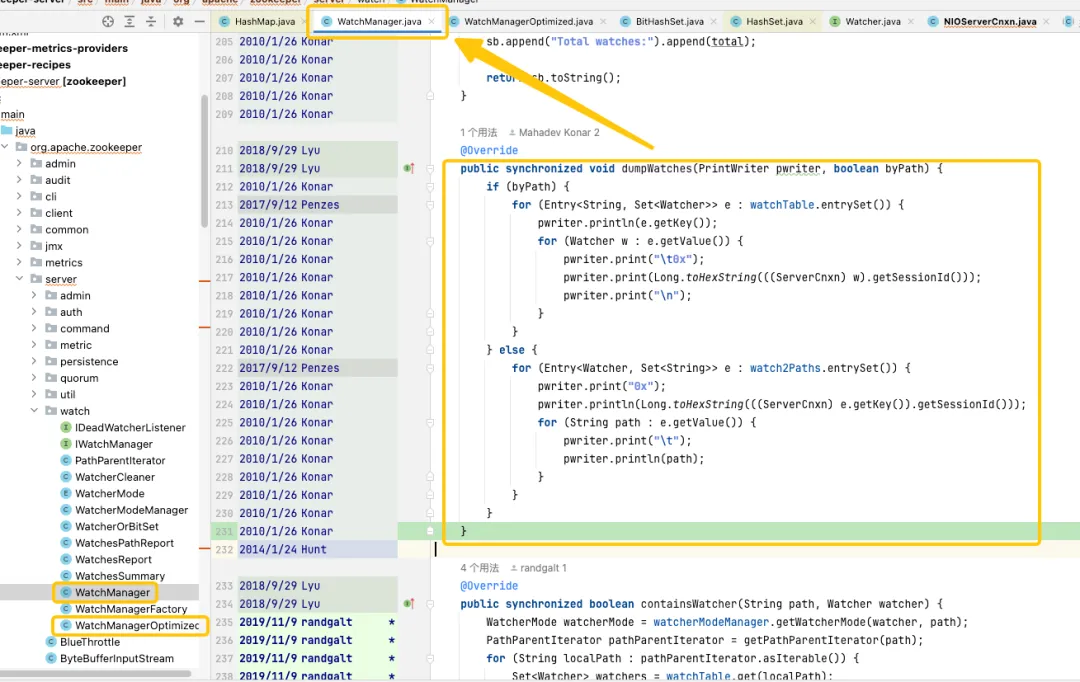
デフォルトのバージョンでは、使用される HashSet はスレッドセーフではありません。このバージョンでは、addWatch、removeWatcher、triggerWatch などの関連する操作メソッドはすべて、メソッドに同期された重いロックを追加することによって実装されます。最適化されたバージョンでは、より洗練された方法でロック メカニズムを使用するために、ConcurrentHashMap と ReadWriteLock の組み合わせが使用されます。このようにして、Watch の追加および Watch のトリガーのプロセス中に、より効率的な操作を実現できます。
ストレージの最適化
これが焦点です。 WatchManager の分析から、WatchTable と Watch2Path を使用した場合のストレージ効率は高くないことがわかります。 ZNode に多くのサブスクリプション関係がある場合、追加で大量の無効なメモリが消費されます。
驚いたことに、WatchManagerOptimized はここで「ブラック テクノロジー」 -> ビットマップを使用します。
リレーショナル ストレージは、次元削減の最適化を実現するためにビットマップを使用して大幅に圧縮されます。
Java BitSet の主な機能:
- スペース効率: BitSet はビット配列を使用してデータを保存するため、標準のブール配列よりも必要なスペースが少なくなります。
- 処理が速い: AND、OR、XOR、反転などのビット演算は、多くの場合、対応するブール論理演算よりも高速です。
- 動的拡張: BitSet のサイズは、より多くのビットに対応するために、必要に応じて動的に拡張できます。
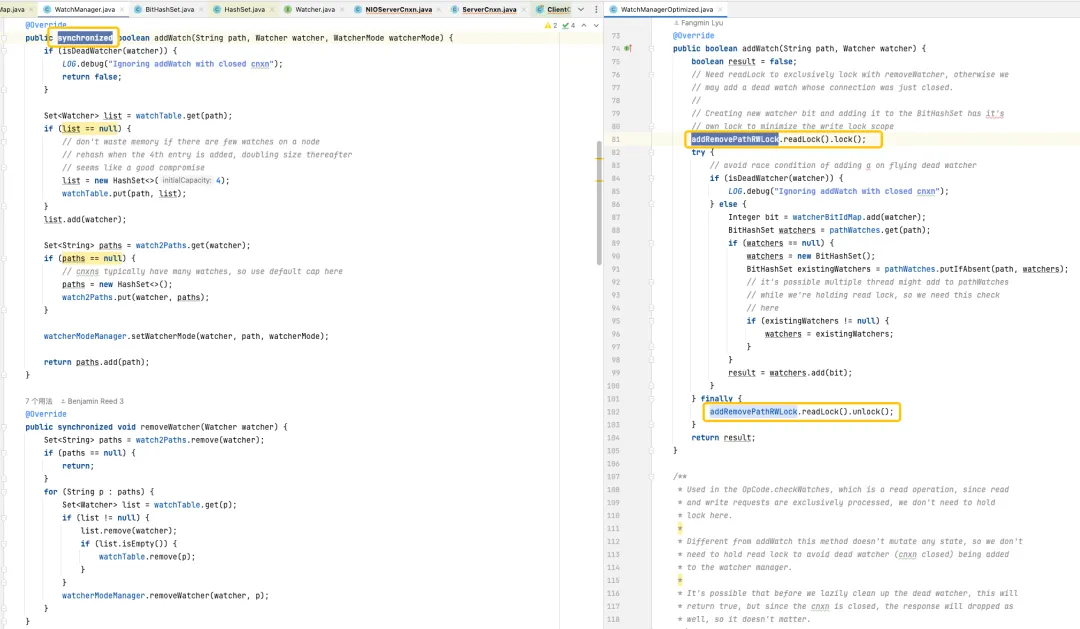
BitSet は、long[] ワードを使用してデータを格納します。long 型は8 バイトを占め、64 ビットです。配列内の各要素は 64 個のデータを保存できます。配列内のデータの保存順序は、左から右、下位から上位になります。
たとえば、下図の BitSet のワード容量は 4 です。下位から上位までの Words[0] はデータ 0 ~ 63 が存在するかどうかを示し、下位から上位までの Words[1] はデータ 64 ~ 127 が存在するかどうかを示します。の上。このうち、words[1] = 8 であり、対応する 2 進数のビット 8 は 1 であり、この時点で BitSet にデータ {67} が格納されていることを示します。
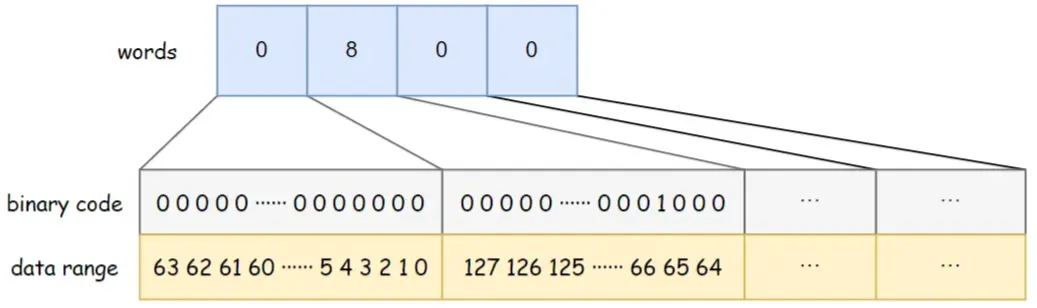
WatchManagerOptimized は BitMap を使用してすべてのウォッチャーを保存します。このように、1Wウォッチャーがいても。ビットマップのメモリ消費量はわずか 8Byte 1W/64/1024= 1.2KBです。 HashSetに置き換えると、少なくとも32Byte 10000/1024=305KBが必要となり、ストレージ効率が300倍近く異なります。
WatchManager.java:
private final Map<String, Set<Watcher>> watchTable = new HashMap<>();
private final Map<Watcher, Set<String>> watch2Paths = new HashMap<>();
WatchManagerOptimized.java:
private final ConcurrentHashMap<String, BitHashSet> pathWatches = new ConcurrentHashMap<String, BitHashSet>();
private final BitMap<Watcher> watcherBitIdMap = new BitMap<Watcher>();
ZNode から Watcher へのマッピング ストレージは Map<string, set> から ConcurrentHashMap<string, BitHashSet > に変更されます。つまり、Set は保存されなくなりましたが、ビットマップ インデックス値を保存するためにビットマップが使用されます。
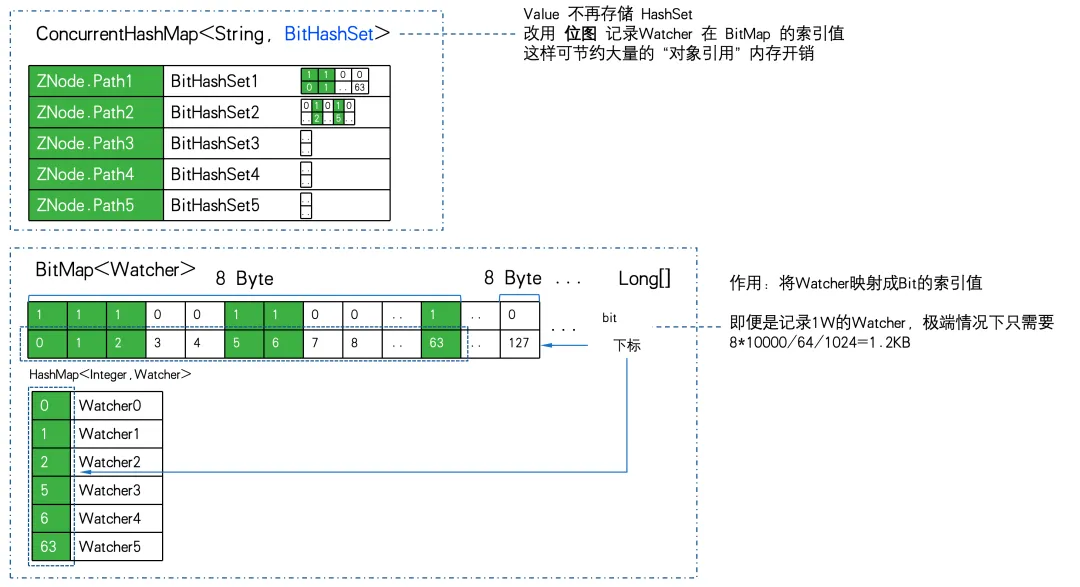
1W ZNode、1W Watcher を使用し、完全なサブスクリプション (すべての Watcher がすべての ZNode にサブスクライブ) の極端な点に進み、ストレージ効率化 PK を実行します。

11.7MB PK 5.9GBのメモリストレージ効率の差は516 倍であることがわかります 。
ロジックの最適化
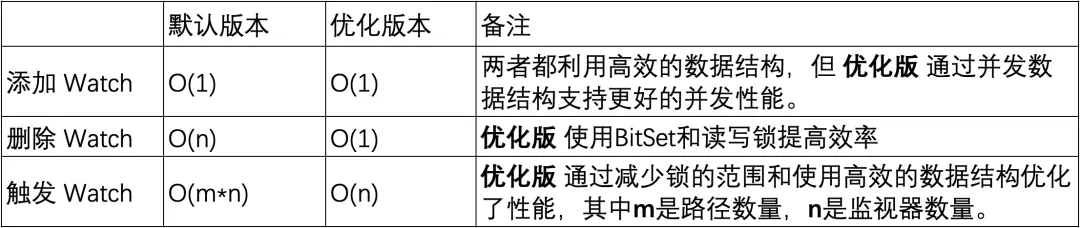
モニターの追加: どちらのバージョンも一定時間内に操作を完了できますが、最適化されたバージョンでは ConcurrentHashMapを使用することで同時実行パフォーマンスが向上します。
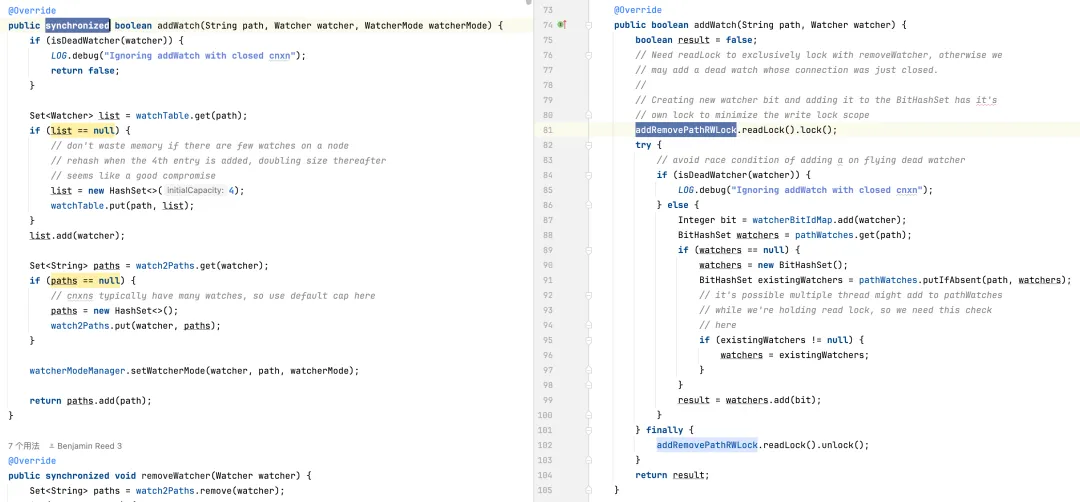
モニターの削除: デフォルト バージョンでは、モニターを検索して削除するためにモニター コレクション全体を走査する必要があり、その結果、時間計算量が O(n) になります。最適化されたバージョン では、 BitSet と ConcurrentHashMapを使用して、ほとんどの場合、O(1) 内のモニターを迅速に見つけて削除します。
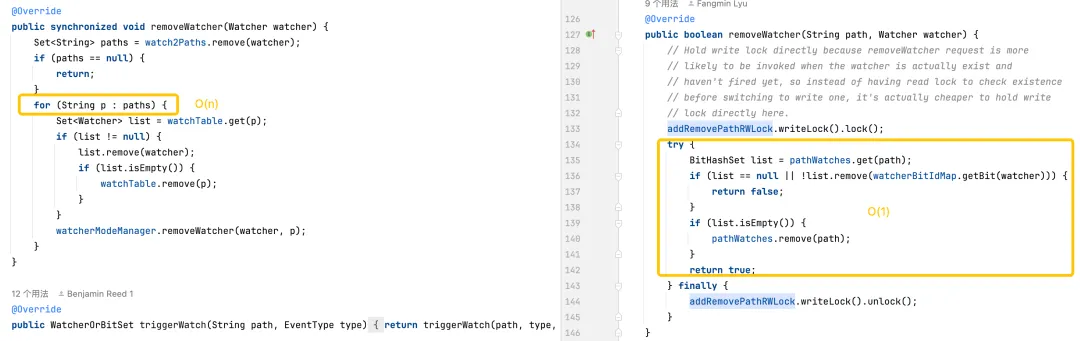
モニターのトリガー: デフォルトのバージョンは、すべてのパス上のすべてのモニターに対する操作が必要なため、より複雑です。最適化されたバージョンでは、より効率的なデータ構造とロックの使用量の削減を通じて、トリガー モニターのパフォーマンスが最適化されます。
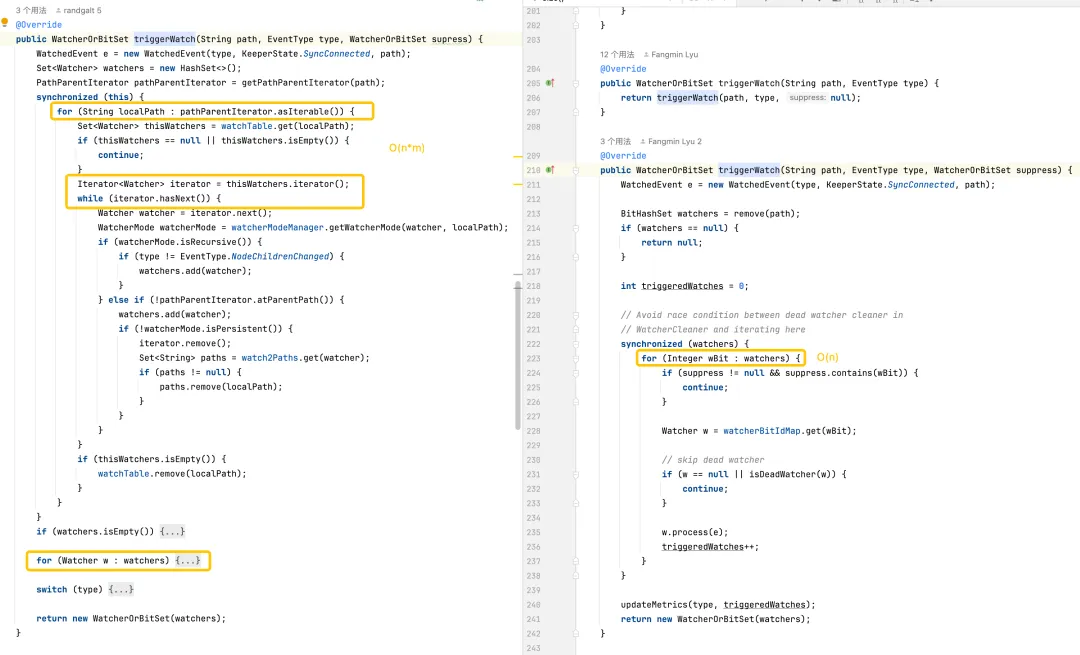
パフォーマンスストレステスト
JMH マイクロベンチマーク
ZooKeeper 3.6.4 ソース コード コンパイル、JMH マイク ストレス テスト WatchBench。
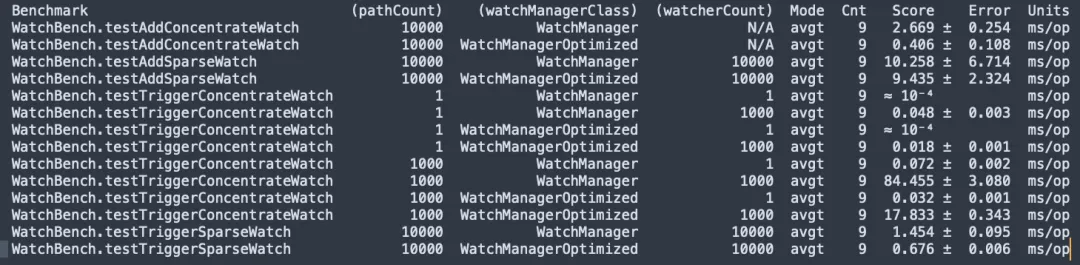
pathCount: テストで使用される ZNode パスの数を示します。
watchManagerClass: テストで使用される WatchManager 実装クラスを表します。
watcherCount: テストで使用されるオブザーバー (ウォッチャー) の数を示します。
Mode: テスト モードを示します。ここでの avgt は、平均実行時間を示します。
Cnt: テストの実行数を示します。
スコア: テストのスコア、つまり平均実行時間を示します。
Error: スコアの誤差範囲を示します。
単位: スコアを表す単位。ここではミリ秒/オペレーション (ms/op) です。
- ZNode と Watcher の間には 100 万のサブスクリプションがあり、デフォルト バージョンでは 50 MB が使用されますが、最適化バージョンでは 0.2 MB しか必要とせず、直線的に増加することはありません。
- Watch を追加すると、最適化バージョン (0.406 ms/op) はデフォルト バージョン (2.669 ms/op) より 6.5 倍高速になります。
- 多数のウォッチがトリガーされ、最適化されたバージョン (17.833 ミリ秒/オペレーション) はデフォルト バージョン (84.455 ミリ秒/オペレーション) より 5 倍高速です。
パフォーマンスストレステスト
次に、3 ノードの ZooKeeper 3.6.4 のセットがマシン (32C 60G) 上に構築され、最適化されたバージョンとデフォルトのバージョンが容量ストレス テストの比較に使用されました。
シナリオ 1: 20W znode ショート パス
Znode のショートパス: /demo/znode1

シナリオ 2: 20W znode の長いパス
Znode の長いパス: /sentinel-cluster/dev/xx-admin-interfaces/lock/_c_bb0832d5-67a5-48ab-8fe0-040b9ddea-lock/12

- ウォッチのメモリ使用量は、ZNode のパスの長さに関係します。
- ウォッチの数はデフォルト バージョンでは直線的に増加し、最適化バージョンでは非常に良好なパフォーマンスを示します。これは、メモリ使用量の最適化にとって非常に明らかな改善です。
グレースケールテスト
前回のベンチマーク テストと容量テストに基づいて、最適化されたバージョンでは、多数の Watch シナリオで明らかにメモリが最適化されています。次に、テスト環境で ZK クラスターのグレースケール アップグレード テストの観察を開始しました。
最初の ZooKeeper クラスターと利点
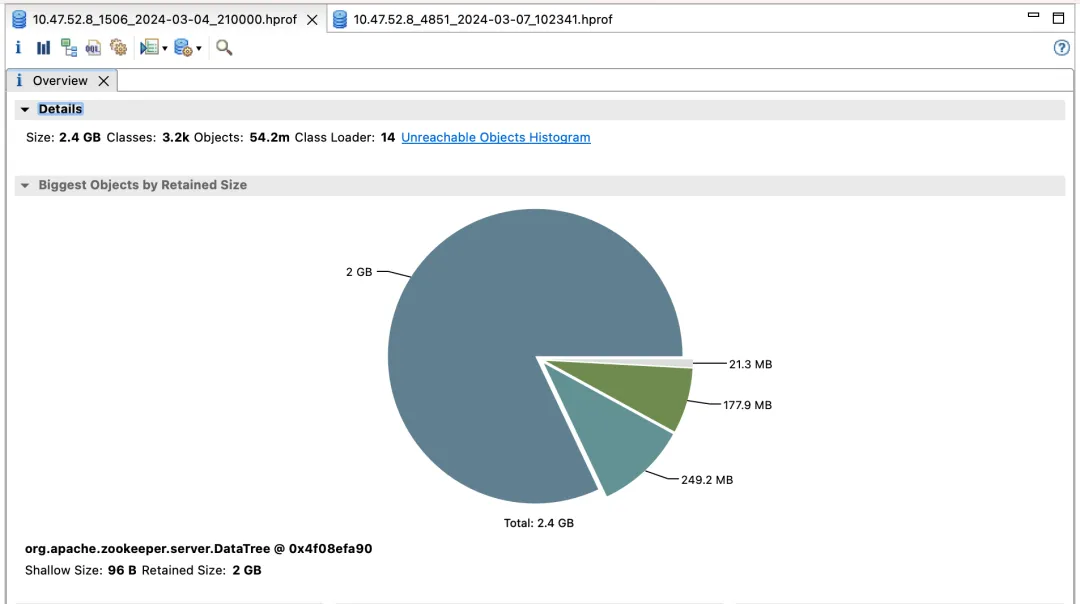
デフォルトのバージョン
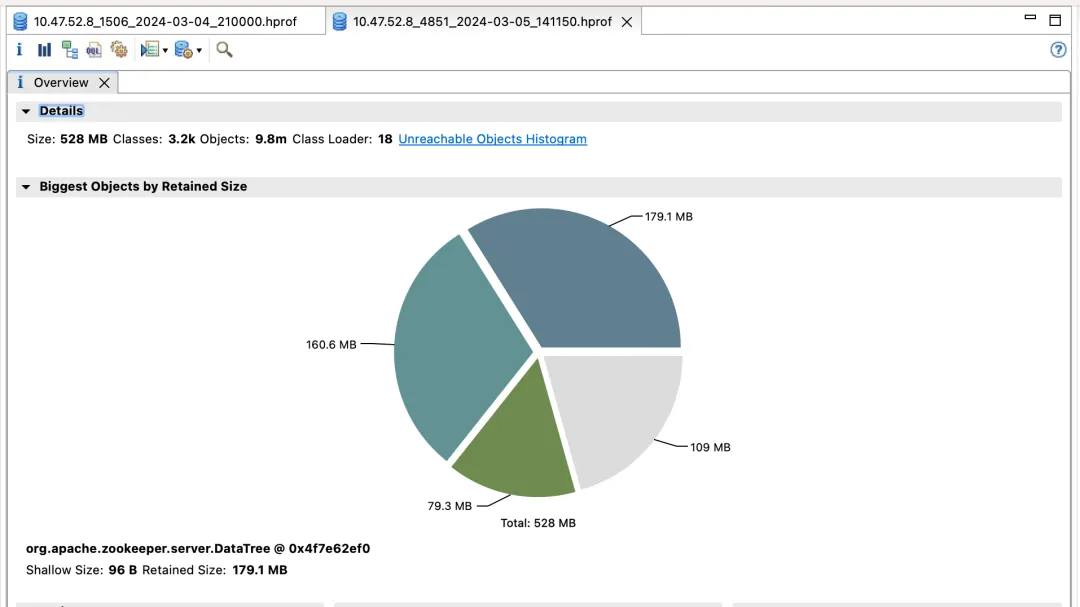
最適化されたバージョン


影響収入:
- election_time (選挙時間): 60% 削減
- fsync_time (トランザクション同期時間): 75% 削減
- メモリ使用量: 91% 削減
2 番目の ZooKeeper クラスターと利点
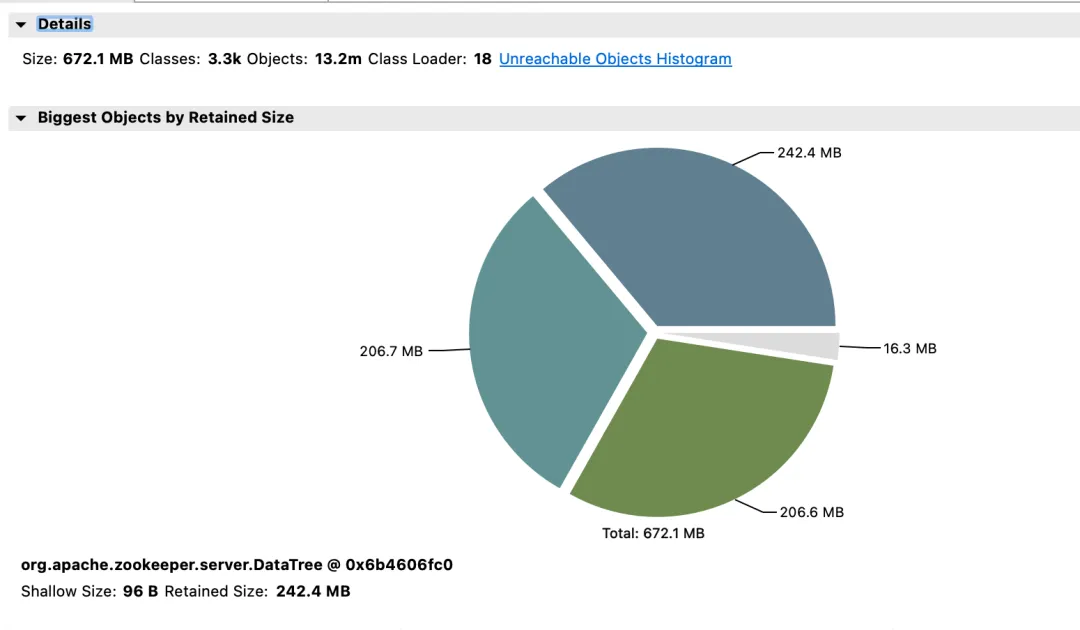



影響収入:
- メモリ: 変更前は、JVM Attach 応答が応答せず、データ収集に失敗していました。
- election_time (選挙時間): 64% 削減されました。
- max_latency (読み取りレイテンシ): 53% 削減。
- professional_latency (選挙処理提案遅延): 1400000 ミリ秒 --> 43 ミリ秒。
- propagation_latency (データ伝播遅延): 1400000 ミリ秒 --> 43 ミリ秒。
ZooKeeper クラスターの 3 番目のセットと利点
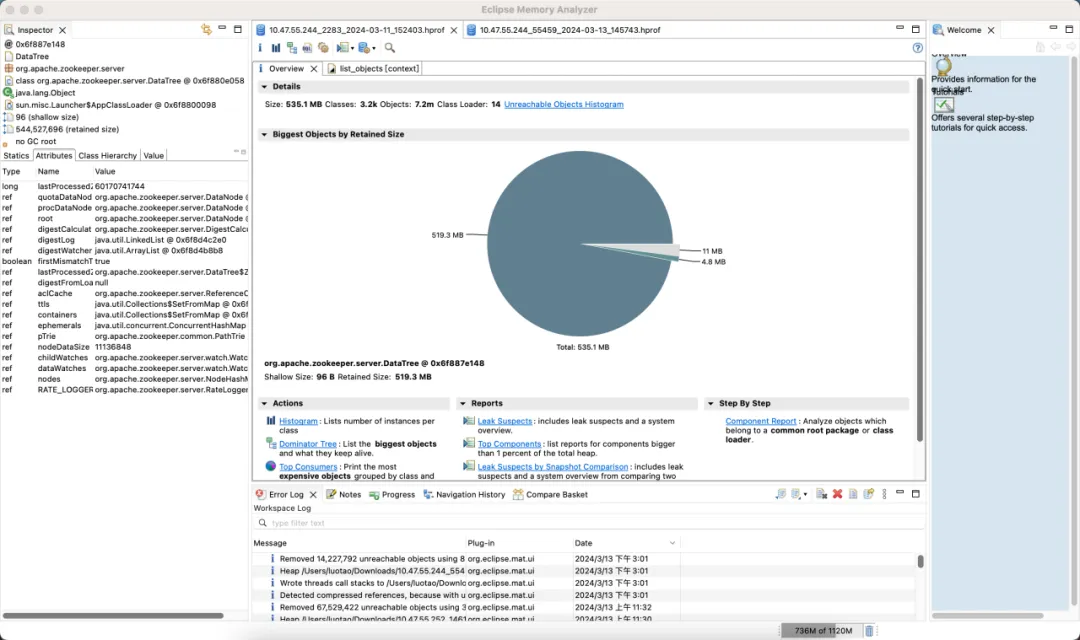
デフォルトのバージョン
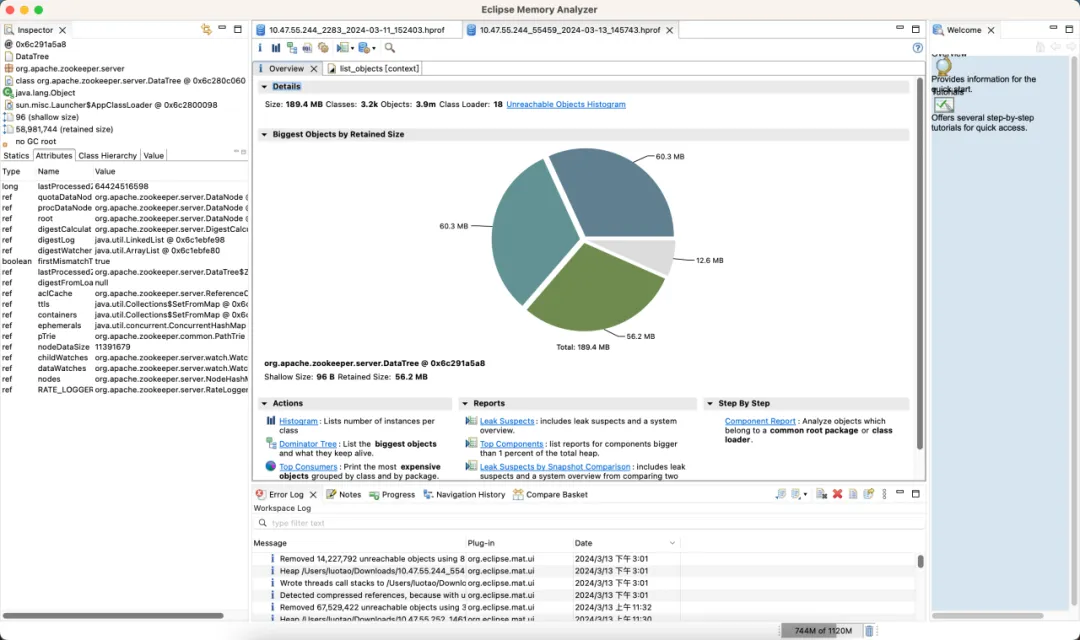
最適化されたバージョン
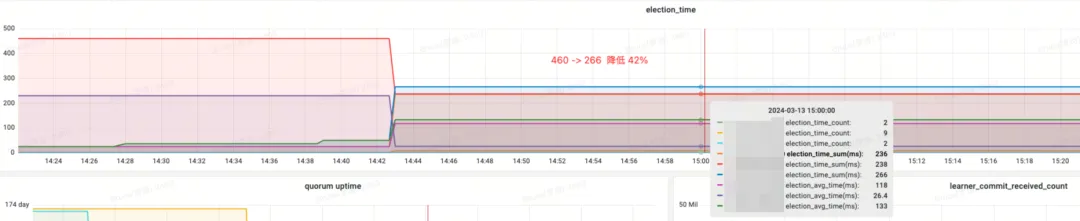

影響収入:
- メモリ: 89% 節約
- election_time (選挙時間): 42% 削減
- max_latency (読み取りレイテンシー): 95% 削減
- professional_latency (選挙処理提案遅延): 679999 ミリ秒 --> 0.3 ミリ秒
- propagation_latency (データ伝播遅延): 928000 ミリ秒 --> 5 ミリ秒
要約する
これまでのベンチマーク テスト、パフォーマンス ストレス テスト、グレースケール テストを通じて、ZooKeeper の WatchManagerOptimized が発見されました。この最適化によりメモリが節約されるだけでなく、ロックの最適化によりノード間の選択やデータ同期などの指標が大幅に改善され、ZooKeeper の一貫性が向上します。また、Alibaba MSE の学生と綿密な意見交換を行い、それぞれが極端なシナリオでのストレス テストをシミュレートし、WatchManagerOptimized によって ZooKeeper の安定性が大幅に向上するという合意に達しました。全体として、この最適化により ZooKeeper の SLA は一桁改善されます。
ZooKeeper には多くの設定オプションがありますが、ほとんどの場合、調整は必要ありません。システムの安定性を向上させるために、次の構成の最適化を実行することをお勧めします。
- dataDir (データ ディレクトリ) と dataLogDir (トランザクション ログ ディレクトリ) をそれぞれ別のディスクにマウントし、高性能ブロック ストレージを使用します。
- ZooKeeper バージョン 3.8 の場合は、JDK 17 を使用して ZGC ガベージ コレクターを有効にすることをお勧めします。バージョン 3.5 および 3.6 の場合は、JDK 8 を使用して G1 ガベージ コレクターを有効にすることをお勧めします。これらのバージョンの場合は、-Xms と -Xmx を構成するだけです。
- SnapshotCount パラメータのデフォルト値である 100,000 から 500,000 を調整します。これにより、ZNode が高頻度で変更されるときのディスク圧力を大幅に軽減できます。
- Watch Manager WatchManagerOptimized の最適化されたバージョンを使用します。
参照:
https://issues.apache.org/jira/browse/ZOOKEEPER-1177
https://github.com/apache/zookeeper/pull/590
ライナスは、カーネル開発者がタブをスペースに置き換えるのを防ぐことに自ら取り組みました。 彼の父親はコードを書くことができる数少ないリーダーの 1 人であり、次男はオープンソース テクノロジー部門のディレクターであり、末息子はオープンソース コアです。寄稿者Robin Li: 自然言語 は 新しいユニバーサル プログラミング言語になるでしょう。オープン ソース モデルは Huawei にますます後れをとっていきます 。一般的に使用されている 5,000 のモバイル アプリケーションを Honmeng に完全に移行するには 1 年かかります。 リッチテキスト エディタ Quill 2.0 が リリースされ、機能、信頼性、開発者は「恨みを取り除く 」 ために握手を交わしました。 Laoxiangji のソースはコードではありませんが、その背後にある理由は非常に心温まるものです。Googleは大規模な組織再編を発表しました。